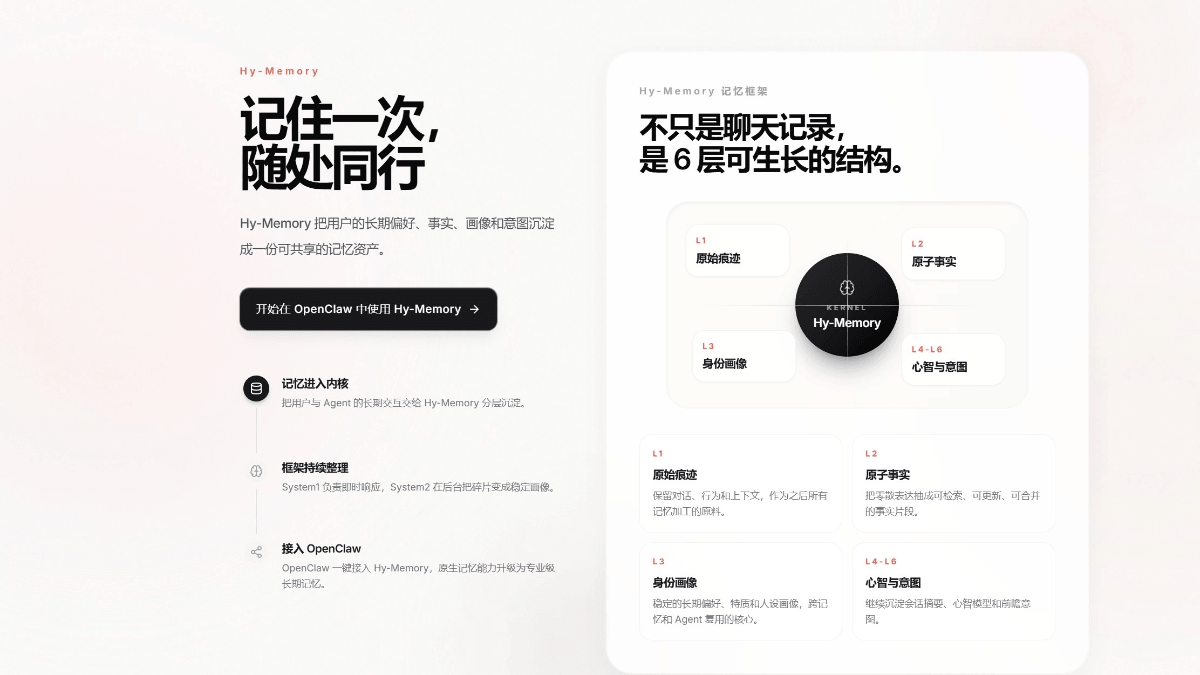
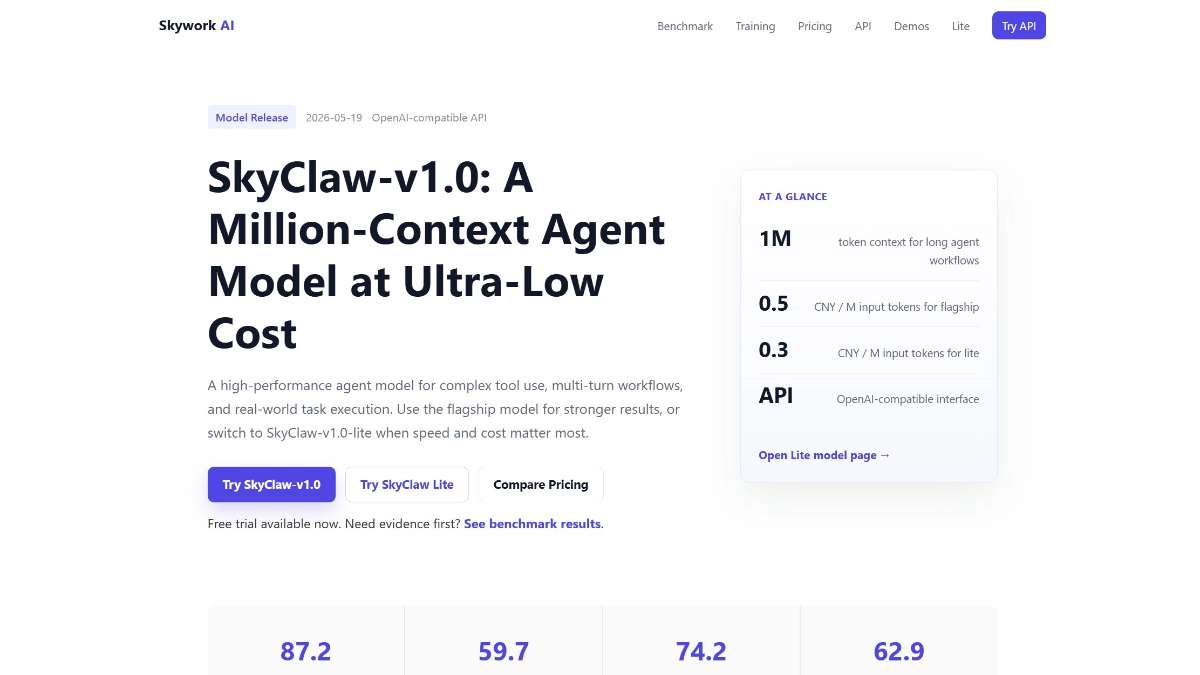
