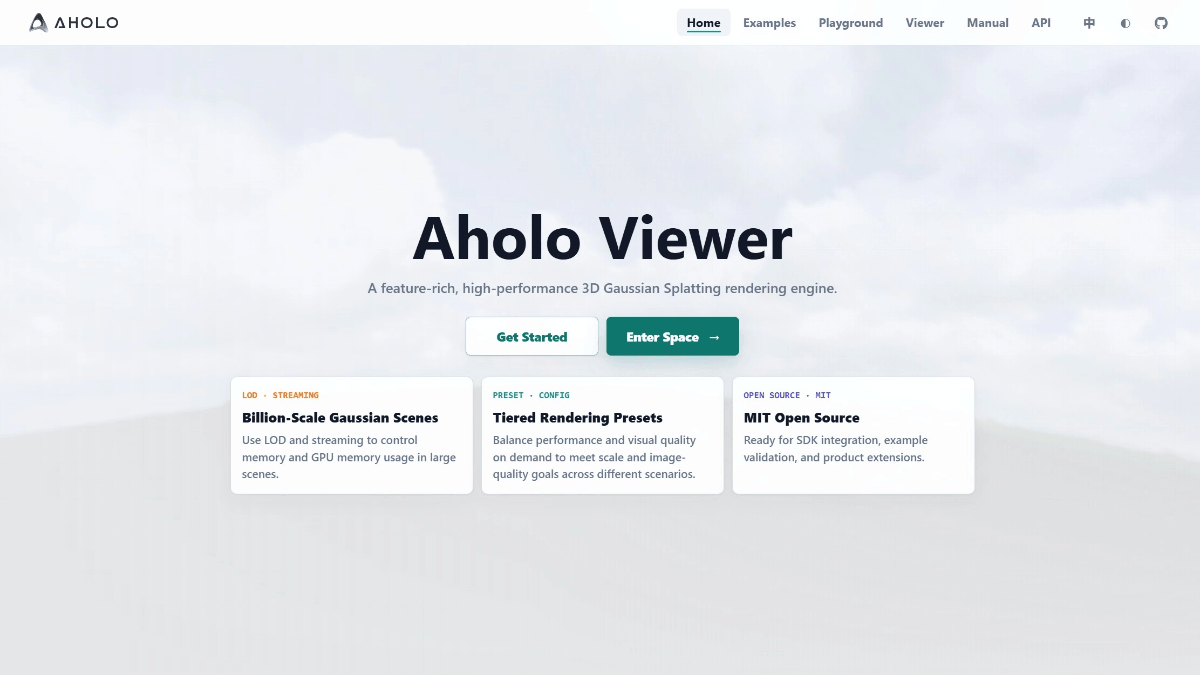
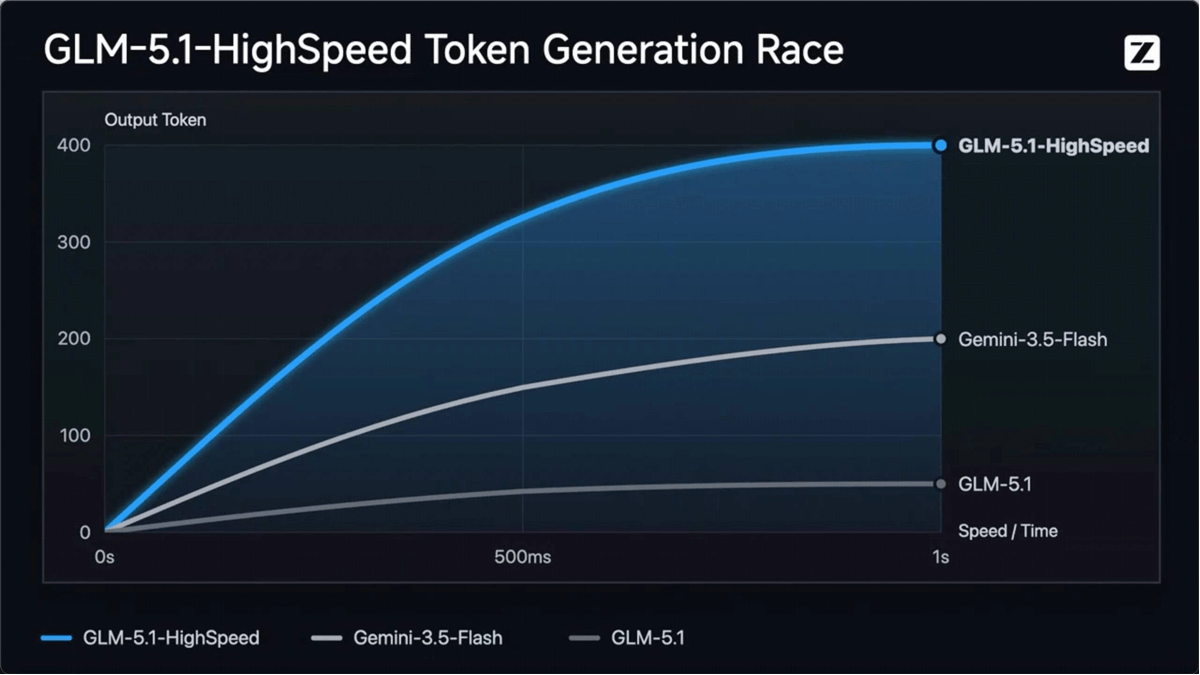
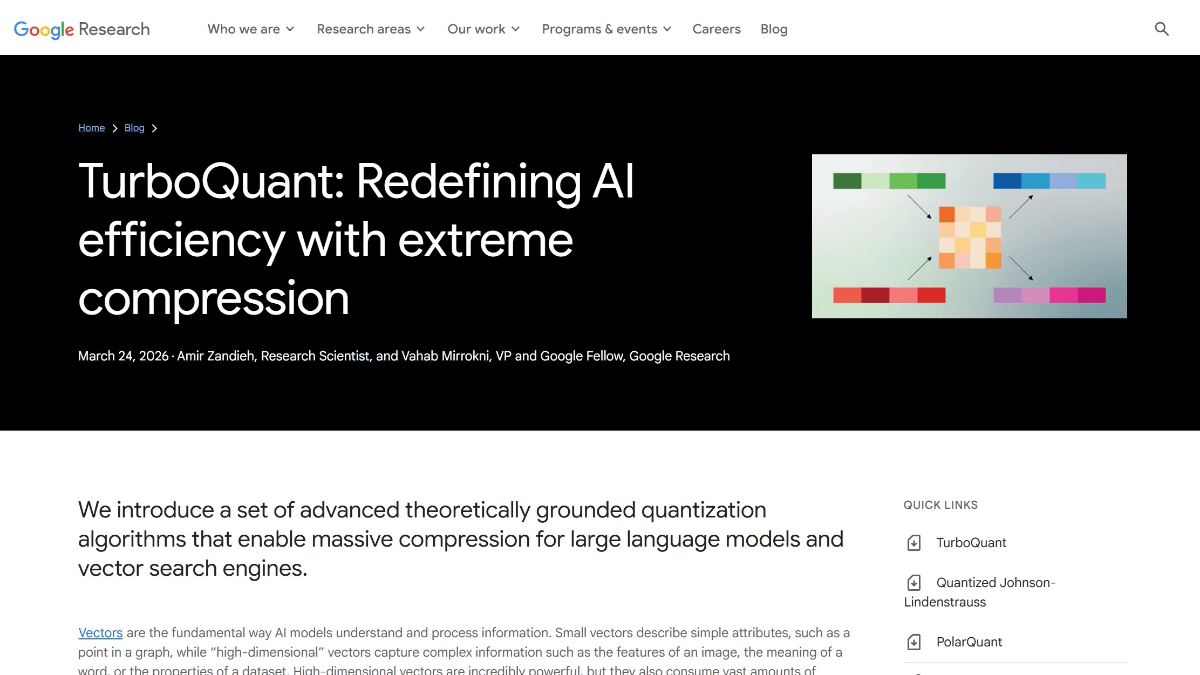
GLM-4.6V - Wisdom Spectrum AI open source multimodal large language model series
GLM-4.6V is a series of multimodal large language models open-sourced by Smart Spectrum AI. The series contains two versions: GLM-4.6V (106B-A12B), the basic version for cloud and high-performance cluster scenarios, with the Mixed Expert (MoE) architecture, a total of about 106 billion references, and an activation...