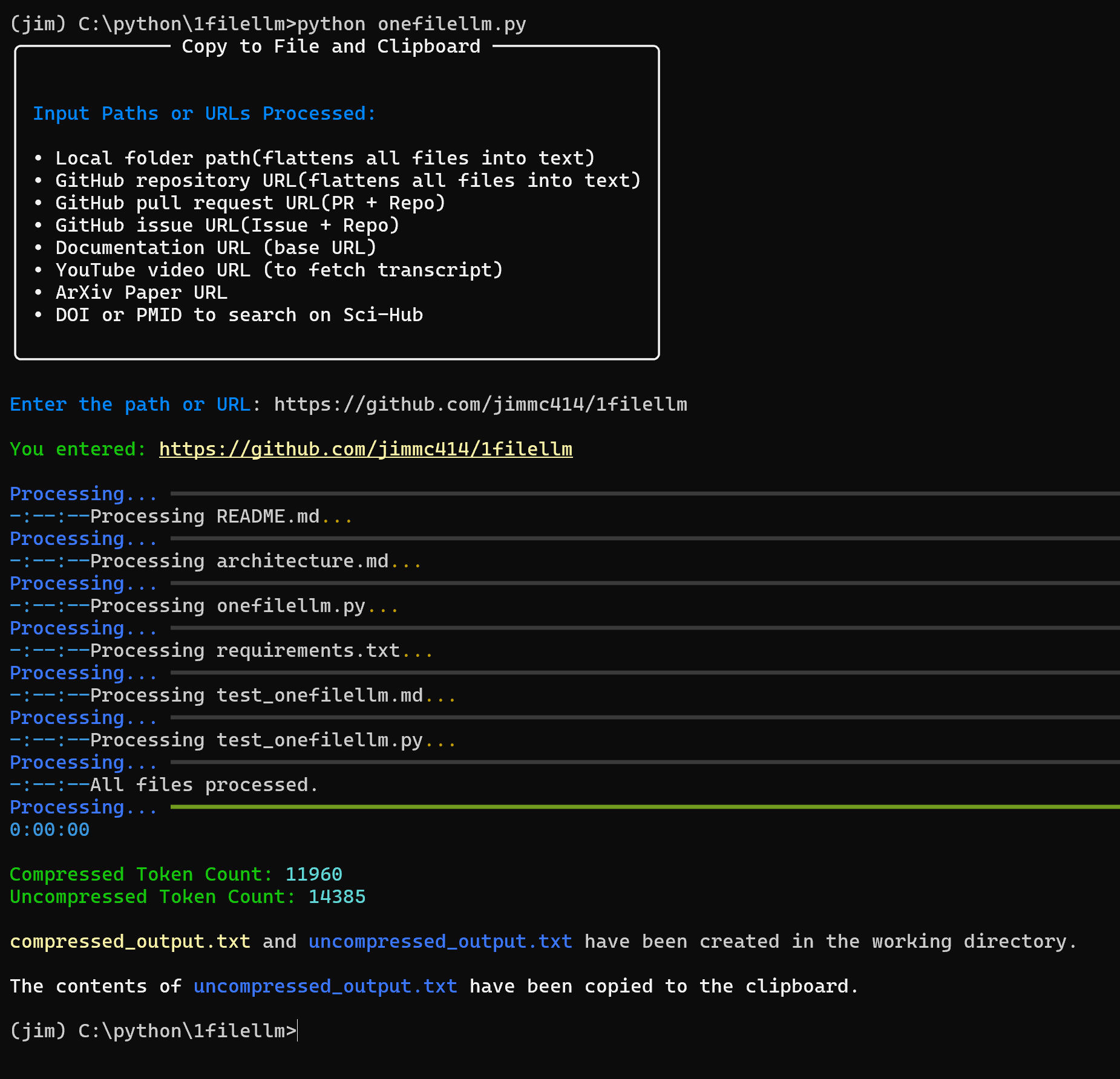
OneFileLLM:整合多种数据源为单一文本文件综合介绍 OneFileLLM 是一个开源命令行工具,旨在将多种数据源整合成单一文本文件,方便输入大语言模型(LLM)。它支持处理 GitHub 仓库、ArXiv 论文、YouTube 视频转录、网页...最新AI资源# AI开源项目# 文档提取与清洗12个月前055.7K
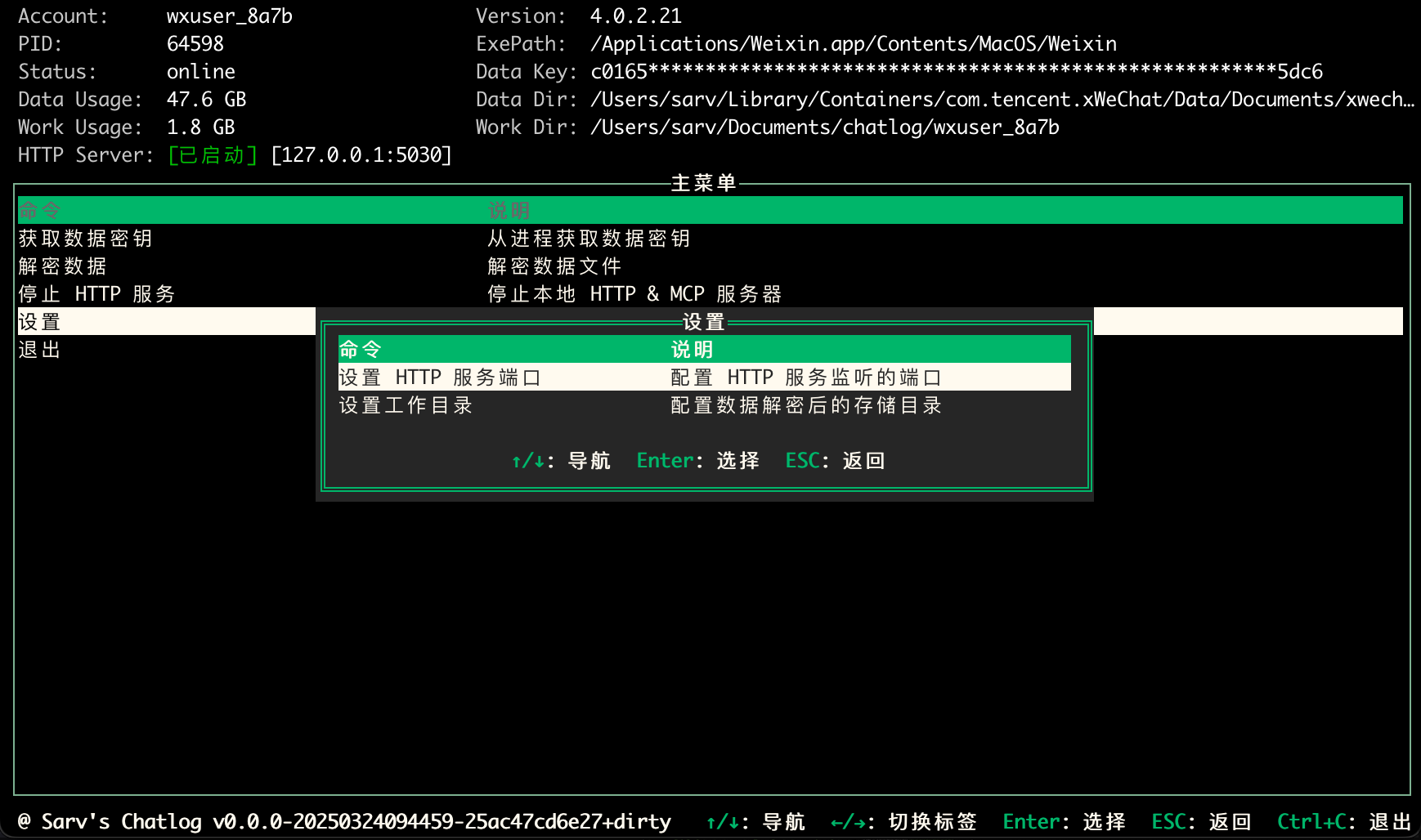
Chatlog:提取和查询微信聊天记录的开源工具综合介绍 Chatlog 是一个开源工具,专注于从微信本地数据库提取和查询聊天记录。它支持微信 3.x 和 4.0 版本,覆盖 Windows 和 macOS 系统。用户可以通过命令行、终端界面或 H...最新AI资源# AI开源项目# MCP服务# 文档提取与清洗1年前0129.8K
VOP:提取复杂图表与数学公式的OCR工具综合介绍 Versatile OCR Program 是一个开源的光学字符识别(OCR)工具,专门为处理复杂的学术和教育文档设计。它能从PDF、图像等文件中提取文本、表格、数学公式、图表和示意图,并生...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前053.1K
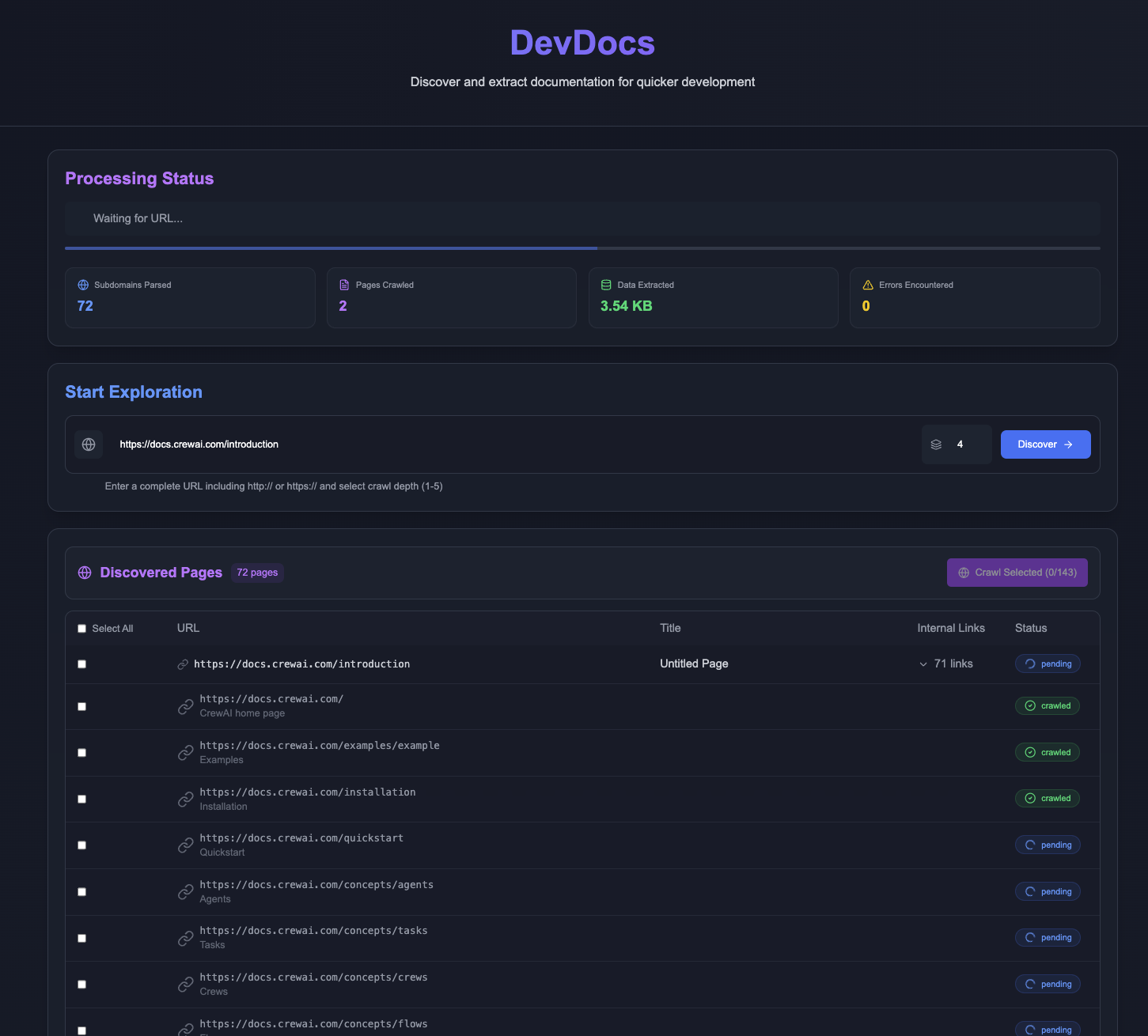
DevDocs:快速抓取并整理技术文档的MCP服务综合介绍 DevDocs 是一个完全免费的开源工具,由 CyberAGI 团队开发,托管在 GitHub 上。它专为程序员和软件开发者设计,能从技术文档的网址开始,自动爬取相关页面并整理成简洁的 Ma...最新AI资源# AI开源项目# MCP服务# 文档提取与清洗1年前058.9K
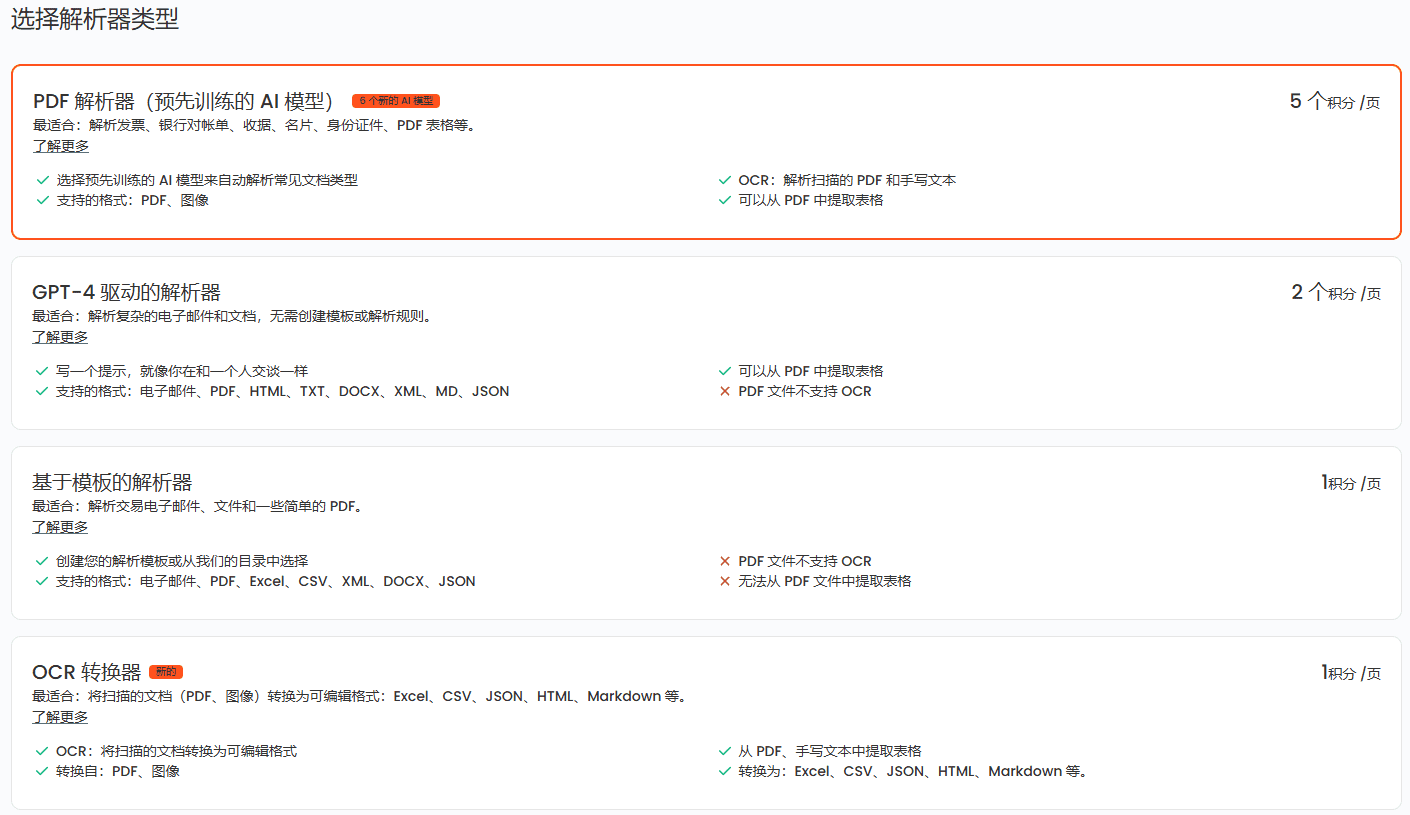
自动解析PDF内容并提取文字与表格的开源服务综合介绍 它能自动分析PDF文档的布局,识别页面中的文字、标题、图片、表格、公式等元素,并判断它们的正确顺序。工具支持OCR功能,可以把扫描PDF转为可搜索文本。它基于Docker运行,提供两种模型...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前060.2K
基于Workers AI免费将多种文件转为Markdown格式综合介绍 serverless-markdown-convertor 是一个免费的开源工具,基于 Cloudflare Worker 和 Workers AI 开发,能将多种文件转换为 Markdow...最新AI资源# AI开源项目# 文档提取与清洗1年前056.6K
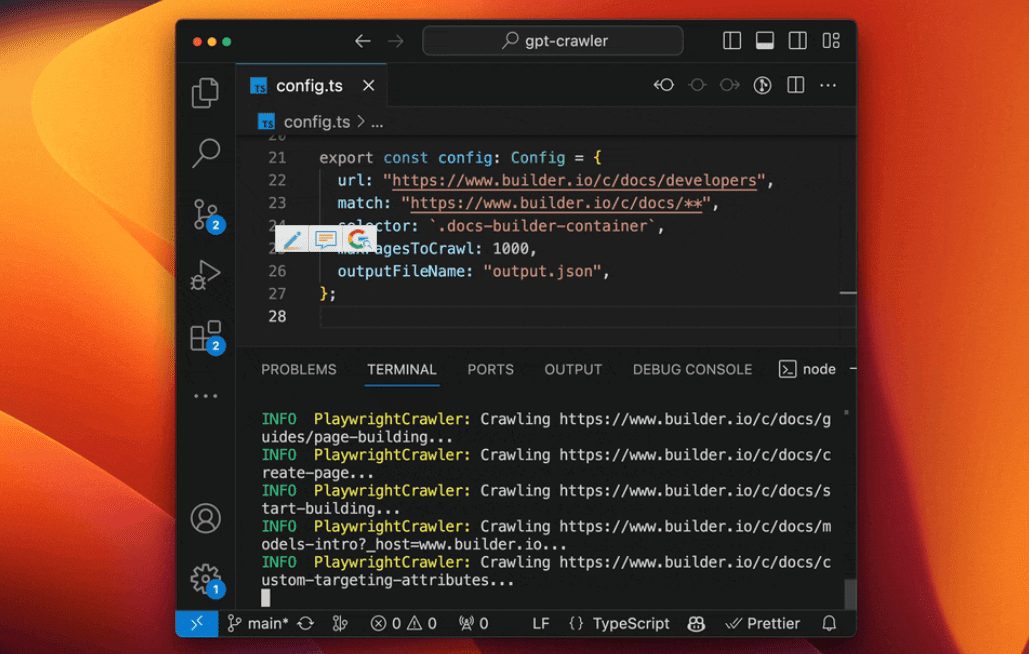
GPT-Crawler:自动爬取网站内容生成知识库文件综合介绍 GPT-Crawler 是由 BuilderIO 团队开发的一个开源工具,托管在 GitHub 上。它通过输入一个或多个网站 URL,爬取页面内容,生成结构化的知识文件(output.jso...最新AI资源# AI开源项目# 文档提取与清洗10个月前058.4K
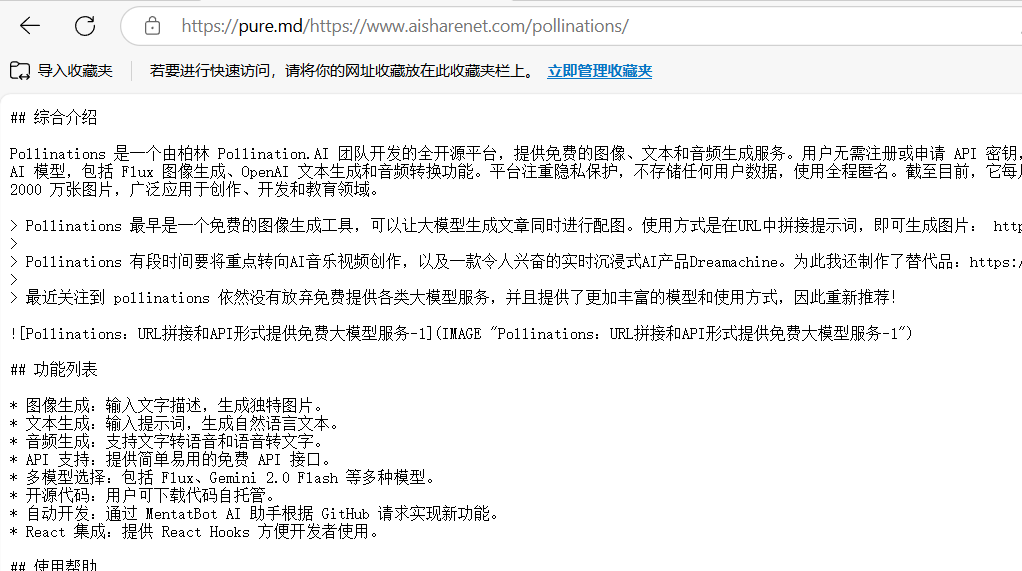
pure.md:网址前插入“pure.md/”即可提取干净的文本综合介绍 pure.md 是一个为 AI 代理和开发者设计的工具,主打快速将网页内容或文件转为 Markdown 格式。它通过代理服务绕过反爬虫限制,提取网页核心数据,并输出简洁的 Markdown ...最新AI资源# AI开放服务# 文档提取与清洗1年前064.2K
