SurfSense - 开源的AI研究与知识管理工具,NotebookLM最强平替SurfSense 是开源的 AI 研究与知识管理工具。高度可定制,能连接搜索引擎、Slack、Jira、Notion、YouTube、GitHub 等众多外部数据源,方便用户整合信息。用户可上传多种...最新AI资源4个月前029.4K
GLM-4.6V - 智谱AI开源的多模态大语言模型系列GLM-4.6V是智谱AI开源的多模态大语言模型系列,系列包含两个版本:GLM-4.6V(106B-A12B),面向云端与高性能集群场景的基础版,采用混合专家(MoE)架构,总参数量约1060亿,激活...最新AI资源4个月前026.7K
InkSight - Google开源的AI手写识别工具InkSight是Google开源的AI手写识别工具,能将纸质手写笔记转换为可编辑的数字墨迹文件(如SVG格式)。与传统OCR不同,能识别文字内容,能还原笔迹样式、段落结构和重点标记,支持多语言处理。最新AI资源4个月前025.7K
NewBie-image-Exp0.1 - NewBieAI-Lab开源的实验性动漫文生图模型NewBie-image-Exp0.1是NewBieAI-Lab团队开源的首个实验性动漫文生图模型,采用3.5B参数的Next-DiT架构,专为二次元风格优化。模型通过双文本编码器(GEMMA3-4B...最新AI资源4个月前029.2K
LongCat-Image - 美团LongCat团队开源的图像生成与编辑模型LongCat-Image是美团LongCat团队发布的开源图像生成与编辑模型。采用混合骨干架构(MM-DiT+Single-DiT),结合视觉语言模型(VLM)条件编码器,能实现文生图和多轮图像编辑...最新AI资源4个月前024.7K
VibeVoice-Realtime - 微软开源的轻量级实时文本转语音模型VibeVoice-Realtime 是微软开源的轻量级实时文本转语音(TTS)模型,专为低延迟和实时交互设计。支持流式文本输入,从第一个文本 token 开始就能发声,延迟仅约300毫秒,适合动态数...最新AI资源4个月前025.3K
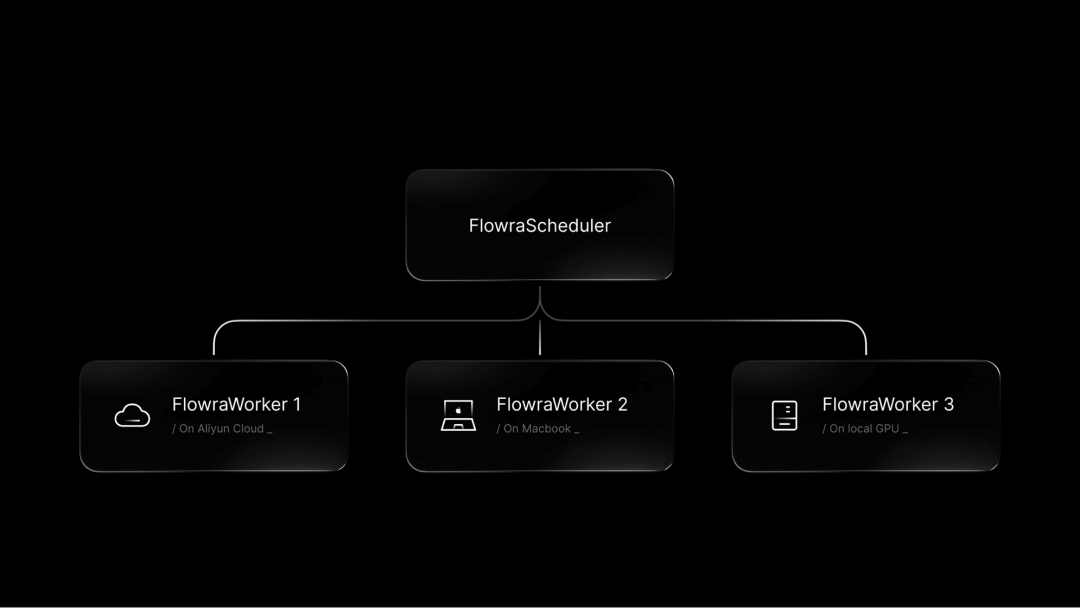
Flowra - 魔搭联合呜哩WULI团队开源的AI工作流开发工具Flowra 是 ModelScope 联合呜哩 WULI 团队开源图执行引擎和节点包开发工具,是 FlowBench 的核心组件。通过有向无环图(DAG)组织工作流,具备智能缓存、并行调度、分布式支...最新AI资源4个月前024.7K
RoboCOIN - 智源联合多所高校开源的双臂机器人真机数据集RoboCOIN是北京智源人工智能研究院联合多家企业和高校开源的全球首个大规模双臂机器人真机数据集,包含15种机器人平台、18万条真实操作轨迹和421种任务场景。最大特点是采用分层标注体系,将任务拆解...最新AI资源4个月前025.2K
TalkCody - 免费开源的AI编程桌面助手,支持复杂任务TalkCody是免费开源的AI编程助手桌面应用,基于Rust + Tauri 2构建,支持Windows、macOS和Linux三大平台,具有原生性能、快速启动和低资源占用的优势。支持50多种主流A...最新AI资源4个月前029.1K
MemMachine - MemVerge推出的开源AI记忆系统MemMachine是MemVerge公司开发的开源AI记忆系统,专为AI大模型和智能体设计,能像人脑一样存储和回忆交互数据,解决AI“无状态失忆”问题。采用分层架构(短期记忆、长期记忆、用户画像...最新AI资源4个月前029K
PartCrafter - 北大联合字节开源的单图3D生成模型PartCrafter 是先进的 3D 生成模型,由北京大学、字节跳动和卡耐基梅隆大学联合提出。能从单张 RGB 图像中一次性生成多个语义明确且几何形态各异的 3D 网格部件。模型通过组合式潜在空间和...最新AI资源4个月前026.5K
GigaWorld-0 - 极佳视界开源的世界模型框架GigaWorld-0是国内具身智能创业公司极佳视界(GigaAI)开源的世界模型框架,主要用于解决具身智能(Embodied AI)领域的数据瓶颈问题。高效生成高质量、多样化且物理真实的训练数据,推...最新AI资源4个月前025.4K
