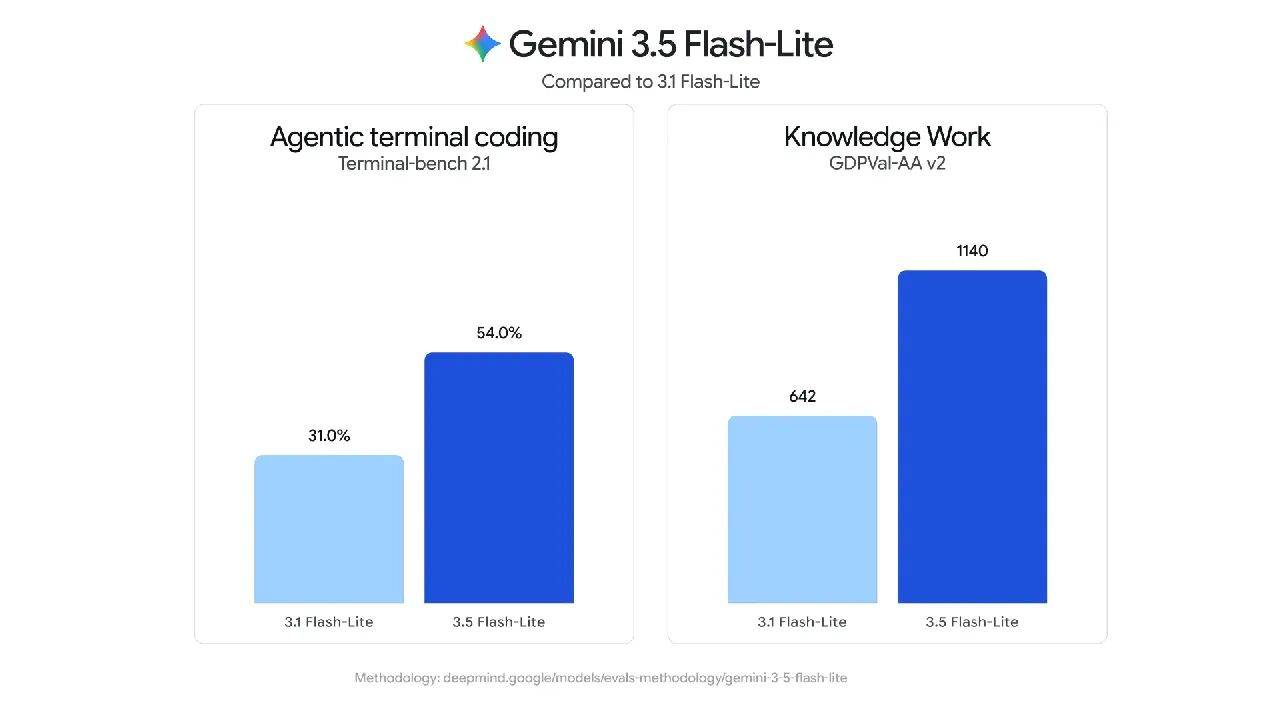
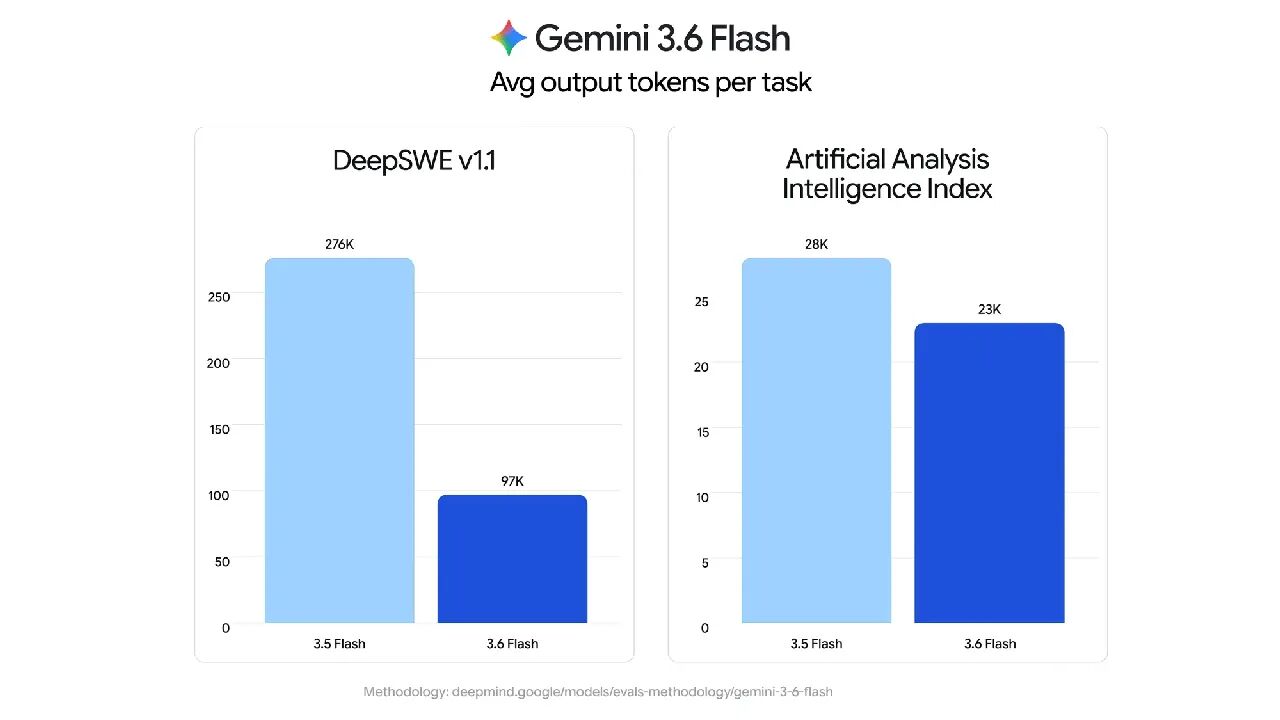
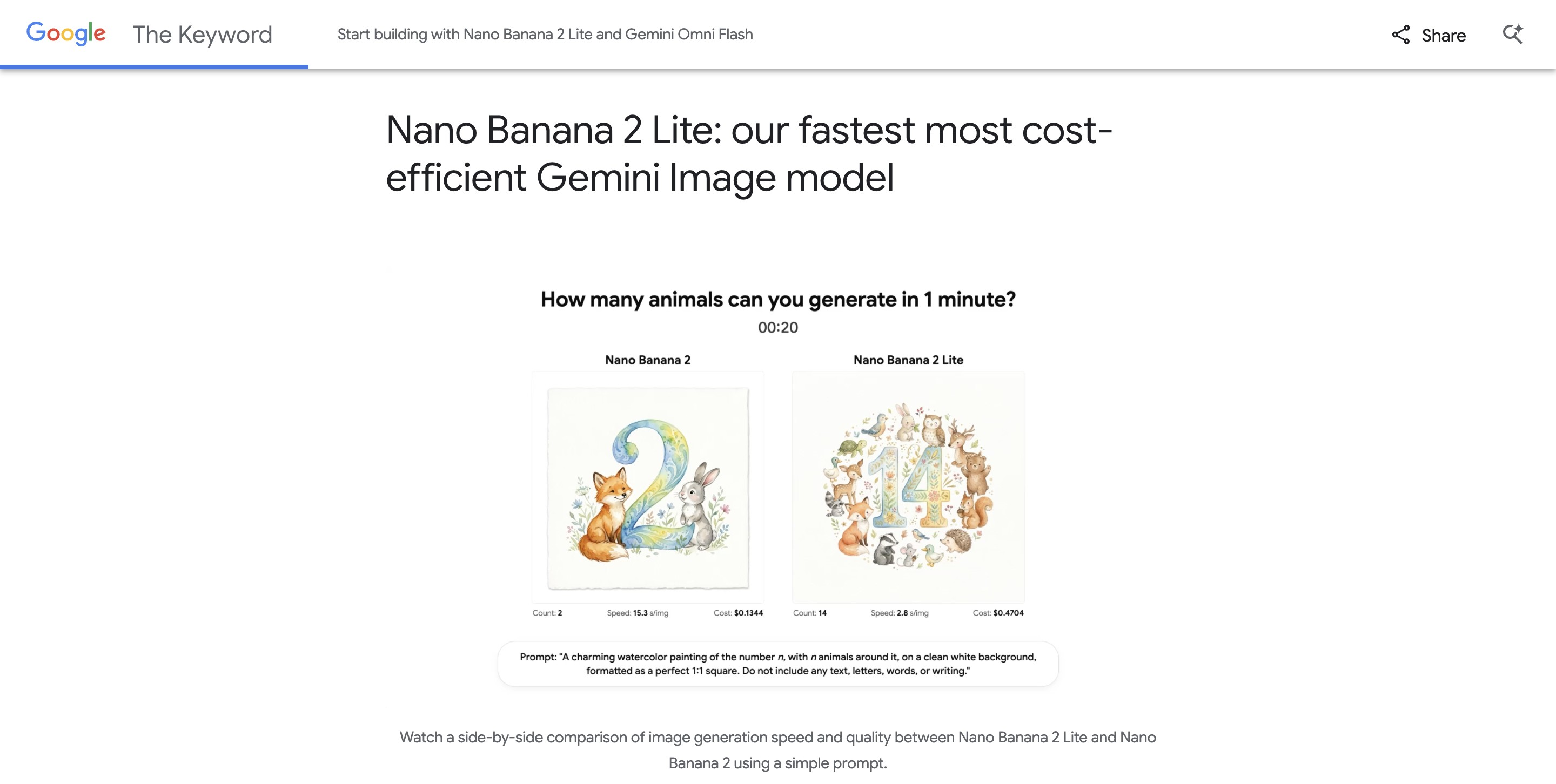
GLM-4.6V는 스마트 스펙트럼 AI에서 오픈소스화한 멀티모달 대규모 언어 모델 시리즈로, 클라우드 및 고성능 클러스터 시나리오를 위한 기본 버전인 GLM-4.6V(106B-A12B)와 혼합 전문가(MoE) 아키텍처, 총 약 106억 개의 레퍼런스, 활성화... 등 두 가지 버전이 있습니다.
