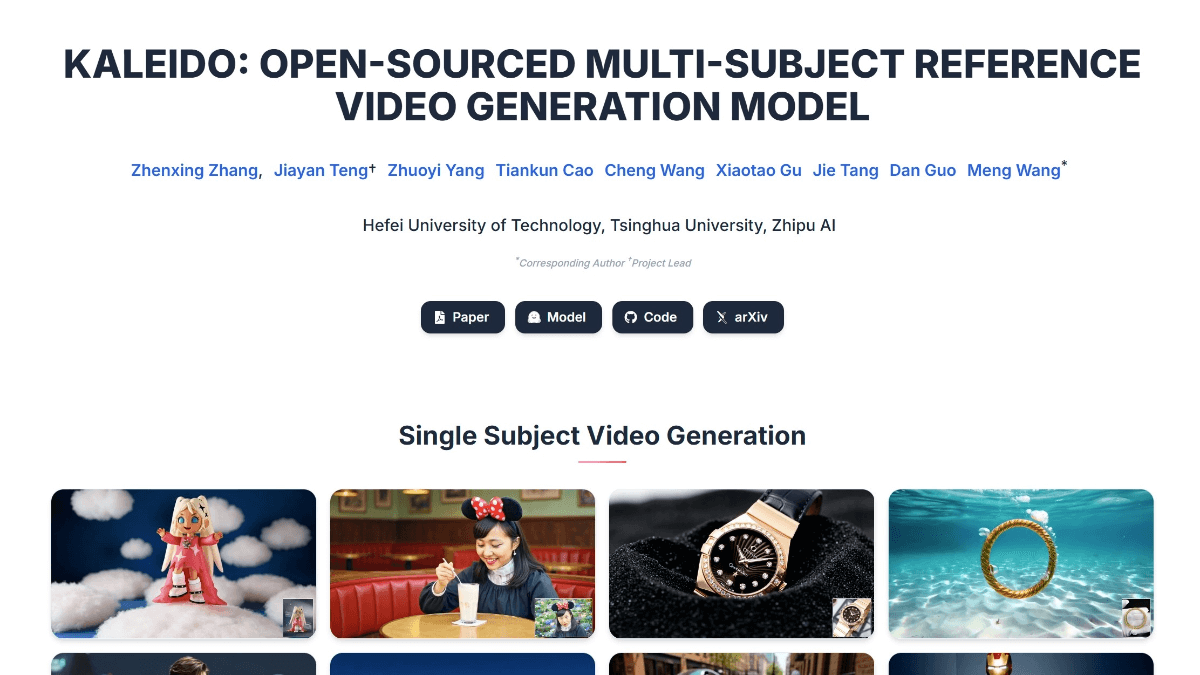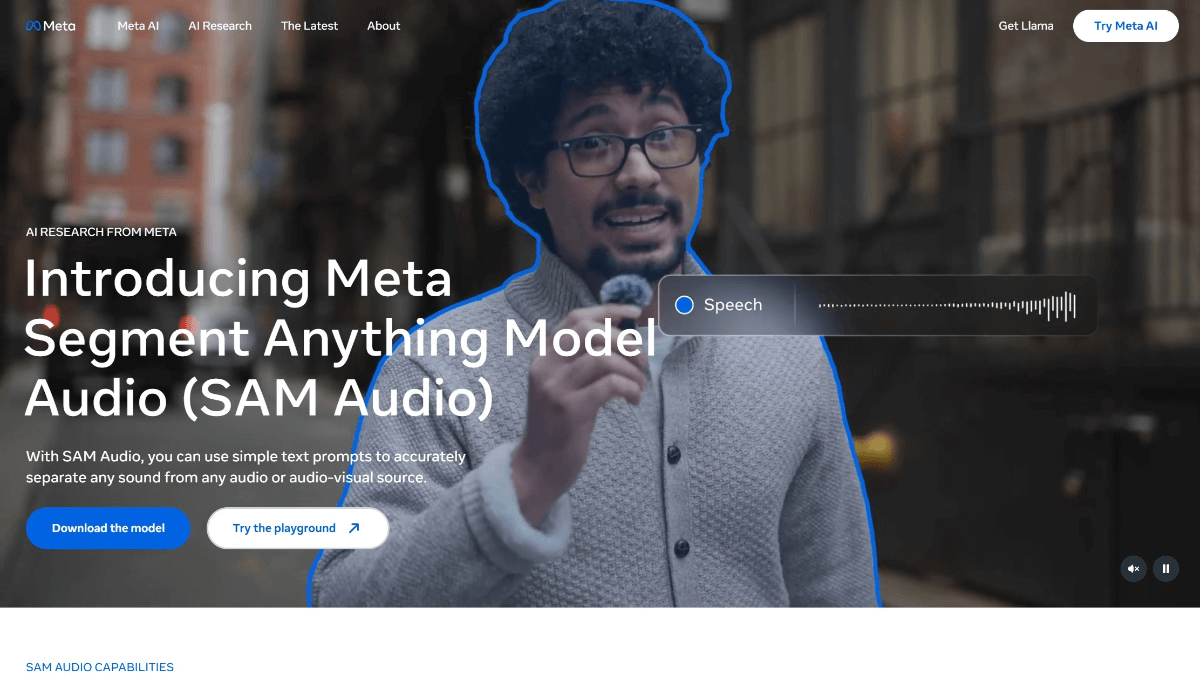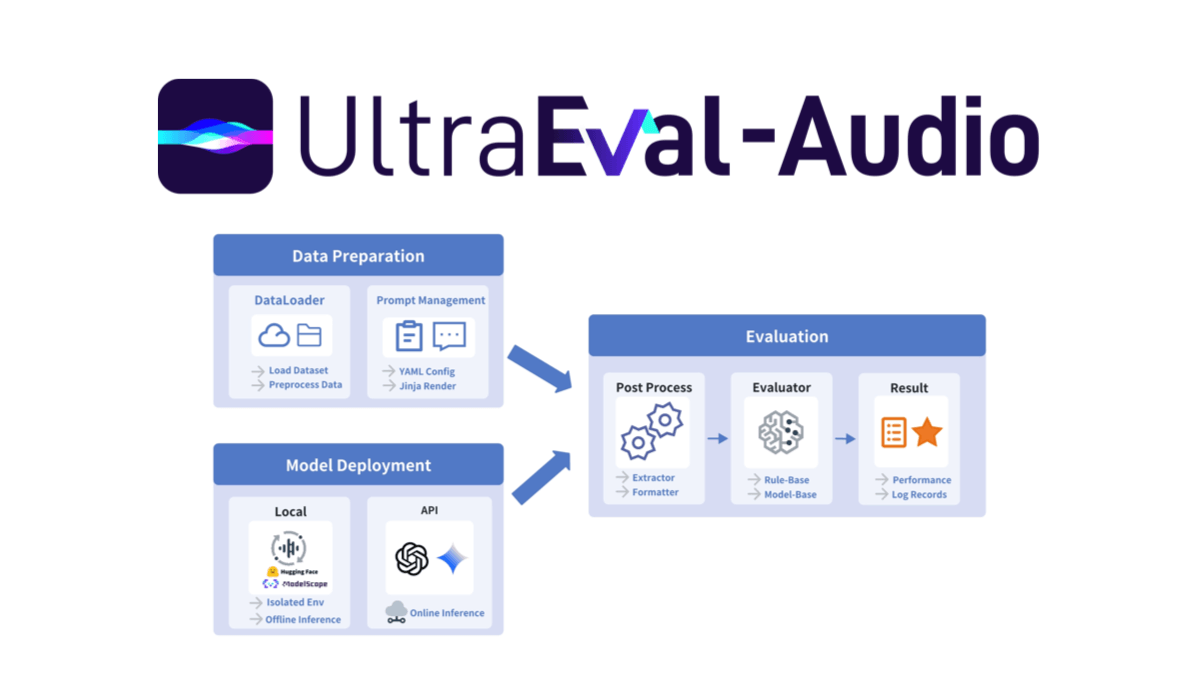