InfinityHuman - 字节联合浙大推出的长视频数字人生成模型InfinityHuman 是字节跳动与浙江大学联合推出的商用级长时序音频驱动人物视频生成模型。模型通过音频驱动,能生成高分辨率、长时长且视觉一致的人物视频。最新AI资源11个月前056.4K
AutoMV - M-A-P联合北邮、南大等开源的免费音乐视频生成系统AutoMV是M-A-P团队联合多所高校研发的开源音乐视频生成系统,能在无需训练的情况下根据完整歌曲自动生成连贯的MV。采用多智能体协作模式,包含音乐分析、编剧、导演和质检等模块,能精准解析歌词、节拍...最新AI资源7个月前056.3K
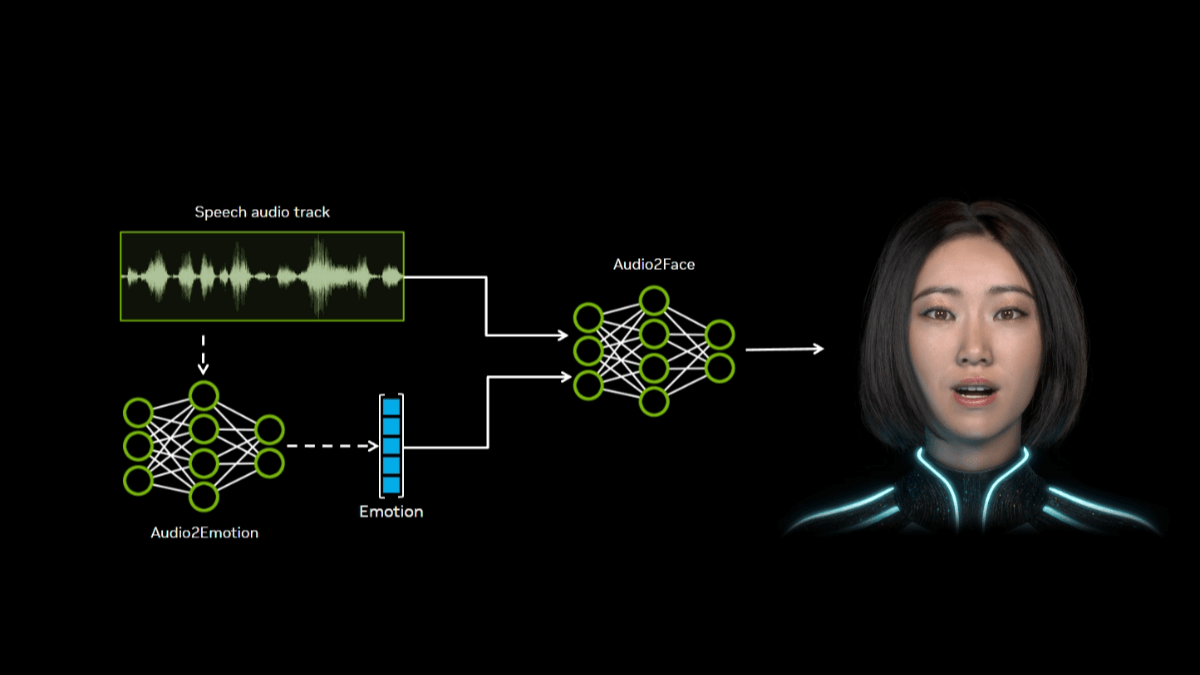
Audio2Face - NVIDIA开源的AI 3D面部动画生成模型Audio2Face是NVIDIA开源的能将音频输入转化为逼真的3D面部动画AI工具。通过分析音频中的语音特征,如音素和语调,生成精确的唇部同步和细腻的情感表达,为虚拟角色赋予生动的人类表情。最新AI资源10个月前056.3K
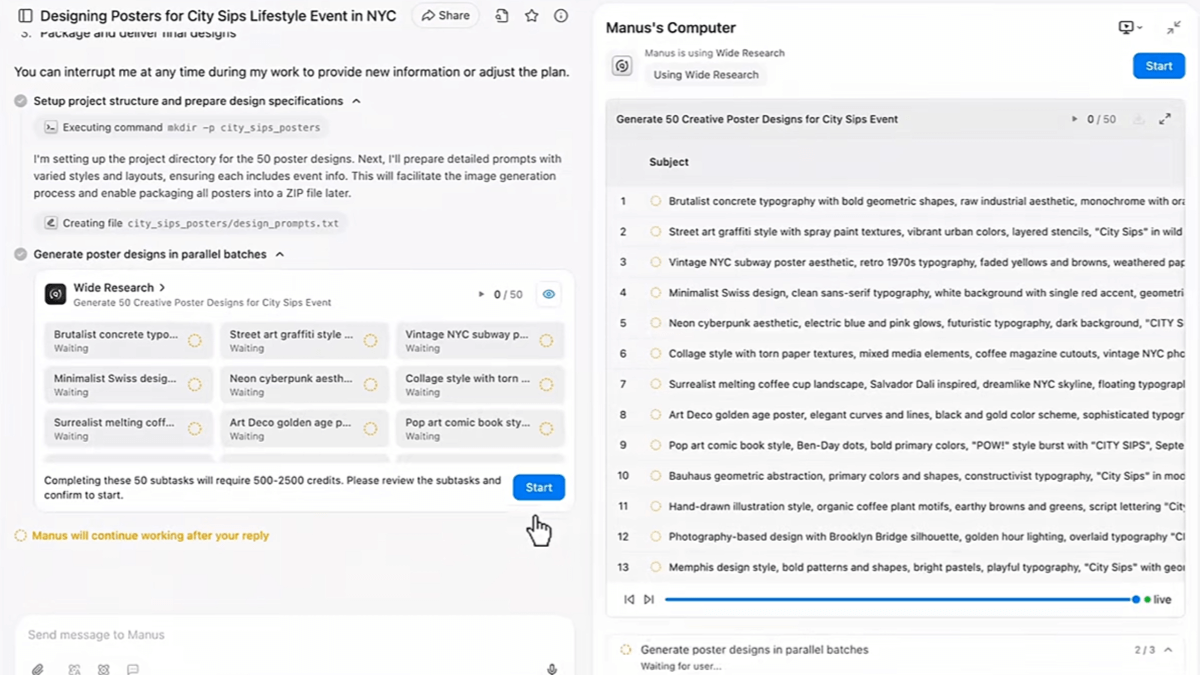
Wide Research - Manus平台推出的多智能体协同功能Wide Research 是 Manus 平台推出的强大功能,专为处理复杂且大规模的任务而设计。平台通过系统级的并行处理机制和智能体协作协议,能支持上百个通用智能体同时工作。最新AI资源1年前056.3K
10Kh RealOmni-Open - 简智机器人开源的具身智能数据集10Kh RealOmni-Open是简智机器人开源的具身智能数据集,是行业内规模最大的开源具身智能数据集。数据集累计拥有超10000小时数据、100万+片段,覆盖10大场景任务、超过30项技能。数据...最新AI资源7个月前056.2K
VibeVoice-ASR - 微软开源的统一语音转文本(ASR)模型VibeVoice-ASR是微软开源的统一语音转文本(ASR)模型,专为处理长音频设计,可一次性处理长达60分钟的连续音频,确保语义连贯性和说话人追踪的一致性。支持自定义热词功能,用户可输入特定词汇或...最新AI资源6个月前056.2K
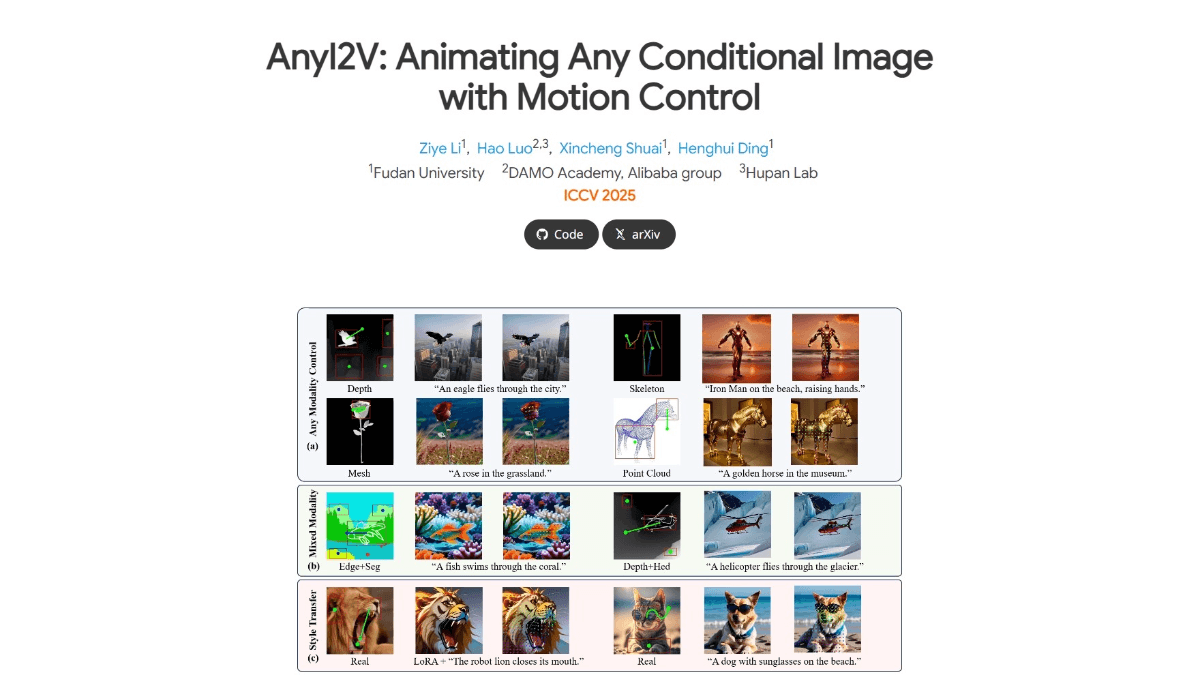
AnyI2V - 复旦联合阿里达摩院等开源的智能图像动画生成框架AnyI2V是复旦大学、阿里巴巴达摩院等联合推出的图像动画生成框架,支持将静态的条件图像(如网格、点云等)转化为动态视频,无需复杂的训练过程和大量数据。最新AI资源11个月前056.2K
SCAIL - 智谱联合清华开源的影视级角色动画生成框架SCAIL(Studio-Grade Character Animation via In-Context Learning)是智谱与清华大学刘永进教授课题组合作提出的一种影视级角色动画生成框架。通过...最新AI资源8个月前056.1K
Clawra - 基于OpenClaw框架开源的AI女友程序Clawra是一个基于OpenClaw框架开发的AI女友程序,由韩国开发者David Im制作,具有完整人设和交互功能。通过Persona Engineering技术赋予AI“18岁亚裔女性练习生”的...最新AI资源6个月前056.1K
OpenReasoning-Nemotron - 英伟达推出的开源系列推理模型OpenReasoning-Nemotron 是英伟达开源的一系列大型语言模型,支持处理数学、科学和代码领域的推理任务。模型基于 DeepSeek R1 0528 模型蒸馏而成,参数规模有 1.5B...最新AI资源1年前056.1K
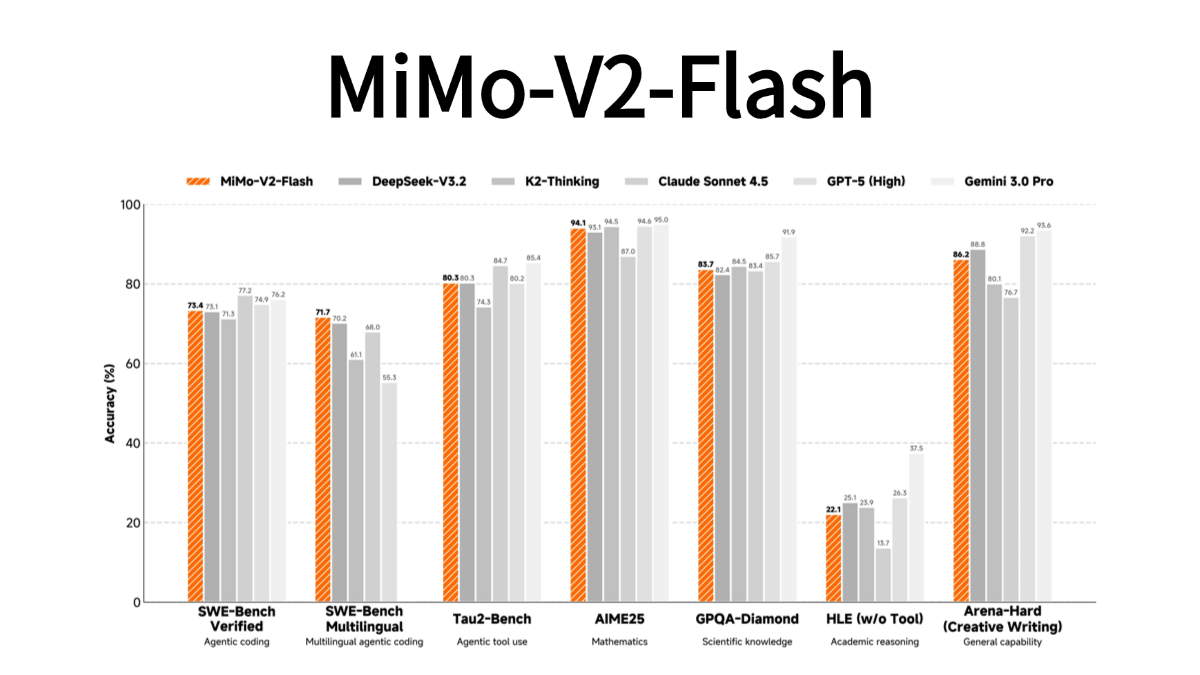
MiMo-V2-Flash - 小米发布的开源MoE架构大模型MiMo-V2-Flash是小米发布的开源MoE架构大模型,总参数3090亿,活跃参数150亿,主打高效推理和智能体应用。模型采用混合注意力架构与多词元预测技术,推理速度达150 tokens/秒,成...最新AI资源8个月前056.1K
FLUX.2 [klein] - Black Forest Labs 开源的轻量级图像生成与编辑模型FLUX.2 [klein] 是 Black Forest Labs 推出的开源轻量级图像生成与编辑模型,专为快速推理和低延迟应用场景设计。支持文本生成图像、图像编辑以及多参考图像生成,能在不到1秒内...最新AI资源6个月前056K
GLM-OCR - 智谱开源的 0.9B 轻量级专业 OCR 模型GLM-OCR 是智谱开源的 0.9B 轻量级专业 OCR 模型,在 OmniDocBench V1.5 以 94.6 分刷新 SOTA。兼顾“小体积”与“全场景”,扫描、手写、印章、多语混排、复杂表...最新AI资源6个月前056K