Mistral 3 - Mistral AI发布开源的最新多模态大模型系列Mistral 3是Mistral AI发布开源的最新多模态大模型系列,包含旗舰模型Mistral Large 3(675B总参数)和轻量版Ministral系列(3B/8B/14B),均支持图像理解...最新AI资源4个月前023.5K
Vidi2 - 字节跳动开源的多模态视频理解与生成大模型Vidi2是字节跳动开源的第二代多模态视频理解与生成大模型,专注于视频内容的理解、分析和创作。支持文本、视频、音频三种模态的联合输入,能同时理解画面内容、声音信息以及自然语言指令,实现跨模态的交互与推...最新AI资源4个月前027.2K
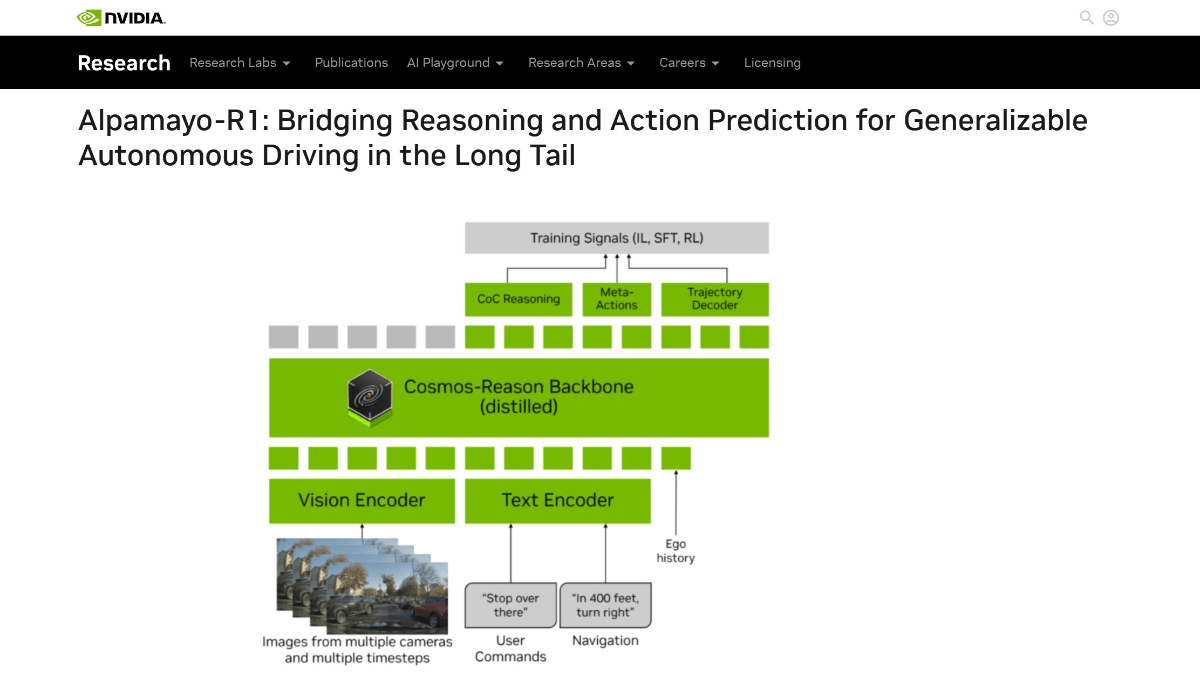
Alpamayo-R1 - 英伟达开源的带推理能力的视觉-语言-行动模型Alpamayo-R1是英伟达研发的具有推理能力的视觉-语言-行动(VLA)模型,专为提升自动驾驶在复杂场景中的决策能力设计。通过引入因果链推理机制,让车辆能像人类驾驶员一样分析场景因果关系(如“因前...最新AI资源4个月前035.4K
Ovis-Image - 阿里AIDC-AI团队开源的文生图模型Ovis-Image 是阿里巴巴国际数字商务集团 AIDC-AI 团队开源的 70 亿参数文生图模型,专注于高质量文本渲染。基于 Ovis-U1 架构,继承了先进的视觉解码器和双向 Token 精炼器...最新AI资源4个月前023.3K
悟界·Emu3.5 - 智源研究院开源的多模态世界大模型悟界·Emu3.5是北京智源人工智能研究院开源的多模态世界大模型,参数量达340亿,具备原生世界建模能力。通过10万亿多模态Token(含790年视频数据)训练,能模拟物理规律,实现图文生成、视觉指导...最新AI资源4个月前026.6K
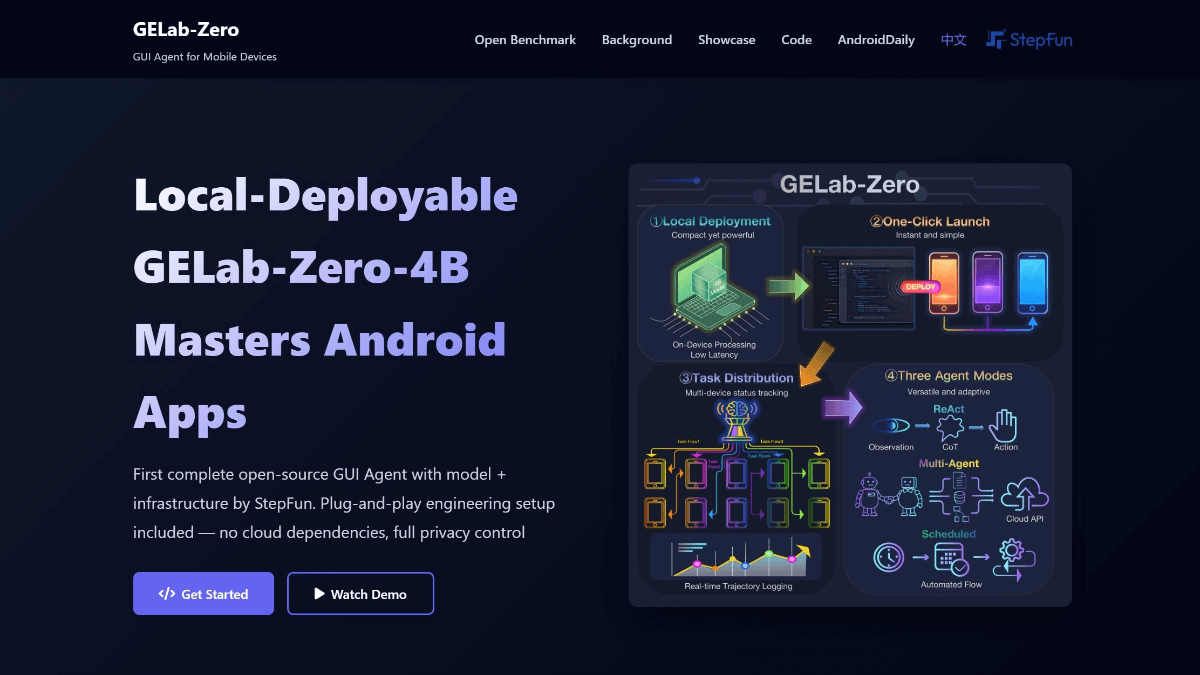
GELab-Zero - 阶跃团队开源的端侧多模态GUI Agent模型GELab-Zero是阶跃团队开源的端侧多模态GUI Agent模型,基于Qwen3-VL-4B-Instruct基座模型构建,参数量为4B。能识别UI元素并执行点击、滑动等操作,支持跨应用任务处理...最新AI资源4个月前034.1K
Depth Anything 3 - 字节跳动Seed开源的3D视觉重建模型Depth Anything 3(DA3)是字节跳动Seed团队研发开源的3D视觉重建模型。通过单一Transformer架构实现任意视角下的空间几何重建,仅需预测深度图和射线图即可还原三维场景,相比...最新AI资源4个月前035.7K
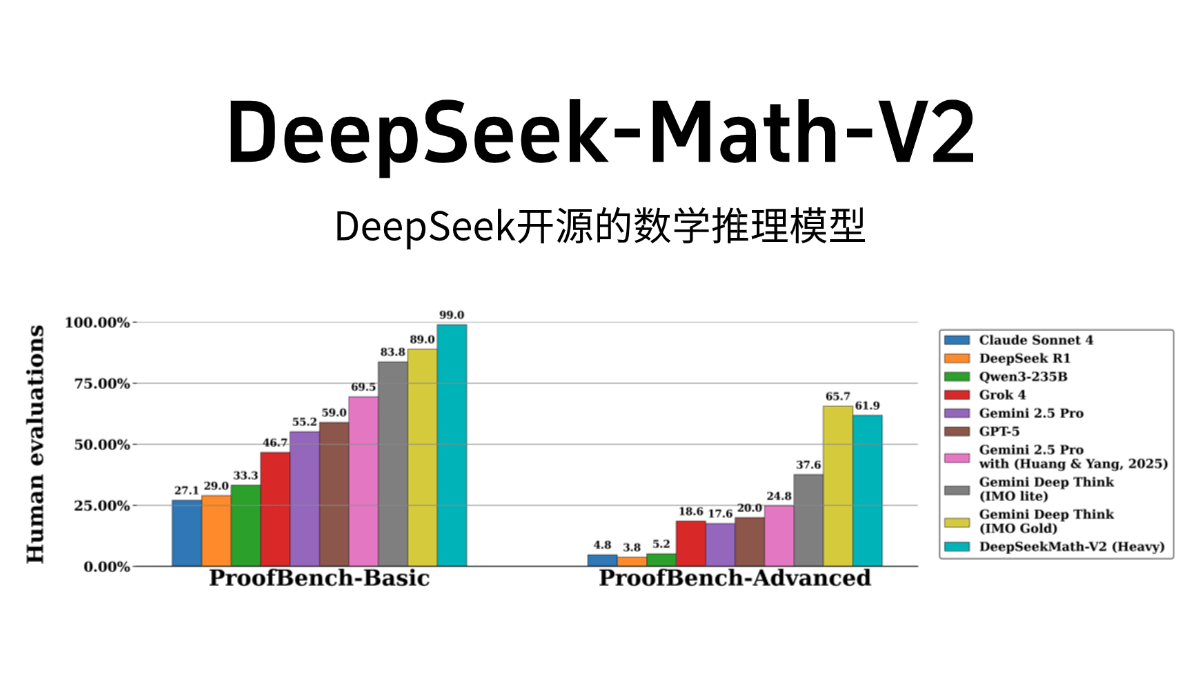
DeepSeek-Math-V2 - DeepSeek开源的数学推理模型DeepSeek-Math-V2是幻方旗下AI公司DeepSeek开源的数学推理模型,最新版本基于DeepSeek-V3.2-Exp-Base改进,性能超越Gemini DeepThink,达到国际数...最新AI资源4个月前028.6K
Z-Image - 阿里通义实验室开源的图像生成模型Z-Image是阿里通义实验室开源的图像生成模型,具有高效、快速和强大的图像生成能力。采用单流扩散Transformer架构(S3-DiT),将文本、视觉语义和图像VAE token整合为统一输入流...最新AI资源4个月前050.2K
ROCK - 阿里巴巴开源的智能体训练环境沙箱ROCK(Reinforcement Open Construction Kit) 是阿里巴巴开源的智能体训练环境沙箱,解决智能体在真实环境中无法规模化训练的难题。ROCK 提供了高稳定的沙箱管理服务...最新AI资源4个月前027K
ViMax - 香港大学开源的多智能体视频生成框架ViMax是香港大学数据科学实验室开源的多智能体视频生成框架,能实现从创意输入到视频输出的全流程自动化。整合了剧本生成、分镜设计、镜头规划和视频渲染等功能,支持用户通过自然语言描述生成连贯的影视级视频...最新AI资源4个月前044.4K
FLUX.2 - 黑森林开源的图像生成与编辑模型FLUX.2是Black Forest Labs发布的开源图像生成与编辑模型,支持文生图、多图参考和图像编辑,具备更丰富的细节、清晰纹理和稳定光线。分为四个版本:FLUX.2 [pro](媲美顶级闭源...最新AI资源4个月前026.3K