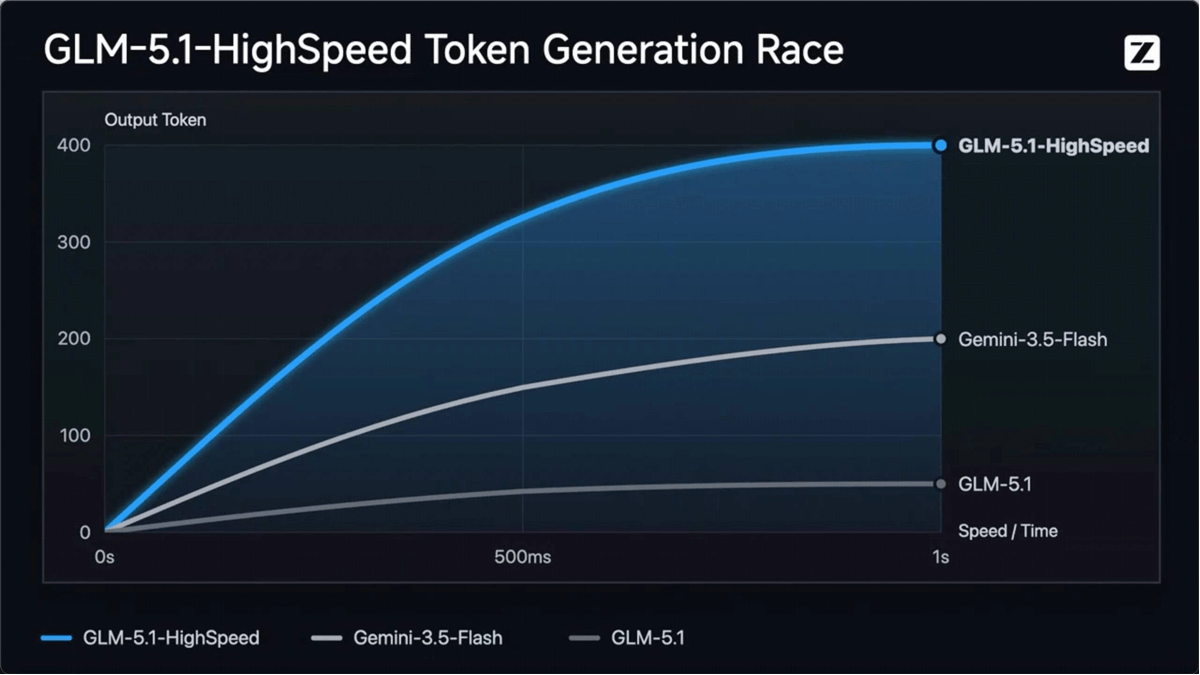
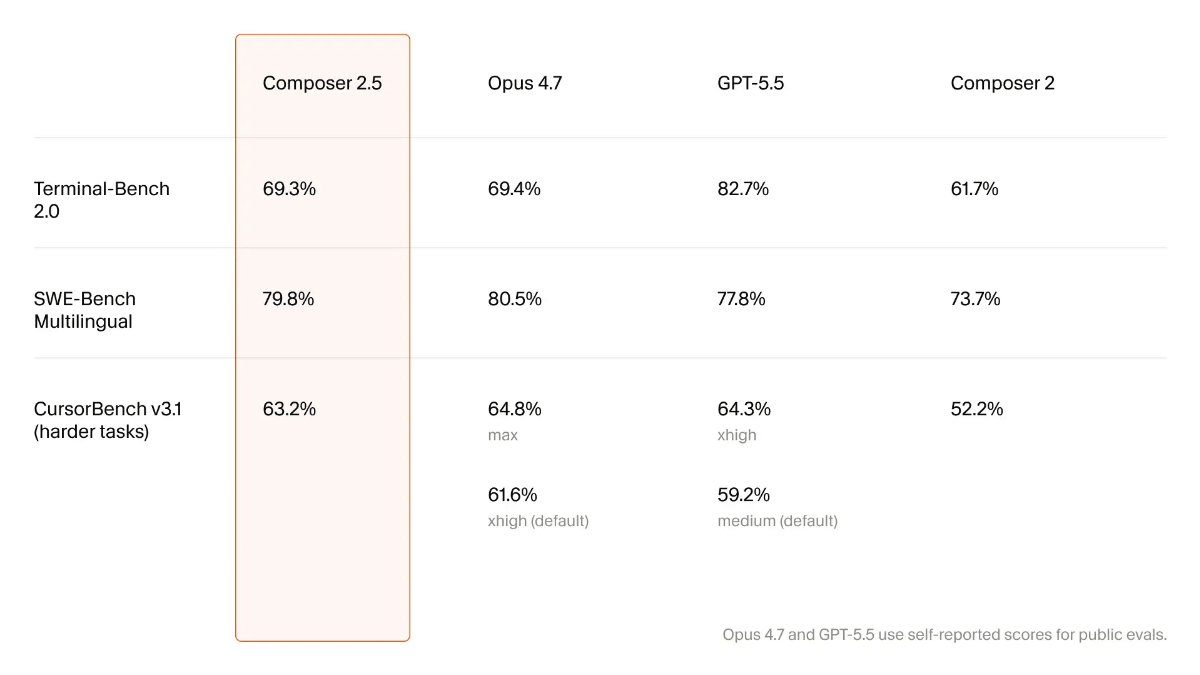