GLM-ASR - 智谱AI开源的高性能语音识别模型系列GLM-ASR是智谱AI开源的高性能语音识别模型系列,包含云端模型GLM-ASR-2512和开源端侧模型GLM-ASR-Nano-2512。GLM-ASR-2512是全球领先的云端语音识别模型,支持多...最新AI资源8个月前056K
MiniCPM 4.1 - 面壁智能推出的超高效端侧大模型MiniCPM 4.1 是面壁智能推出的超高效端侧大语言模型。采用 InfLLM v2 稀疏注意力架构,每个词元仅需计算与少于 5% 词元的相关性,显著降低长文本处理开销。在 128K 长文本场景下...最新AI资源11个月前055.8K
MiniCPM-o 4.5 - 面壁智能开源的 9B 全模态旗舰模型MiniCPM-o 4.5 是面壁智能开源的 9B 全模态旗舰模型,以“边看边听主动说”的端到端架构,在手机端即可跑出 GPT-4o 级体验:支持单图、多图、高帧率长视频、实时语音双工对话,首 tok...最新AI资源6个月前055.8K
Protenix-v1 - 字节Seed团队推出的首个开源蛋白质结构预测模型Protenix-v1是字节跳动ByteDance Seed团队推出的首个开源蛋白质结构预测模型,性能在严格对齐训练数据和模型规模后超越AlphaFold 3。模型具备显著的推理时扩展特性:通过增加采...最新AI资源6个月前055.8K
阶跃深研 - 阶跃星辰推出的AI深入研究工具阶跃深研是阶跃星辰推出的高效AI研究工具,能在短时间内自主完成复杂问题的研究并生成专业报告。工具专为金融、咨询、医疗、法律等领域设计,凭借深度搜索与信息整合能力,在行业评测中表现优异。最新AI资源1年前055.8K
Step-Audio-R1.1 - 阶跃星辰开源的全球首个原生语音推理模型Step-Audio-R1.1是阶跃星辰开源的全球首个原生语音推理模型,最新升级版本在权威评测榜单Artificial Analysis Speech Reasoning中以96.4%准确率登顶。模型...最新AI资源7个月前055.8K
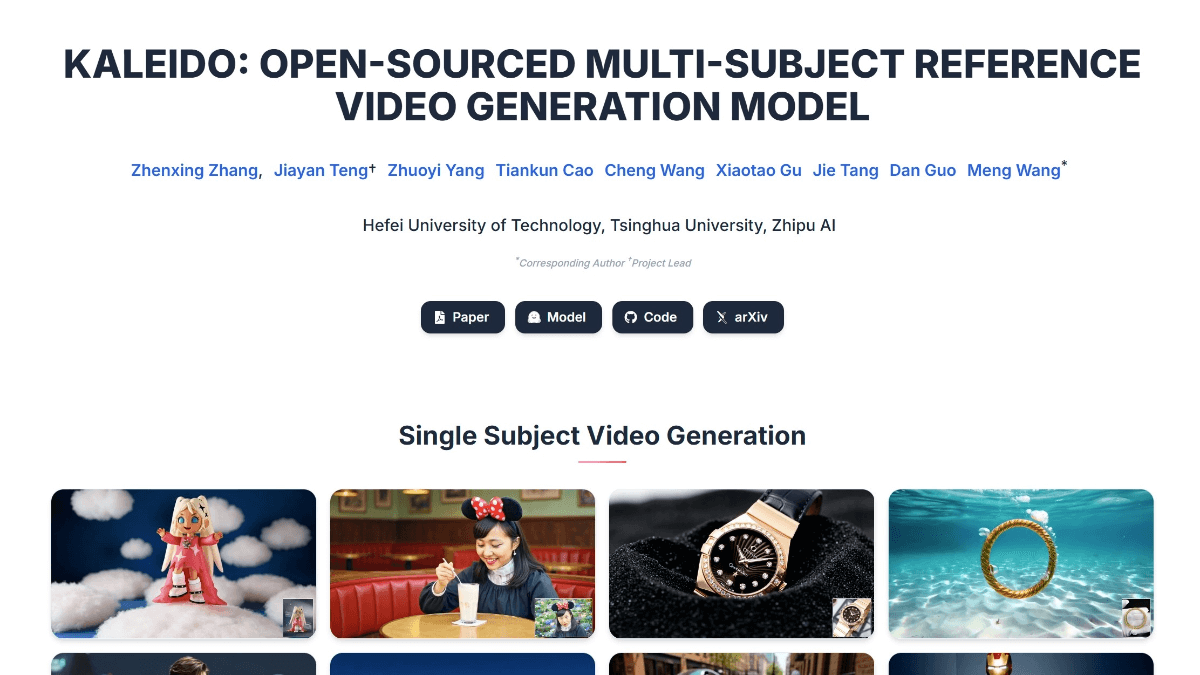
Kaleido - 智谱AI联合清华大学等开源的多主体参考视频生成模型Kaleido是合肥工业大学、清华大学和智谱AI联合开发的开源多主体参考视频生成模型。通过多个参考图像生成主体一致的视频,解决了现有模型在多主体一致性和背景解耦方面的不足。Kaleido通过专门的数据...最新AI资源8个月前055.7K
Claude Sonnet 4.5 - Anthropic推出的最强AI编程模型Claude Sonnet 4.5 是 Anthropic 公司推出的人工智能模型,专为编程、计算机操作和复杂任务自动化设计。模型在代码生成、长时间任务处理、推理和数学计算方面表现出色,支持从初始规划...最新AI资源10个月前055.7K
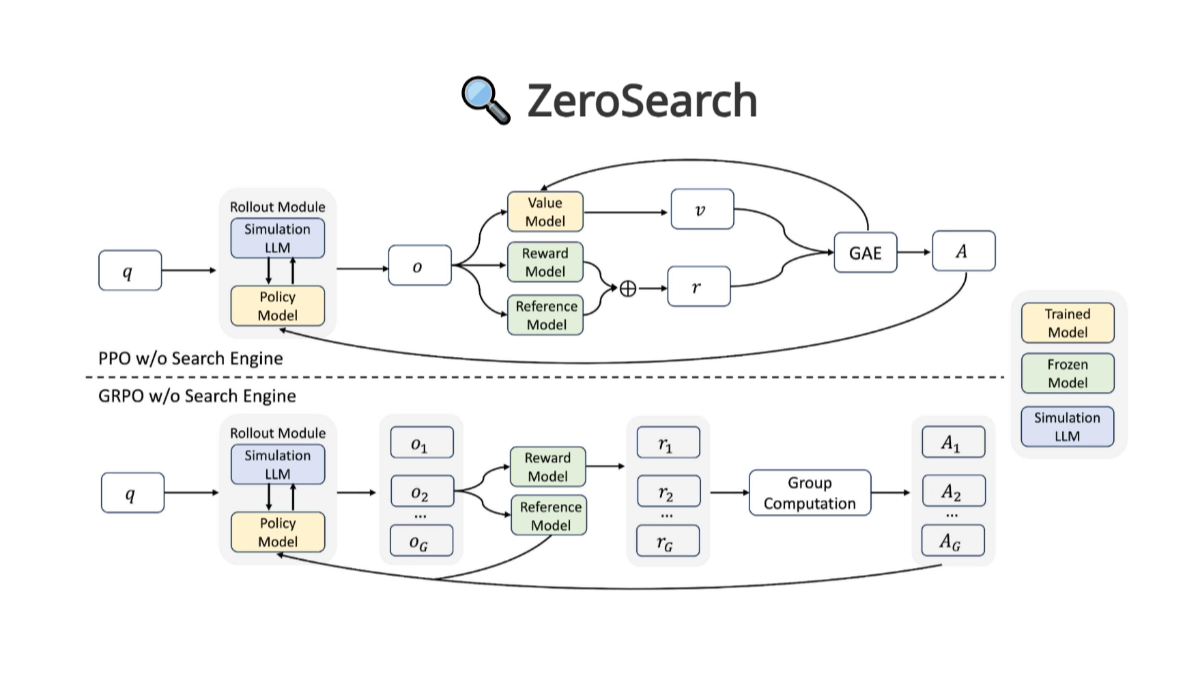
ZeroSearch - 阿里通义推出的开源大模型搜索引擎框架ZeroSearch是阿里巴巴通义实验室开源的创新大模型搜索引擎框架。框架无需与真实搜索引擎交互,基于模拟搜索引擎的方式,用大模型自身的预训练知识生成相关或噪声文档,大幅降低训练成本(降低80%以上...最新AI资源1年前055.6K
PromptEnhancer - 腾讯混元开源的AI提示词增强工具PromptEnhancer 是腾讯混元团队开源的提示词增强工具,提升文本到图像(Text-to-Image,T2I)模型的生成效果。通过链式推理(Chain-of-Thought,CoT)的方式对用...最新AI资源11个月前055.5K
FLM-Audio - 智源联合南洋理工开源的全双工音频对话模型FLM-Audio 是北京智源人工智能研究院联合 Spin Matrix 与新加坡南洋理工大学共同发布的原生全双工音频对话大模型,支持中文和英文。采用原生全双工架构,可在每个时间步合并听觉、说话和独白...最新AI资源10个月前055.5K
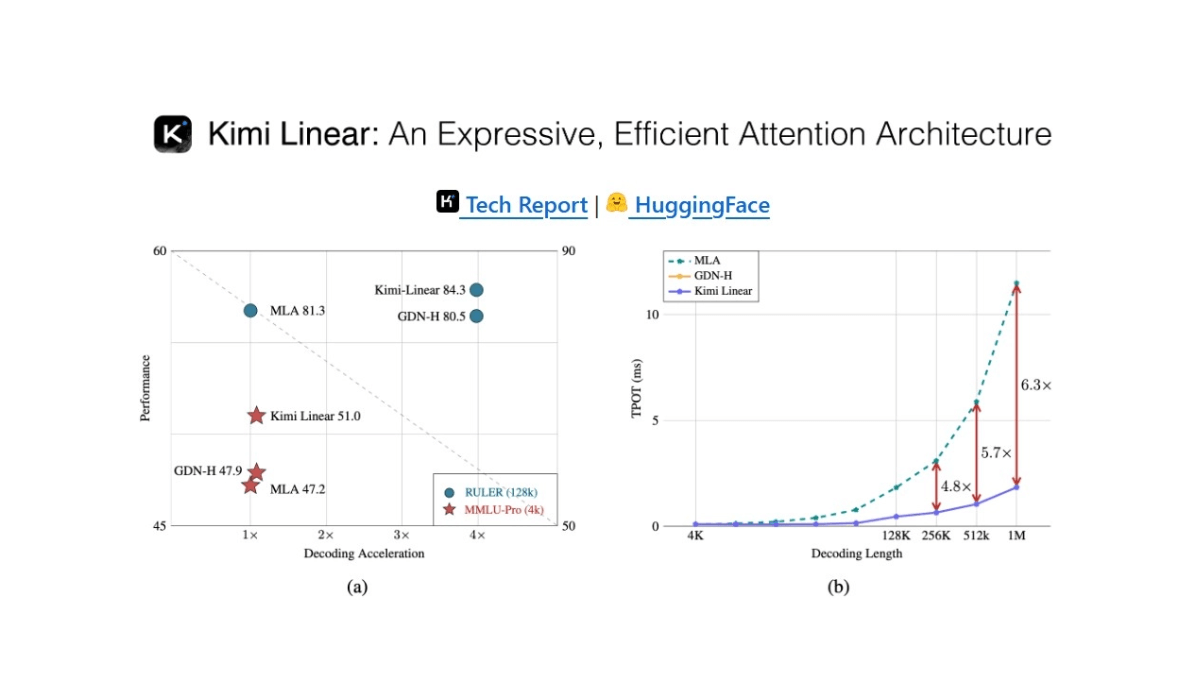
Kimi Linear - 月之暗面开源的新型混合线性注意力架构Kimi Linear 是月之暗面开源的新型混合线性注意力架构,以 Kimi Delta Attention(KDA)为核心,通过更细粒度的门控机制优化了传统注意力模型,显著提升了硬件效率和内存控制能...最新AI资源9个月前055.4K
