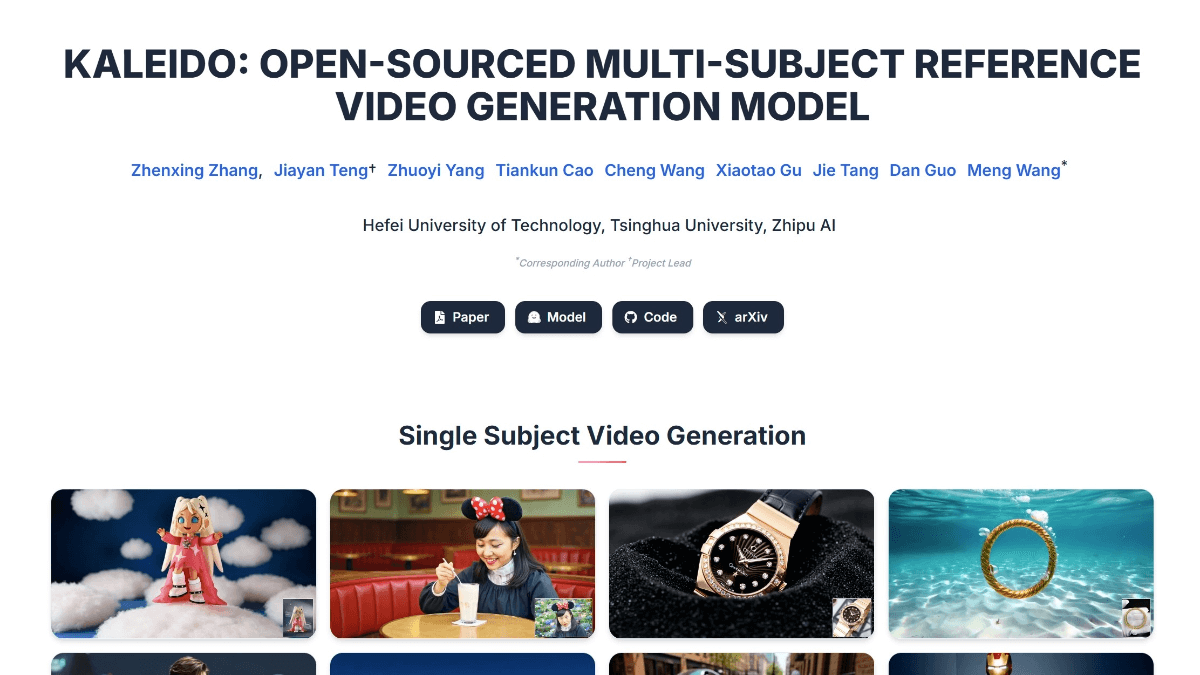
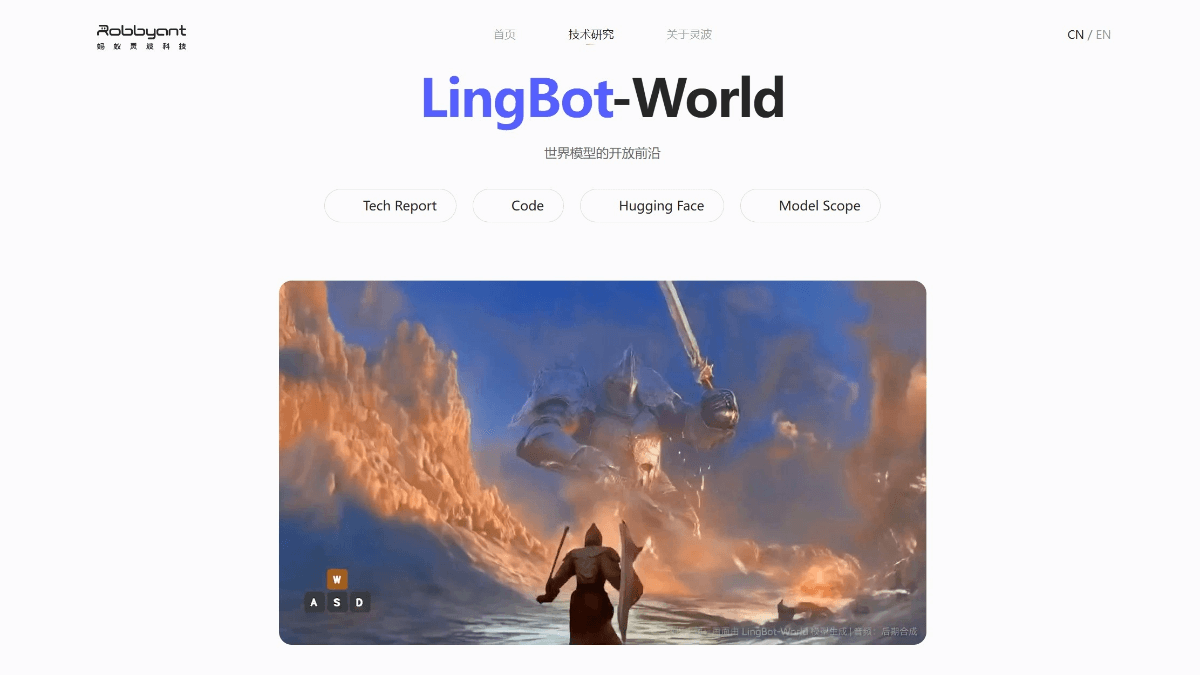