Cloudsquid:上传文档并描述要求智能提取结构化数据综合介绍 Cloudsquid 是一家 2023 年成立于德国柏林的公司,专注于用人工智能简化文件处理。它的核心产品是一个在线数据提取平台,用户只需上传 PDF、图片、音频、视频等文件,简单说明需要提...最新AI资源# 文档提取与清洗1年前055.9K
PDF Craft:PDF扫描文件转Markdown的开源工具综合介绍 PDF Craft 是一个开源工具,专为扫描书籍的PDF设计,能将其转换为Markdown格式。它由 oomol-lab 开发,托管在 GitHub 上,适合喜欢整理电子书的用户。工具通过本...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前082.8K
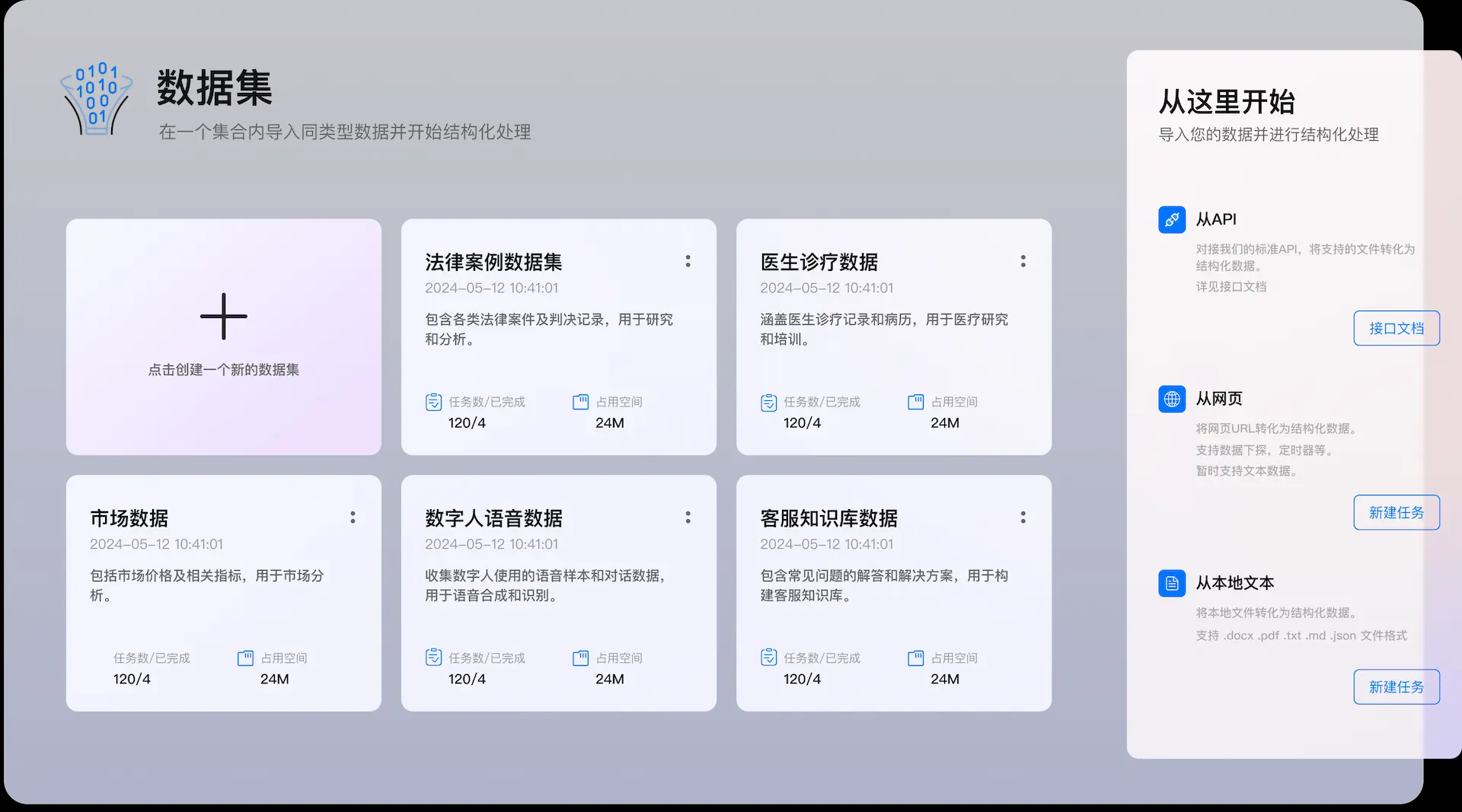
Supametas.AI:提取非结构化数据为LLM高可用数据综合介绍 Supametas.AI 是一个数据处理平台,专门把网页、文档、音视频等杂乱信息整理成AI能用的结构化数据。它支持从多个来源收集数据,包括网页链接、API、本地文件等,然后输出为 JSON ...最新AI资源# AI开放服务# 文档提取与清洗1年前056.1K
MarkPDFDown:基于多模态模型将PDF转为Markdown文件综合介绍 MarkPDFDown 是一个开源工具。它利用多模态大语言模型,把 PDF 文件转为 Markdown 格式。开发者是 GitHub 用户 jorben。这个工具的目标很简单:让 PDF 文...最新AI资源# AI开源项目# 文档提取与清洗1年前061.8K
SmolDocling:小体积高效处理文档的视觉语言模型综合介绍 SmolDocling 是由 ds4sd 团队与 IBM 合作开发的一个视觉语言模型(VLM),基于 SmolVLM-256M 打造,托管在 Hugging Face 平台。它体积小,只有 ...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前053K
飞桨 PP-TableMagic:复杂表格结构化信息提取神器表格识别的目标是解析图片中的表格,准确识别表格结构和单元格位置,并将其还原为结构化的表格格式(例如 HTML)。在当今信息化时代,大量重要的表格数据仍以非结构化状态存在(如扫描文档中的信息统计表图片...最新AI资源# AI开源项目# 文档提取与清洗1年前067.9K
Mistral OCR:94.89%总体精度,1000 页/30秒,只需1美元在人类文明的历史长河中,每一次信息获取和解析方式的飞跃,都深刻地推动着社会进步。从远古的象形文字,到便携的纸莎草,再到后来出现的印刷术以及当今的数字化浪潮,每一次技术革新都极大地拓展了人类知识的传播范...最新AI资源# AI开放服务# OCR# 文档提取与清洗1年前061.1K
Firecrawl MCP Server:基于 Firecrawl 的网页爬虫 MCP 服务综合介绍 Firecrawl MCP Server 是由 MendableAI 开发的一款开源工具,基于 Model Context Protocol (MCP) 协议实现,与 Firecrawl A...最新AI资源# AI开源项目# MCP服务# 文档提取与清洗1年前074.2K
