

GLM-5.1-highspeed是什么
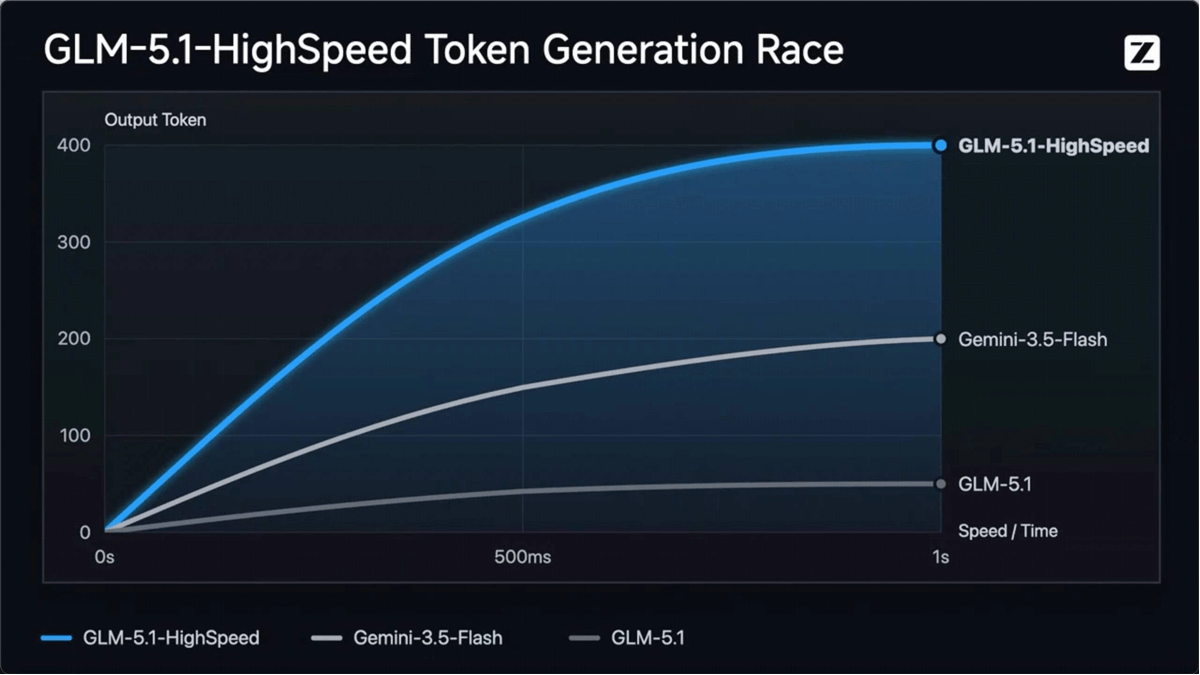
GLM-5.1-highspeed 是智谱AI发布的旗舰级高速推理API,基于GLM-5.1打造,输出速度达到 400 tokens/s,刷新当前全球大模型厂商API的速度上限。打破了"高速即轻量"的行业惯例,首次在国产大模型中实现旗舰级能力与极致低延迟兼得,完整保留GLM-5.1的Coding、推理与综合任务处理能力,支持200K上下文窗口和128K最大输出。
GLM-5.1-highspeed的功能特色
- 极速文本生成:模型输出速度达400 tokens/s,将复杂推理任务的响应时间压缩至极低水平,实现"即问即答"的实时交互体验。
- 完整旗舰能力保留:在实现高速推理的同时,完整保留GLM-5.1的Coding、推理与综合任务处理能力,无需为速度牺牲模型质量。
- 긴 컨텍스트 지원:提供200K上下文窗口与128K最大输出长度,能够处理大型代码库重构、长文档分析等复杂任务。
- 流式实时输出:支持Server-Sent Events(SSE)流式传输协议,实现边生成边返回,极大降低感知延迟。
- 심층 사고 모드:支持启用thinking模式,在极速响应的同时输出模型的推理过程,满足可解释性需求。
- MCP工具调用:支持通过Model Context Protocol灵活调用外部工具与数据源,扩展应用场景边界。
- 구조화된 출력:支持JSON等结构化格式输出,便于与业务系统集成。
GLM-5.1-highspeed的核心优势
- 速度与质量兼得:打破行业"高速模型必为轻量模型"的惯例,首次实现旗舰级能力与400 tokens/s极速响应的统一。
- TileRT高性能推理引擎:由智谱GLM团队与TileRT团队联合打造,通过编译期静态编排、寄存器级数据直传和Tile级微任务调度,将推理过程中的访存开销和调度延迟压缩到极致。
- 全栈系统级优化:在推理引擎层(重写核心推理路径)、调度系统层(动态批处理与KV缓存优化)、基础设施层(集群部署与网络链路优化)三个层面协同发力,确保400 TPS是稳定可用的生产级能力而非峰值数据。
- 生产级稳定性:已在实际生产环境中部署,基于8×H200 NVL服务器架构,能够稳定承载真实用户流量和高并发场景。
GLM-5.1-highspeed官网是什么
- 프로젝트 웹사이트:https://docs.bigmodel.cn/cn/guide/models/text/glm-5.1-highspeed
GLM-5.1-highspeed的操作步骤
- 获取平台访问权限:目前GLM-5.1-highspeed仅面向智谱BigModel开放平台的部分企业客户定向开放,需先联系智谱官方或平台商务团队申请接入资格与试用权限。
- API 키 가져오기:在获得接入资格后,登录智谱BigModel开放平台,在开发者控制台中创建或获取对应的API Key,用于后续接口调用的身份鉴权。
- 配置基础请求参数:在API请求中指定模型名称为