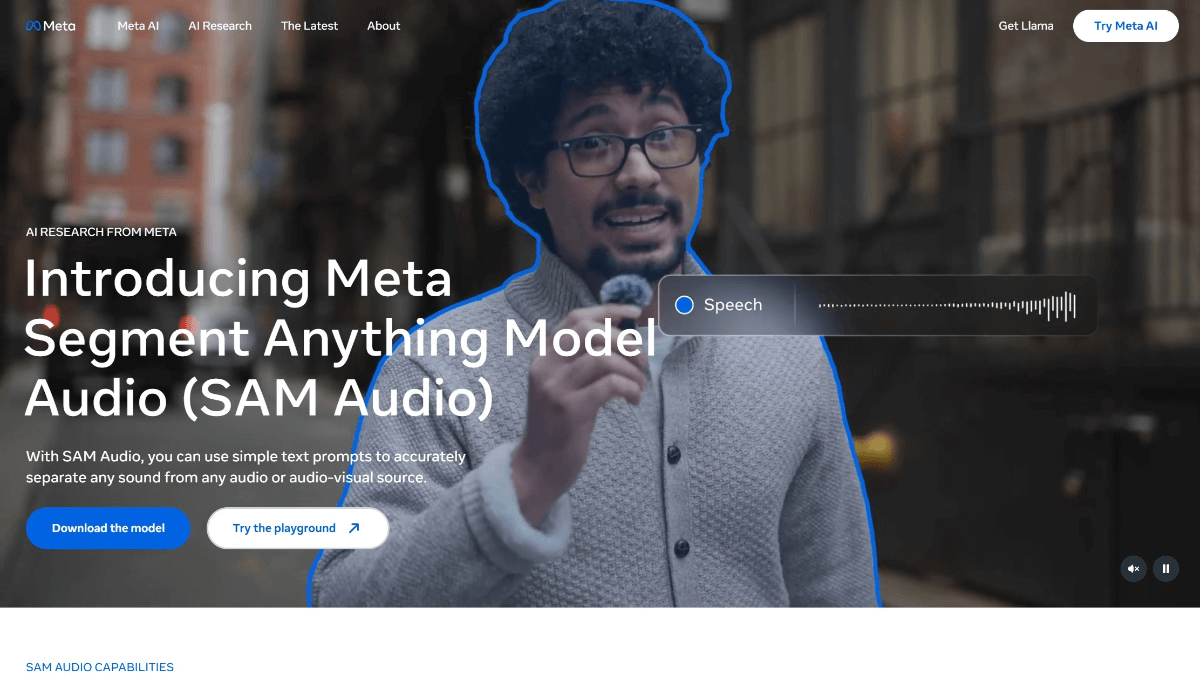
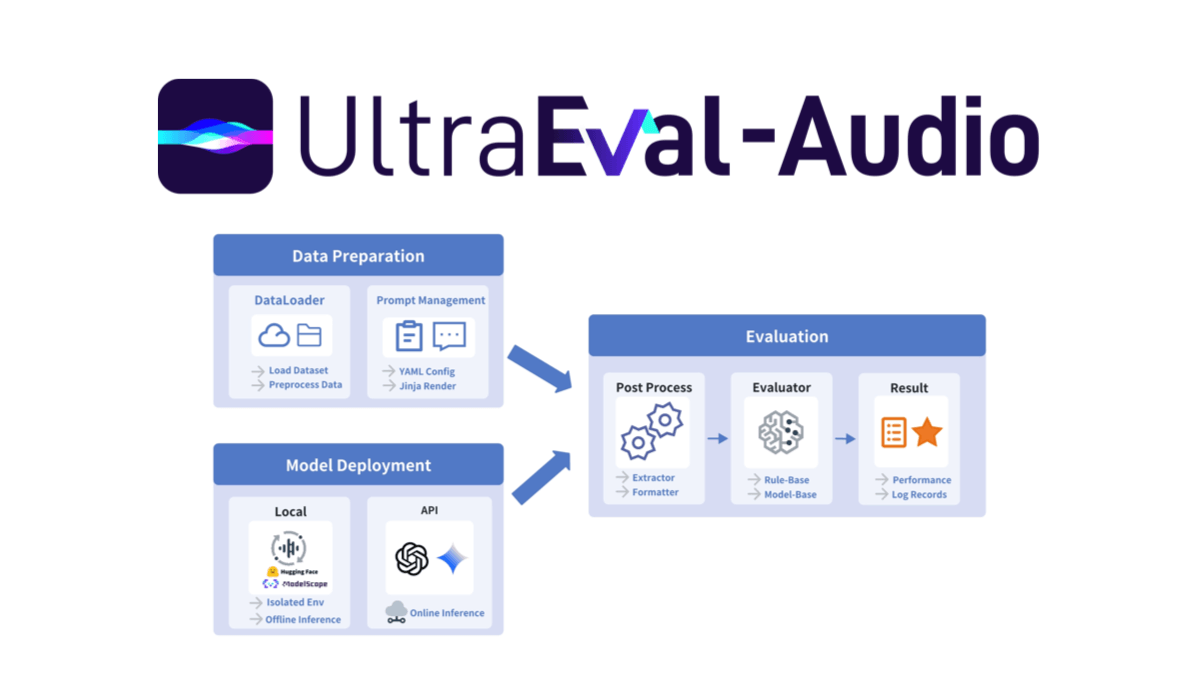
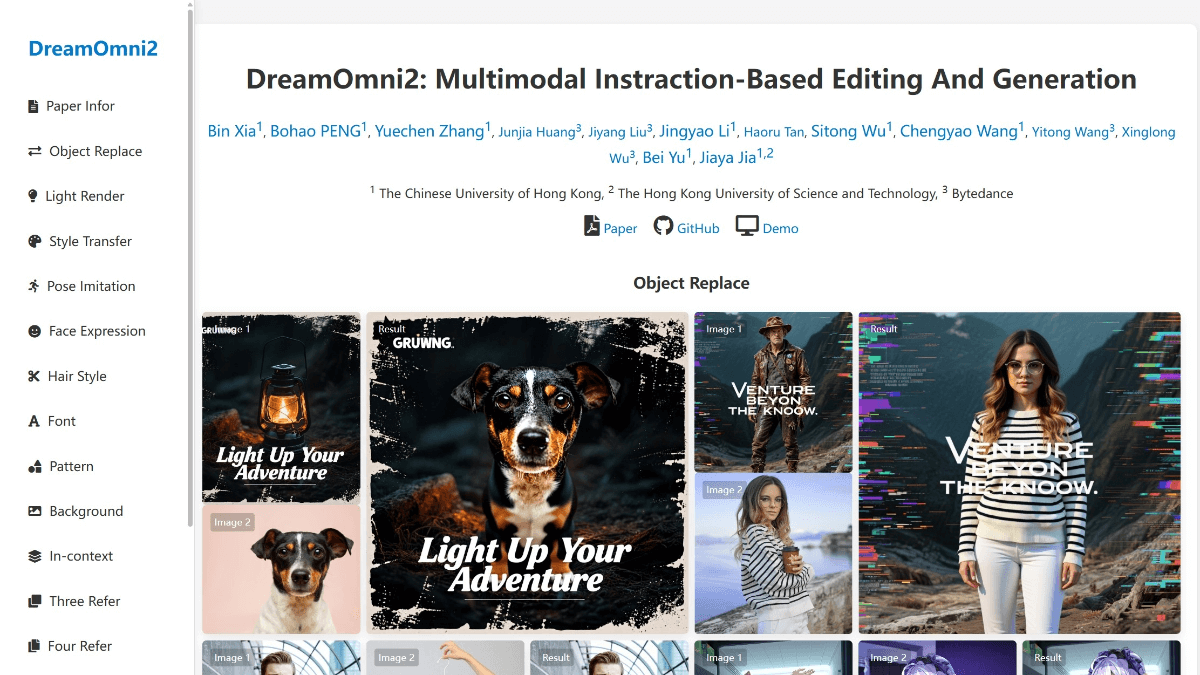