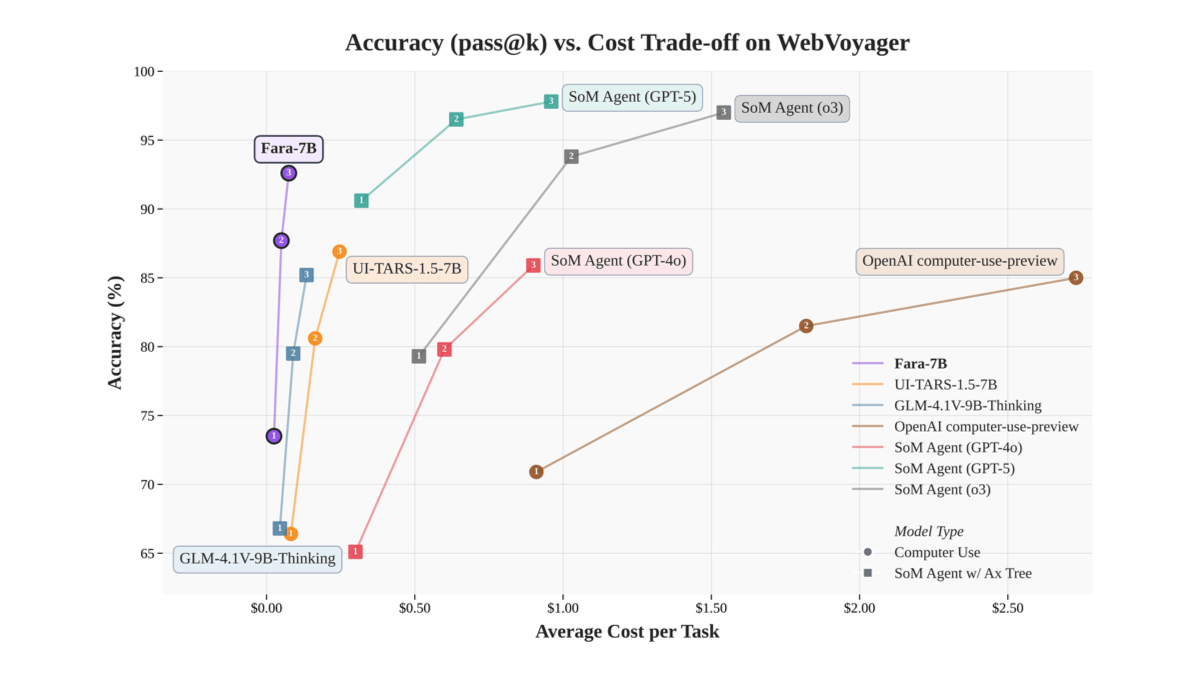
Fara-7B - 微软开源的计算机操作Agent助手模型Fara-7B是微软开源发布的70亿参数规模的计算机操作代理(CUA)模型,基于Qwen2.5-VL-7B架构。通过视觉解析网页截图,在屏幕上执行点击、输入等操作,无需依赖额外的可访问性树或多个大模型...最新AI资源4个月前031.9K
HunyuanOCR - 腾讯混元开源的光学字符识别专家模型HunyuanOCR是腾讯混元团队开源的高性能光学字符识别模型,参数量仅10亿。基于混元多模态架构开发,采用端到端设计,能高效处理文字检测、识别及文档解析任务。模型在复杂文档测试中得分94.1分,超越...最新AI资源4个月前033.5K
Supertonic - 开源的高性能AI 文本转语音系统,极速离线运行Supertonic是开源的高性能的文本转语音(TTS)系统,专注于在本地设备上快速生成语音。采用ONNX Runtime技术,可在手机、电脑甚至树莓派等设备上运行,支持23种语言和语音克隆,无需网络...最新AI资源4个月前027.8K
MiMo-Embodied - 小米开源的跨领域具身智能基座模型MiMo-Embodied是小米集团开源的全球首个成功融合具身智能(Embodied AI)与自动驾驶的跨具身基础模型。解决具身智能与自动驾驶之间的知识迁移难题,实现两大领域的任务统一建模。最新AI资源5个月前033.1K
MOSS-Speech - 复旦大学开源的语音到语音大模型MOSS-Speech是复旦大学邱锡鹏教授团队开源的语音到语音(Speech-to-Speech)大模型。突破传统语音处理方式,无需文本引导,直接对语音进行理解和生成,能捕捉语调、情绪等非文字要素,使...最新AI资源5个月前028.5K
Parallax - Gradient开源的全球首个全自主AI操作系统Parallax是分布式AI实验室Gradient开源的全球首个“全自主AI操作系统”。支持在Mac、Windows等异构设备上跨平台部署大模型,让用户完全掌控模型、数据与AI记忆。系统内置网络感知分...最新AI资源5个月前084.1K
HunyuanVideo 1.5 - 腾讯混元免费开源的轻量级视频生成模型HunyuanVideo 1.5 是腾讯混元大模型团队开源的轻量级视频生成模型,基于 Diffusion Transformer(DiT)架构,参数量为 8.3B。支持生成 5-10 秒的高清视频,分...最新AI资源5个月前034.4K
Awex - 蚂蚁集团开源的高性能权重交换框架Awex是蚂蚁集团开源的高性能权重交换框架,专为强化学习中的大规模参数同步设计。能在秒级完成TB级参数交换,显著提升训练推理效率。Awex具备极速同步性能,在千卡集群上,万亿参数模型可在6秒内完成全量...最新AI资源5个月前081.8K
Seekdb - 蚂蚁OceanBase开源的AI原生混合搜索数据库Seekdb(OceanBase Seekdb)是蚂蚁OceanBase开源的 AI 原生混合搜索数据库,支持向量、全文、标量及地理空间数据的统一混合搜索,采用多阶段检索机制,实现低延迟下的高精度搜索...最新AI资源5个月前027.3K
LoopTool - 上海交大联合小红书开源的自动化工具调用数据进化框架LoopTool是上海交通大学与小红书团队开源的自动化的工具调用数据进化框架,专为提升大语言模型的工具调用能力设计。通过闭环迭代优化数据生成与模型训练,利用开源模型(如Qwen3-32B)作为数据生成...最新AI资源5个月前083.3K
SAM 3D - Meta开源的3D重建模型系列SAM 3D是Meta公司推出的基于SAM系列的3D重建模型,包含SAM 3D Objects和SAM 3D Body两个分支。其中SAM 3D Objects能从单张照片生成可交互的3D物体模型,支...最新AI资源5个月前031.1K
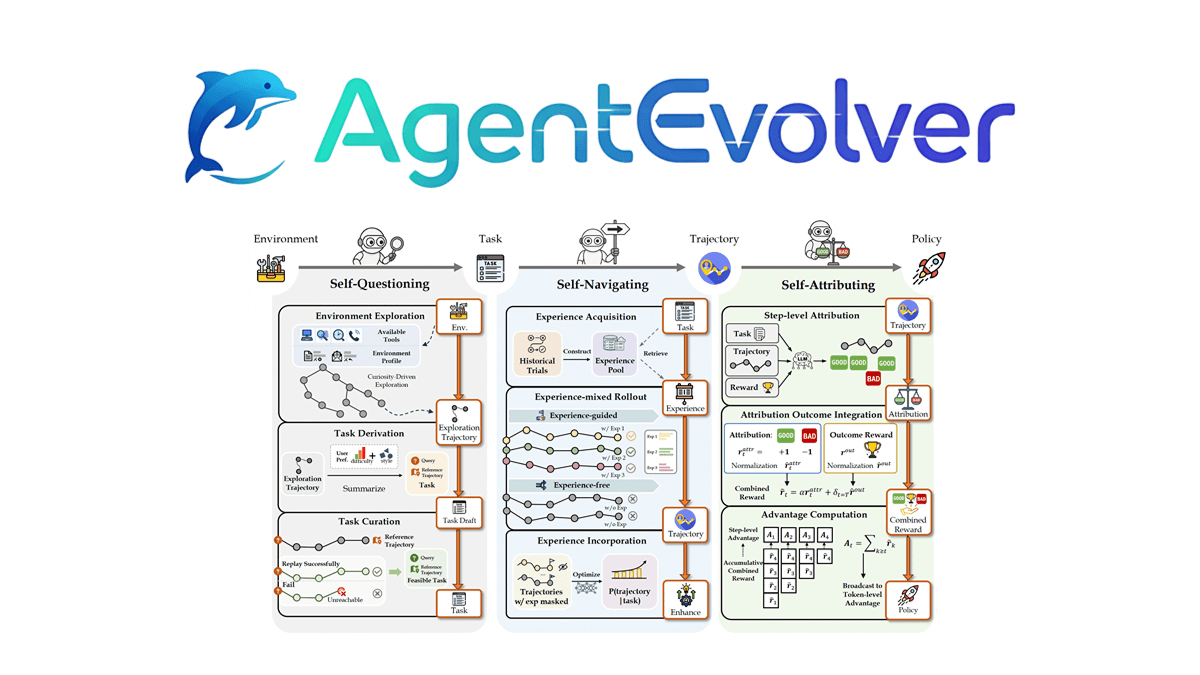
AgentEvolver - 阿里通义实验室开源的智能体进化系统AgentEvolver是阿里巴巴通义实验室开源的智能体进化系统。通过自我提问、自我导航和自我归因三种机制,实现智能体的自主学习与进化。AgentEvolver采用服务导向架构,将环境沙盒、LLM和经...最新AI资源5个月前089K