olmOCR:PDF文档转换为文本,支持表格、公式和手写内容的识别综合介绍 olmOCR 是由 Allen Institute for Artificial Intelligence (AI2) 的 AllenNLP 团队开发的一款开源工具,专注于将 PDF 文件转...最新AI资源# AI开源项目# 文档提取与清洗1年前069.9K
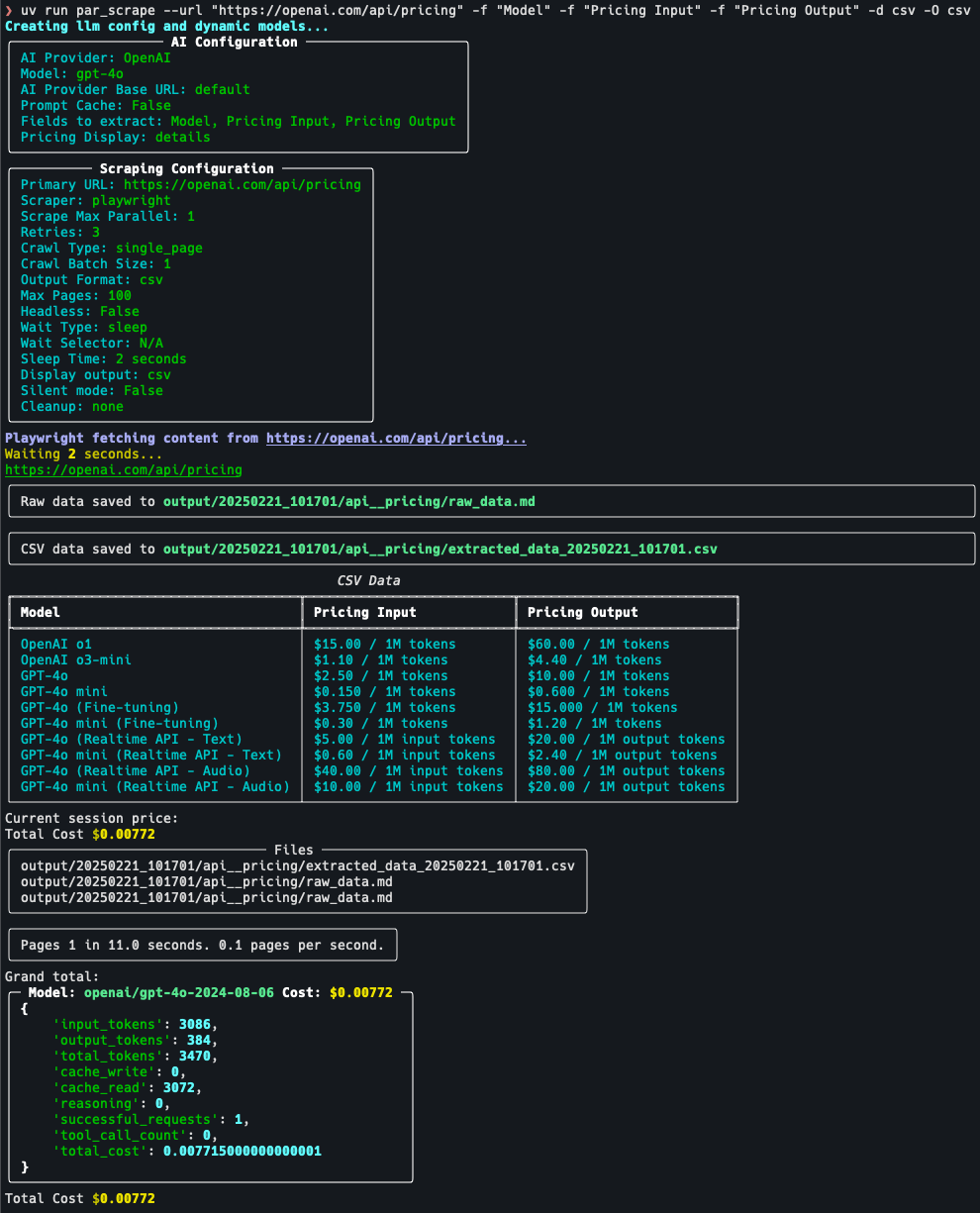
par_scrape:智能提取网页数据的爬虫工具综合介绍 par_scrape 是一个基于 Python 的开源网页爬虫工具,由开发者 Paul Robello 在 GitHub 上推出,旨在帮助用户从网页中智能提取数据。它整合了 Selenium...最新AI资源# AI开源项目# 文档提取与清洗1年前056.1K
PDF-Extract-Kit:提取复杂结构PDF内容的开源工具综合介绍 PDF-Extract-Kit 是一个由 OpenDataLab 团队开发的开源项目,专注于从复杂多样的 PDF 文档中高效提取高质量内容。它集成了先进的文档解析技术,支持布局检测、公式识别...最新AI资源# AI开源项目# 文档提取与清洗1年前0106.1K
Crawl4LLM:为LLM预训练提供的高效网页爬取工具综合介绍 Crawl4LLM 是一个由清华大学和卡内基梅隆大学联合开发的开源项目,专注于优化大模型(LLM)预训练的网页爬取效率。它通过智能选择高质量网页数据,显著减少无效爬取,号称能将原本需要爬取1...最新AI资源# AI开源项目# 文档提取与清洗1年前058.1K
Markdownify MCP Server:基于MCP协议将各种内容转换为Markdown格式综合介绍 Markdownify MCP Server 是一个基于 Model Context Protocol(模型上下文协议)的开源工具,托管于 GitHub,由开发者 Zach Caceres ...最新AI资源# AI开源项目# MCP服务# 文档提取与清洗1年前066.3K
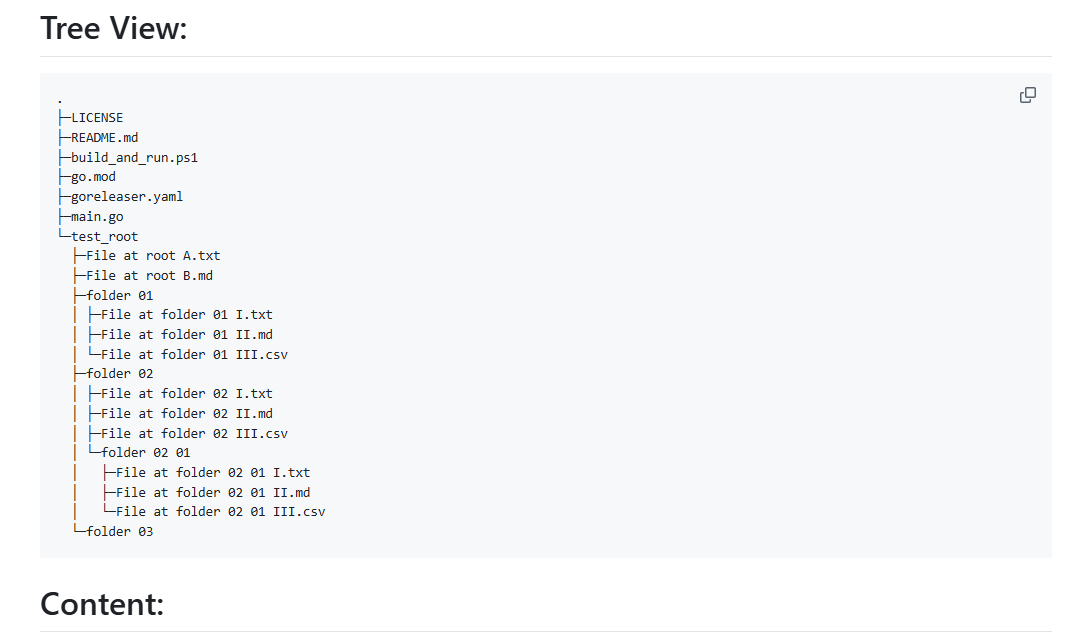
CodeWeaver:将代码结构和内容自动生成Markdown文档综合介绍 CodeWeaver 是一个命令行工具,旨在将代码库编织成单个、易于浏览的Markdown文档。它通过递归扫描目录,生成项目文件层次结构的结构化表示,并在代码块中嵌入每个文件的内容。这款工具...最新AI资源# AI开源项目# 文档提取与清洗1年前060K
Kreuzberg:从任何文档中提取文本的开源工具综合介绍 Kreuzberg是一个用于简化PDF文件文本提取的库,旨在提供简单、无忧的文本提取解决方案。该库特别适合需要进行文本提取的RAG(Retrieval-Augmented Generatio...最新AI资源# AI开源项目# 文档提取与清洗1年前062.5K
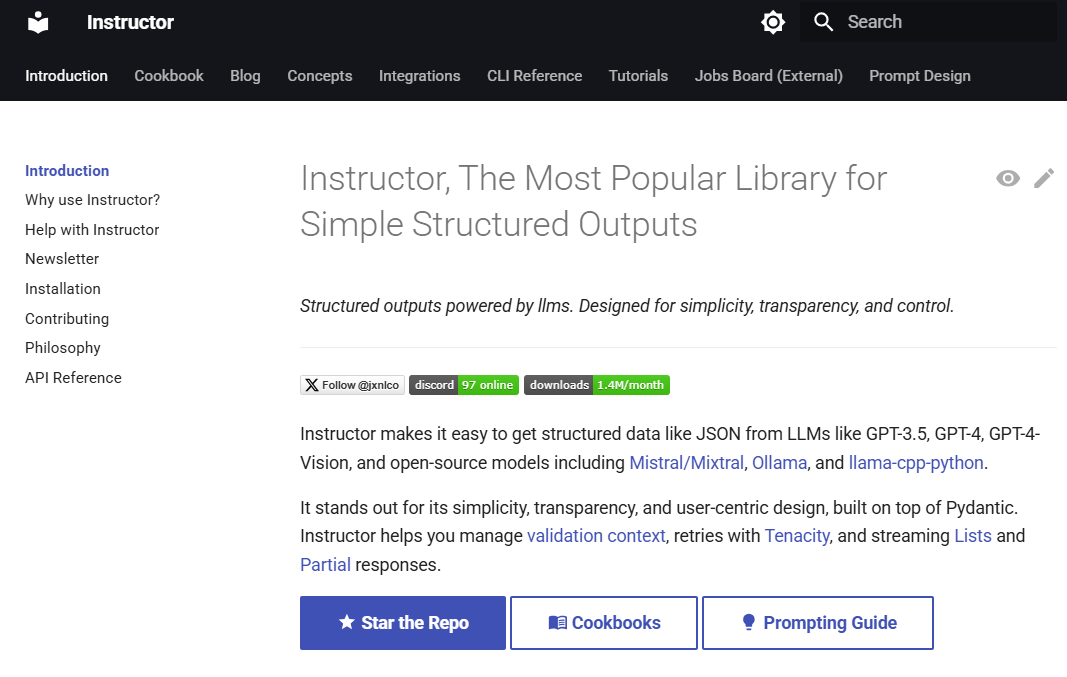
Instructor:简化大语言模型结构化输出工作流的Python库综合介绍 Instructor 是一个流行的 Python 库,专为处理大语言模型(LLMs)的结构化输出而设计。它基于 Pydantic 构建,提供了一个简单、透明且用户友好的 API,用于管理数据...最新AI资源# AI开源项目# 文档提取与清洗1年前055.8K
zChunk:基于Llama-70B的通用语义分块策略综合介绍 zChunk是由ZeroEntropy开发的一种新型分块策略,旨在为通用语义分块提供解决方案。该策略基于Llama-70B模型,通过提示生成分块,优化了文档的分块过程,确保在信息检索时保持高...最新AI资源# AI开源项目# 文档提取与清洗1年前051K