混元图像2.1 - 腾讯推出的开源文生图模型混元图像2.1(HunyuanImage 2.1)是腾讯推出的开源文生图模型,专为高质量图像生成设计。模型支持原生2K分辨率,能精准呈现复杂场景和细节,使人物表情和动作能生动还原。最新AI资源11个月前055.4K
SoulX-Podcast - Soul AI Lab开源的对话式语音合成模型SoulX-Podcast 是 Soul AI Lab 开源的先进多说话者对话式语音合成模型,专为生成高质量播客内容设计。具备多轮对话生成能力,能模拟真实播客场景中的流畅对话,支持普通话、英语及多种中...最新AI资源9个月前055.3K
New API - 开源的AI模型接口管理与分发系统,统一为标准化接口New API是基于Go语言开发的开源AI聚合网关工具,可统一管理30+种主流大模型(如OpenAI、Claude、Midjourney等),将不同模型接口转换为标准化OpenAI格式。最新AI资源7个月前055.3K
NeuTTS Air - 支持离线CPU运行的免费轻量级语音合成模型NeuTTS Air是开源的轻量级语音合成模型,由Neuphonic团队开发,可在本地设备(如手机、笔记本、树莓派)上实时运行,无需依赖云端。采用0.5B参数的Qwen架构和自研NeuCodec编解码...最新AI资源10个月前055.3K
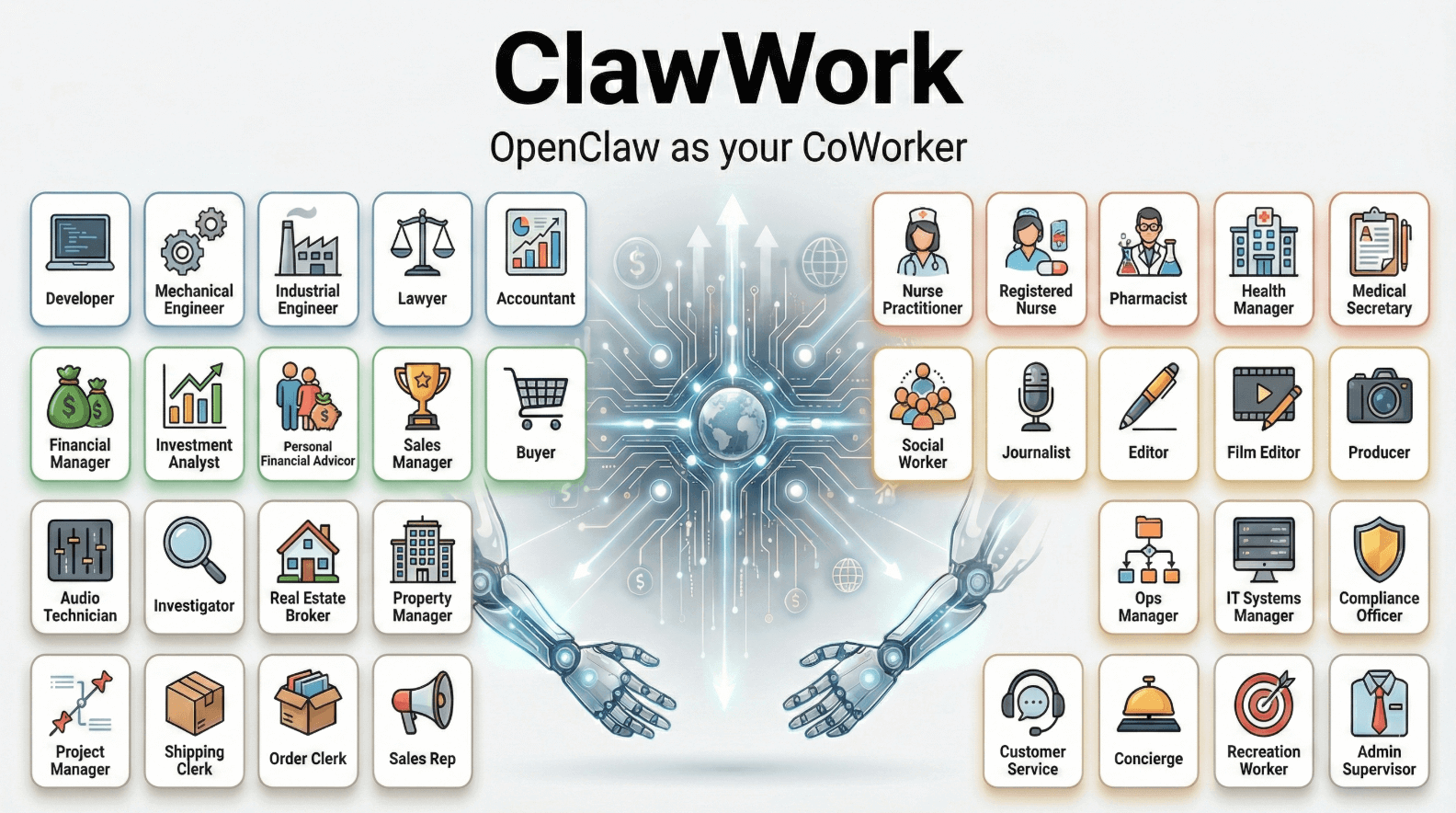
ClawWork - 香港大学数据科学实验室开源的AI经济压力测试框架ClawWork是香港大学数据科学实验室开发的AI经济压力测试框架,允许AI在模拟经济环境中完成真实工作任务并获得报酬。核心逻辑是让初始资金仅10美元的AI通过完成220个专业任务(覆盖制造、金融、医...最新AI资源5个月前055.3K
XVERSE-Ent - 元象科技开源的泛娱乐领域中英大模型XVERSE-Ent是元象科技推出的专注于泛娱乐领域的开源大模型,包含中英文双版本,支持社交互动、游戏叙事和文化创作等场景。模型通过角色一致性强化、长剧情理解等技术优化,能在虚拟角色人设稳定性、复杂故...最新AI资源7个月前055.2K
SoulX-FlashTalk - Soul App AI团队开源的实时数字人生成模型SoulX-FlashTalk是Soul App AI团队开源的实时数字人生成模型,拥有140亿参数量,实现了0.87秒超低延迟和32帧/秒的高帧率。模型通过双向蒸馏技术解决了传统数字人延迟高、画面易...最新AI资源6个月前055K
Wan-Move - 阿里通义联合清华等开源的AI视频生成框架Wan-Move是阿里通义实验室、清华大学等机构联合开发的开源AI视频生成框架,专注于通过精准运动控制技术实现高质量视频合成。核心技术是"潜在轨迹引导",能在现有图像到视频模型基础上无缝添加点级运动控...最新AI资源8个月前054.9K
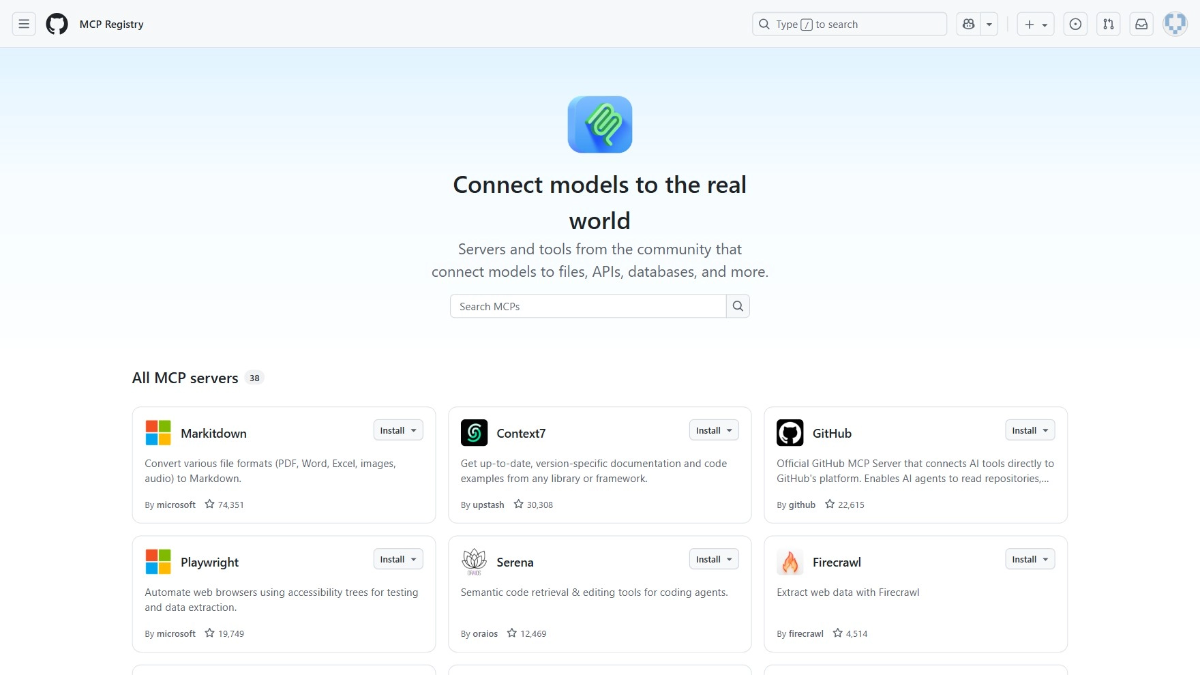
MCP Registry - GitHub推出的官方MCP服务器管理平台MCP Registry 是 GitHub 推出的集中化平台,能帮助开发者更便捷地发现和安装 MCP 服务器。MCP Registry 的出现,让开发者能在一个地方快速找到所需的 AI 工具,极大地简...最新AI资源11个月前054.9K
VLAC - 上海AI Lab开源的具身奖励大模型VLAC是上海人工智能实验室开源的具身奖励大模型。以InternVL多模态大模型为基础,融合互联网视频数据和机器人操作数据,为机器人在真实世界中的强化学习提供过程奖励和任务完成情况估计。VLAC能有效...最新AI资源11个月前054.9K
SHARP - 苹果开源的单目视图3D场景合成技术SHARP(Sharp Monocular View Synthesis in Less Than a Second)是苹果开源的单目视图合成技术。能从单张照片快速生成逼真的3D场景表示,仅需不到一秒...最新AI资源7个月前054.8K
Ring-2.5-1T - 蚂蚁百灵开源的万亿参数混合线性架构思考模型Ring-2.5-1T 是蚂蚁集团百灵大模型团队开源的全球首个万亿参数混合线性架构思考模型,采用1:7 MLA与Lightning Linear Attention混合设计,激活参数量达63B。模型在...最新AI资源5个月前054.7K
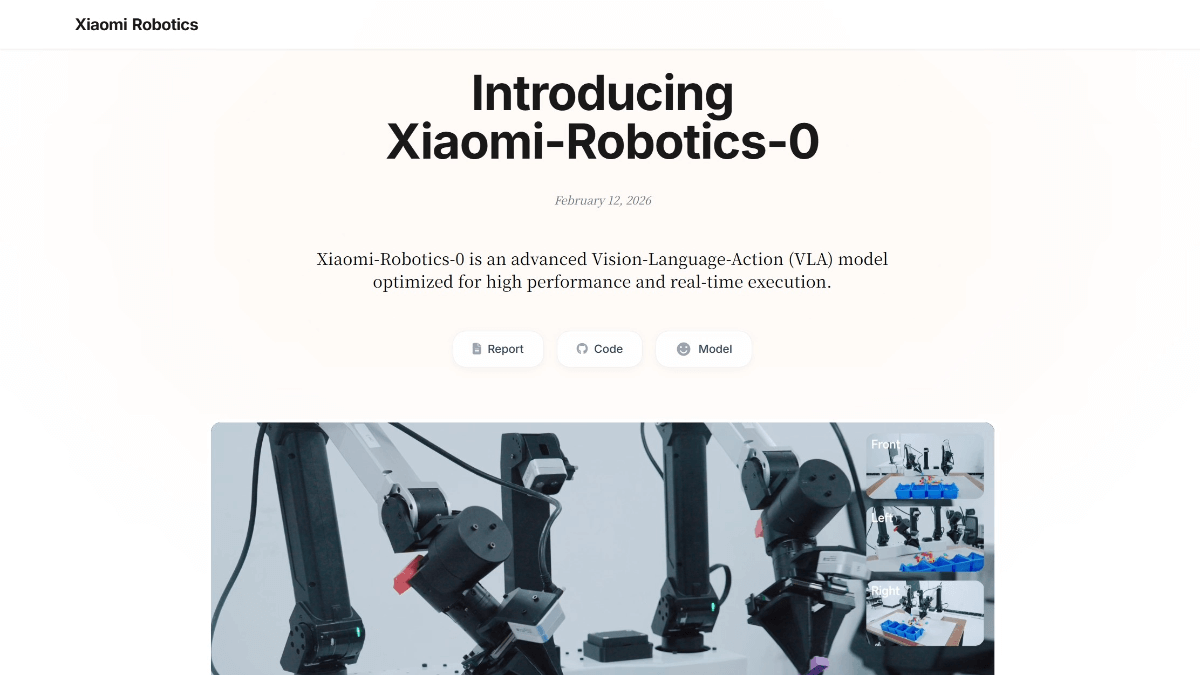
Xiaomi-Robotics-0 - 小米开源的首代具身智能大模型Xiaomi-Robotics-0 是小米开源的首代具身智能大模型,拥有47亿参数,采用"大脑+小脑"混合架构设计。视觉语言大脑基于多模态大模型,负责理解人类模糊指令与空间推理;动作执行小脑则通过Di...最新AI资源5个月前054.7K