MemOS - 开源的AI记忆管理与调度平台,共享长期记忆MemOS是MemTensor等开源的面向大语言模型(LLM)的记忆管理与调度框架。将记忆视为与算力同等重要的资源,通过标准化的MemCube记忆单元,统一管理明文、激活状态和参数记忆。最新AI资源5个月前085.2K
网格搜索(Grid Search)是什么,一文看懂网格搜索(Grid Search)是机器学习中用于系统化寻找最优超参数组合的自动化方法。这种方法通过预先定义每个超参数的候选值范围,穷举所有可能的参数组合,逐一训练模型并评估性能,最终选择表现最佳的超...AI答疑5个月前028.3K
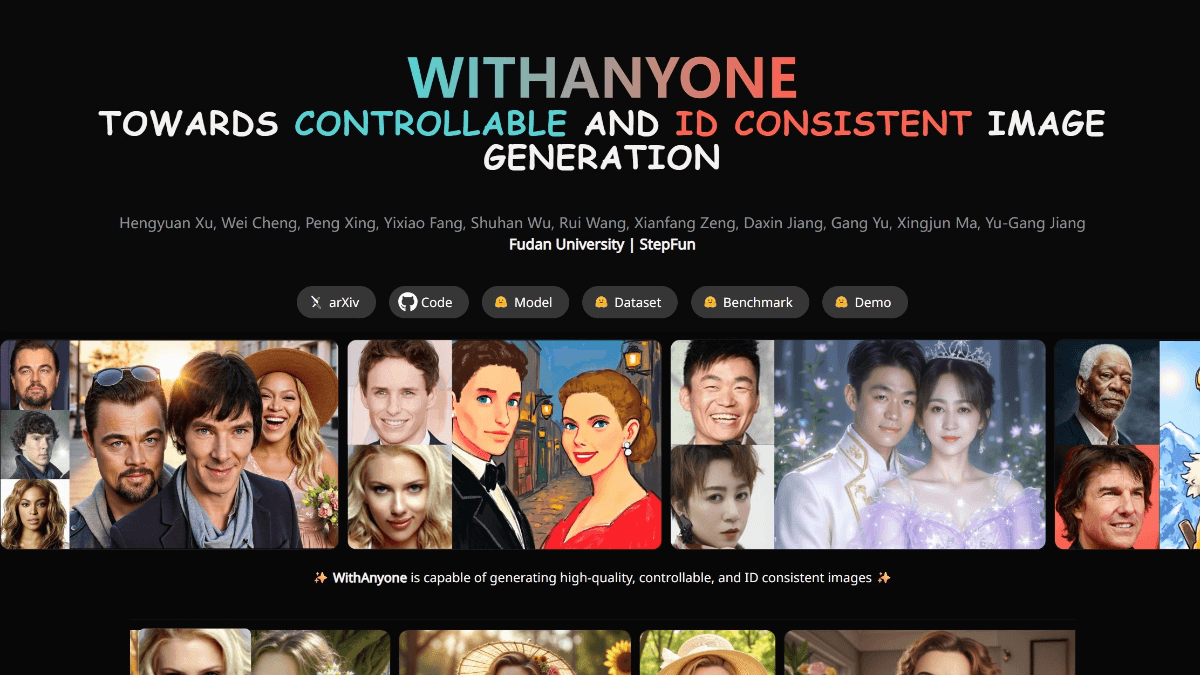
WithAnyone - 复旦联合阶跃星辰开源的AI合照生成模型WithAnyone 是复旦大学和阶跃星辰联合开发的 AI 合照生成模型,解决传统 AI 图像生成中常见的“复制粘贴”问题,实现更自然、可控的多人图像生成。模型通过大规模数据集 MultiID-2M ...最新AI资源5个月前084.2K
ChatTutor - 开源的AI教学辅助工具,可视化互动学习ChatTutor是开源的AI教学辅助工具,专注于STEM学科的可视化互动学习。通过多智能体架构实现对话式答疑和动态绘图功能,能在电子白板上实时绘制数学图形、物理电路或思维导图,帮助用户直观理解抽象概...最新AI资源5个月前023.4K
DPAI Arena - JetBrains开源的AI编程基准测试平台DPAI Arena(Developer Productivity AI Arena)是JetBrains创建的开放基准测试平台,衡量AI辅助开发工具在真实世界软件工程任务中的有效性。通过透明的评估流...最新AI资源5个月前029.3K
EverMemOS - 盛大团队推出的开源长期记忆操作系统EverMemOS是陈天桥领导的盛大团队推出的开源长期记忆操作系统,专为AI智能体设计,解决大语言模型因固定上下文窗口导致的记忆断裂问题。系统基于人类大脑记忆机制,采用四层架构(代理层、记忆层、索引层...最新AI资源5个月前035.3K
Astron Agent - 科大讯飞开源的企业级智能工作流开发平台Astron Agent是科大讯飞开源的企业级智能工作流开发平台,专注于帮助企业快速构建可落地的AI代理应用。采用Java+Spring Boot技术栈,支持轻量化私有化部署(最低2核4G配置),内置...最新AI资源5个月前029.6K
Bee - 腾讯混元联合清华开源的全栈多模态大模型项目Bee是腾讯混元团队与清华大学联合推出的全栈开源多模态大模型解决方案,通过提升数据质量缩小开源模型与闭源模型的性能差距。项目包含三大核心成果:1500万规模的高质量双层CoT数据集Honey-Data...最新AI资源5个月前026.5K
InfinityStar - 字节开源的统一时空自回归视频生成框架InfinityStar是字节跳动开源的统一时空自回归框架,专为高分辨率图像和视频生成设计。采用离散自回归方法,能在单一模型中同时处理文本到图像、文本到视频、图像到视频等任务。框架在VBench基准测...最新AI资源5个月前027.5K
Koina - 慕尼黑工大联合密歇根大开源的去中心化机器学习平台Koina是开源的去中心化机器学习平台,专注于简化蛋白质组学数据分析。由德国慕尼黑工业大学和美国密歇根大学团队开发。平台通过标准化接口整合了30多个主流模型(如ProSIT、MS²PIP),支持肽段质...最新AI资源5个月前028.2K
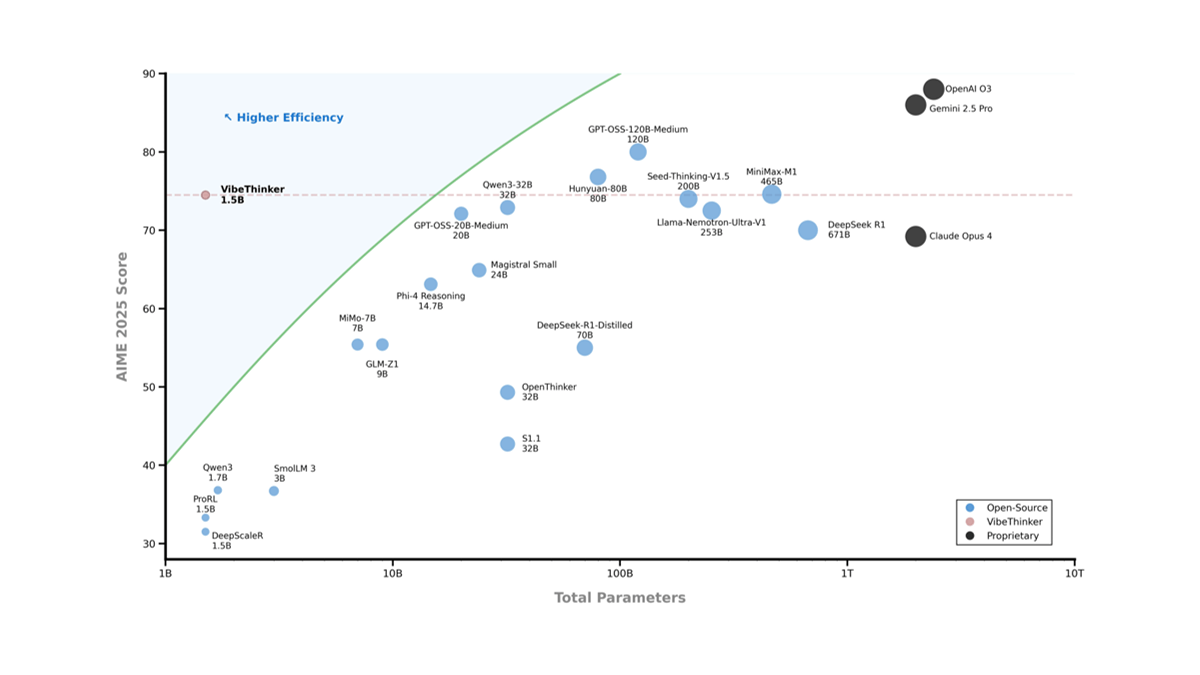
VibeThinker-1.5B - 微博AI开源的15亿参数大型语言模型VibeThinker-1.5B是微博AI开源的15亿参数的大型语言模型。基于阿里巴巴的Qwen2.5-Math-1.5B进行精细调整,专为数学和代码任务优化,表现出色,推理性能在行业内处于领先水平。最新AI资源5个月前031.2K
BestBlogs - 开源的AI内容聚合平台,精选优质技术内容BestBlogs 是专注于为技术从业者、创业者和产品经理等提供高质量内容的平台。通过 RSS 订阅和爬虫技术,从 400 多个优质博客中收集文章、播客、视频等多形式内容。核心优势在于利用 AI 大语...最新AI资源5个月前025.1K