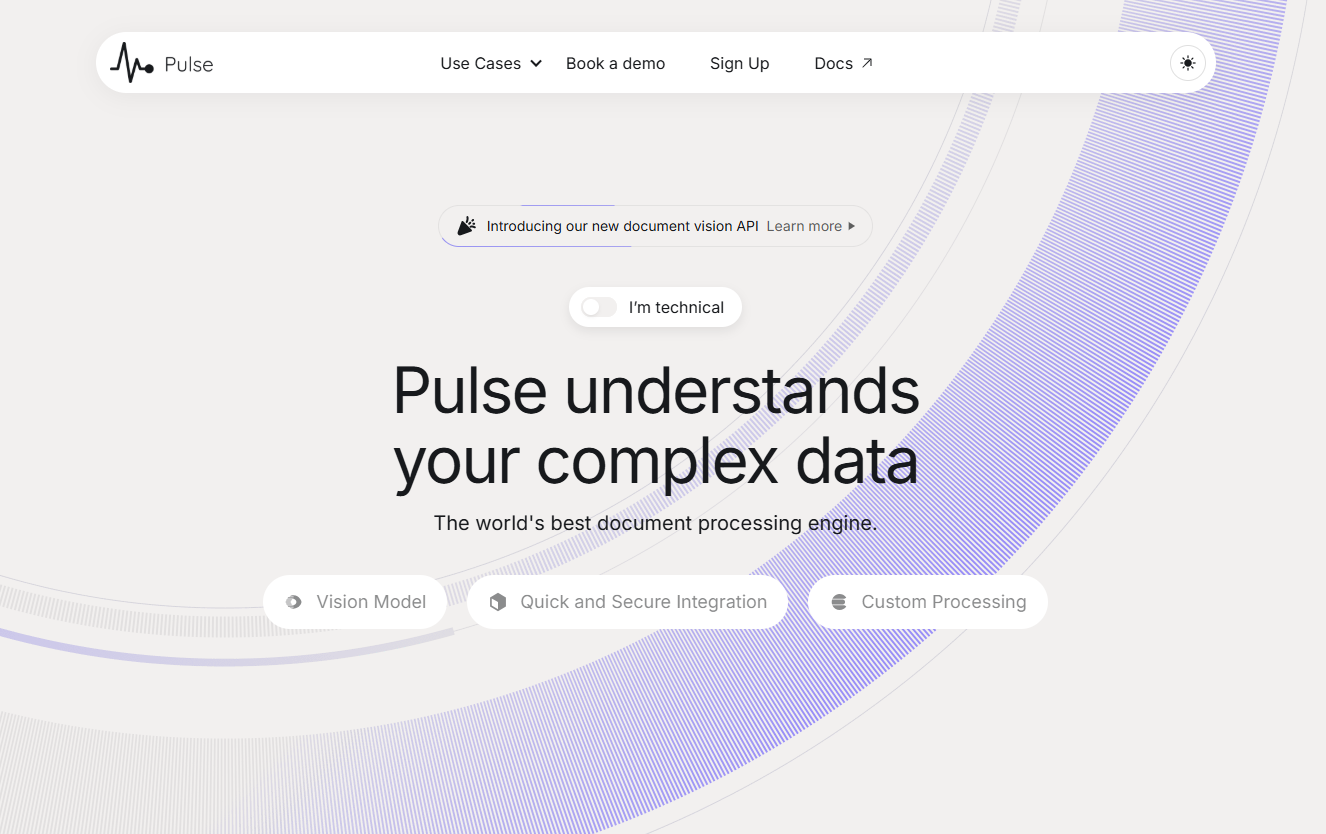
Pulse:文档处理与数据提取的商业解决方案综合介绍 Pulse 是一个专注于文档处理和数据提取的智能平台,旨在帮助企业和开发者高效地解析和处理各种复杂文档。通过其先进的计算机视觉和多模态处理技术,Pulse 能够准确地从文本、图像、表格等多种...最新AI资源# 文档提取与清洗1年前054.9K
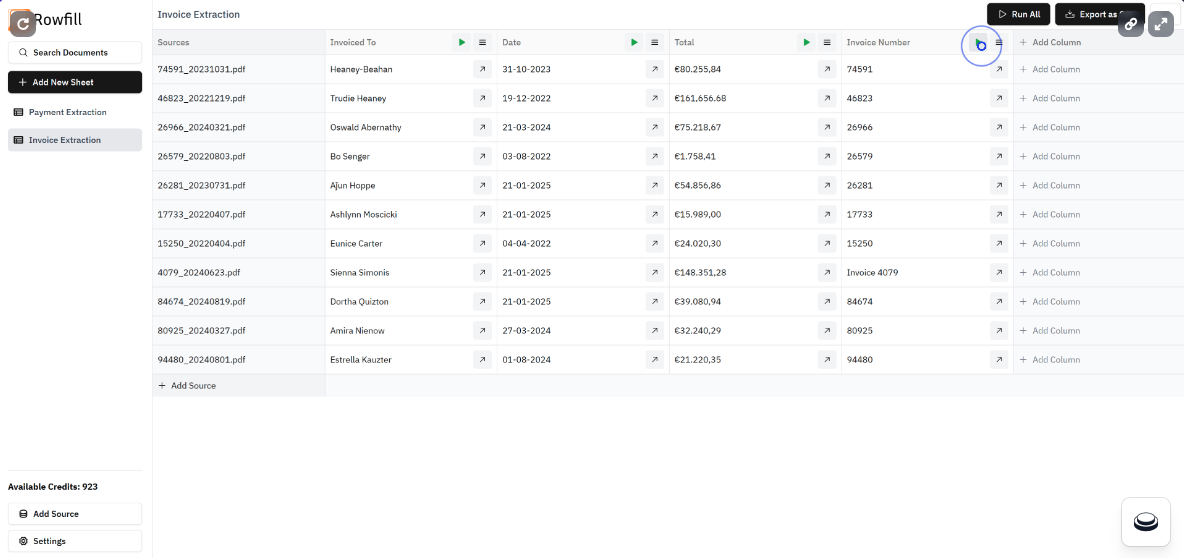
Rowfill:批量提取文档结构化信息并自动化分析综合介绍 Rowfill 是一个开源的文档处理平台,专为知识工作者设计。它利用先进的人工智能技术,从复杂的文档、图像和PDF中提取、分析和处理数据。Rowfill 支持本地大语言模型(LLM)和Ope...最新AI资源# AI开源项目# AI数据分析# 文档提取与清洗1年前054.7K
PPTX2MD:将PPTX文件转换为Markdown的专用工具综合介绍 PPTX2MD是一个开源工具,旨在将PowerPoint的PPTX文件转换为Markdown格式。该工具由GitHub用户ssine开发,支持保留标题、列表、文本格式(如粗体、斜体、颜色和超...最新AI资源# AI开源项目# 文档提取与清洗1年前079.3K
Repomix:打包代码库为一个文本文件以便大模型检索综合介绍 Repomix(前称Repopack)是一款开源工具,专门用于将整个代码库打包成一个单一的、AI友好的文件。这个工具可以让开发者轻松地将他们的代码库提供给大语言模型(如Claude、Chat...最新AI资源# AI开源项目# 文档提取与清洗1年前090.7K
Yek:读取git仓库文本文件并快速分块,以供大模型使用综合介绍 Yek 是一个基于 Rust 的快速工具,用于读取存储库或目录中的文本文件,将其分块并序列化以供大型语言模型(LLM)使用。该工具默认使用 .gitignore 规则跳过不需要的文件,并利用...最新AI资源# AI开源项目# 文档提取与清洗1年前058.9K
LlamaParse:Llamaindex推出的高品质解析文档,提取数据服务(每日免费提取1000页)综合介绍 LlamaParse 是一个强大的文档解析工具,能够处理复杂的文档如 PDF、PowerPoint、Word 文档和电子表格,并将其转换为结构化数据。LlamaParse 提供多种使用方式...最新AI资源# AI开放服务# 文档提取与清洗1年前069.5K
UnDatas.IO:精准解析各类非结构化数据的API服务(付费)综合介绍 UnDatas.IO 是一个专注于解析和处理非结构化数据的平台。它利用先进的技术,自动识别文档布局,分类表格、图像、公式和文本,极大地简化了数据处理流程。该平台不仅能够节省大量的数据整理时间...最新AI资源# AI开放服务# 文档提取与清洗1年前053.4K
Zerox:PDF、DOCX、图像转换为Markdown,视觉模型高精度OCR综合介绍 Zerox是一个开源项目,旨在通过视觉模型将PDF、DOCX、图像等文件转换为Markdown格式。该项目由getomni-ai团队开发,提供了简单高效的OCR(光学字符识别)解决方案。Ze...最新AI资源# AI开源项目# 文档提取与清洗1年前077.6K
SemHash:快速实现语义文本去重,提升数据清理效率综合介绍 SemHash 是一个轻量级且灵活的工具,用于通过语义相似性来去重数据集。它结合了 Model2Vec 的快速嵌入生成和 Vicinity 的高效 ANN(近似最近邻)相似性搜索。SemHa...最新AI资源# AI开源项目# 文档提取与清洗1年前072.1K