LingBot-World - 蚂蚁旗下灵波科技开源的交互式世界模型LingBot-World 是蚂蚁集团旗下具身智能公司灵波科技(Robbyant)开源的交互式世界模型,专为具身智能、自动驾驶及游戏开发打造高保真“数字演练场”。模型通过可扩展数据引擎从大规模游戏环境...最新AI资源6个月前054.6K
混元Motion1.0 - 腾讯混元团队开源的文本生成3D动作模型混元Motion1.0(HY-Motion1.0)是腾讯混元团队开源的文本生成3D动作模型,采用10亿参数Diffusion Transformer架构,能通过自然语言描述直接生成高质量3D角色动画。最新AI资源7个月前054.6K
Kimi K2.5 - 月之暗面开源的新一代旗舰模型Kimi K2.5 是月之暗面发布的开源旗舰模型,采用 1T MoE 架构、激活 32B、上下文 256K token,原生支持图文视频多模态输入。在 Agent、代码、视觉理解三大基准均列开源第一...最新AI资源6个月前054.5K
DeepSeek-V3.1-Terminus - DeepSeek推出的最新版AI模型DeepSeek-V3.1-Terminus 是 DeepSeek 团队推出的人工智能语言模型,是 DeepSeek-V3.1 的升级版本。模型在语言一致性、代码生成和搜索能力等方面进行优化,能更准确...最新AI资源10个月前054.5K
olmOCR 2 - AI2开源的多模态文档解析模型olmOCR 2是Allen Institute for Artificial Intelligence(AI2)开源的多模态文档解析模型,是olmOCR的升级版本。将数字化的打印文档(如 PDF)高...最新AI资源9个月前054.5K
HeyGen - AI 数字人视频创作平台,支持多语言翻译配音HeyGen是AI驱动的数字人视频创作平台,支持简化视频制作流程,让用户快速生成专业水准的数字人视频。平台基于先进的AI技术,赋予用户对数字人物形象和声音的完全控制权,提供丰富的素材库,包括多样化背景...最新AI资源1年前054.5K
LingBot-VA - 蚂蚁灵波开源的首个“自回归视频-动作世界模型”LingBot-VA 是蚂蚁灵波开源的全球首个“自回归视频-动作世界模型”,把视频生成与机器人控制塞进同一 Transformer,每一步同时输出下一帧世界画面和对应动作,实现“边想边干”。最新AI资源6个月前054.4K
CWM - Meta FAIR开源的代码世界语言模型CWM(Code World Model)是Meta FAIR团队发布的一款320亿参数的开源代码世界语言模型,专为代码生成和推理设计。引入“世界模型”概念,能模拟代码执行过程,预测变量状态变化,提前...最新AI资源10个月前054.4K
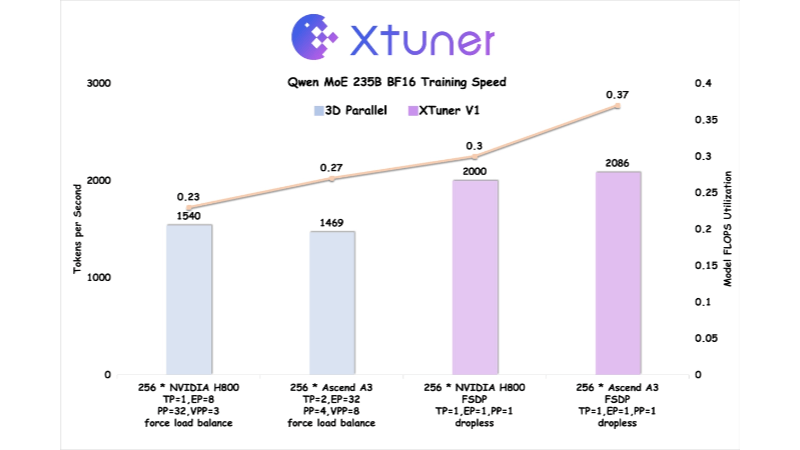
XTuner V1 - 上海AI Lab开源的大模型训练引擎XTuner V1 是上海人工智能实验室开源的新一代大模型训练引擎,专为超大规模稀疏混合专家(MoE)模型训练设计。基于 PyTorch FSDP 开发,通过显存、通信和负载等多维度优化,实现了高性能...最新AI资源11个月前054.3K
Code2Video - Show Lab开源的AI教学视频生成框架Code2Video是创新的开源项目,能将代码片段自动转换为高质量的视频内容(mp4格式)。项目通过独特的代码中心范式,使用carbon-now-cli工具将代码生成精美的图片,利用ffmpeg将这些...最新AI资源10个月前054.1K
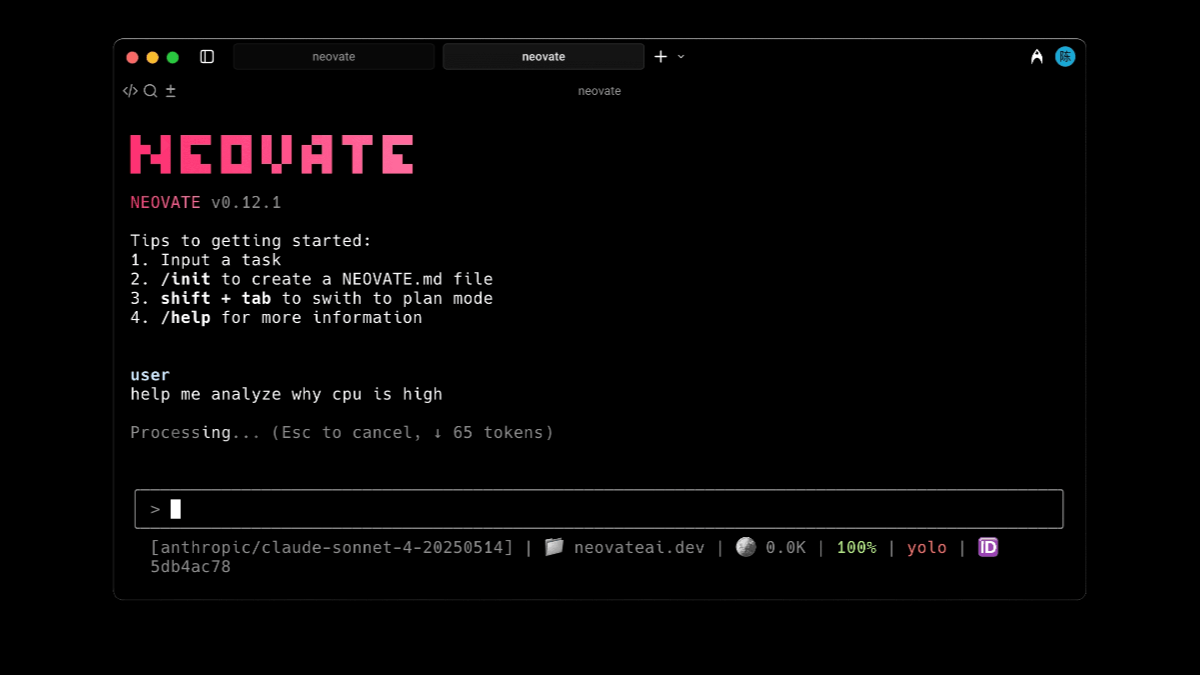
Neovate Code - 蚂蚁开源的智能编程助手Neovate Code 是蚂蚁集团支付宝体验技术部开源的智能编程助手,通过人工智能技术提升开发效率。具备对话式开发功能,开发者可以通过自然语言描述需求,Neovate Code 能理解并生成相应的代...最新AI资源10个月前054K
Ouro - 字节跳动Seed团队开源的新型循环语言模型Ouro是字节跳动Seed团队开发的新型循环语言模型(Looped Language Models),核心创新在于通过参数共享的循环计算结构,在预训练阶段直接构建推理能力。模型采用24层作为基础块,通...最新AI资源9个月前054K
SkyReels-V3 - 昆仑万维Skywork AI开源的多模态视频生成模型SkyReels-V3是昆仑万维Skywork AI开源的多模态视频生成模型,被誉为视频生成领域的"全能型"标杆。模型基于"一核多支"的统一架构,在单一建模框架内集成三大核心能力:参考图像转视频、智能...最新AI资源6个月前053.7K