Kimi K2-0905는 프로그래밍 지원 기능이 뛰어나고 코드를 효율적으로 생성하며 프론트엔드 개발에서 깔끔하고 표준화된 코드 생성을 지원하는 다크 사이드 오브 더 문 테크놀로지스의 고급 AI 모델입니다. 모델 컨텍스트 길이가 256K로 확장되어 복잡한 작업을 처리할 수 있습니다.
스카이워크 유니픽 2.0은 이미지 생성, 편집, 이해에 초점을 맞춘 효율적인 멀티모달 모델로, 퀸테센스가 오픈소스로 제공합니다. 이 모델은 2B 매개변수 SD3.5-Medium 아키텍처를 기반으로 하며 사전 교육, 점진적인 이중 작업 강화 전략 및 공동 교육을 통해 실현됩니다....
GPT-5는 OpenAI가 여러 가지 업그레이드를 통해 출시한 최신 언어 모델입니다. 문제의 복잡성에 따라 효율적인 모드와 심층 사고 모드를 자동으로 전환하여 빠른 응답과 정확한 답변을 가능하게 하는 실시간 라우터가 내장된 통합 지능 시스템입니다.GPT-5에는 푸시용을 포함하여 여러 버전이 있습니다....
퀀이미지는 알리바바 통이 첸첸 팀이 공개한 오픈 소스 이미지 생성 기본 모델입니다. 200억 개의 매개 변수로 멀티모달 이해, 고해상도 코딩, 확산 모델링의 세 가지 모듈을 통합하는 멀티모달 확산 트랜스포머 아키텍처(MMDiT)를 채택하고 있습니다.Qwen-Image의...