Parseur:自动化提取文档数据,各类文档中提取结构化文本综合介绍 Parseur是一款领先的AI数据提取软件,旨在帮助用户从PDF、电子邮件和其他文档中自动提取文本数据。通过Parseur,用户可以轻松地将非结构化数据转换为结构化数据,并将其发送到各种应用...最新AI资源# 文档提取与清洗1年前060.8K
AI Functions:将输入内容转换为结构化输出的(API)服务综合介绍 Weco AI Functions 是一个强大的平台,旨在帮助用户快速构建和部署AI功能。通过简单的描述任务,用户可以生成结构化的输出模式,并进行A/B测试和观察性监控。该平台支持无代码原型...最新AI资源# AI开放服务# 文档提取与清洗1年前052.7K
NV Ingest:解析复杂格式文档,提取多模态数据为元数据和文本综合介绍 NV Ingest(NVIDIA Ingest) 是一套早期访问的微服务,专为解析数十万复杂、混乱的非结构化 PDF 和其他企业文档而设计。它能够将这些文档转换为元数据和文本,以便嵌入到检索...最新AI资源# AI开源项目# 文档提取与清洗1年前064.3K
Trellis:转换非结构文档为结构化EXCEL格式数据,PDF快速转表格(付费)综合介绍 Trellis是一款专注于将复杂的非结构化数据源转换为结构化SQL格式的数据平台。通过其强大的AI引擎,Trellis能够处理金融文档、语音通话和电子邮件等多种数据源,并将其转换为可供数据和...最新AI资源# 文档提取与清洗1年前051.1K
Ollama OCR:使用Ollama中视觉模型提取图像中的文本综合介绍 Ollama OCR是一个强大的光学字符识别(OCR)工具包,它利用Ollama平台提供的最先进视觉语言模型来从图像中提取文本。该项目既可作为Python包使用,也提供了用户友好的Strea...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前0106.4K
llms.txt Generator:快速抓取网站内容并,生成LLM训练文本数据集综合介绍 llmstxt-generator 是一个专业的网站内容提取和整合工具,专门为大语言模型(LLM)的训练和推理准备高质量文本数据集。该工具由 Mendable AI 开发,采用 @firec...最新AI资源# AI开源项目# 文档提取与清洗1年前055.7K
Doc2X:文档图片公式识别与转换工具,支持多格式转换与高精度翻译综合介绍 Doc2X 是一款功能强大的文档图片公式识别与转换工具,致力于提供高效智能的文档处理解决方案。无论是学术科研论文、教辅书籍、企业文档还是财报研报,Doc2X 都能精准识别 PDF 中的表格和...最新AI资源# AI开放服务# AI翻译# 文档提取与清洗1年前089K
ExtractThinker:提取和分类文档为结构化数据,优化文档处理流程综合介绍 ExtractThinker 是一个灵活的文档智能工具,利用大型语言模型(LLMs)从文档中提取和分类结构化数据,提供类似 ORM 的无缝文档处理工作流。它支持多种文档加载器,包括 Tess...最新AI资源# AI开源项目# 文档提取与清洗1年前061.6K
HtmlRAG:构建高效HTML检索增强生成系统,优化RAG系统中的HTML文档检索与处理综合介绍 HtmlRAG是一个创新的开源项目,专注于改进检索增强生成(RAG)系统中的HTML文档处理方法。该项目提出了一种新颖的方法,认为在RAG系统中使用HTML格式比纯文本更有效。项目包含了完整...最新AI资源# 文档提取与清洗# 知识检索与RAG框架1年前057.6K