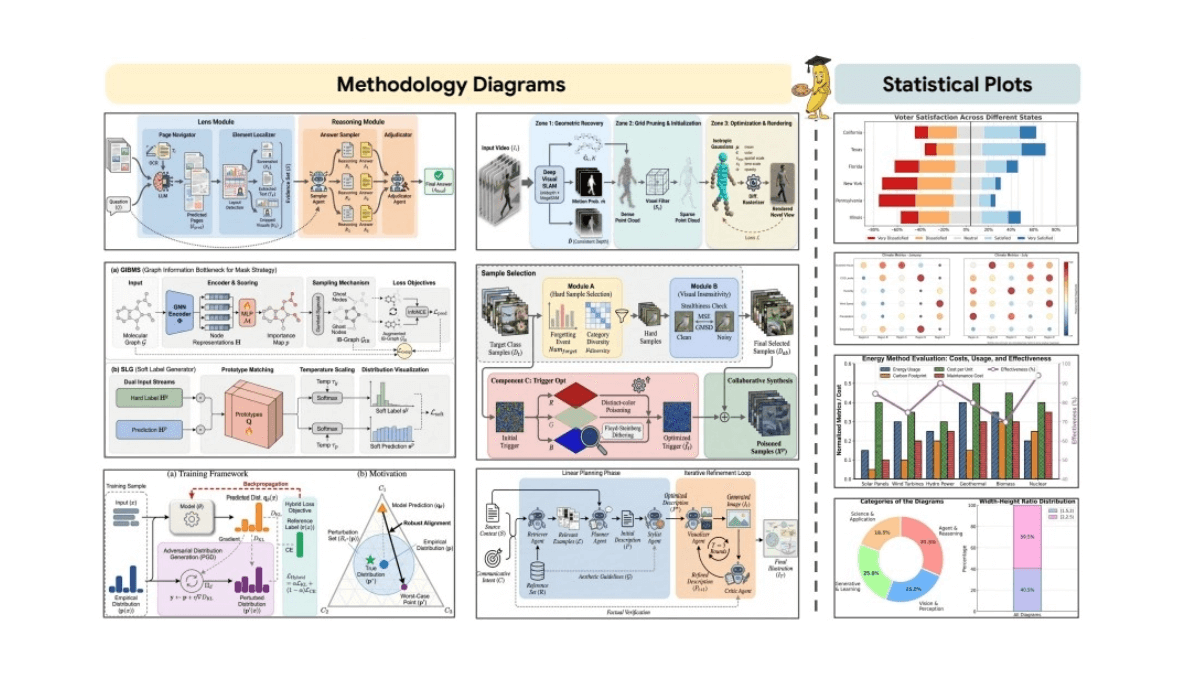
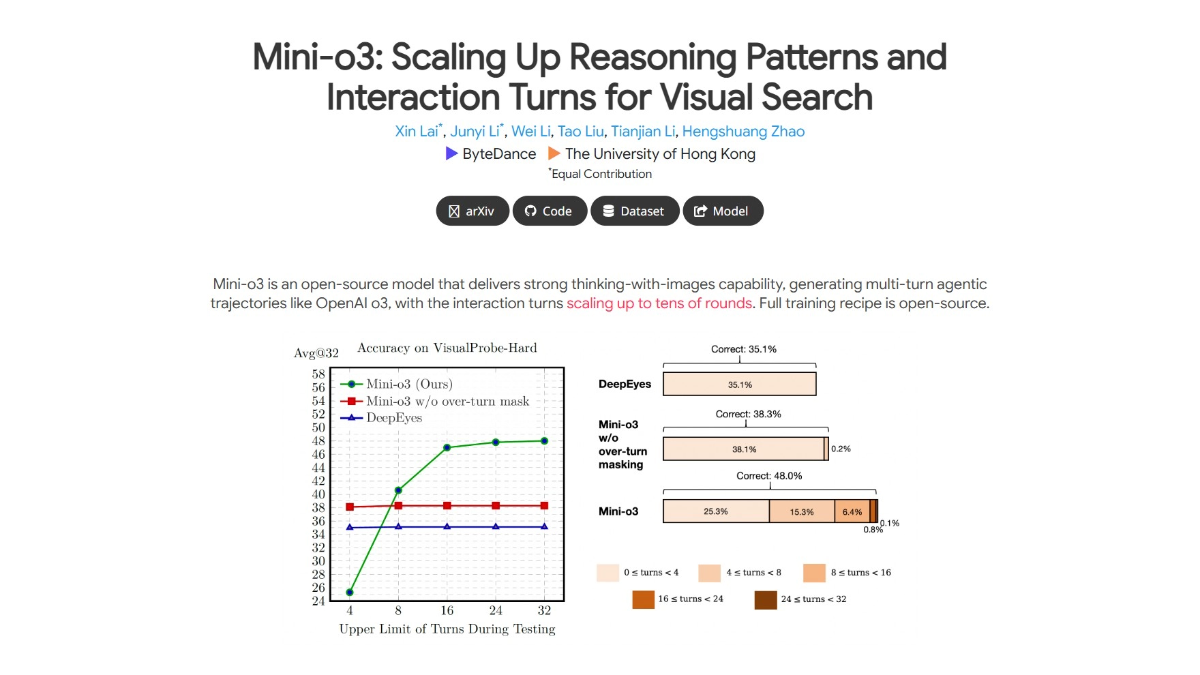