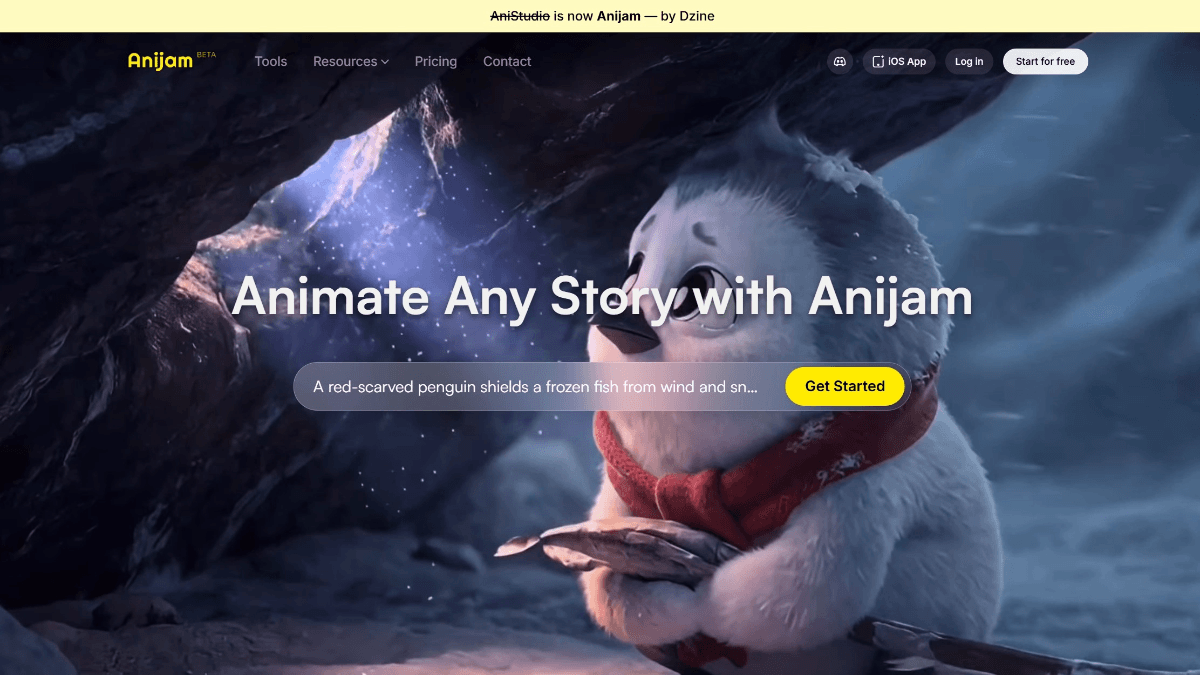