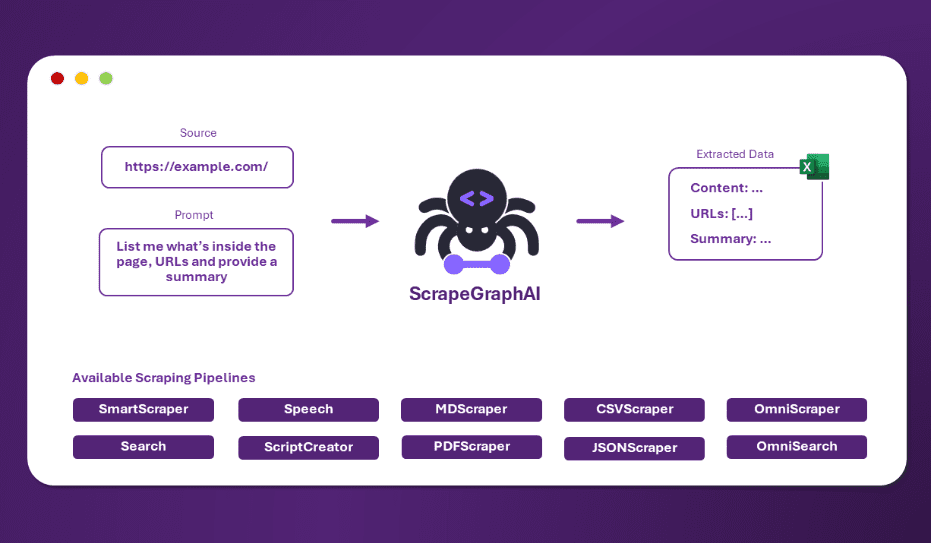
ScrapeGraphAI:一个提示词搞定网页抓取,无需编写规则智能网页内容提取工具综合介绍 ScrapeGraphAI是一个创新的Python网页抓取库,它巧妙地结合了大语言模型(LLM)和直接图逻辑来创建网站和本地文档的抓取管道。这个工具的独特之处在于它的简单性和强大功能的完美平...最新AI资源# AI开源项目# 文档提取与清洗1年前058.7K
Vision Parse:使用视觉语言模型将PDF文档智能转换为Markdown格式综合介绍 Vision Parse是一个革命性的文档处理工具,它巧妙地结合了最先进的视觉语言模型(Vision Language Models)技术,能够将PDF文档智能转换为优质的Markdown格...最新AI资源# AI开源项目# 文档提取与清洗1年前057.1K
Outlines:通过正则表达式、JSON或Pydantic模型生成结构化文本输出综合介绍 Outlines 是一个由 dottxt-ai 开发的开源库,旨在通过结构化文本生成来提升大语言模型(LLM)的应用能力。该库支持多种模型集成,包括 OpenAI、transformers...最新AI资源# AI开源项目# 文档提取与清洗1年前085K
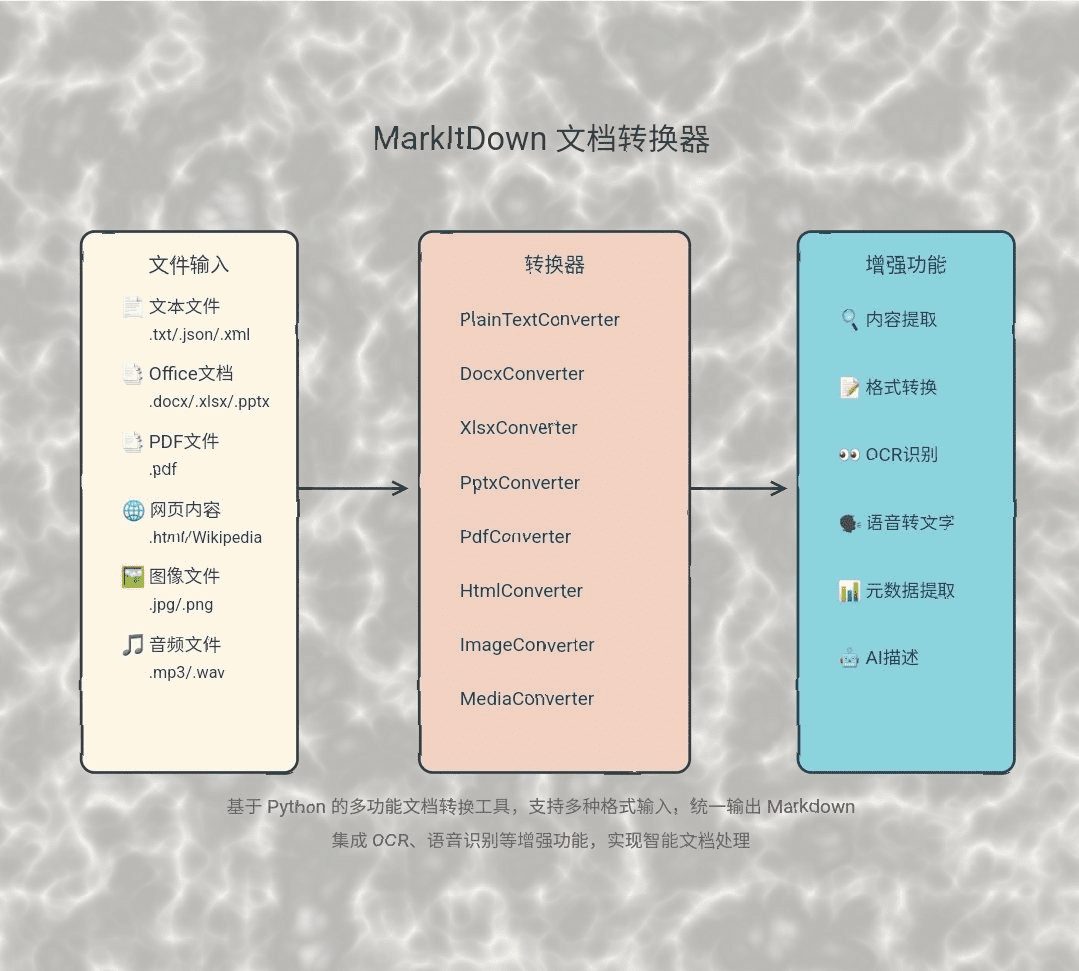
MarkItDown:微软文档智能转换工具,转换各种文件为Markdown格式综合介绍 MarkItDown是由微软开发的一个Python工具,旨在将各种文件和办公文档转换为Markdown格式。该工具支持多种文件类型,包括PDF、PowerPoint、Word、Excel、图...最新AI资源# AI开源项目# 文档提取与清洗1年前065K
Chunkr:使用视觉模型进行文档摄取以及根据文本段落层级智能分块的一体化服务综合介绍 Chunkr 是一个自托管的 API,专门用于将 PDF、PPTX、DOCX 和 Excel 文件转换为适合 RAG(检索增强生成)和 LLM(大语言模型)使用的数据。该项目由 Lumina...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前055.5K
GitIngest:快速将Github代码仓库转为适合LLM理解的文本综合介绍 GitIngest 是一个开源工具,旨在将 GitHub 代码库转化为适合大语言模型(LLM)提示的文本。通过简单的操作,用户可以将任何 GitHub 仓库的内容提取并格式化为适合 LLM ...最新AI资源# AI开源项目# 文档提取与清洗1年前081.9K
E2M:将多种文件格式转换为Markdown,轻松实现文档格式统一综合介绍 E2M(Everything to Markdown)是一个开源的Python库,旨在将多种文件格式转换为Markdown格式。该工具支持包括doc、docx、epub、html、htm、u...最新AI资源# AI开源项目# 文档提取与清洗1年前061.7K
Docling:支持多种格式文档解析并导出为Markdown和JSON,PDF支持OCR综合介绍 Docling 是一个强大的文档解析和导出工具,支持多种文档格式,包括 PDF、DOCX、PPTX、XLSX、图像、HTML、AsciiDoc 和 Markdown。它能够将这些文档解析并导...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前0109.7K