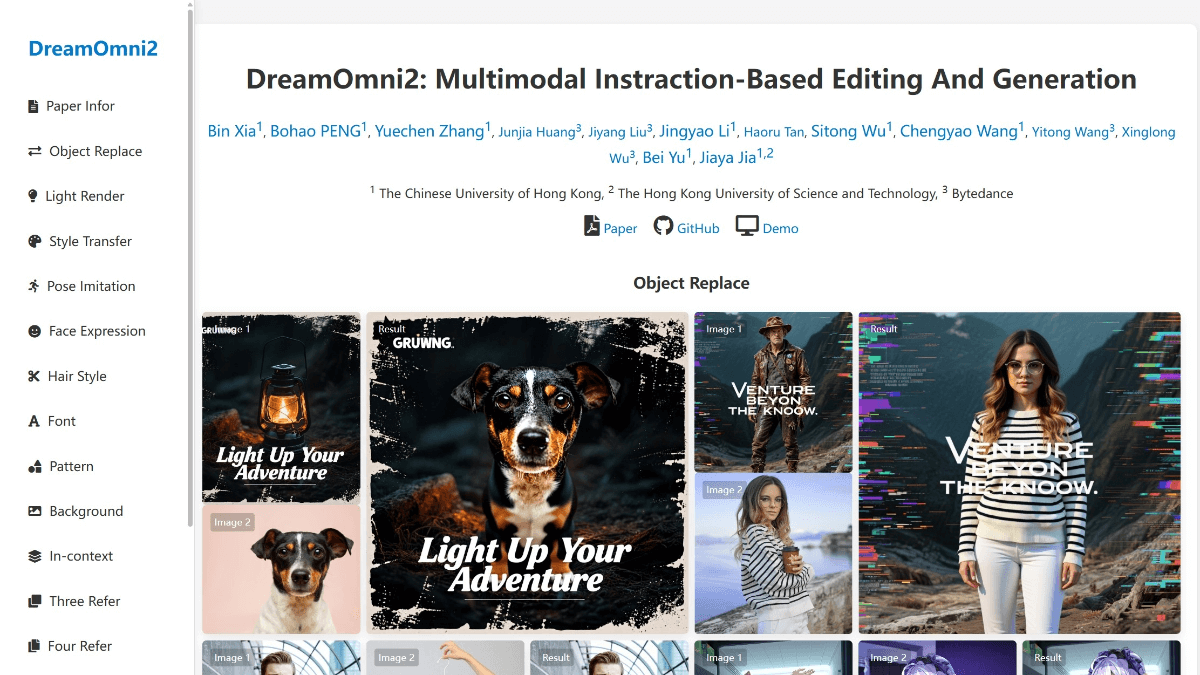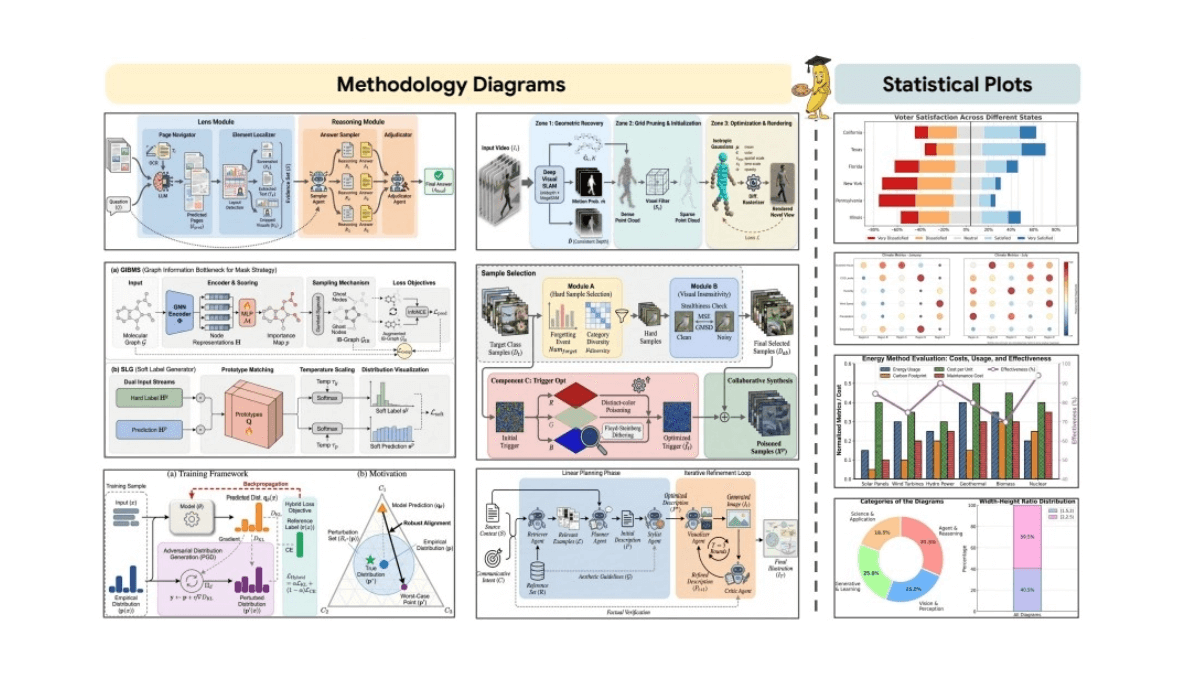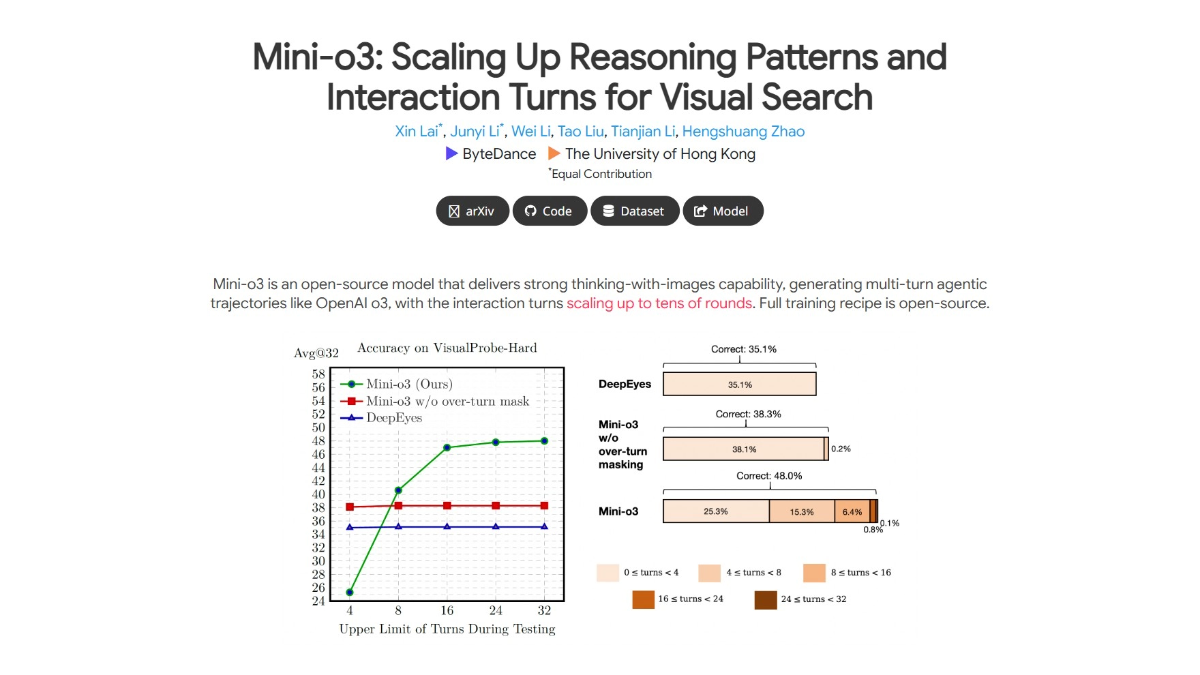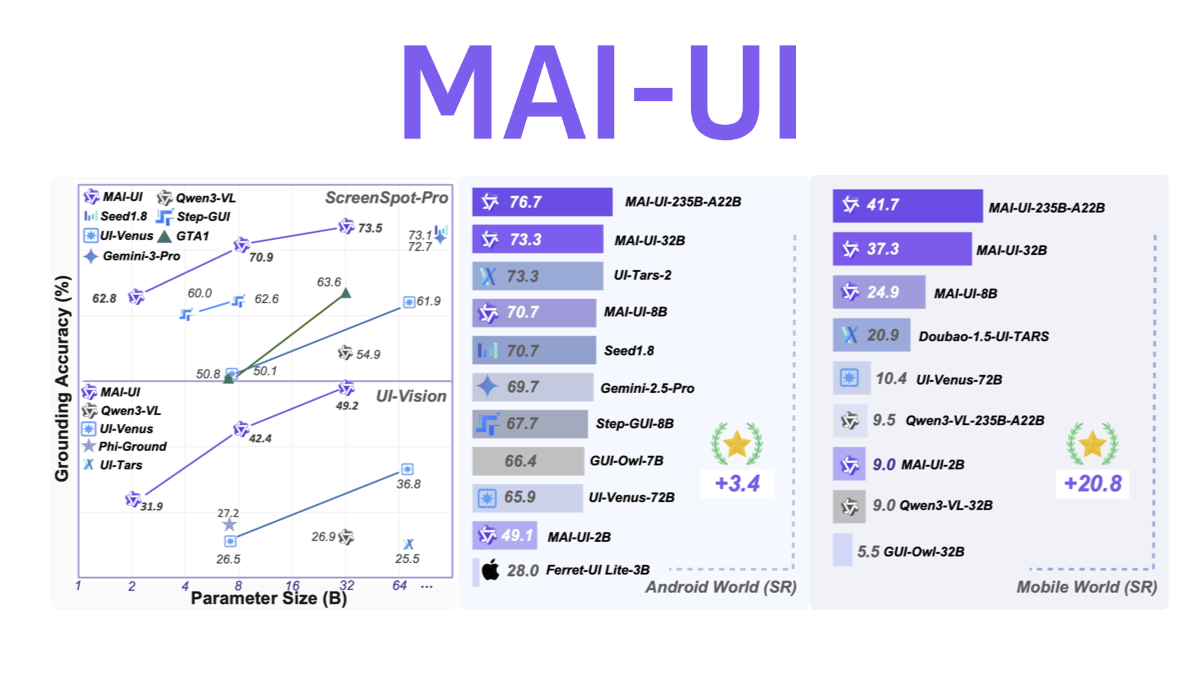