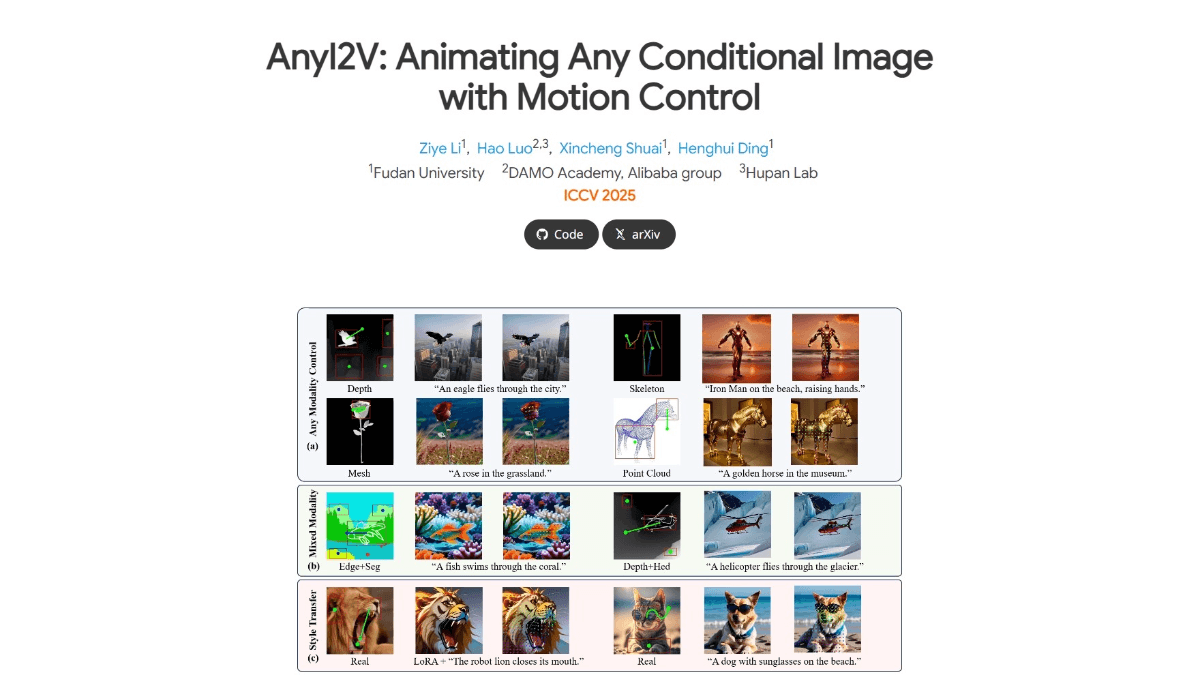
SCAIL(Studio-Grade Character Animation via In-Context Learning)は、Smart Spectrumが清華大学のLiu Yongjin教授のグループと共同で提案した、映画・テレビ用のキャラクターアニメーション生成フレームワークです。このフレームワークを通して...