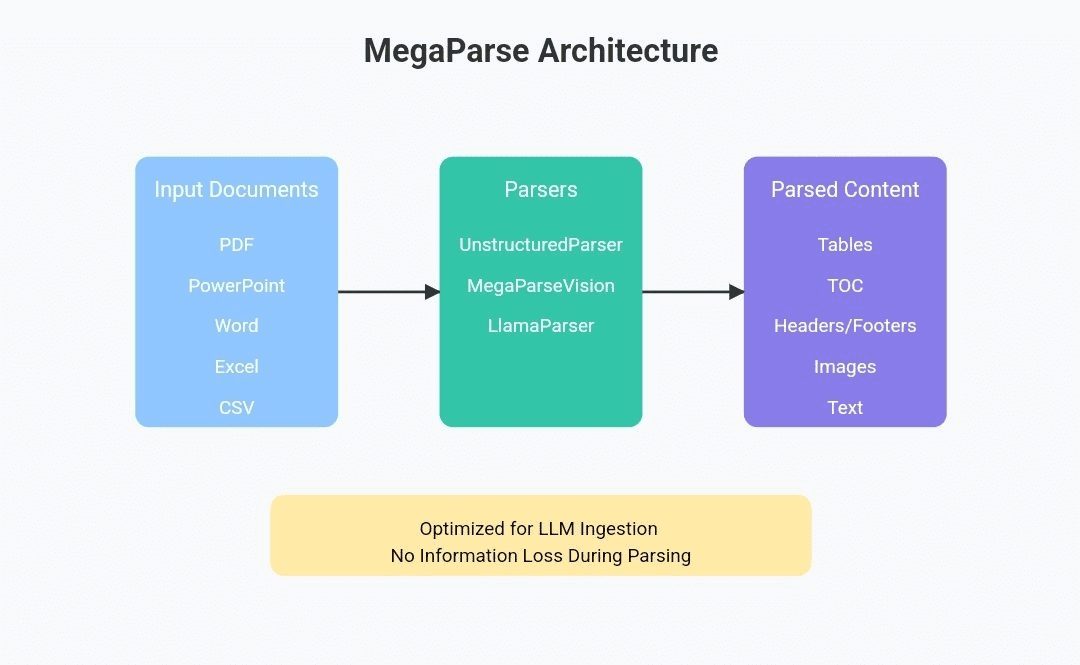
MegaParse:解析各类型文档为LLM可用数据,完整保留文档中的表格、图片等所有信息综合介绍 MegaParse 是一个强大且多功能的文件解析工具,专为大语言模型(LLM)的数据处理优化而设计。无论是处理文本、PDF、PowerPoint 演示文稿还是 Word 文档,MegaPar...最新AI资源# AI开源项目# 文档提取与清洗1年前063.8K
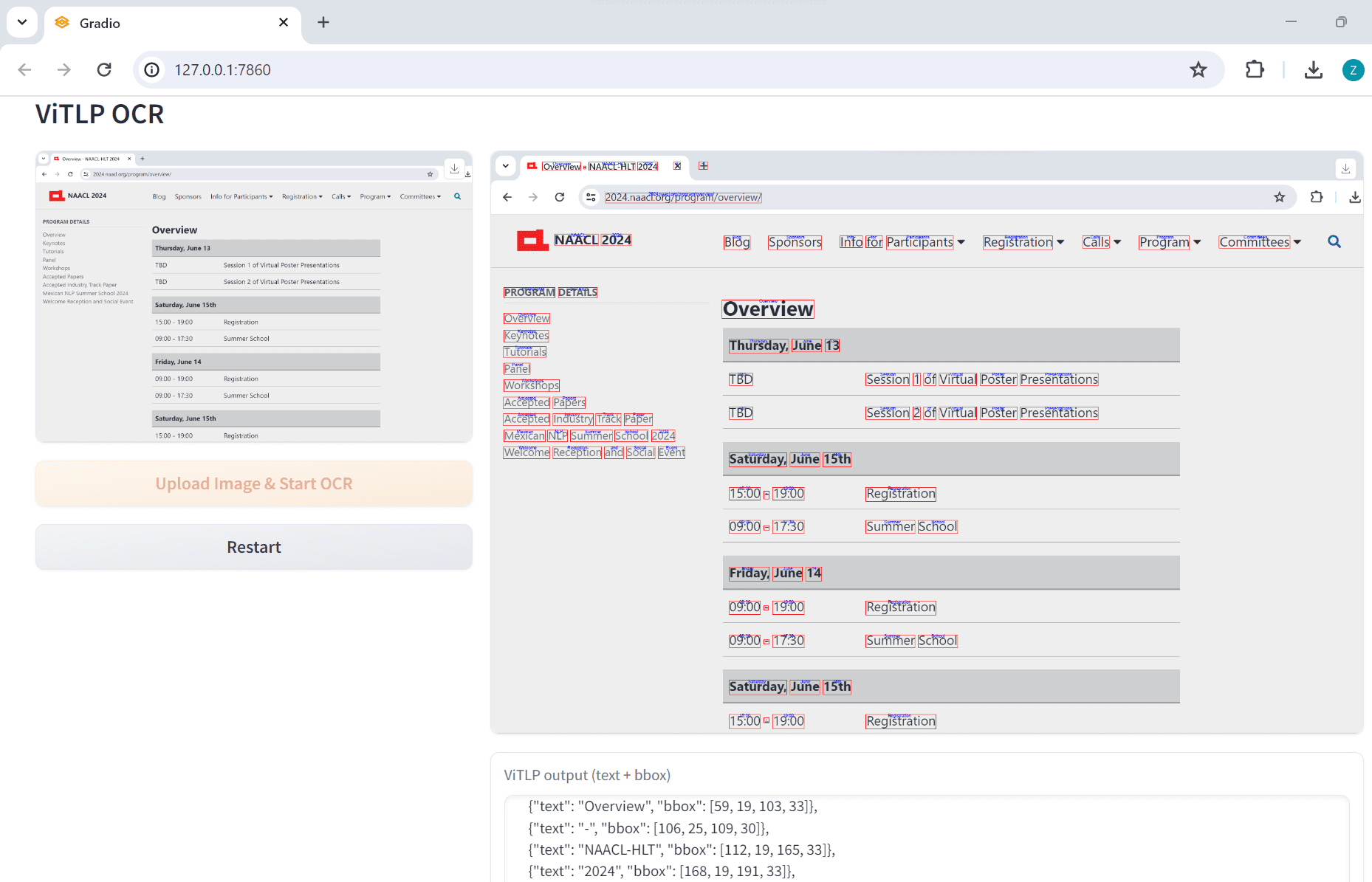
ViTLP:排版复杂PDF文档提取结构化数据,视觉引导生成文本布局预训练模型综合介绍 ViTLP(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)是一个开源项目,旨在通...最新AI资源# OCR# 文档提取与清洗1年前054.7K
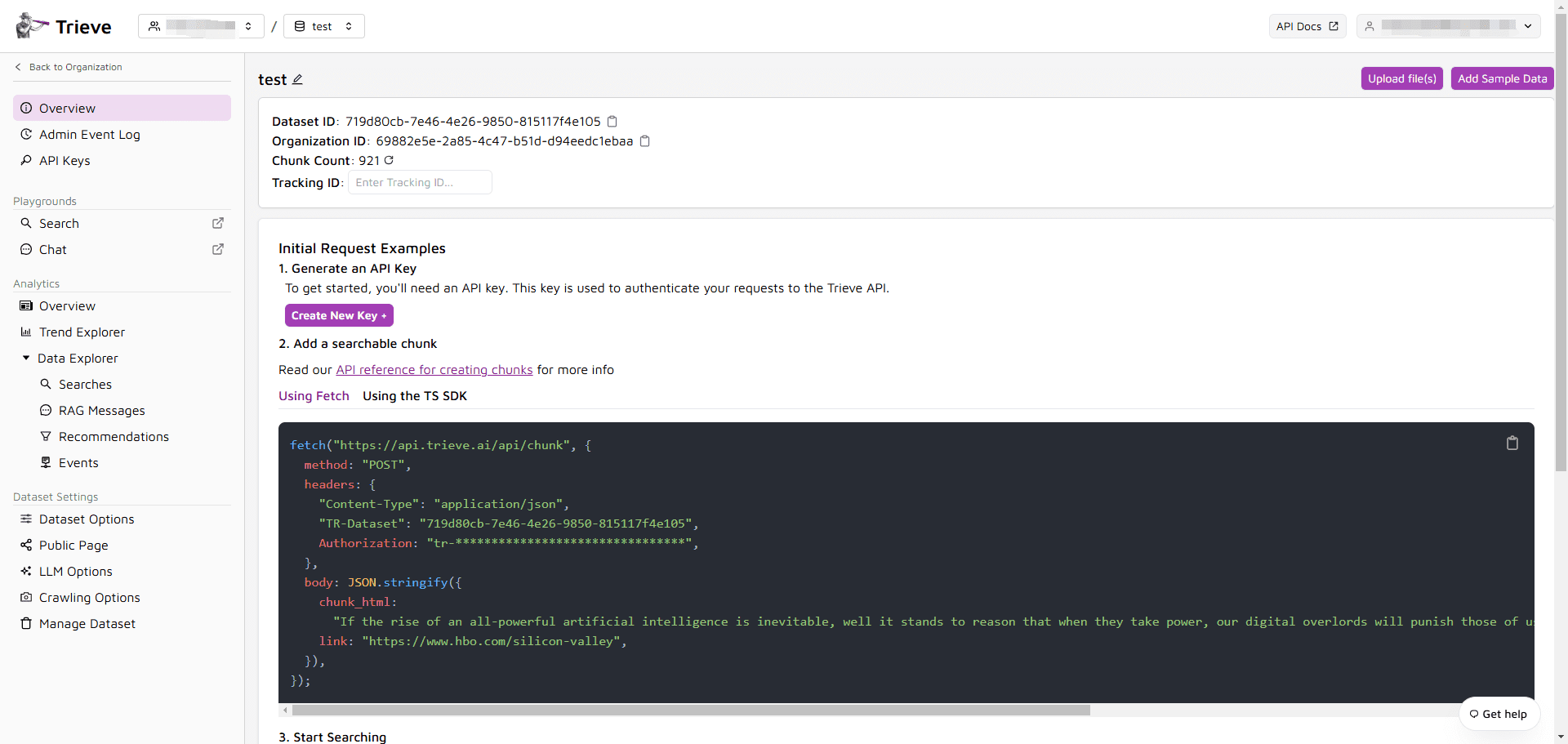
Trieve:提供搜索、推荐和分析的全方位RAG云基础设施综合介绍 Trieve 是由 Devflow, Inc. 开发的全方位基础设施,专为搜索、推荐、RAG(检索增强生成)和分析而设计。该平台通过 API 提供服务,支持自托管,适用于 AWS、GCP、K...最新AI资源# AI开放服务# 文档提取与清洗1年前061.9K
pdf2htmlEX:PDF无损转换为HTML,保持文本格式,适用于学术论文和杂志排版综合介绍 pdf2htmlEX 是一个开源工具,旨在将 PDF 文件转换为 HTML 格式,通过分析 PDF 文件的内容并使用 HTML + CSS 精确还原其视觉效果, 将 PDF 文档转换为浏览器...最新AI资源# AI开源项目# 文档提取与清洗1年前062.4K
Maxun:开源无代码平台,自动抓取网页数据并转换为API或电子表格综合介绍 Maxun是一个开源的无代码网页数据提取平台,用户可以在几分钟内训练机器人,自动抓取网页数据并将其转换为API或电子表格。该平台支持分页和滚动,能够适应网站布局的变化,提供强大的数据抓取功能...最新AI资源# AI开源项目# 文档提取与清洗1年前063.1K
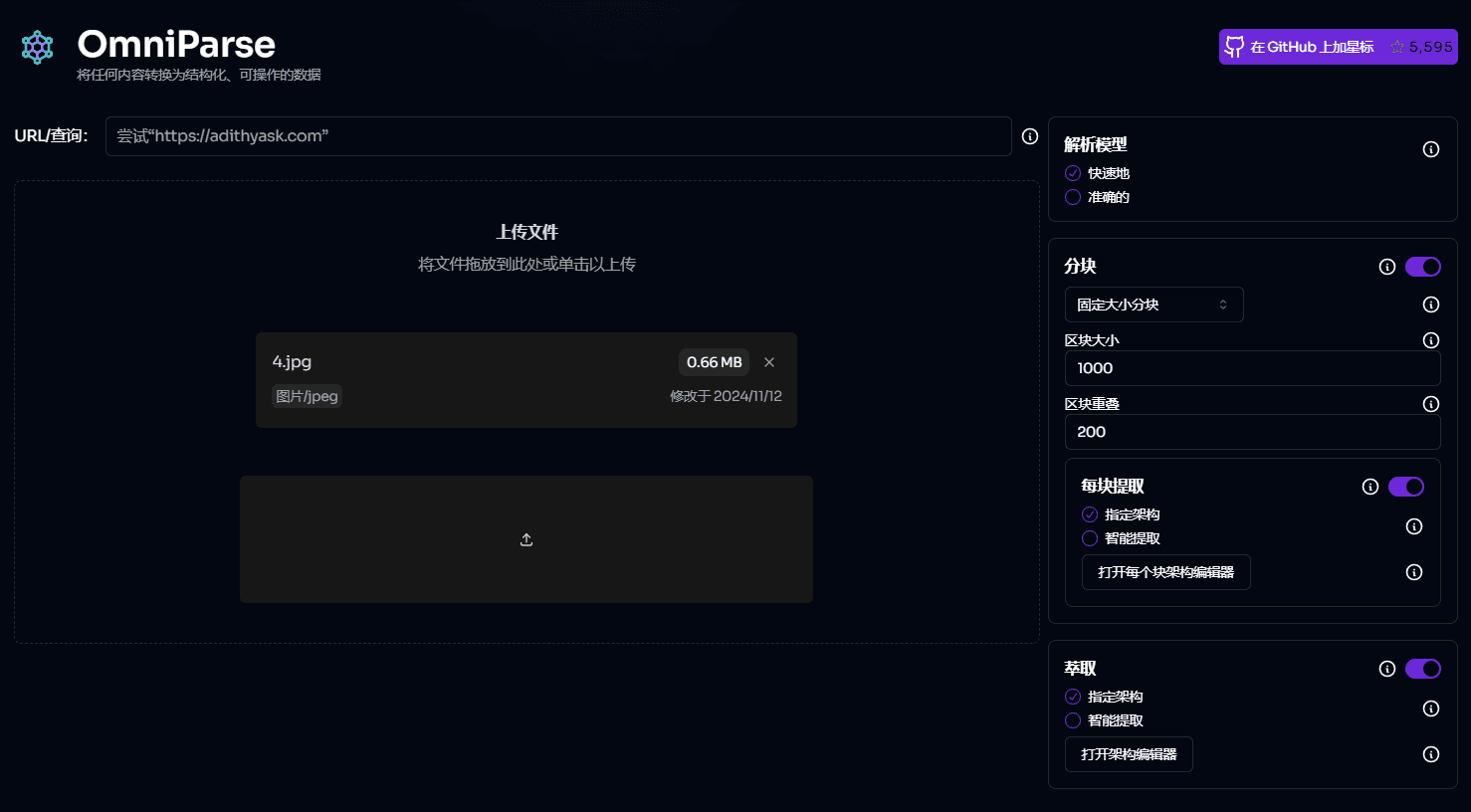
OmniParse:从文档/多媒体中提取任何非结构化数据解析为结构化数据综合介绍 OmniParse是一个强大的数据解析与优化平台,旨在将任何非结构化数据转换为结构化、可操作的数据,优化后适用于GenAI(生成式人工智能)框架。无论是处理文档、表格、图像、视频、音频文件还...最新AI资源# AI开源项目# 文档提取与清洗1年前053.8K
Parsio:自动从 PDF、电子邮件和其他文档中提取关键结构化数据综合介绍 Parsio 是一款基于 AI 技术的文档和邮件数据提取工具,能够自动从 PDF、电子邮件及其他文档中提取结构化数据。该平台提供强大的 PDF 解析器和 OCR 功能,支持多种文档类型,包括...最新AI资源# 文档提取与清洗1年前058.9K
Chonkie:轻量级RAG文本切块库综合介绍 Chonkie 是一个轻量级且高效的 RAG(Retrieval-Augmented Generation)文本切块库,旨在帮助开发者快速、简便地对文本进行分块处理。该库支持多种分块方法,包...最新AI资源# AI开源项目# 文档提取与清洗1年前073.9K
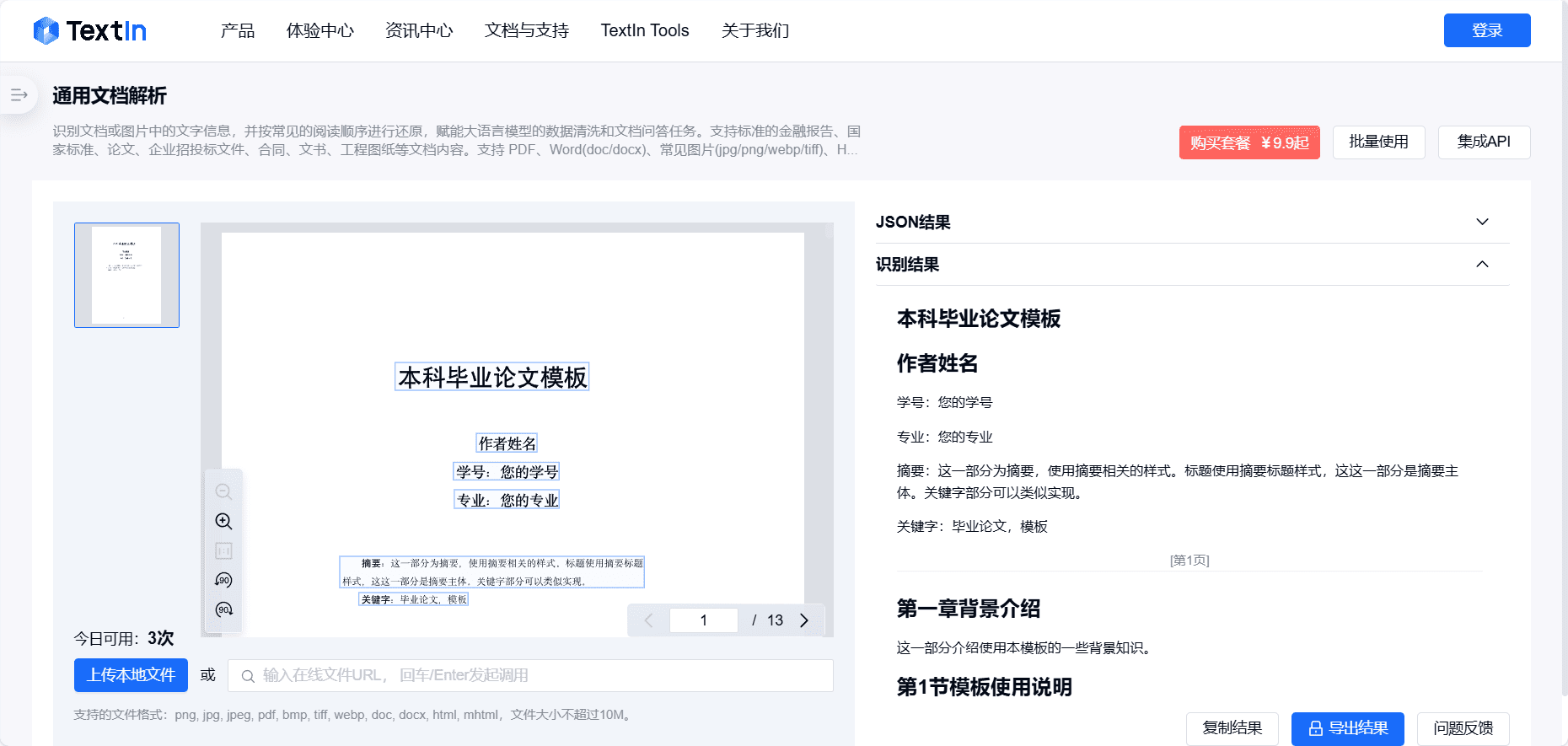