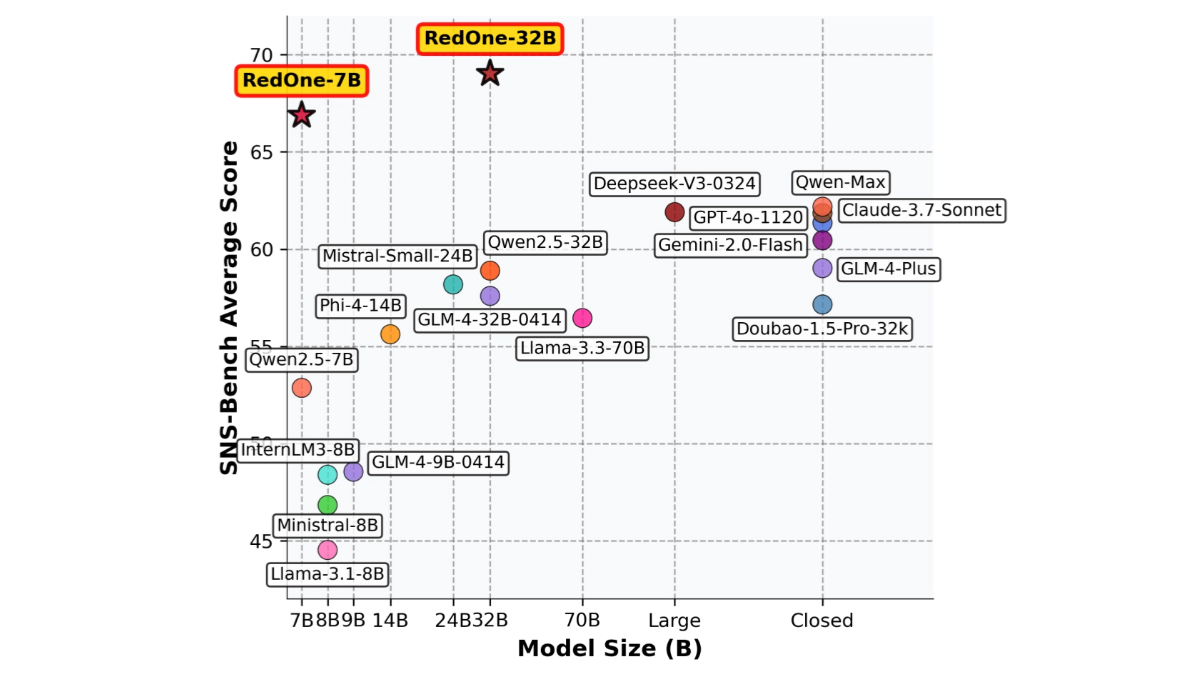
레드원은 리틀 레드북에서 도입한 소셜 네트워크에 특화된 대규모 언어 모델입니다. 이 모델은 사회 및 문화적 지식을 통합하고, 멀티태스킹 기능을 강화하며, 인간의 선호도를 조정하는 3단계 훈련 전략을 통해 훈련되며, RedOne은 소셜 작업 성능, 유해 콘텐츠 탐지 및 검색에서 기본 모델보다 훨씬 뛰어난 성능을 발휘합니다....
TRAE SOLO는 바이트댄스에서 출시한 인공지능 프로그래밍 어시스턴트인 TRAE가 인공지능 기술로 소프트웨어 개발 과정을 간소화하기 위해 선보인 인공지능 자동 개발 도우미로, 사용자의 요구 사항을 이해하고 텍스트 설명, 음성 명령, 파일 업로드 등을 지원하여 요구 사항을 입력하면 자동으로 계획을 세우고...
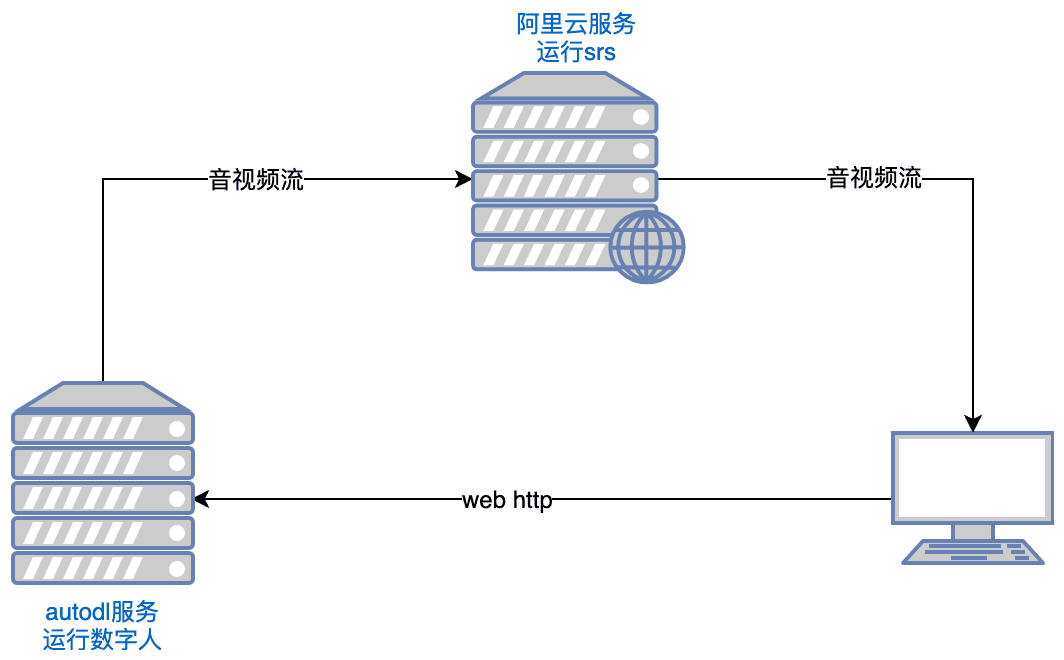
포괄적 인 소개 라이브토킹은 오픈 소스 실시간 대화 형 디지털 휴먼 시스템으로 고품질 디지털 휴먼 라이브 솔루션을 구축하기 위해 최선을 다하고 있습니다. 이 프로젝트는 아파치 2.0 오픈 소스 프로토콜을 사용하며, ER-NeRF 렌더링, 실시간 오디오 및 비디오 스트리밍 처리 등 다양한 최첨단 기술과 통합되어 있습니다 ...