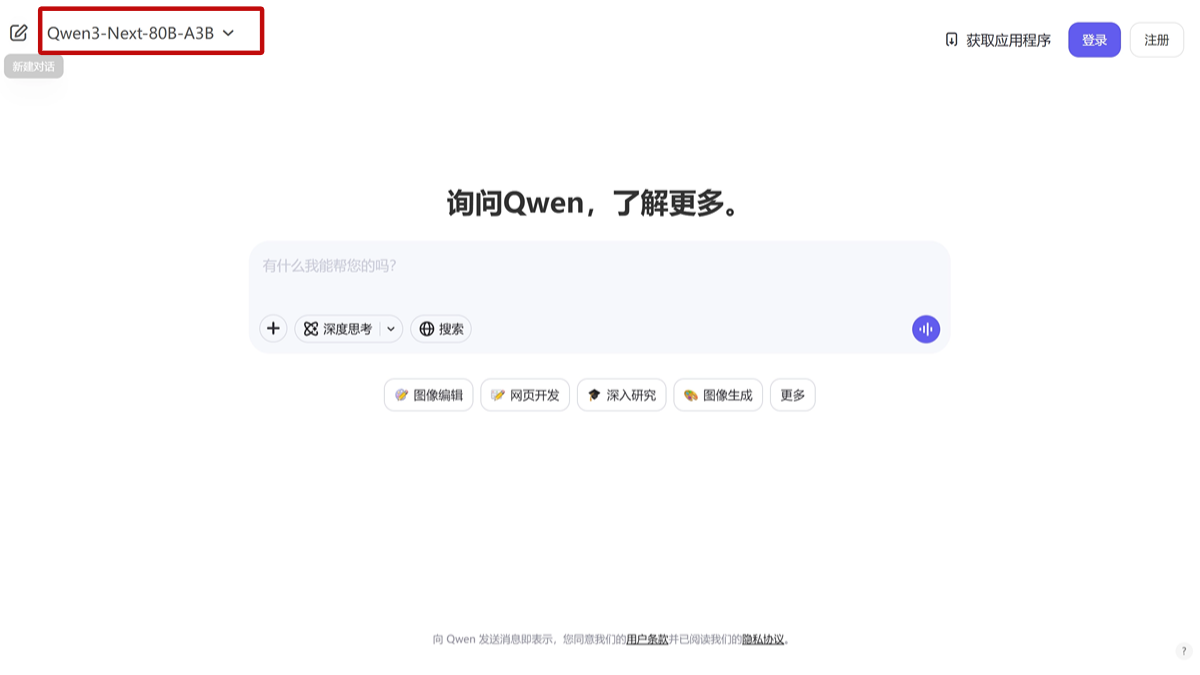
Qwen3-Next - 阿里通义推出的最新基础模型Qwen3-Next是阿里通义开源的新一代混合架构大模型,结合了Gated DeltaNet和Gated Attention技术,擅长处理长文本,推理速度快且节省计算资源。最新AI资源11个月前053.7K
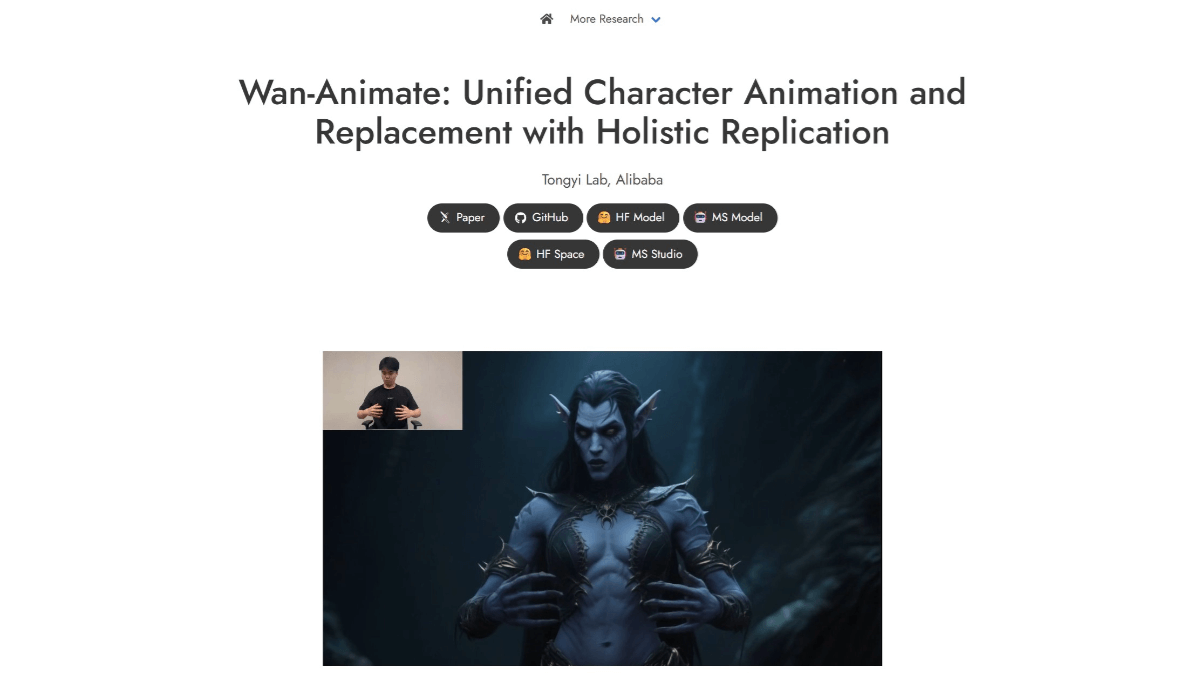
Wan2.2-Animate - 通义万相开源的动作生成模型Wan2.2-Animate是通义万相开源的动作生成模型,支持动作模仿和角色扮演两种模式。用户只需输入一张角色图片和一段参考视频,模型能将视频中角色的动作、表情迁移到图片角色中,赋予图片角色动态表现力...最新AI资源10个月前053.7K
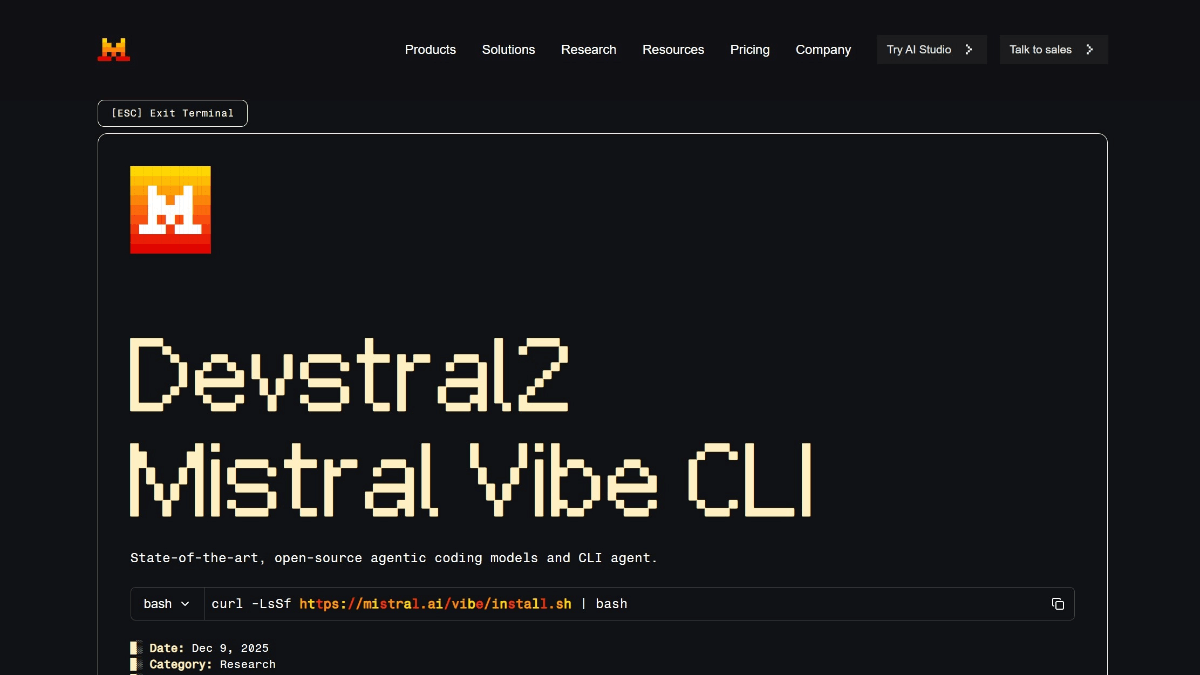
Mistral Vibe - Mistral AI推出的开源命令行编码助手Mistral Vibe是Mistral AI推出的开源命令行编码助手,基于Devstral模型开发,支持自然语言交互完成代码搜索、文件操作、版本控制等任务。能自动扫描项目结构和Git状态,通过@符号...最新AI资源8个月前053.5K
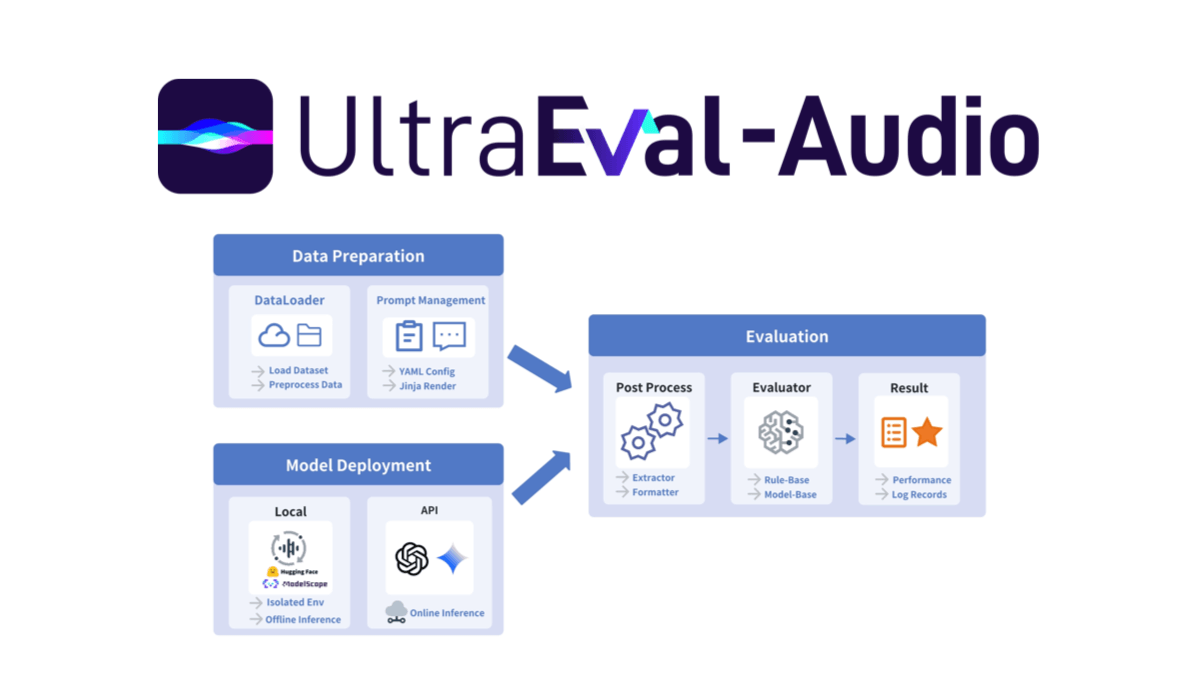
UltraEval-Audio - 清华、OpenBMB联合面壁智能开源的音频模型评测框架UltraEval-Audio是清华大学NLP实验室、OpenBMB和面壁智能联合开发的音频模型评测框架,最新版本为v1.1.0。专注于解决音频模型复现难、依赖冲突等问题,提供一键复现热门模型(如Vo...最新AI资源7个月前053.4K
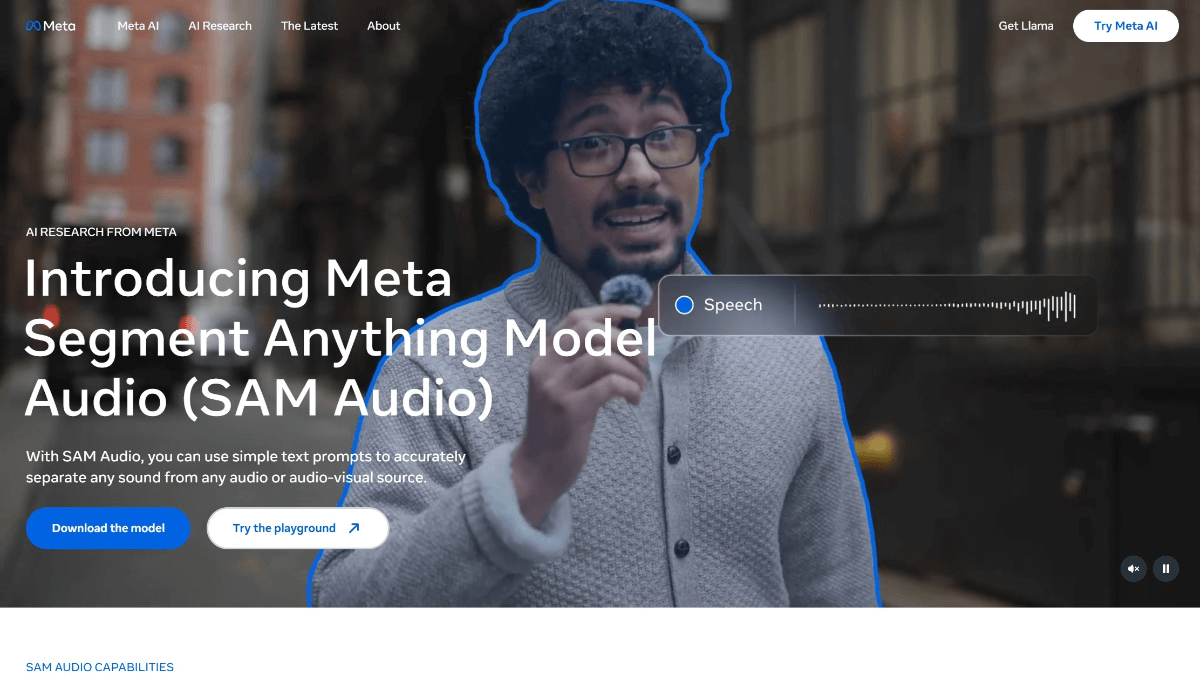
SAM Audio - Meta推出的开源多模态音频分割模型SAM Audio是Meta推出的开源多模态音频分割模型,从复杂的音频混合中精准分离出任意目标声音。通过结合文本、视觉和时间维度的提示,实现灵活、高效的音频处理,为音频编辑、去噪、声音提取等任务提供了...最新AI资源7个月前053.4K
Chatterbox-Turbo - Resemble AI开源的文本到语音模型Chatterbox-Turbo 是 Resemble AI 推出的开源文本到语音(TTS)模型,专为高效、低延迟的语音合成而设计。基于350M参数的精简架构,单步推理生成音频,时间延迟极低,在150...最新AI资源7个月前053.3K
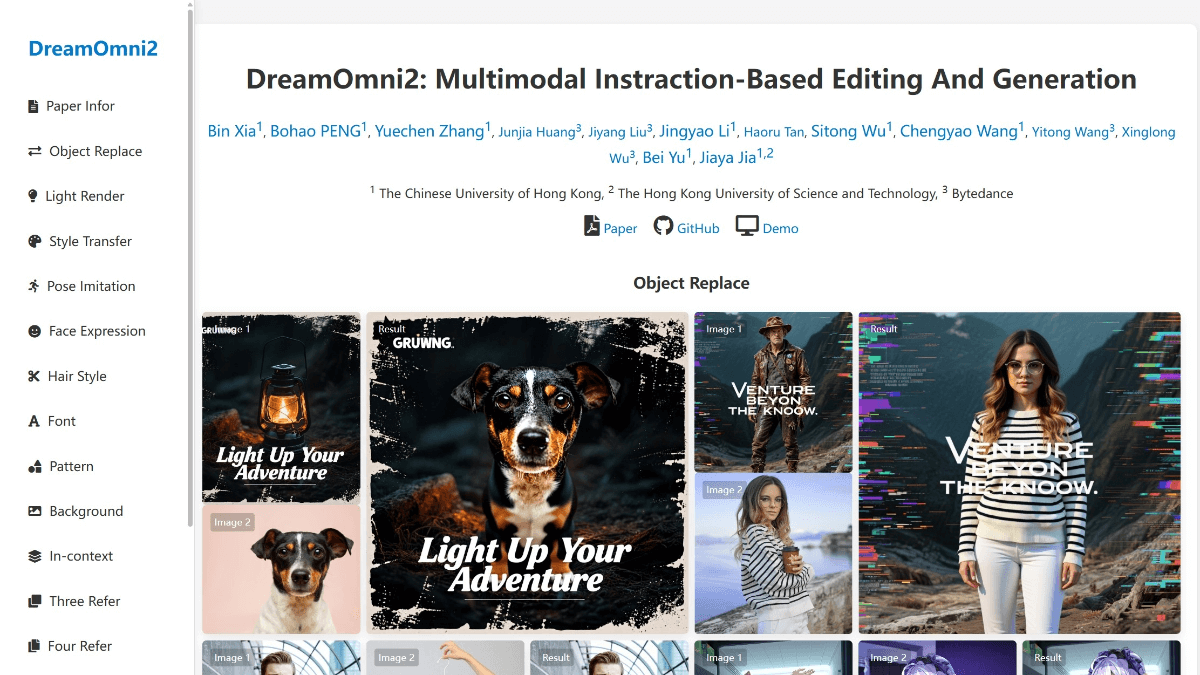
DreamOmni2 - 港科大开源的多模态AI图像编辑与生成模型DreamOmni2是港科大贾佳亚团队开源的多模态AI图像编辑与生成模型。能同时处理文本和图像指令,支持多张参考图,为创作者提供更灵活的创作方式。模型采用三阶段数据合成流程进行训练,联合训练生成/编辑...最新AI资源9个月前053.3K
SongBloom - 腾讯联合港中文、南大开源的歌曲生成模型SongBloom是腾讯AI Lab联合香港中文大学(深圳)与南京大学研发的开源歌曲生成模型,解决AI音乐生成中的“塑料感”问题,实现高质量、结构完整的歌曲生成。只需输入10秒参考音频和对应歌词,即可...最新AI资源10个月前053K
PaperBanana - 北大与谷歌联合开源的AI学术插图自动生成框架PaperBanana是北大与谷歌团队联合开源的AI学术插图自动生成框架,专门解决科研人员绘制方法示意图和统计图表的痛点。框架通过五个智能体协作(检索、规划、造型、渲染和批评),实现从文本描述到Neu...最新AI资源6个月前053K
UniPixel - 香港理工、腾讯、中科院等开源的像素级多模态模型UniPixel是香港理工大学、腾讯、中国科学院和vivo等机构联合提出的新型多模态模型,实现像素级视觉语言理解。通过统一对象指代和分割能力,支持多种细粒度任务,如图像分割、视频分割、区域理解以及Pi...最新AI资源10个月前052.9K
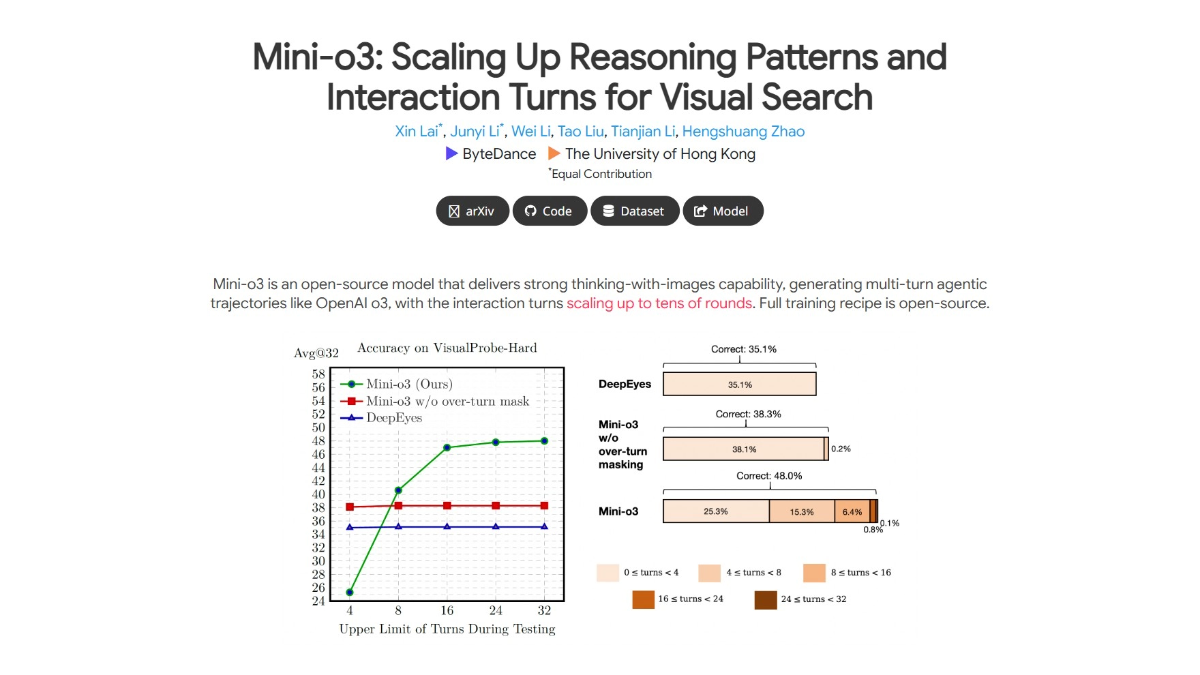
Mini-o3 - 字节、港大联合开源的视觉推理模型Mini-o3是字节跳动和香港大学联合推出的开源模型,专注于解决复杂视觉搜索问题。模型具备强大的多轮交互推理能力,能通过深度探索和试错定位目标。最新AI资源11个月前052.9K
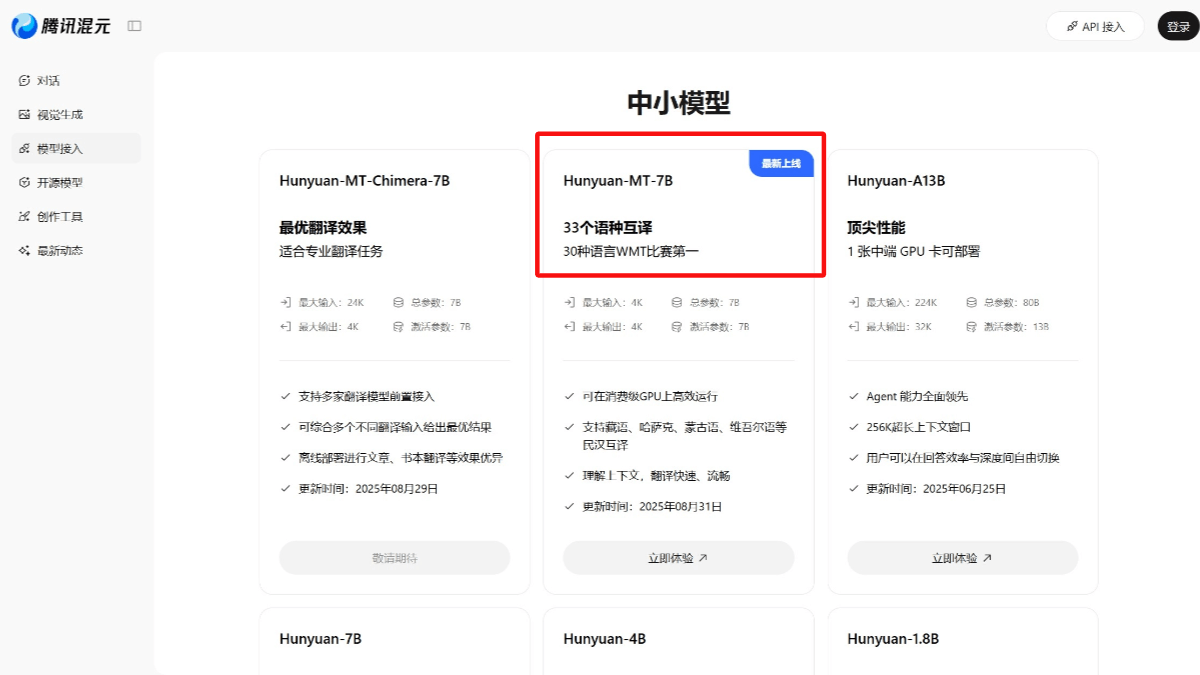