Egocentric-10K - Build AI开源的第一人称视角机器人数据集Egocentric-10K 是大规模的第一人称视角(egocentric)工厂操作视频数据集,由 build.ai 团队开源。数据集包含 10,000 小时的视频,总帧数达 10.8 亿帧,涉及 2...最新AI资源5个月前030.2K
LazyCraft - 开源AI Agent应用开发与管理平台,基于LazyLLM构建LazyCraft 是商汤基于开源框架 LazyLLM 构建的开源 AI Agent 应用开发与管理平台,为企业和开发者提供一站式AI应用开发解决方案。帮助开发者以低门槛、低成本快速构建和发布大模型应...最新AI资源5个月前033.9K
Kosong - Moonshot AI开源的全新AI Agent开发框架Kosong 是月之暗面(Moonshot AI)开源的全新AI Agent开发框架,为开发者提供一个轻量、灵活且高度可扩展的底层支持,以构建下一代智能体应用。通过异步工具编排引擎,能高效调度多个工具...最新AI资源5个月前028.2K
SenseNova-SI - 商汤科技开源的空间智能大模型系列SenseNova-SI是商汤科技发布的开源空间智能大模型,专注于提升AI在空间理解与推理方面的能力。模型在空间测量、重构、关系判断、视角转换、形变分析和空间推理等六个核心维度上表现出色,显著优于其他...最新AI资源5个月前024.7K
Omnilingual ASR - Meta推出的多语言语音识别框架Omnilingual ASR是Meta推出的多语语音识别框架,覆盖1600+语言,78%语言字符错误率低于10%。其70亿参数wav2vec 2.0编码器结合CTC与Transformer解码器,支...最新AI资源5个月前028.4K
Frappe Builder - 开源的AI低代码网站构建工具,拖拽组件快速搭建Frappe Builder是开源的低代码建站工具,由Frappe公司开发,核心特点是提供类似Figma的可视化编辑器,支持拖拽组件快速搭建网站。属于Frappe生态(Frappeverse)的一部分...最新AI资源5个月前031.2K
DeepOCR - 基于DeepSeek-OCR模型的开源复刻项目DeepOCR 是开源复刻项目,实现 DeepSeek-OCR 的核心架构,通过光学压缩技术高效处理文本信息。核心是 DeepEncoder,由 SAM-base(处理高分辨率图像)、16×卷积压缩器...最新AI资源5个月前027.9K
Glow - 开源的命令行工具,支持在终端渲染Markdown文件Glow 是开源的命令行工具,用于在终端中优雅地渲染 Markdown 文件。工具支持高亮代码块、数学公式等复杂元素,提供丰富的功能,如自定义样式、分页显示、鼠标支持等。最新AI资源5个月前032K
NocoBase - 免费开源的AI无代码开发平台,可视化构建应用NocoBase是基于AI驱动的开源无代码开发平台,支持快速搭建业务系统,无需编程即可通过配置完成应用开发。项目采用Apache-2.0协议,提供私有化部署和灵活扩展能力,适用于企业管理、协作平台等场...最新AI资源5个月前028.3K
UniWorld V2 - 兔展智能联合北大推出的新一代图像编辑模型UniWorld V2是兔展智能与北京大学UniWorld团队联合推出的新一代图像编辑模型。在图像编辑领域具有显著优势,特别是在中文理解和复杂指令执行方面表现出色。模型能精准渲染艺术中文字体,支持精细...最新AI资源5个月前030K
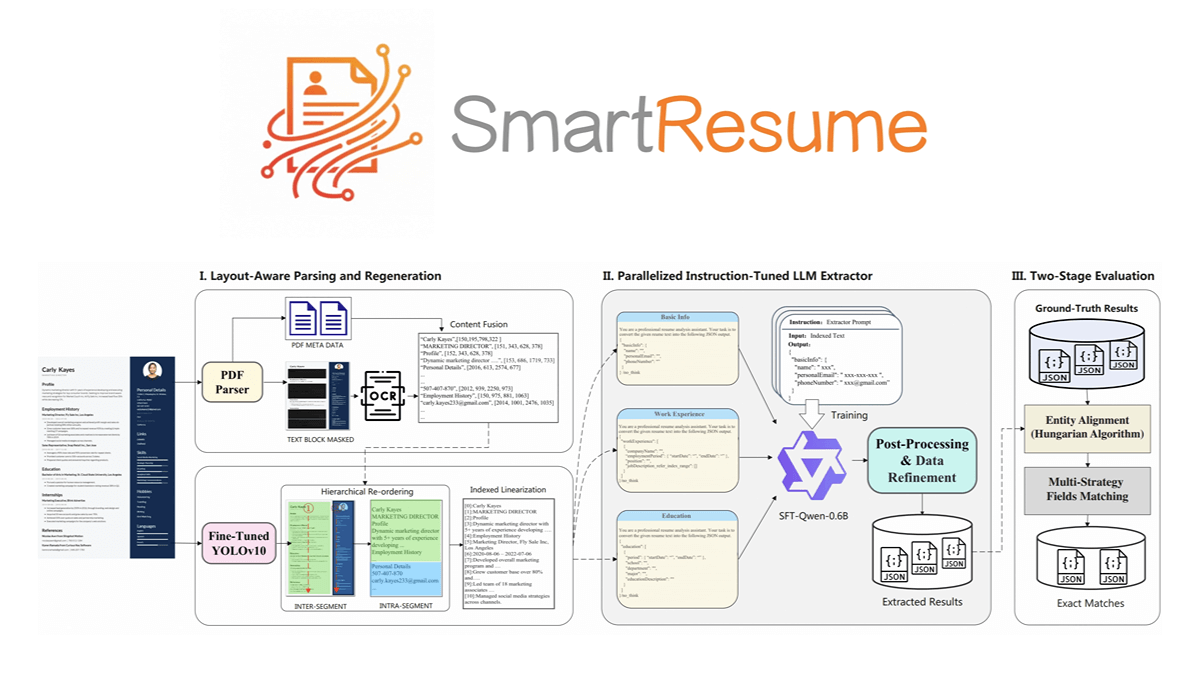
SmartResume - 阿里巴巴开源的AI简历解析与优化工具SmartResume 是阿里巴巴开源的智能简历解析与优化工具,能高效地从 PDF、图片或 Office 文档中提取结构化信息,如基本资料、教育经历和工作经验等。通过融合 OCR 技术和 PDF 元数...最新AI资源5个月前031.6K
Step-Audio-EditX - 阶跃星辰开源的首个LLM级音频编辑大模型Step-Audio-EditX是开源的音频编辑大模型,由阶跃星辰团队研发,专注于通过人工智能技术实现音频内容的精细操控。模型能动态调整音频的情绪、说话风格(如撒娇、老人腔等)和副语言元素(如笑声、叹...最新AI资源5个月前030.9K