GLM-5.1-highspeed,设置所需的上下文窗口(最高支持200K)和最大输出长度(最高128K),并根据业务场景配置温度、Top-P等生成参数。 - 启用SSE流式输出:在请求头或参数中开启Server-Sent Events(SSE)流式传输模式,实现边生成边返回,将400 tokens/s的极速能力转化为低延迟的实时交互体验。
- 按需启用深度思考模式:如需模型输出推理过程,在API调用中通过设置
extra_body={"enable_thinking": True}参数开启thinking模式,让模型在极速响应的同时展示内部推理链条。 - 配置MCP工具调用:如需扩展模型能力边界,通过Model Context Protocol接入外部工具与数据源,在请求中定义可用工具列表及调用规则,实现模型与外部系统的联动。
- 设置结构化输出格式:如需与业务系统对接,在请求中指定输出格式为JSON等结构化类型,便于后续解析与自动化处理。
GLM-5.1-highspeed的适用人群
- AI编程开发者:需要高频调用模型进行代码生成、重构、审查的Coding Agent开发者,多轮调用的延迟累积可被大幅压缩。
- 实时交互产品团队:构建实时语音助手、在线客服、交互式原型生成等对响应延迟极度敏感产品的团队。
- Agent应用开发者:需要快速调度多Agent并行执行、动态生成工具与界面的智能体应用开发者。
- 企业级AI应用团队:对商业决策、实时数据分析、高频工具调用有低延迟要求的企业客户。
GLM-5.1-highspeed的常见问题
Q:GLM-5.1-highspeed的400 tokens/s是峰值速度还是持续可用速度?
A:400 tokens/s是经过全栈优化后稳定可用的生产级能力,智谱通过TileRT引擎、动态批处理和集群负载均衡等技术,确保在高并发场景下持续保持该速度水平。
Q:个人开发者能否使用GLM-5.1-highspeed?
A:目前该模型仅面向智谱BigModel开放平台的部分企业客户定向开放,个人开发者暂时无法直接使用。建议关注智谱后续的开放计划,或先使用GLM-5.1标准版进行开发测试。
Q:GLM-5.1-highspeed与GLM-5.1标准版在能力上有何差异?
A:两者在模型能力上完全一致,高速版完整保留了GLM-5.1的Coding、推理与综合任务处理能力。唯一区别在于推理速度和底层引擎实现方式——高速版通过TileRT引擎实现了400 TPS的极速推理。
Q:如何启用GLM-5.1-highspeed的深度思考模式?
A:在API调用时,通过设置 extra_body={"enable_thinking": True} 参数即可启用thinking模式,模型会在生成最终回答的同时输出推理过程。
Q:GLM-5.1-highspeed的上下文窗口是多少?
A:支持200K上下文窗口和128K最大输出长度。部分评测者期待未来推出1M上下文版本。
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...