Hunyuan-MT-7B - 腾讯混元开源的轻量级翻译模型Hunyuan-MT-7B 是腾讯混元团队推出的轻量级翻译模型,参数量为70亿,支持33个语种及5种民汉语言/方言的互译,包括粤语、维吾尔语、藏语等。在国际计算语言学协会(ACL)WMT2025比赛中...最新AI资源11个月前052.8K
Chroma 1.0 - FlashLabs开源的全球首个实时端到端语音对话模型Chroma 1.0是FlashLabs发布的全球首个开源的实时端到端语音对话模型,兼具低延迟交互、高保真个性化语音克隆和强对话能力。通过紧密耦合语音理解与生成,采用1:2文本-音频token调度策略...最新AI资源6个月前052.7K
rStar2-Agent - 微软开源的高效AI推理模型rStar2-Agent是微软开源的先进的人工智能数学推理模型,在AIME24测试中达到80.6%的准确率,展现出强大的数学问题解决能力。模型具备科学推理能力,在GPQA-Diamond基准测试中达到...最新AI资源11个月前052.6K
DeepSearchQA - 谷歌开源的AI研究Agent测试基准DeepSearchQA是谷歌开源的AI研究Agent测试基准,专门用于评估智能体在复杂多步查询任务中的表现。包含900个手工设计的"因果链"任务,覆盖17个领域,要求AI像人类研究员一样通过多步骤推...最新AI资源8个月前052.6K
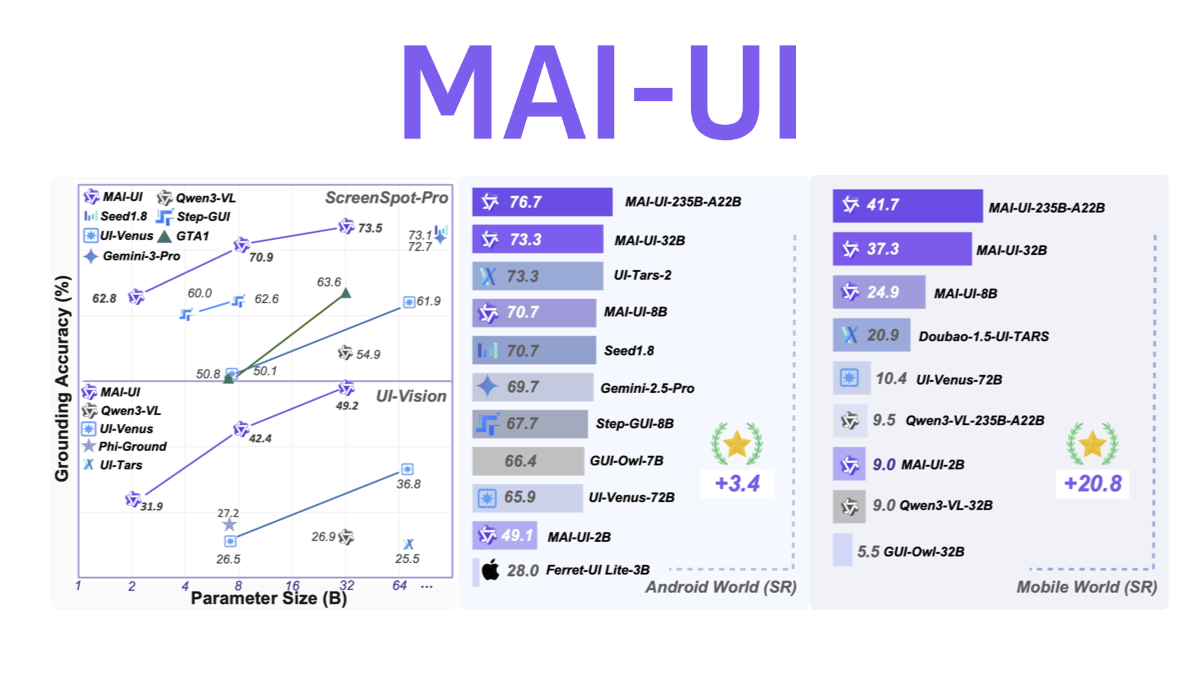
MAI-UI - 阿里通义实验室开源的通用GUI智能体基座模型MAI-UI是阿里巴巴通义实验室开源的通用GUI智能体基座模型,具备跨应用操作、模糊语义理解、主动用户交互和多步骤流程协调四大能力。采用端云协同架构,轻量模型驻守设备处理日常任务,复杂任务可调用云端大...最新AI资源7个月前052.6K
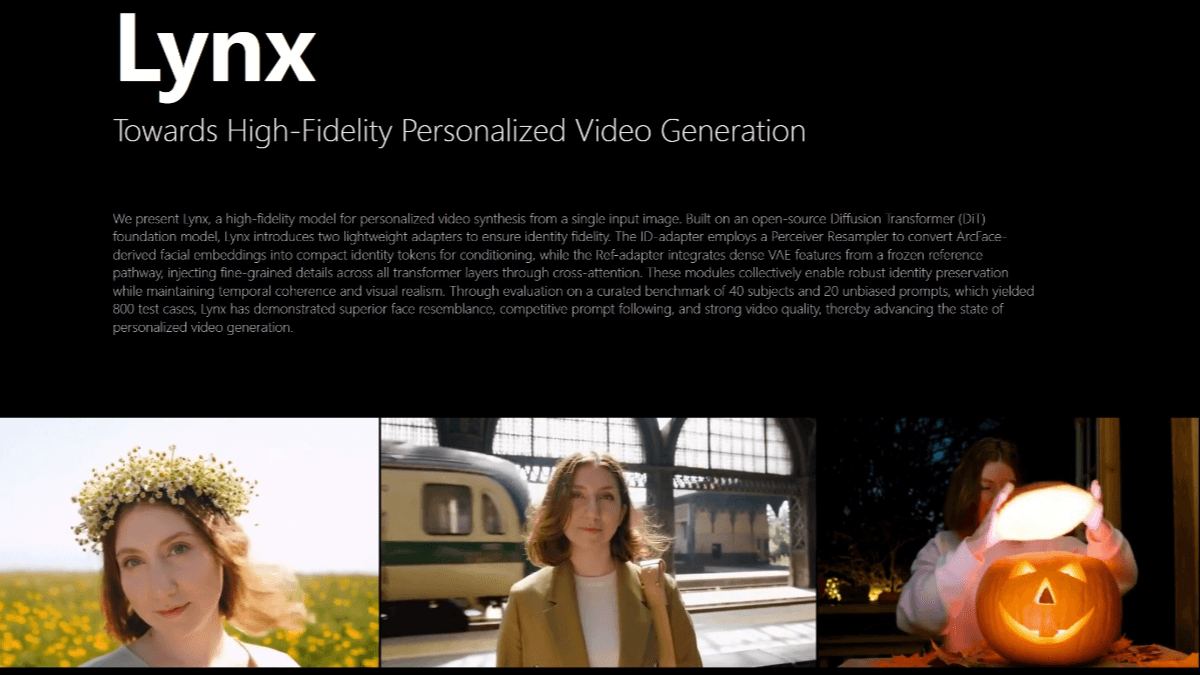
Lynx - 字节跳动开源的高保真视频生成模型Lynx 是字节跳动开源的高保真个性化视频生成模型,仅需单张人像照片,能生成身份一致的视频。基于扩散 Transformer(DiT)基础模型构建,引入 ID-adapter 和 Ref-adapte...最新AI资源10个月前052.5K
问小白o4 - 问小白推出的并行思考模型,同时开启8条思考路径问小白o4是创新的并行思考模型,能同时开启8条思考路径,从多角度分析问题并自动筛选出最优解。模型融合先进的Long-CoT强化学习和过程奖励学习技术,具备强大的深度推理能力,且在复杂任务中表现出色。最新AI资源11个月前052.4K
美间:在线软装(家装)设计工具,快速生成设计方案,软装辅助AI工具箱综合介绍 美间 是一个专注于家居设计和营销谈单的在线平台。该网站提供丰富的设计素材、软装和提案PPT模板、海报模板等,帮助设计师和业主快速生成高质量的设计方案。美间的在线软装设计工具可以在短短10秒内...最新AI资源# AI图像编辑# AI生成演示文稿/PPT1年前052.2K
Qwen3-VL-Reranker - 阿里巴巴推出的多模态重排序模型Qwen3-VL-Reranker是阿里巴巴推出的多模态重排序模型,专门用于提升跨模态检索的精准度。与Qwen3-VL-Embedding协同工作:前者负责快速召回候选结果,后者通过深度跨模态交互(如...最新AI资源7个月前052.2K
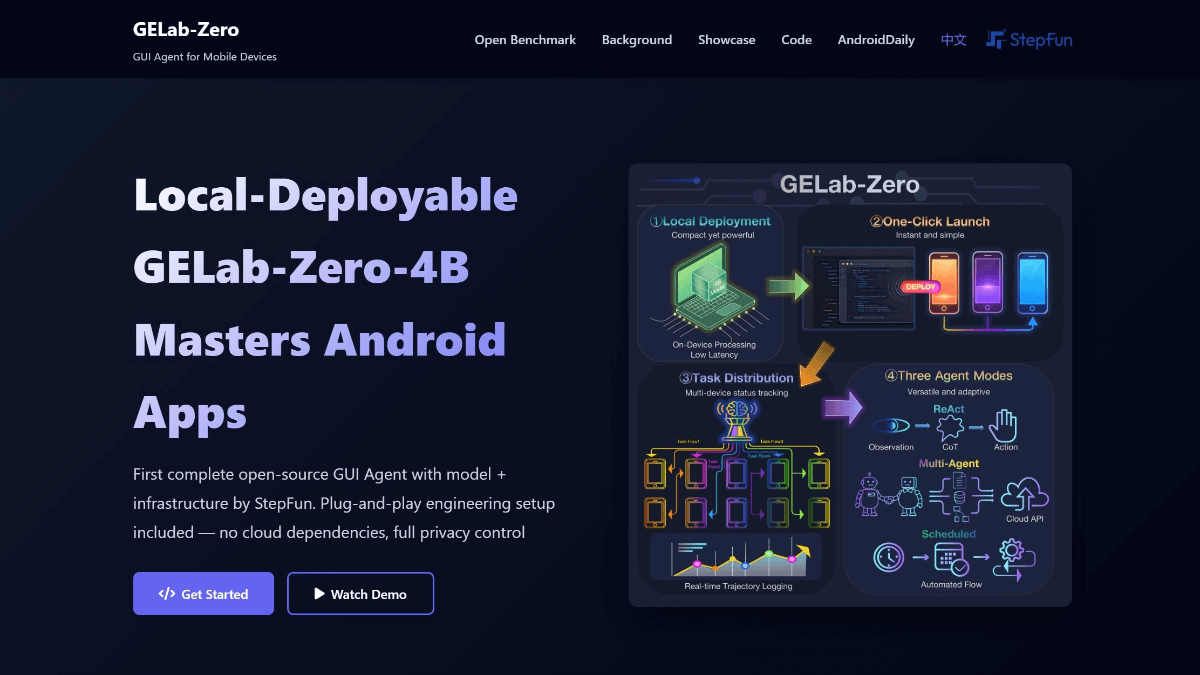
GELab-Zero - 阶跃团队开源的端侧多模态GUI Agent模型GELab-Zero是阶跃团队开源的端侧多模态GUI Agent模型,基于Qwen3-VL-4B-Instruct基座模型构建,参数量为4B。能识别UI元素并执行点击、滑动等操作,支持跨应用任务处理...最新AI资源8个月前052.2K
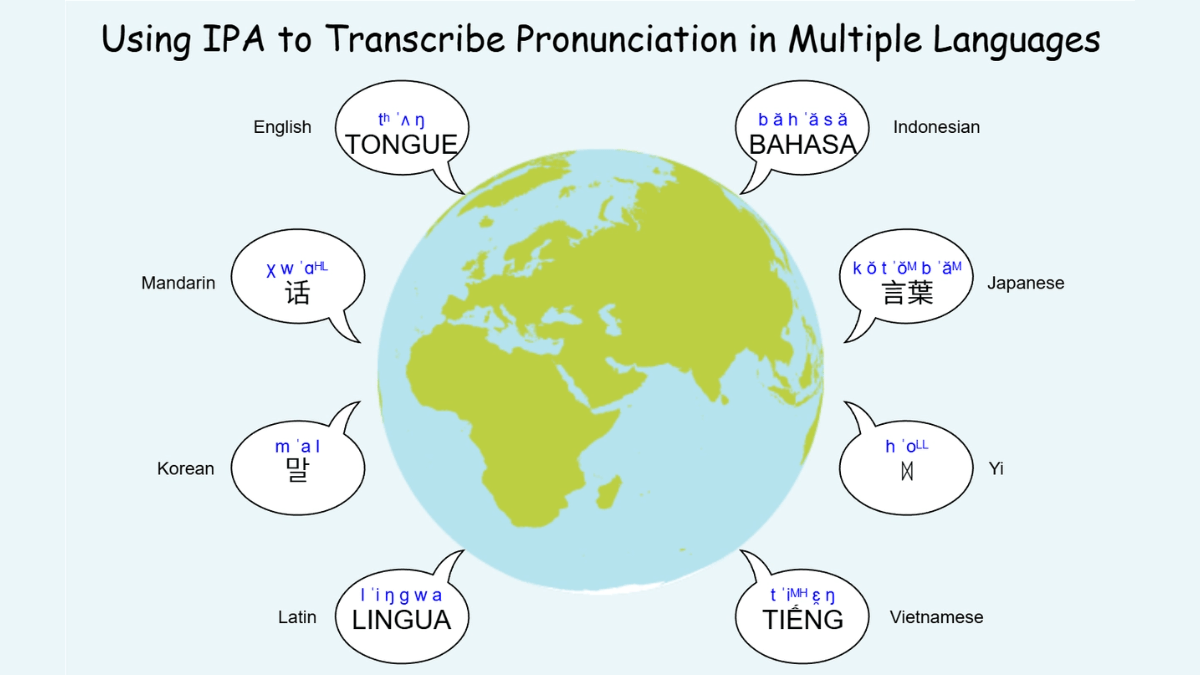
DiaMoE-TTS - 清华联合巨人网络开源的多方言语音合成框架DiaMoE-TTS 是清华大学和巨人网络联合开源的多方言语音合成框架,基于国际音标(IPA),解决方言数据稀缺、正字法不一致和音系变化复杂等问题。通过统一的 IPA 前端标准化音素表示,消除跨方言差...最新AI资源10个月前052.2K
Zen Browser - 基于Firefox内核的开源AI网页浏览器Zen Browser是基于Firefox内核的开源浏览器,主打简洁高效的浏览体验,核心特色是垂直标签栏和工作区隔离功能。采用侧边栏设计,能清晰展示50+个标签页的完整标题,支持多窗口分屏浏览。最新AI资源7个月前051.9K
DeepSeek-V3.2-Exp - DeepSeek最新开源的实验性AI模型DeepSeek-V3.2-Exp是DeepSeek开源的实验性AI模型,通过引入DeepSeek Sparse Attention(DSA)机制,显著提升长文本处理的效率。模型基于DeepSeek...最新AI资源10个月前051.9K