Open-o3 Video - 北大联合字节开源的视频推理模型Open-o3 Video 是北京大学和字节跳动联合开发的开源视频推理模型,专注于通过时间和空间证据增强视频推理能力。通过明确标注关键证据的时间戳和边界框,帮助模型更好地理解和解释视频内容。最新AI资源5个月前027.2K
Handy - 开源免费的本地AI语音转文字工具Handy是开源免费的本地语音转文字工具,支持Windows、MacOS和Linux系统,由Rust和React开发。通过本地处理语音数据,无需上传云端,保障隐私安全,适合快速转录和文字输入。最新AI资源5个月前059.6K
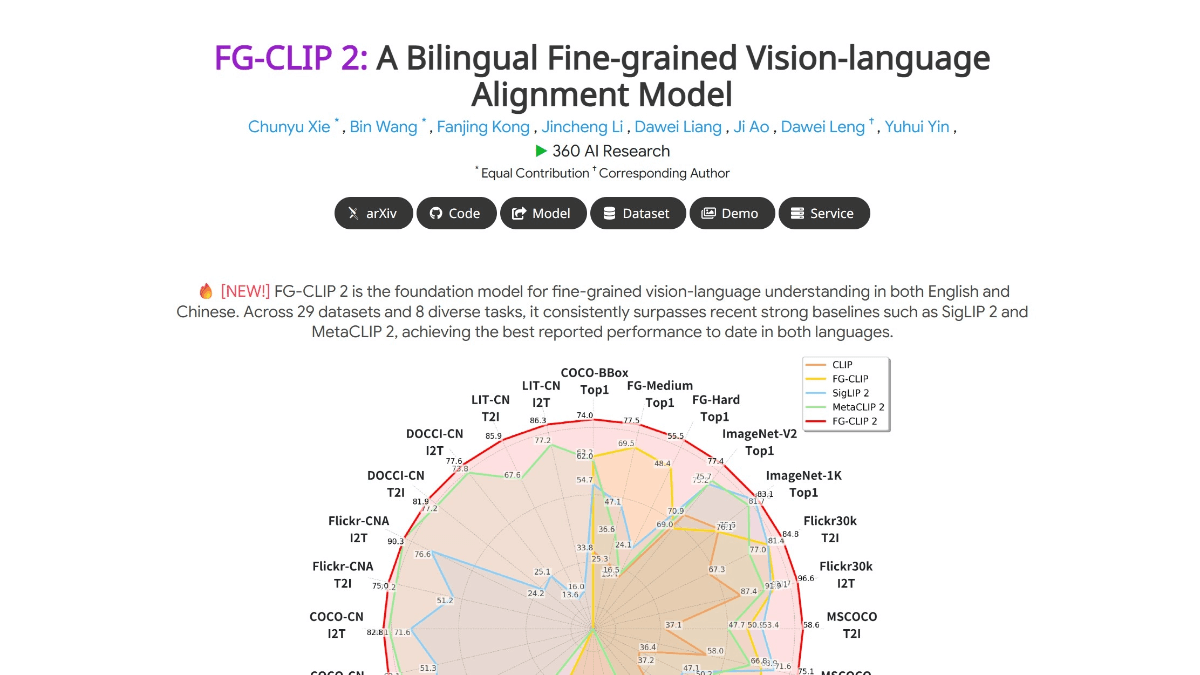
FG-CLIP 2 - 360开源的图文跨模态视觉语言模型FG-CLIP 2是360人工智能研究院推出的全球领先的图文跨模态视觉语言模型(VL-M),在29项权威基准测试中超越Google和Meta的同类模型,成为目前性能最强的VL-M。能精准识别图像中的毛...最新AI资源5个月前028K
朴素贝叶斯(Naive Bayes)是什么,一文看懂朴素贝叶斯(Naive Bayes)算法是基于贝叶斯定理的监督学习算法。“朴素”之处在于假设特征之间相互条件独立。简化假设大大降低计算复杂度,使算法在实际应用中表现出高效性。AI答疑5个月前033.1K
K均值聚类(K-Means Clustering)是什么,一文看懂K均值聚类(K-Means Clustering)是经典的无监督机器学习算法。主要用于将数据集划分为K个互不相交的簇。算法目标是将n个数据点分配到K个簇中,使每个数据点都属于离其最近的簇中心对应的簇。AI答疑5个月前027.6K
微舆BettaFish - 开源的多智能体舆情分析系统微舆(BettaFish)是开源的多智能体舆情分析系统。采用多智能体架构,通过Query、Media、Insight、Report等Agent协同工作,实现检索、抽取与报告闭环。系统支持AI驱动的全域...最新AI资源5个月前061.4K
Ouro - 字节跳动Seed团队开源的新型循环语言模型Ouro是字节跳动Seed团队开发的新型循环语言模型(Looped Language Models),核心创新在于通过参数共享的循环计算结构,在预训练阶段直接构建推理能力。模型采用24层作为基础块,通...最新AI资源5个月前037.1K
ChronoEdit - 英伟达与多伦多大学联合开源的AI图像编辑框架ChronoEdit是英伟达与多伦多大学联合研发的开源AI图像编辑框架,将图像编辑任务重新定义为视频生成任务,以确保编辑结果在时间和物理上的一致性。通过从一个 14B 参数的预训练视频生成模型中蒸馏出...最新AI资源5个月前032.1K
LongCat-Flash-Omni - 美团开源的全模态大语言模型LongCat-Flash-Omni 是美团 LongCat 团队发布的开源全模态大语言模型。拥有5600亿参数规模(激活参数270亿),在保持庞大参数量的同时,实现了毫秒级的实时音视频交互能力。最新AI资源5个月前030.1K
Petri - Anthropic开源的 AI 安全审计框架Petri 是 Anthropic 开发的开源 AI 安全审计框架,系统性地评估 AI 模型的安全性和行为对齐情况。通过模拟真实场景,让自动化审计员与目标模型进行多轮对话,然后由法官代理对模型的行为进...最新AI资源5个月前026.5K
前馈神经网络(Feedforward Neural Network)是什么,一文看懂前馈神经网络(Feedforward Neural Network,FNN)是基础且广泛使用的人工神经网络模型。核心特征在于网络中的连接不形成任何循环或反馈路径,信息严格从输入层单向流动到输出层,经一...AI答疑5个月前030.9K
卷积神经网络(Convolutional Neural Network)是什么,一文看懂卷积神经网络(Convolutional Neural Network,简称CNN),是专门设计用于处理具有网格结构数据的人工神经网络,在图像和视频分析领域表现卓越。AI答疑5个月前028.4K
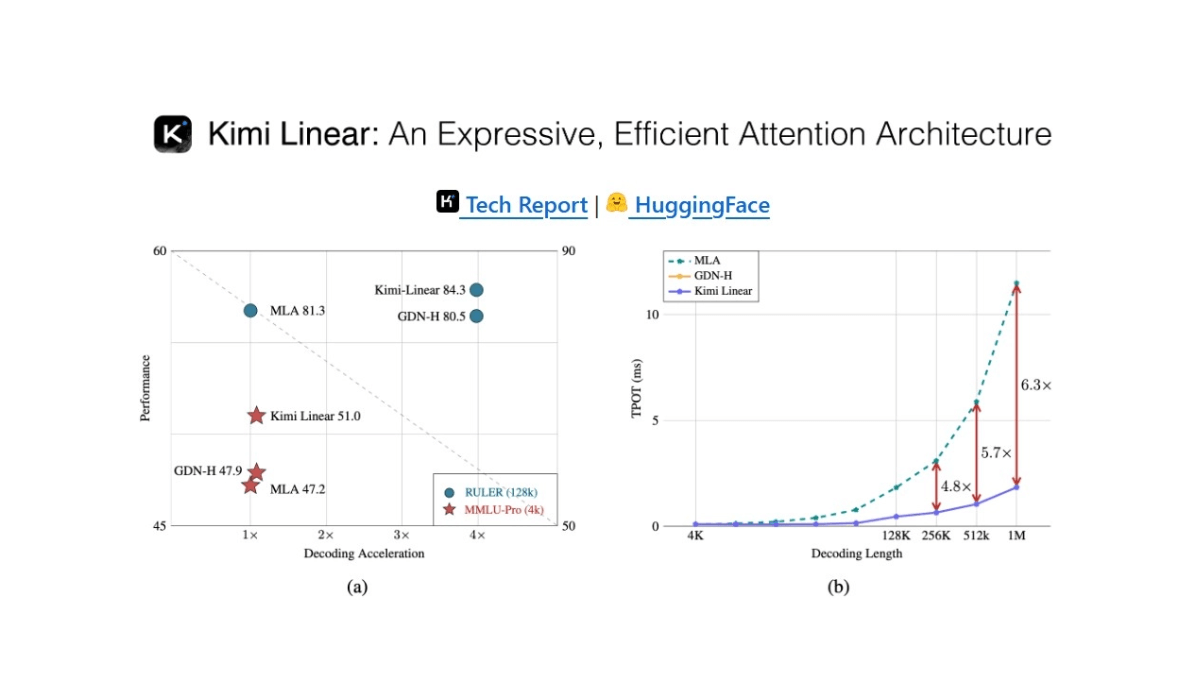
Kimi Linear - 月之暗面开源的新型混合线性注意力架构Kimi Linear 是月之暗面开源的新型混合线性注意力架构,以 Kimi Delta Attention(KDA)为核心,通过更细粒度的门控机制优化了传统注意力模型,显著提升了硬件效率和内存控制能...最新AI资源5个月前038.6K
