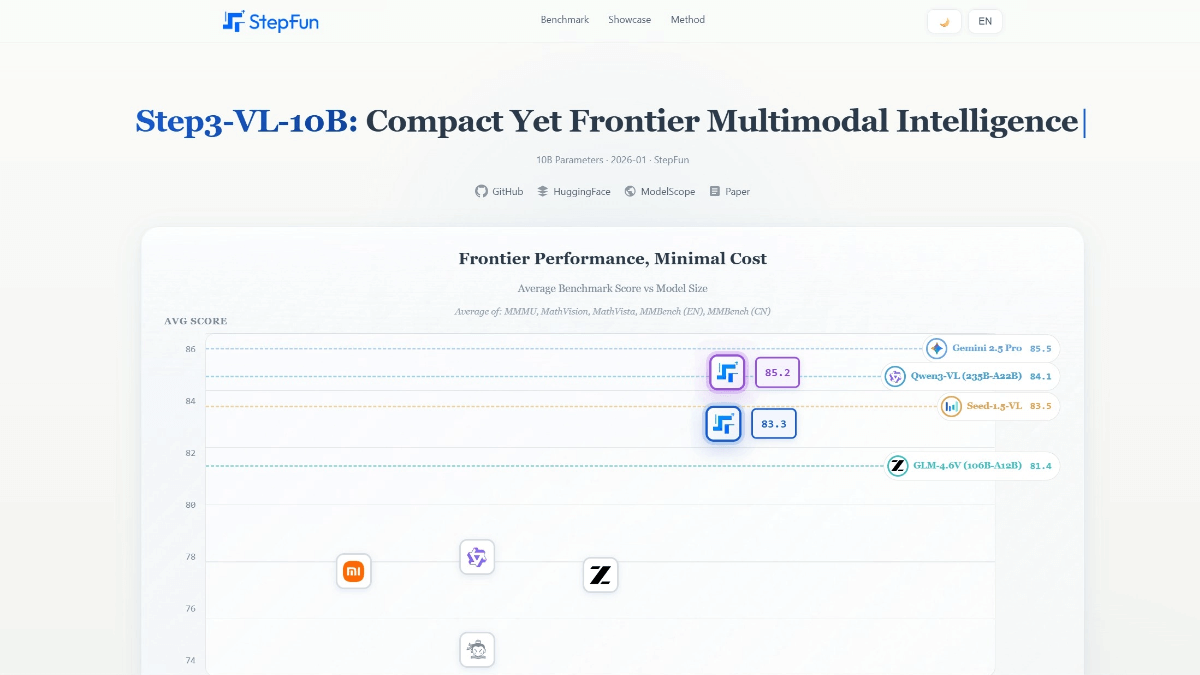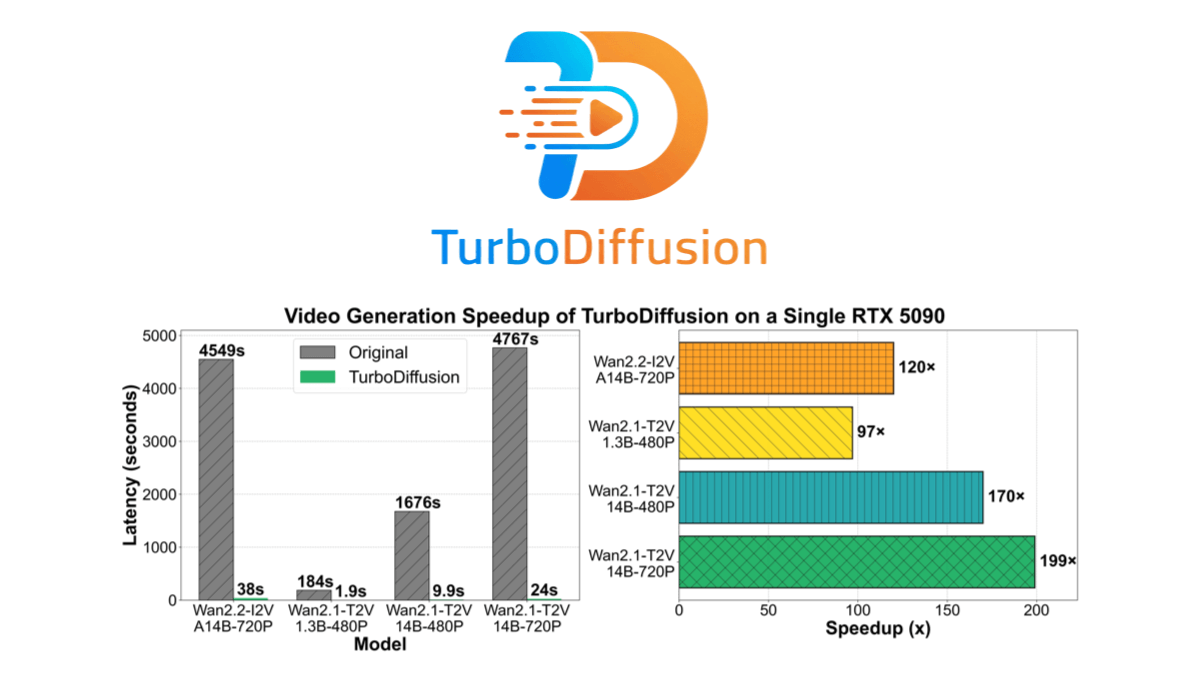
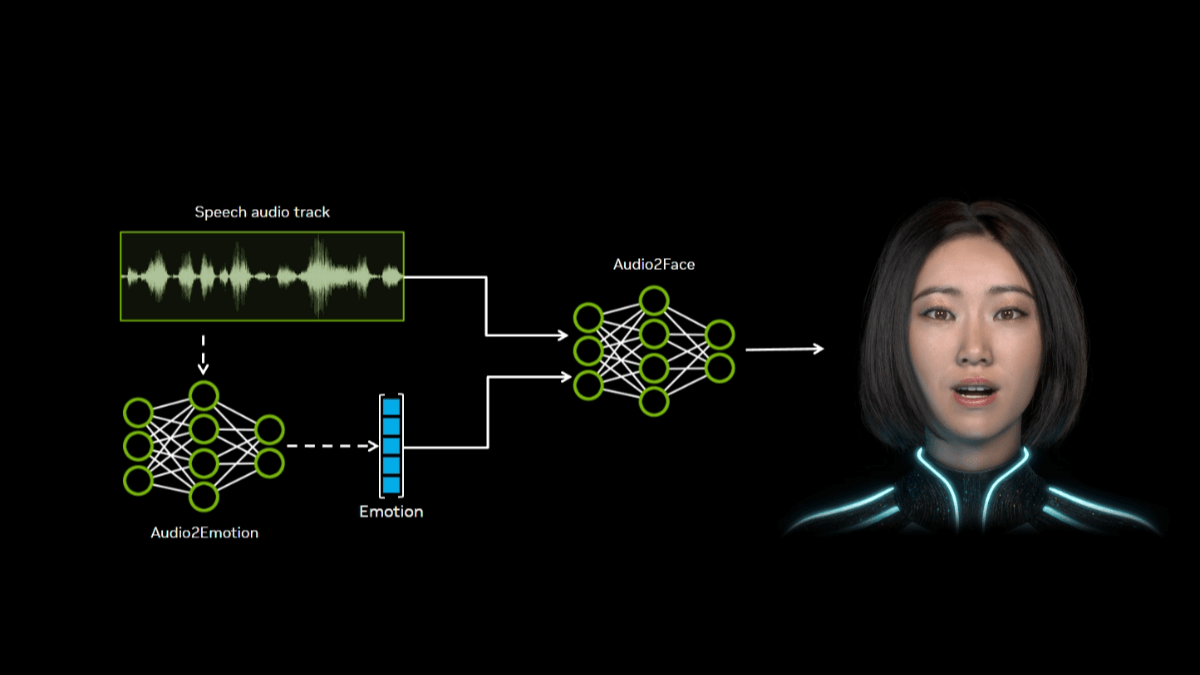
InfinityHuman: un modelo de generación humana digital de vídeo largo lanzado por Bytes en colaboración con ZJU.
InfinityHuman es un modelo comercial de generación de vídeos de personajes con series de audio de larga duración lanzado conjuntamente por ByteDance y la Universidad de Zhejiang. El modelo se basa en el audio y puede generar vídeos de personajes de alta resolución, larga duración y coherencia visual.






![FLUX.2 [klein] - Black Forest Labs 开源的轻量级图像生成与编辑模型](https://aisharenet.com/wp-content/uploads/2026/01/1768710007-1768710007-FLUX.2-klein.png)