MedASR - 谷歌开源的医疗语音识别模型MedASR是谷歌开源的1.05亿参数医疗语音识别模型,在5000小时脱敏临床语料上微调,针对药品、剂量、解剖术语优化,内置6-gram医学语言模型,在私有放射科数据集RAD-DICT上词错率仅4.6...最新AI资源7个月前051.7K
openPangu-VL-7B - 华为开源的7B参数多模态模型openPangu-VL-7B是华为开源的7B参数规模的多模态模型,专为昇腾端侧设备优化设计。模型在视觉定位、OCR识别、文档理解等任务中表现出色,支持实时推理(5FPS),单卡延迟仅160毫秒。最新AI资源7个月前051.6K
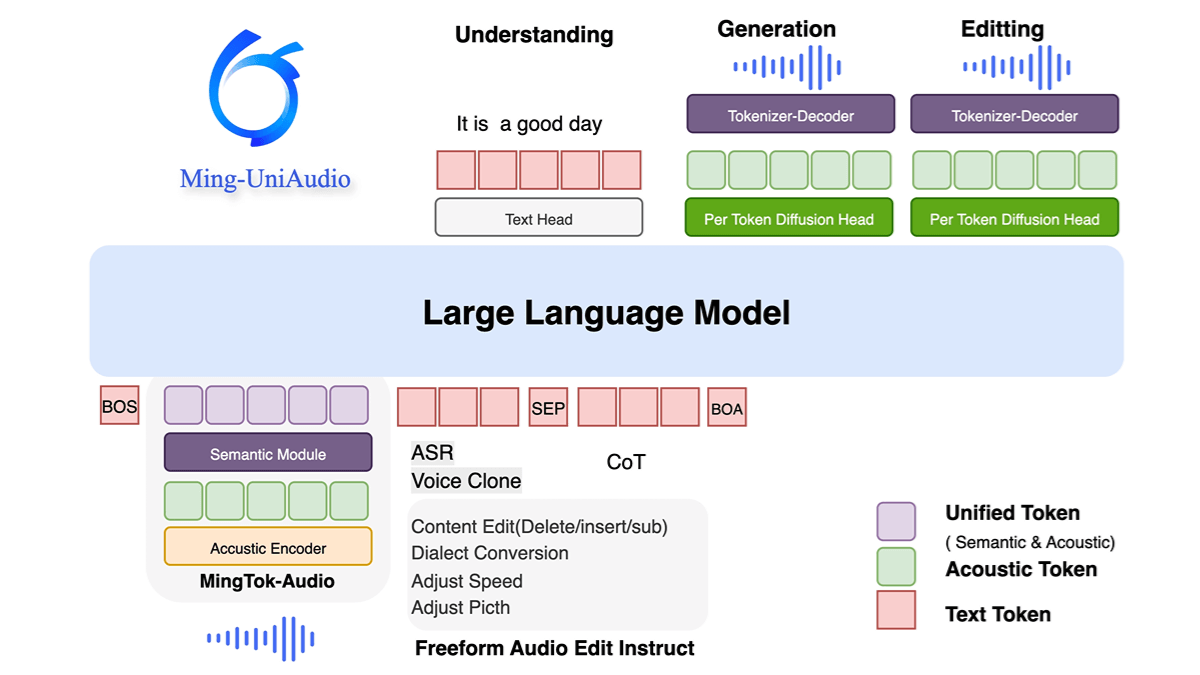
Ming-UniAudio - 蚂蚁开源的统一音频多模态生成模型Ming-UniAudio是蚂蚁集团开源的统一音频多模态生成模型,支持文本、音频、图像和视频的混合输入与输出。采用多尺度Transformer和混合专家(MoE)架构,通过模态感知路由机制高效处理跨模...最新AI资源10个月前051.6K
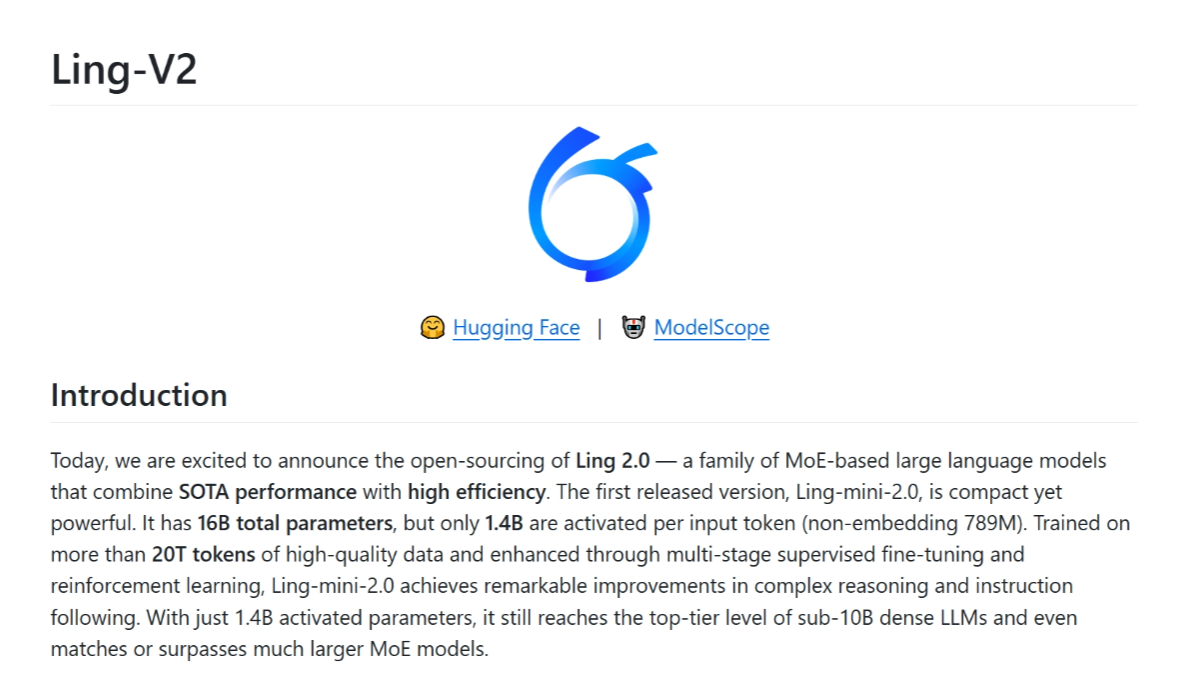
Ling-V2 - 蚂蚁百灵开源的MoE架构语言模型系列Ling-V2 是蚂蚁百灵团队推出的基于 MoE 架构的大型语言模型家族,首个版本 Ling-mini-2.0 拥有 160 亿总参数,每个输入标记仅激活 14 亿参数。最新AI资源10个月前051.4K
GLM-4.7-Flash - 智谱开源的混合专家架构语言模型GLM-4.7-Flash是智谱开源的混合专家架构语言模型,参数规模为30B,激活参数量3B,上下文窗口达200K,最大输出令牌为128K。在编程能力上表现出色,SWE-bench验证集分数达59.2...最新AI资源6个月前051.3K
MOVA - 创智学院联合模思智能开源的端到端音视频生成模型MOVA(MOSS-Video-and-Audio) 是上海创智学院 OpenMOSS 团队联合模思智能(MOSI)开源的端到端音视频生成模型,是中国首个高性能开源音视频模型。突破了传统"先画面后配音...最新AI资源6个月前051.1K
GPT-5-Codex - OpenAI推出的最强编程模型GPT-5-Codex 是 OpenAI 推出的强大的编程优化模型,基于 GPT-5 进一步强化,专为软件工程师设计。模型能快速生成高质量代码,支持多种编程语言,且能优化现有代码提升性能。最新AI资源11个月前051.1K
FunctionGemma - 谷歌开源专为函数调用优化的轻量级AI模型FunctionGemma是谷歌推出的专为函数调用优化的轻量级AI模型,基于2.7亿参数的Gemma 3基础模型开发,可在手机、浏览器等设备上实时将自然语言转换为可执行API指令。核心特点是支持本地离...最新AI资源7个月前050.9K
AgentCPM-Report - 清华联合面壁智能等开源的深度调研智能体工具AgentCPM-Report 是清华大学自然语言处理实验室、中国人民大学、面壁智能与 OpenBMB 开源社区联合研发的深度调研智能体工具。基于 8 亿参数的模型,通过深度检索和推理,能生成万字长篇...最新AI资源6个月前050.9K
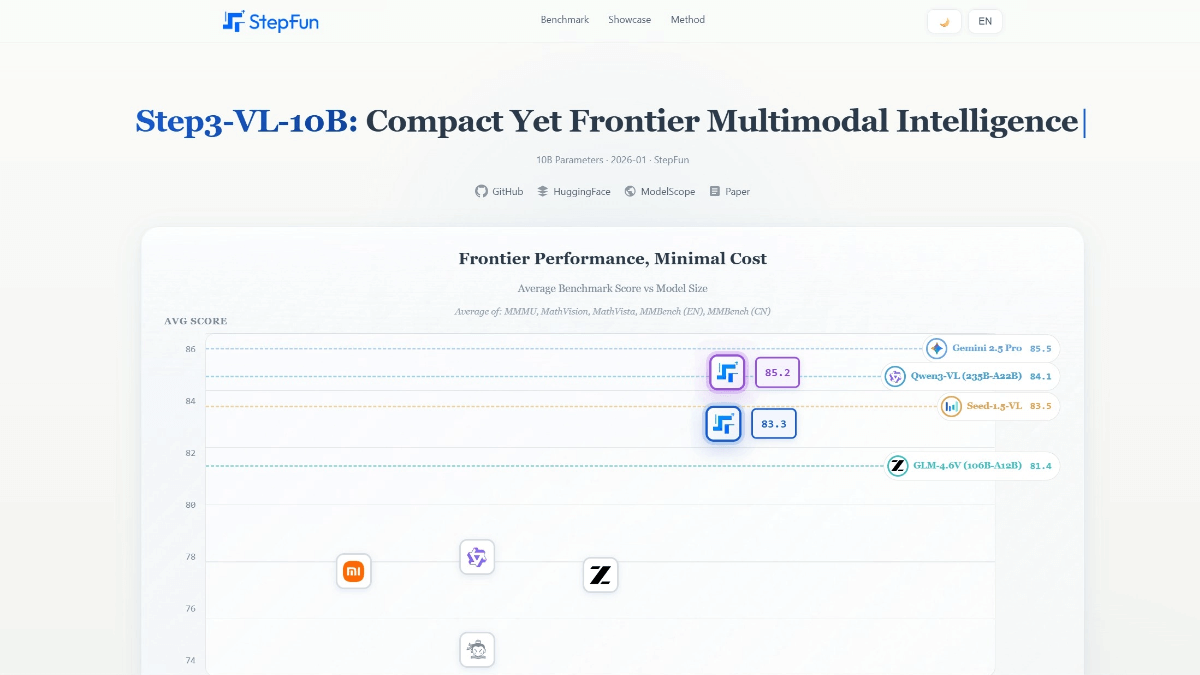
Step3-VL-10B - 阶跃星辰开源的100亿参数多模态AI模型Step3-VL-10B是阶跃星辰团队开源的100亿参数多模态AI模型,核心突破在于以轻量化设计实现顶级性能。模型通过统一预训练策略(1.2T多模态令牌数据)和创新的并行协同推理技术(PACORE...最新AI资源6个月前050.9K
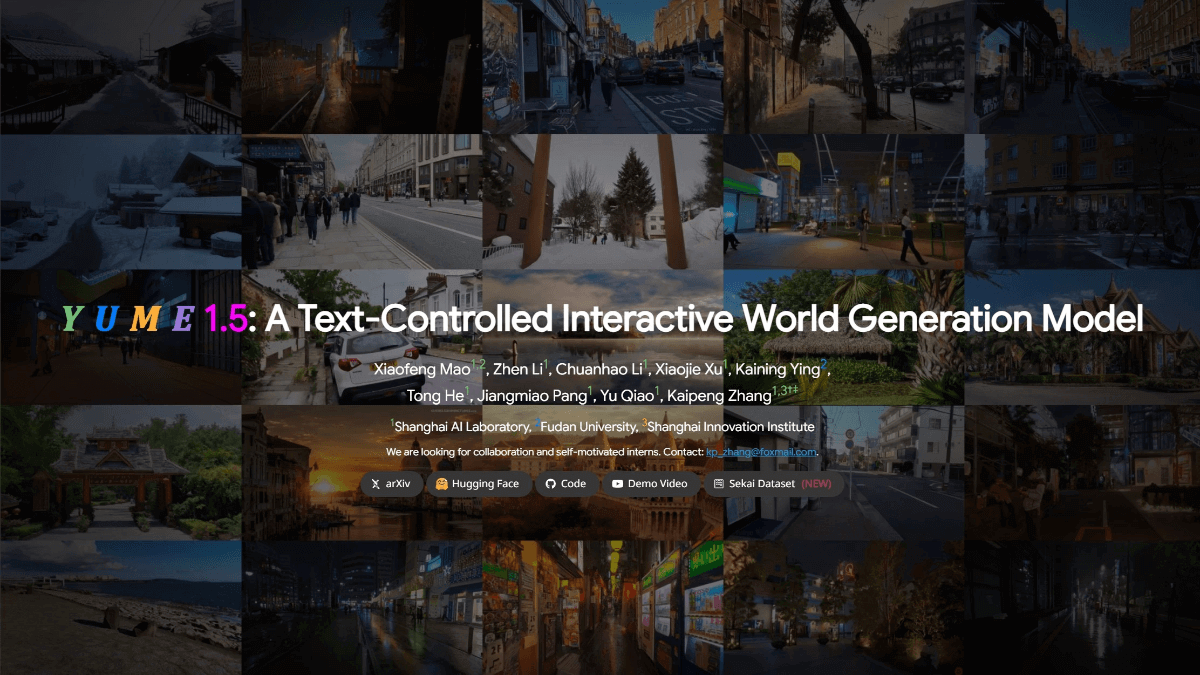
Yume1.5 - 上海AI Lab联合复旦大学开源的交互式世界生成模型Yume1.5是开源的交互式世界生成模型,由上海人工智能实验室、复旦大学、上海创新研究院联合开发,能实现实时交互渲染(单卡12 FPS)。采用了联合时空通道建模(TSCM)技术,即使上下文长度增加也能...最新AI资源7个月前050.8K
聆音EchoCare - 香港科学院开源的超声基座大模型聆音EchoCare是中国科学院香港创新研究院人工智能与机器人创新中心(CAIR)研发的超声基座大模型,基于全球最大的超声影像数据集(超450万张图像)训练而成,覆盖多中心、多地区、多人种及50余个人...最新AI资源10个月前050.6K