FIBO - 全球首个开源原生支持JSON的文本生成图像模型FIBO 是 Bria AI 开发的全球首个开源的原生支持 JSON 的文本生成图像模型。基于 8B 参数的 DiT(扩散 Transformer)架构,采用流匹配(Flow Matching)训练方...最新AI资源5个月前031K
SoulX-Podcast - Soul AI Lab开源的对话式语音合成模型SoulX-Podcast 是 Soul AI Lab 开源的先进多说话者对话式语音合成模型,专为生成高质量播客内容设计。具备多轮对话生成能力,能模拟真实播客场景中的流畅对话,支持普通话、英语及多种中...最新AI资源5个月前039.8K
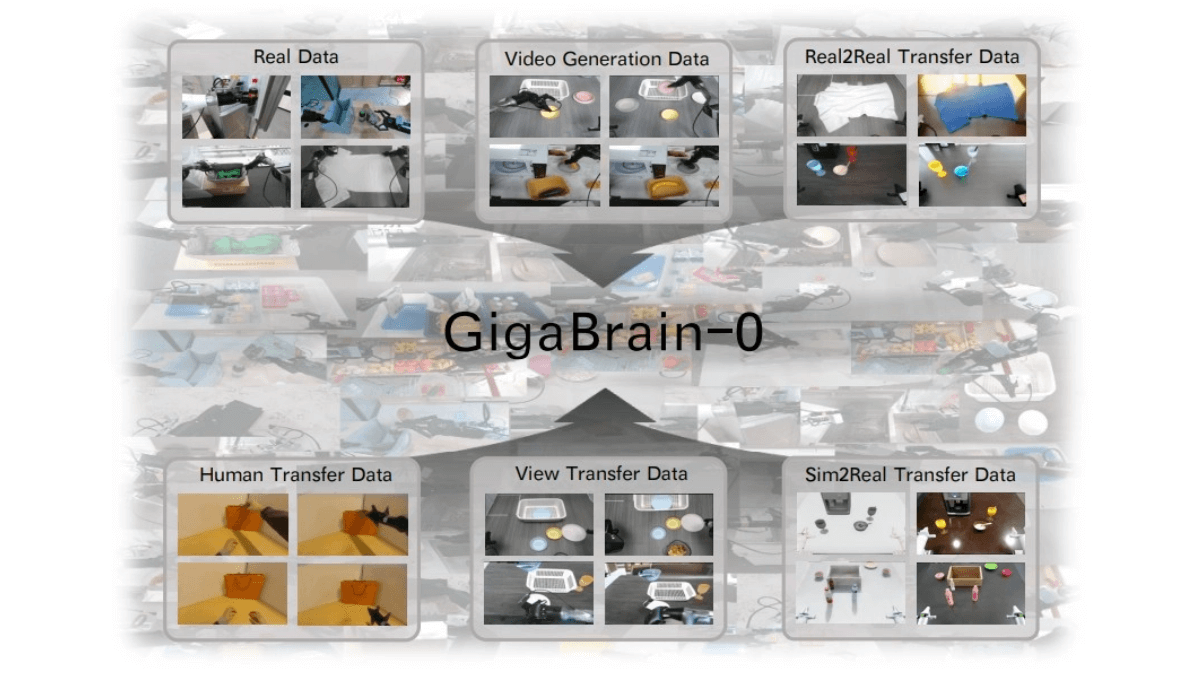
GigaBrain-0 - 开源的具身基础模型,由世界模型生成数据驱动GigaBrain-0是国内首个利用世界模型生成数据实现真机泛化的端到端视觉-语言-动作(VLA)具身基础模型,由极佳视界与湖北人形机器人创新中心联合发布开源。采用混合Transformer架构,融合...最新AI资源5个月前027.3K
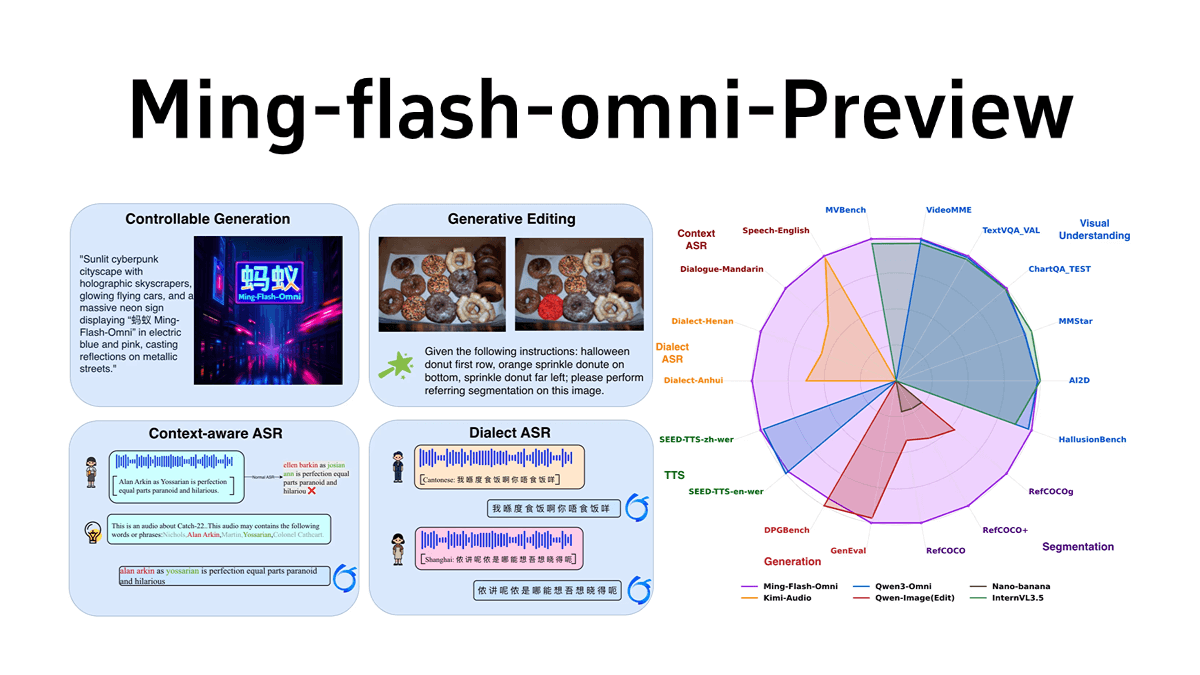
Ming-flash-omni-Preview - 蚂蚁集团开源的全模态大模型Ming-flash-omni-Preview是蚂蚁集团inclusionAI发布的开源全模态大模型,参数规模达千亿,基于Ling 2.0的稀疏MoE架构,总参数103B,激活9B。在全模态理解和生成...最新AI资源5个月前032.1K
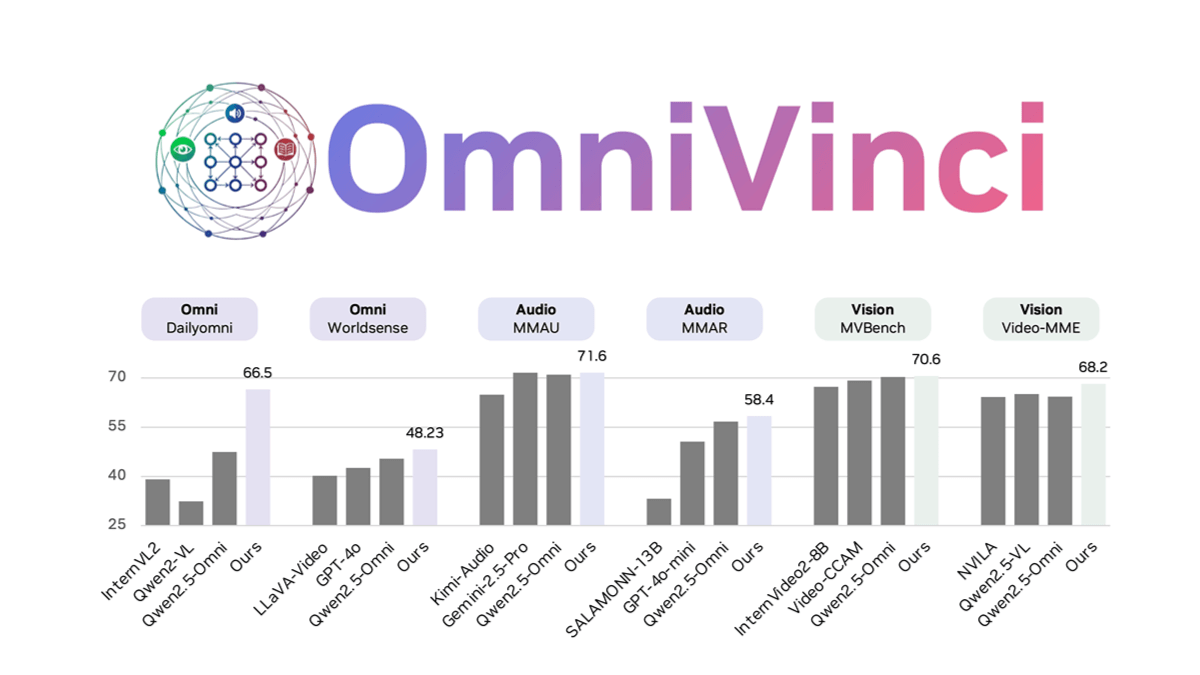
OmniVinci - NVIDIA开源的全模态大语言模型OmniVinci 是 NVIDIA 开发的开源全模态大型语言模型,通过架构革新和数据优化解决多模态模型中的模态割裂问题。通过 OmniAlignNet 加强视觉和音频嵌入的对齐,利用时间嵌入分组捕捉...最新AI资源5个月前031.7K
olmOCR 2 - AI2开源的多模态文档解析模型olmOCR 2是Allen Institute for Artificial Intelligence(AI2)开源的多模态文档解析模型,是olmOCR的升级版本。将数字化的打印文档(如 PDF)高...最新AI资源5个月前037.8K
ValueCell - 开源的多智能体金融平台,多个Agent分工协作ValueCell是开源的多智能体金融应用平台,通过AI技术提升金融分析和投资管理的效率。模拟专业投资团队,多个AI智能体分工协作,涵盖市场分析、情绪分析、基本面研究、自动交易等功能,为用户提供全面的...最新AI资源5个月前057K
Dexbotic - 原力灵机开源的具身智能VLA模型一站式科研服务平台Dexbotic是原力灵机(Dexmal)开源的具身智能视觉-语言-动作(VLA)模型一站式科研服务平台,解决具身智能领域研究碎片化、效率低等问题。以 PyTorch 为基础,为具身智能领域的研究和开...最新AI资源5个月前029K
LongCat-Video - 美团LongCat开源的视频生成模型LongCat-Video是美团LongCat团队开源的13.6亿参数视频生成模型,采用MIT开源协议,支持文生视频、图生视频和视频续写三大任务。模型通过"粗到细"生成策略和块稀疏注意力机制,能在数分...最新AI资源5个月前050.9K
DreamOmni2 - 港科大开源的多模态AI图像编辑与生成模型DreamOmni2是港科大贾佳亚团队开源的多模态AI图像编辑与生成模型。能同时处理文本和图像指令,支持多张参考图,为创作者提供更灵活的创作方式。模型采用三阶段数据合成流程进行训练,联合训练生成/编辑...最新AI资源5个月前035.7K
交叉验证(Cross-Validation)是什么,一文看懂交叉验证(Cross-Validation)是机器学习中评估模型泛化能力的核心方法,基本思想是将原始数据分割为训练集和测试集,通过轮换使用不同数据子集进行训练和验证,获得更可靠的性能估计。这种方法模拟...AI答疑5个月前031.7K