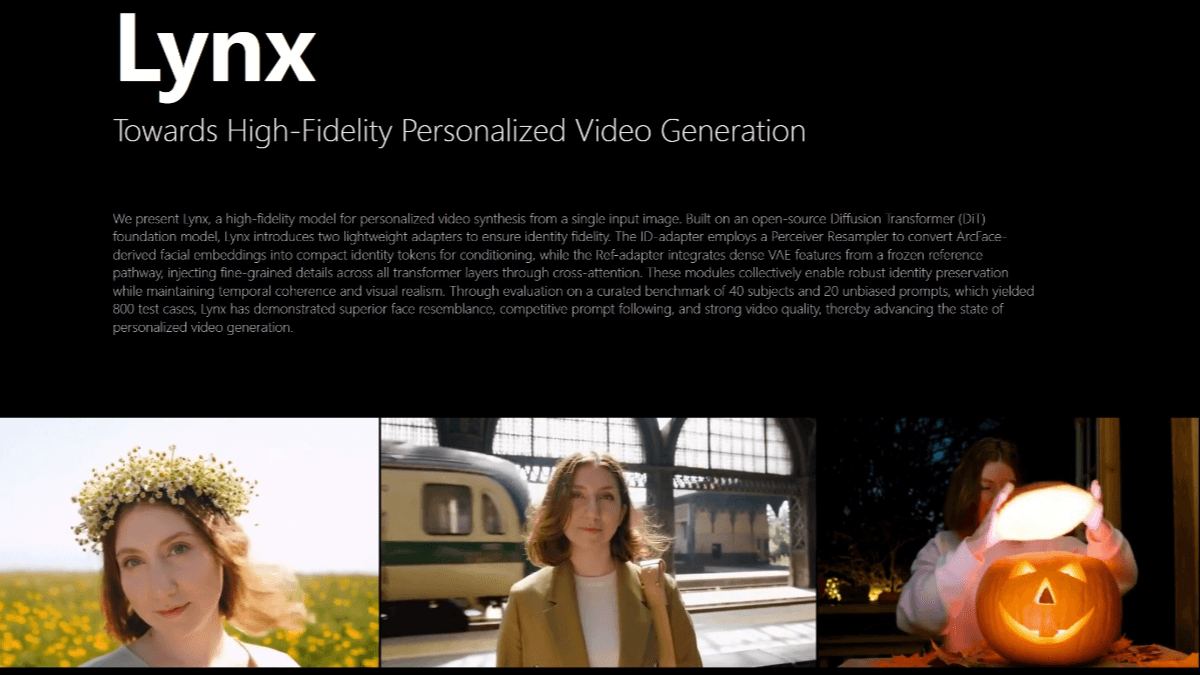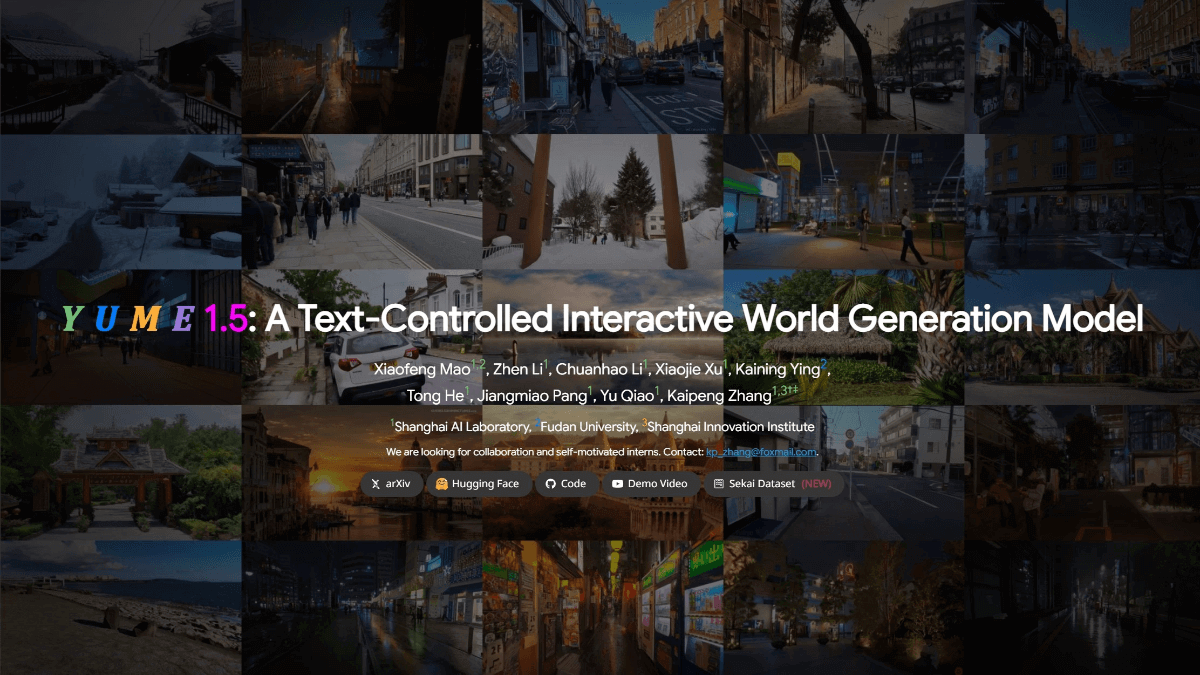
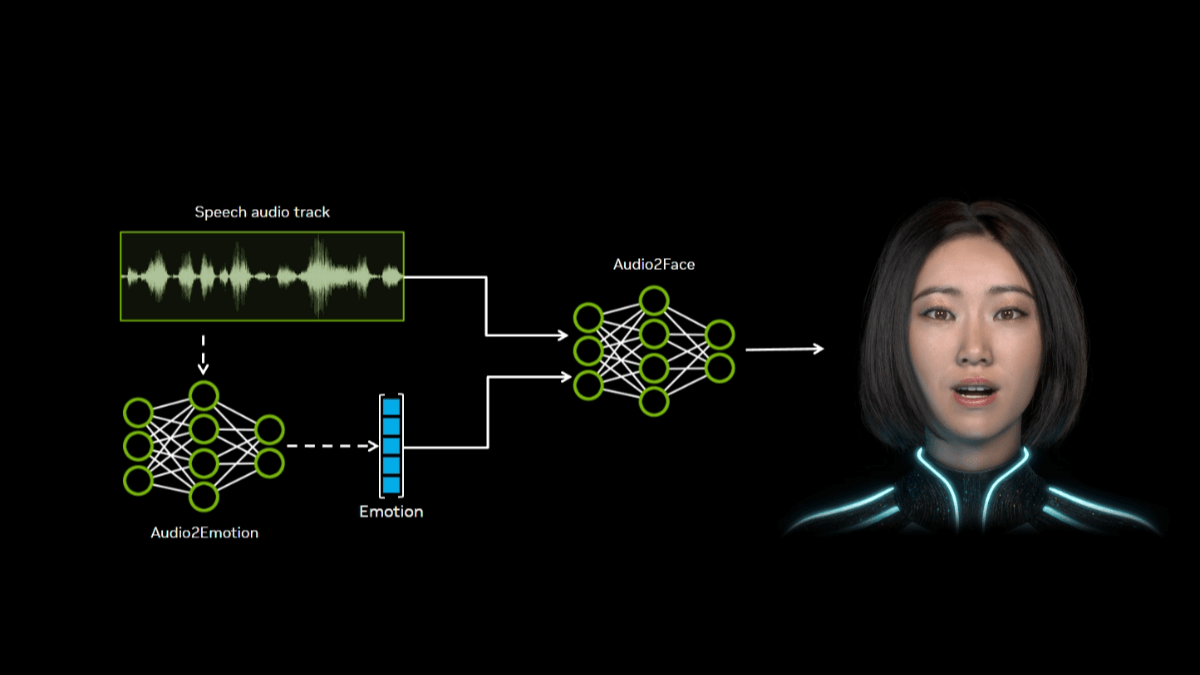
InfinityHuman - Long video digital human generation model launched by Bytes in collaboration with ZJU
InfinityHuman is a commercial-grade long time-series audio-driven character video generation model jointly launched by ByteDance and Zhejiang University. The model is audio-driven and can generate high-resolution, long duration and visually consistent character videos.






![FLUX.2 [klein] - Black Forest Labs 开源的轻量级图像生成与编辑模型](https://aisharenet.com/wp-content/uploads/2026/01/1768710007-1768710007-FLUX.2-klein.png)