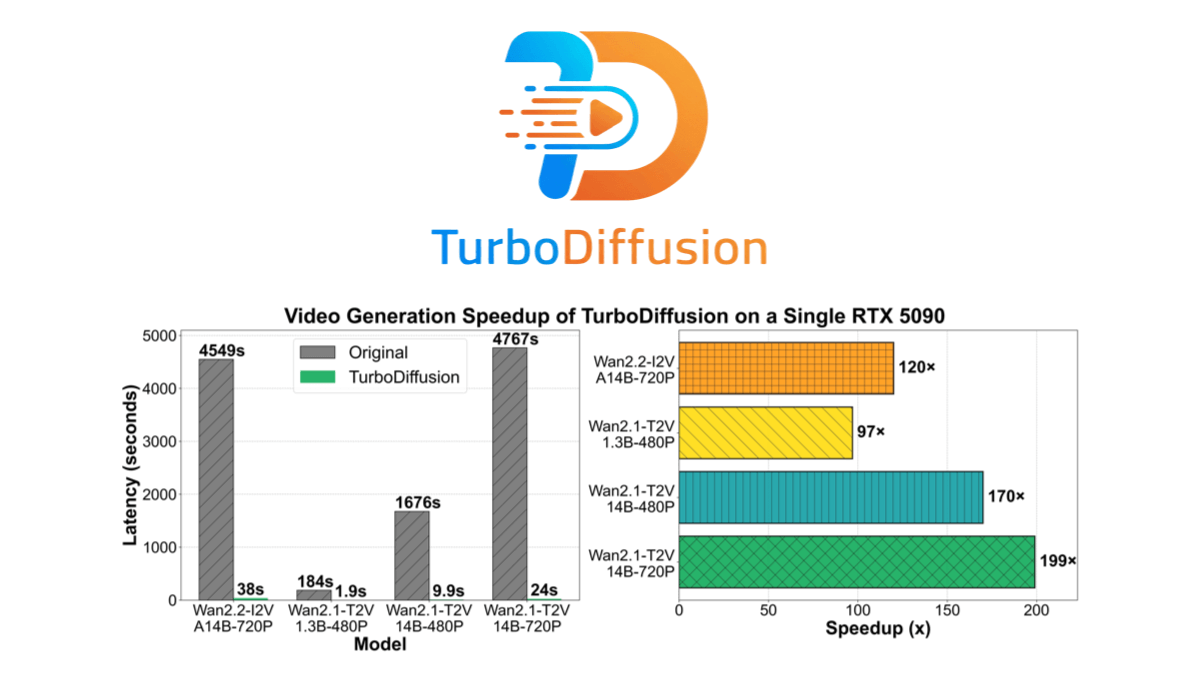
TurboDiffusion - 生数科技联合清华等开源的视频生成加速框架TurboDiffusion是清华大学、生数科技和加州大学伯克利分校联合开源的视频生成加速框架,能在保持画质几乎无损的情况下,将视频生成速度提升100-200倍。通过稀疏线性注意力、采样步数蒸馏和8位...最新AI资源7个月前050.4K
GLM-TTS - 智谱AI推出的开源工业级语音合成系统GLM-TTS 是智谱推出的开源工业级语音合成系统,具备强大的语音合成能力。采用两阶段生成架构:第一阶段将文本转换为语音令牌序列,第二阶段将令牌序列转换为高质量音频。系统支持仅用3秒语音样本即可完成音...最新AI资源8个月前050.4K
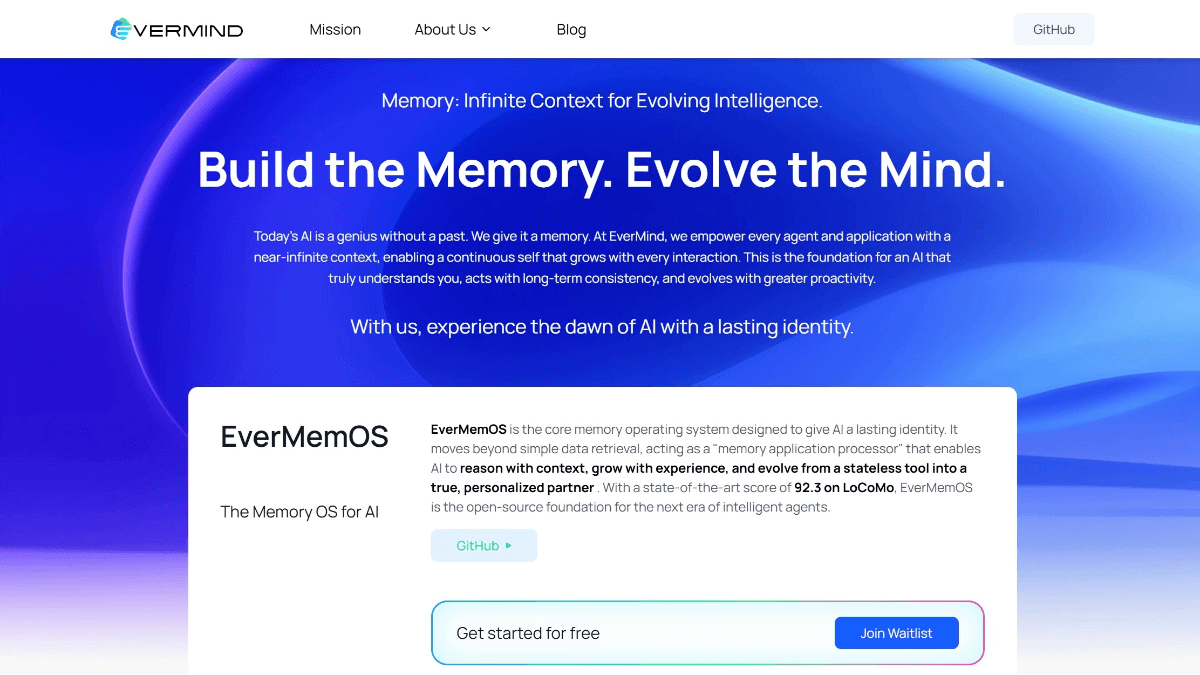
EverMemOS - 盛大团队推出的开源长期记忆操作系统EverMemOS是陈天桥领导的盛大团队推出的开源长期记忆操作系统,专为AI智能体设计,解决大语言模型因固定上下文窗口导致的记忆断裂问题。系统基于人类大脑记忆机制,采用四层架构(代理层、记忆层、索引层...最新AI资源9个月前050.4K
Granite-Docling-258M - IBM开源的视觉语言模型Granite-Docling-258M 是 IBM 推出的超紧凑开源视觉语言模型,专为高效文档转换设计。模型能将文档转换为机器可读格式,同时完整保留布局、表格、公式等元素。最新AI资源10个月前050.3K
LingBot-Depth - 蚂蚁灵波科技开源的高精度空间感知模型LingBot-Depth是蚂蚁灵波科技开源的高精度空间感知模型,专门解决机器人在透明玻璃、反光物体等复杂场景中的深度识别难题。模型通过创新的"掩码深度建模"技术,在RGB图像基础上预测缺失的深度值最新AI资源6个月前050.3K
T5Gemma 2 - 谷歌开源的新一代编码器-解码器模型T5Gemma 2 是谷歌开源的新一代编码器 - 解码器模型,基于 Gemma 3 架构升级而来,具备多模态和长上下文处理能力。支持文本和图像等多种数据类型,能处理超长上下文(最高 128K),在生成...最新AI资源7个月前050.3K
RealVideo - 智谱 AI 开源的实时流式视频生成系统RealVideo 是智谱 AI 开源的实时流式视频生成系统,能在 2 至 3 秒内快速生成自然流畅的视频回应。用户只需上传一张照片并输入文字,系统能生成对应的语音和视频,实现与 AI 角色的实时对话...最新AI资源8个月前050.3K
LazyCraft - 开源AI Agent应用开发与管理平台,基于LazyLLM构建LazyCraft 是商汤基于开源框架 LazyLLM 构建的开源 AI Agent 应用开发与管理平台,为企业和开发者提供一站式AI应用开发解决方案。帮助开发者以低门槛、低成本快速构建和发布大模型应...最新AI资源9个月前050.2K
PromptFill - 开源的结构化提示词生成AI工具,专为AI绘画设计PromptFill是专为AI绘画设计的结构化提示词生成工具,通过可视化的“填空”交互方式,帮助用户快速构建、管理和迭代复杂的Prompt,提升AI图像生成的效率与质量。PromptFill的核心功能...最新AI资源7个月前050.1K
Depth Anything 3 - 字节跳动Seed开源的3D视觉重建模型Depth Anything 3(DA3)是字节跳动Seed团队研发开源的3D视觉重建模型。通过单一Transformer架构实现任意视角下的空间几何重建,仅需预测深度图和射线图即可还原三维场景,相比...最新AI资源8个月前050K
VoiceSculptor - 西北工业大学联合语图智能开源的音色设计模型VoiceSculptor 是西北工业大学联合多家机构开源的音色设计模型,基于 LLaSA-3B 和 CosyVoice2 开发,专注于通过自然语言指令生成多样化音色的语音合成。支持对语速、音量、基频...最新AI资源7个月前050K
Youtu-LLM - 腾讯 Youtu 团队开源的轻量级语言模型Youtu-LLM 是腾讯 Youtu 团队开源的轻量级语言模型,参数规模为 19.6 亿。专为智能体任务设计,具备强大的“原生智能体能力”,在多项任务中超越同规模甚至更大模型。最新AI资源7个月前049.9K






![FLUX.2 [klein] - Black Forest Labs 开源的轻量级图像生成与编辑模型](https://aisharenet.com/wp-content/uploads/2026/01/1768710007-1768710007-FLUX.2-klein.png)