TextIn:通用文档转换,PDF转Markdown工具综合介绍 TextIn是一款专业的PDF转Markdown工具,旨在帮助用户高效地将PDF文档转换为Markdown格式。该工具支持多种文件格式,操作简单,转换速度快,能够保留原始PDF的格式和内容...最新AI资源# 文档提取与清洗1年前054.8K
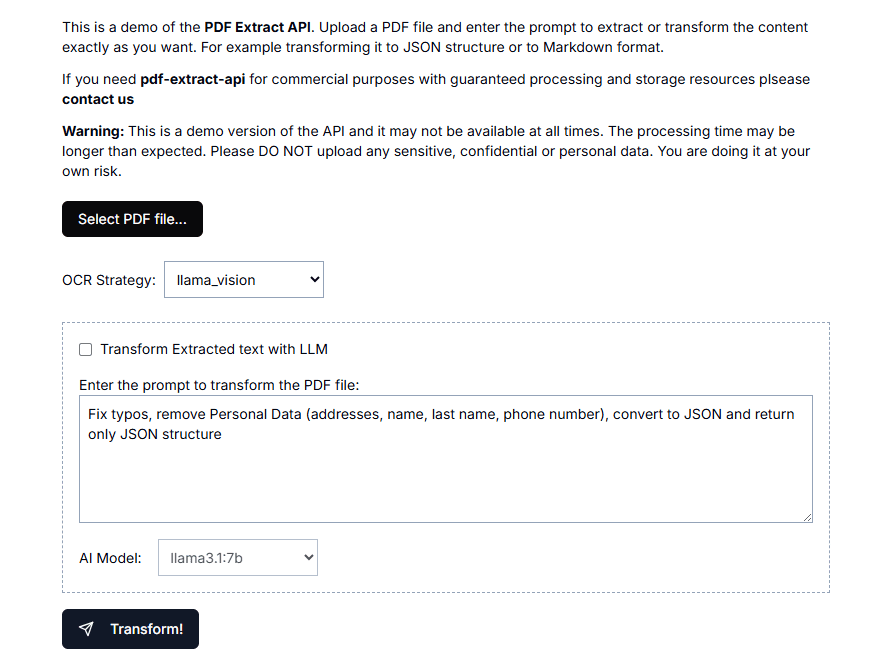
文本提取API(text-extract-api):视觉提取文本信息,匿名化的PDF提取工具综合介绍 文本提取API(text-extract-api)是一个强大的工具,旨在从各种文档格式(如PDF、Word、PPTX等)中提取和解析内容。该API利用最先进的光学字符识别(OCR)技术和Ol...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前057.9K
Datalab:专用OCR识别AI模型,PDF转Markdown(开源/API)综合介绍 Datalab 提供了一系列先进的AI模型,专注于OCR、布局分析、PDF转Markdown等功能。这些模型不仅性能卓越,而且易于使用,并且是开源的。平台上的Marker模型可以快速准确地将...最新AI资源# AI开放服务# AI开源项目# OCR1年前066.6K
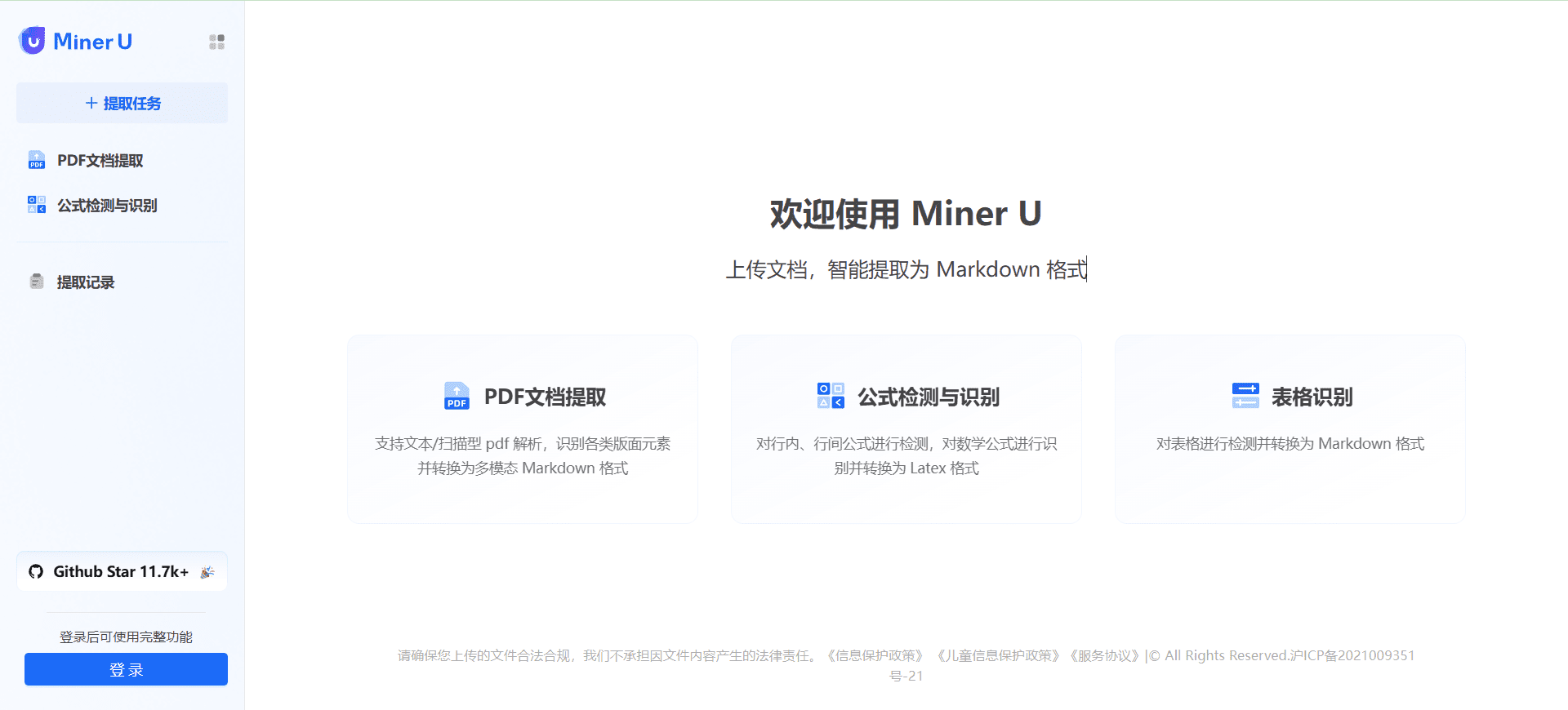
MinerU:PDF文档提取转换为多模态Markdown格式,支持电子书OCR扫描综合介绍 MinerU是由上海人工智能实验室OpenDataLab团队开发的一款开源数据提取工具,专注于从复杂的PDF文档、网页和电子书中高效提取内容。它能够将包含图片、公式、表格等元素的多模态PDF...最新AI资源# AI开源项目# OCR# 文档提取与清洗2年前0141.6K
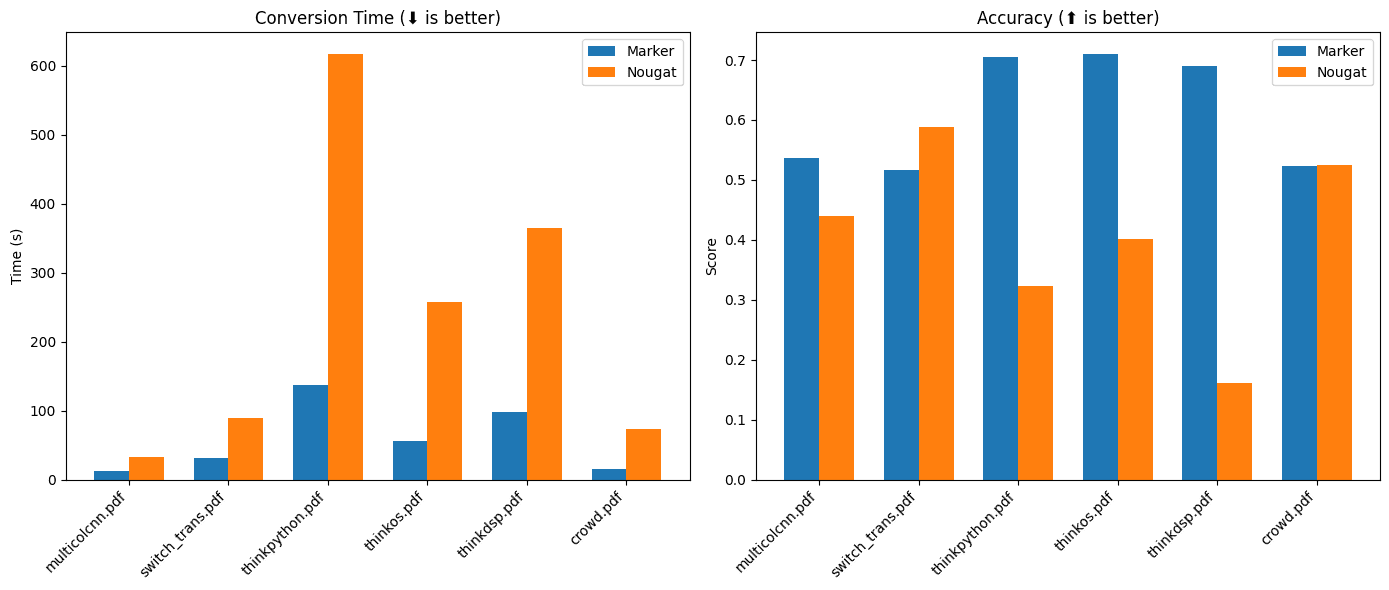
Marker:快速将PDF转换为Markdown的开源工具综合介绍 Marker 是一个基于深度学习的文档处理工具,旨在将 PDF 文件快速准确地转换为 Markdown 格式。它支持多种文档类型,特别优化了书籍和科学论文的转换。Marker 能够去除页眉页...最新AI资源# AI开源项目# 文档提取与清洗1年前0127.7K
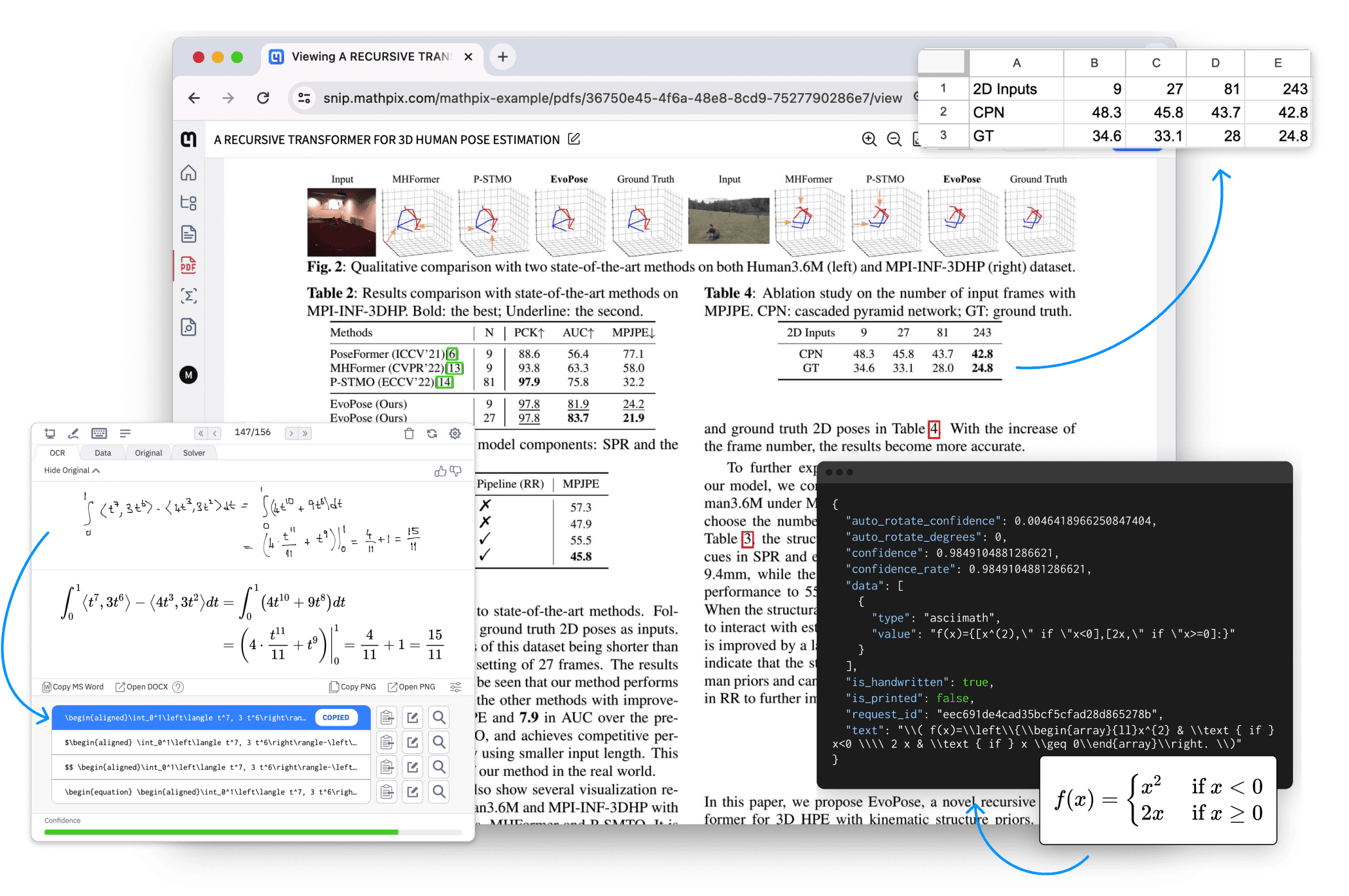
Mathpix:PDF和图片文档结构化转换软件,支持多终端综合介绍 Mathpix 是一款强大的 AI 驱动文档自动化工具,专为科研人员、开发者和企业设计。它能够快速准确地将 PDF 和图像转换为可搜索、可导出和机器可读的文本。Mathpix 提供了多种功能...最新AI资源# AI开放服务# 文档提取与清洗2年前0109.7K
Unstructured:开源预处理非结构化文档,无结构数据处理的利器综合介绍 Unstructured-IO 提供了一系列开源组件,用于处理和预处理图像和文本文档,如 PDF、HTML、Word 文档等。其主要目标是简化和优化数据处理工作流程,特别是为大语言模型(LL...最新AI资源# AI开源项目# 文档提取与清洗2年前073.9K
Reader API:网页内容提取工具,HTML转换为Markdown格式综合介绍 Jina AI的Reader项目是一个开源工具(Reader 开源地址),可将任何URL通过添加前缀https://r.jina.ai/转换成适合大型语言模型(Large Languag...最新AI资源# AI开源项目# 文档提取与清洗2年前0340.3K