随机森林(Random Forest)是什么,一文看懂随机森林(Random Forest)是一种集成学习算法,通过构建多个决策树并综合其预测结果来完成机器学习任务。该算法基于Bootstrap聚合思想,从原始数据集中有放回地随机抽取多个样本子集,为每棵...AI答疑5个月前028.8K
损失函数(Loss Function)是什么,一文看懂损失函数(Loss Function)是机器学习中的核心概念,承担着量化模型预测误差的重要任务。这个函数通过数学方式衡量模型预测值与真实值之间的差异程度,为模型优化提供明确的方向指引。AI答疑5个月前027.6K
混元世界模型1.1 - 腾讯混元发布的开源3D重建大模型混元世界模型1.1(WorldMirror)是腾讯混元团队发布的开源3D重建大模型,是混元世界模型系列的升级版本。支持多视图图像、视频以及相机位姿、内参、深度图等多模态先验输入,突破了传统3D重建仅依...最新AI资源6个月前035K
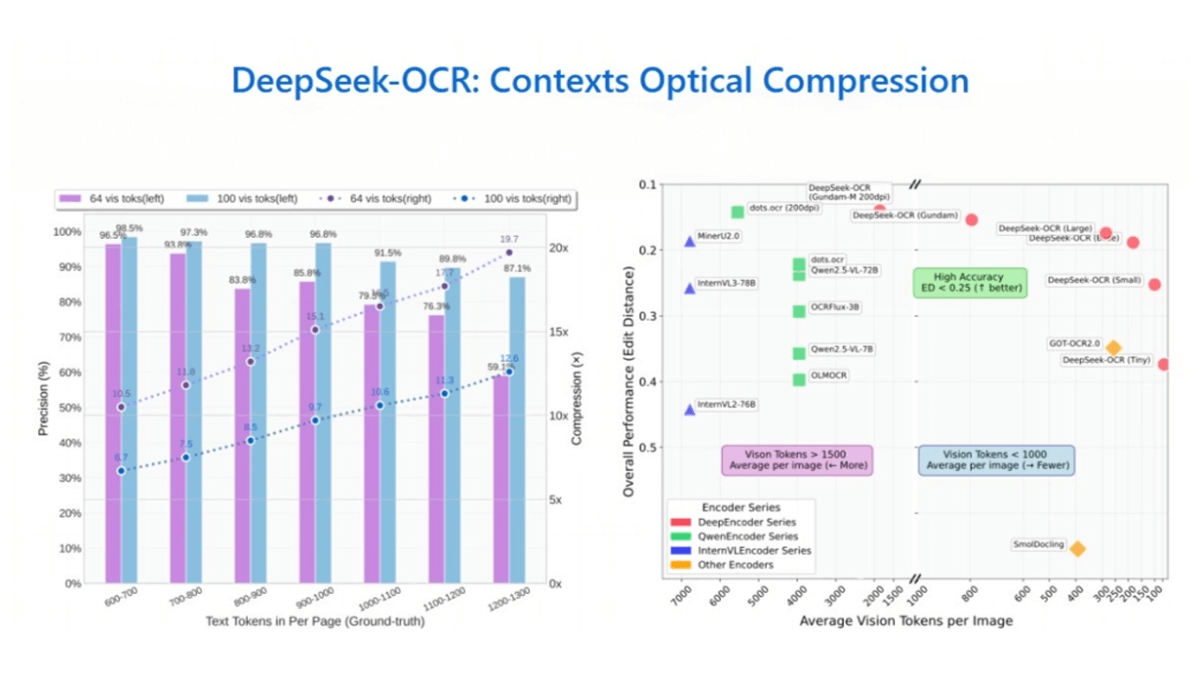
DeepSeek-OCR - DeepSeek开源的光学字符识别模型DeepSeek-OCR 是 DeepSeek 团队开源的先进光学字符识别(OCR)模型,通过“上下文光学压缩”技术,将文本转换为图像,利用视觉 token 进行压缩和解码,实现高效长文本处理。最新AI资源6个月前040.2K
VitaBench - 美团LongCat开源的交互式Agent评测基准VitaBench是美团LongCat团队发布的首个面向复杂生活场景的交互式Agent评测基准,评估大模型智能体在真实生活场景中的综合能力。以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为载体,构建包...最新AI资源6个月前031.7K
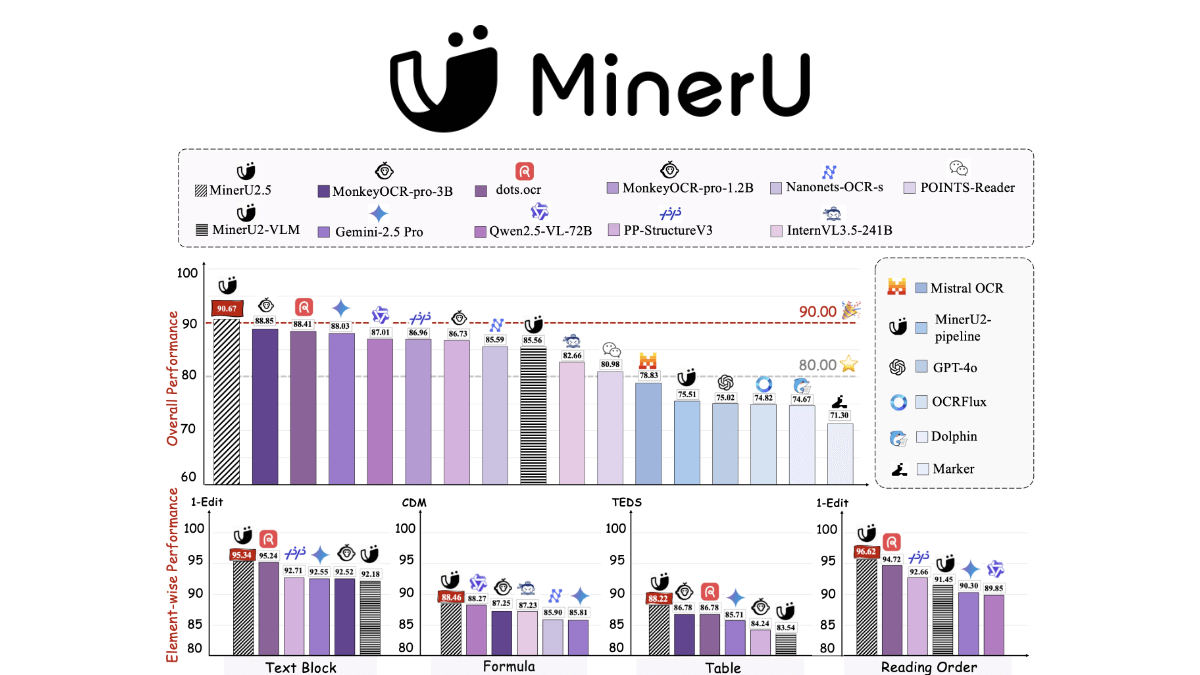
MinerU2.5 - 上海AI Lab联合北大开源的文档解析模型MinerU2.5是上海人工智能实验室与北京大学团队联合研发的解耦式视觉语言模型,专注于高效处理高分辨率文档图像解析。核心创新在于采用"先全局版面检测后局部内容识别"的两阶段设计:第一阶段通过低分辨率...最新AI资源6个月前045.8K
LongCat-Audio-Codec - 美团LongCat开源的语音编解码方案LongCat-Audio-Codec是美团LongCat团队开源的语音编解码方案。方案专为语音大语言模型(Speech LLM)设计,通过语义与声学双Token并行提取机制,兼顾语音的语义和声学特征...最新AI资源6个月前029.6K
PaddleOCR-VL - 百度开源的超轻量级视觉-语言模型PaddleOCR-VL是百度开源的超轻量级视觉-语言模型,专为文档解析场景优化。模型仅含0.9B参数,通过融合动态高分辨率视觉编码器与轻量级ERNIE语言模型,在保持高精度的同时显著降低计算开销。最新AI资源6个月前046.4K
UniPixel - 香港理工、腾讯、中科院等开源的像素级多模态模型UniPixel是香港理工大学、腾讯、中国科学院和vivo等机构联合提出的新型多模态模型,实现像素级视觉语言理解。通过统一对象指代和分割能力,支持多种细粒度任务,如图像分割、视频分割、区域理解以及Pi...最新AI资源6个月前035.1K
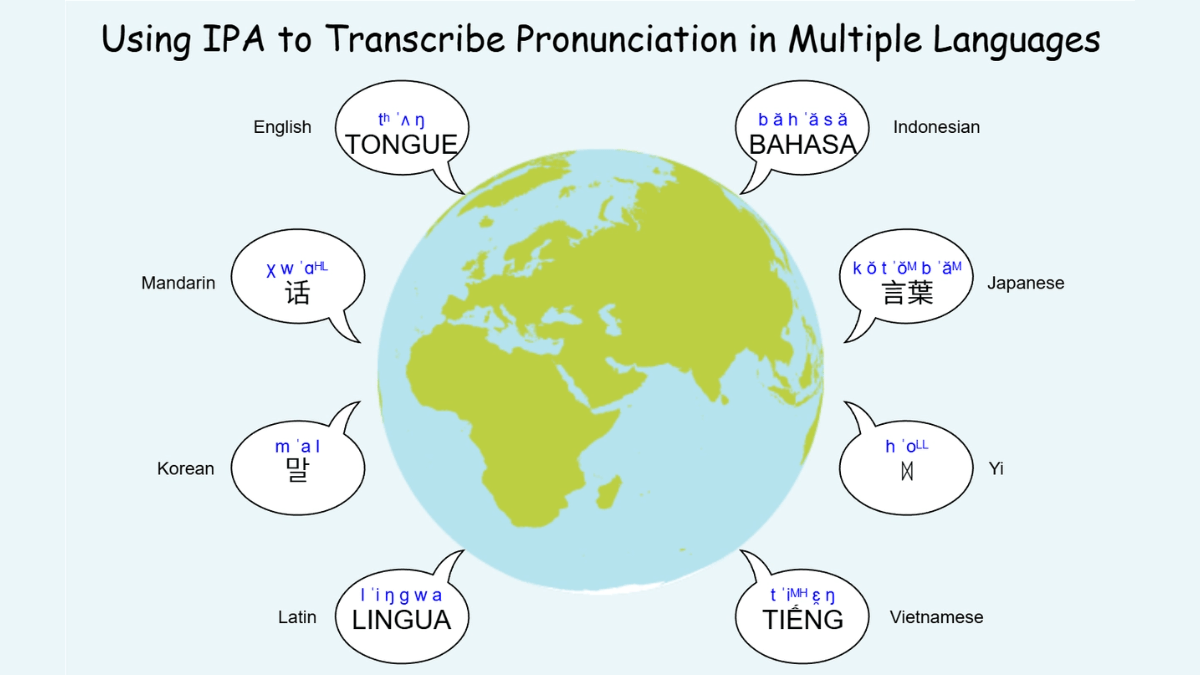
DiaMoE-TTS - 清华联合巨人网络开源的多方言语音合成框架DiaMoE-TTS 是清华大学和巨人网络联合开源的多方言语音合成框架,基于国际音标(IPA),解决方言数据稀缺、正字法不一致和音系变化复杂等问题。通过统一的 IPA 前端标准化音素表示,消除跨方言差...最新AI资源6个月前037.1K
Kandinsky 5.0 - 俄罗斯AI团队开源的视频生成模型系列Kandinsky 5.0是俄罗斯AI团队开发的最新视频生成模型系列,主打轻量化设计与高性能表现。系列首款模型Kandinsky 5.0 Video Lite仅20亿参数却超越了同类14B大模型,尤其...最新AI资源6个月前045.1K
SongBloom - 腾讯联合港中文、南大开源的歌曲生成模型SongBloom是腾讯AI Lab联合香港中文大学(深圳)与南京大学研发的开源歌曲生成模型,解决AI音乐生成中的“塑料感”问题,实现高质量、结构完整的歌曲生成。只需输入10秒参考音频和对应歌词,即可...最新AI资源6个月前035.9K