Steps Deep Researchは、Steps Starが発表した効率的なAIリサーチツールで、複雑な問題のリサーチを自律的に完了し、専門的なレポートを短時間で作成することができる。このツールは、金融、コンサルティング、ヘルスケア、法律などの分野向けに設計されており、詳細な検索機能と情報統合機能により、業界レビューで優れた評価を得ている。
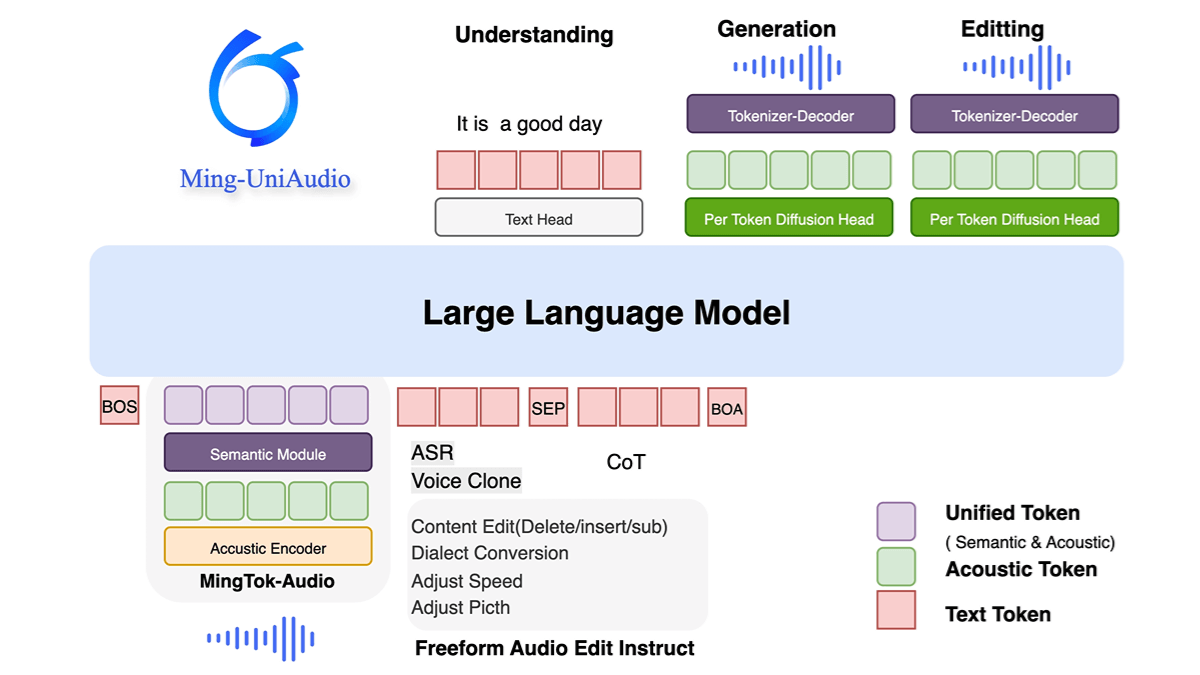
FLM-Audioは、Beijing Zhiyuan Artificial Intelligence Research InstituteとSpin Matrix、Nanyang Technological University of Singaporeが共同開発したネイティブ全二重音声対話マクロモデルで、中国語と英語の両方に対応している。ネイティブの全二重アーキテクチャを採用し、各時間ステップでリスニング、スピーキング、モノローグをマージすることができます...
SoulX-Podcastは、高品質のポッドキャストコンテンツを生成するために設計された、Soul AI Labのオープンソースの先進的な複数話者会話音声合成モデルです。SoulX-Podcastは複数ラウンドのダイアログを生成する機能を持ち、実際のポッドキャスティングシナリオでスムーズなダイアログをシミュレートできます。
Ask White o4は、8つの思考経路を同時に開き、問題を多角的に分析し、最適解を自動的にフィルタリングする革新的な並列思考モデルです。このモデルには、高度なLong-CoT強化学習とプロセス報酬学習技術が組み込まれており、強力な深層推論機能を持ち、複雑なタスクで優れたパフォーマンスを発揮します。
Zen BrowserはFirefoxカーネルをベースとしたオープンソースブラウザで、垂直タブバーやワークスペースの分離などのコア機能を備え、シンプルで効率的なブラウジング体験に焦点を当てています。サイドバーのデザインにより、50以上のタブの完全なタイトルを明確に表示でき、マルチウィンドウの画面分割ブラウジングをサポートします。






![FLUX.2 [klein] - Black Forest Labs 开源的轻量级图像生成与编辑模型](https://aisharenet.com/wp-content/uploads/2026/01/1768710007-1768710007-FLUX.2-klein.png)