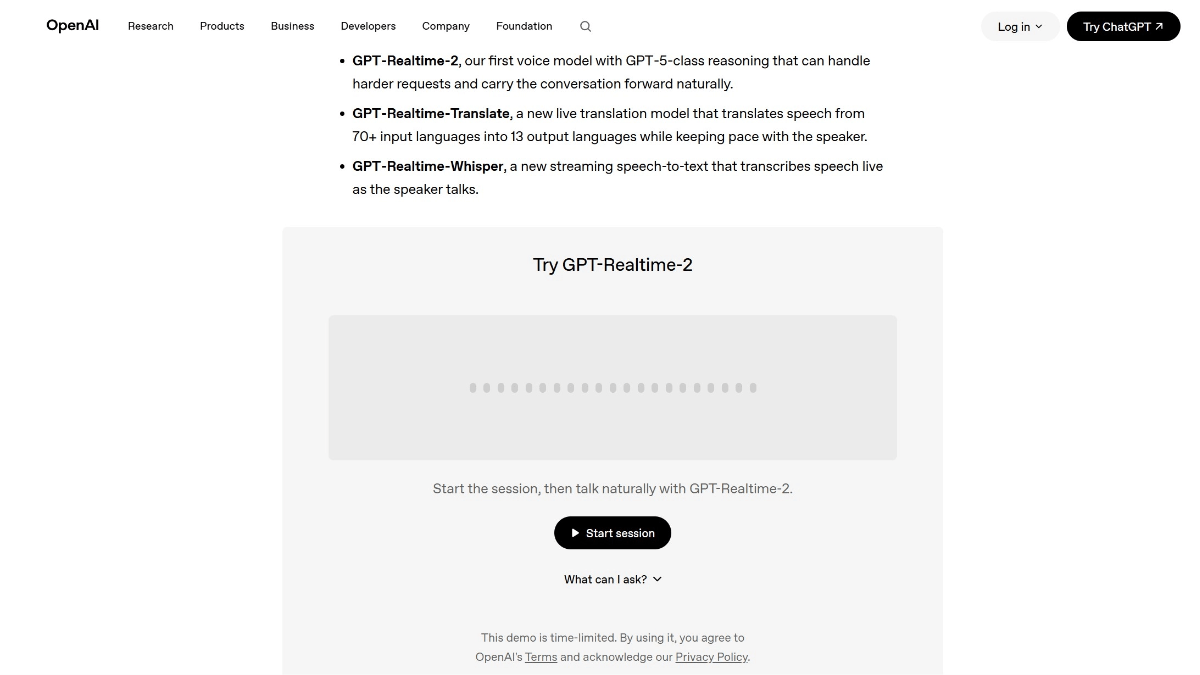
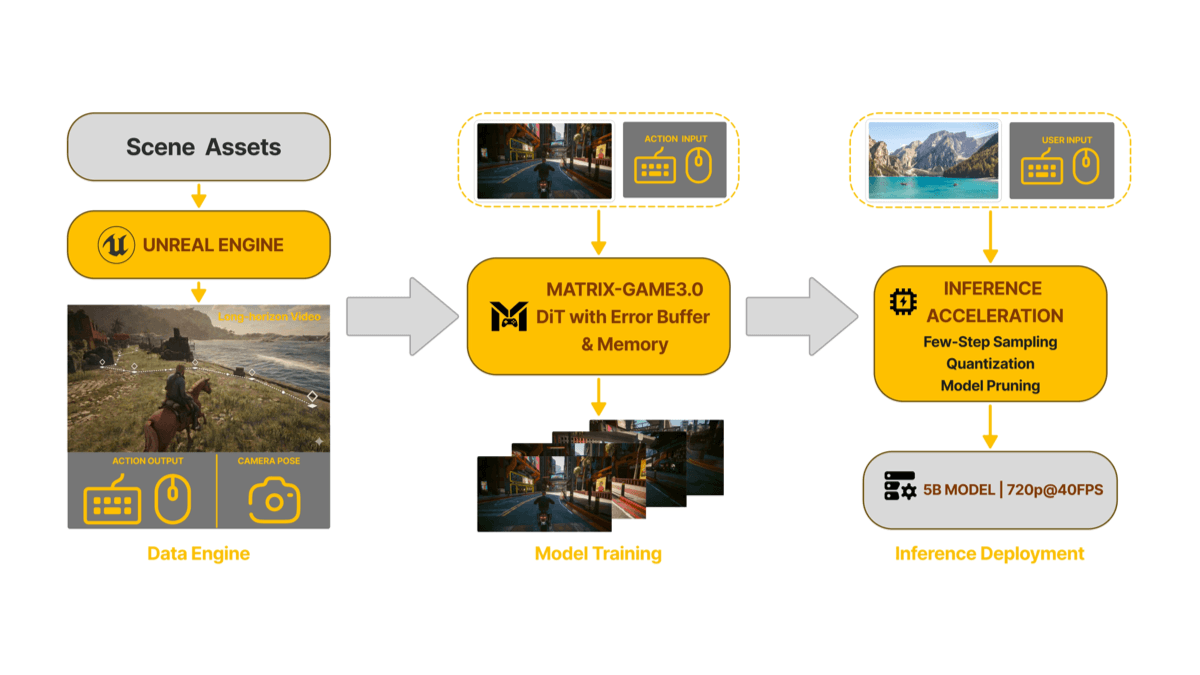
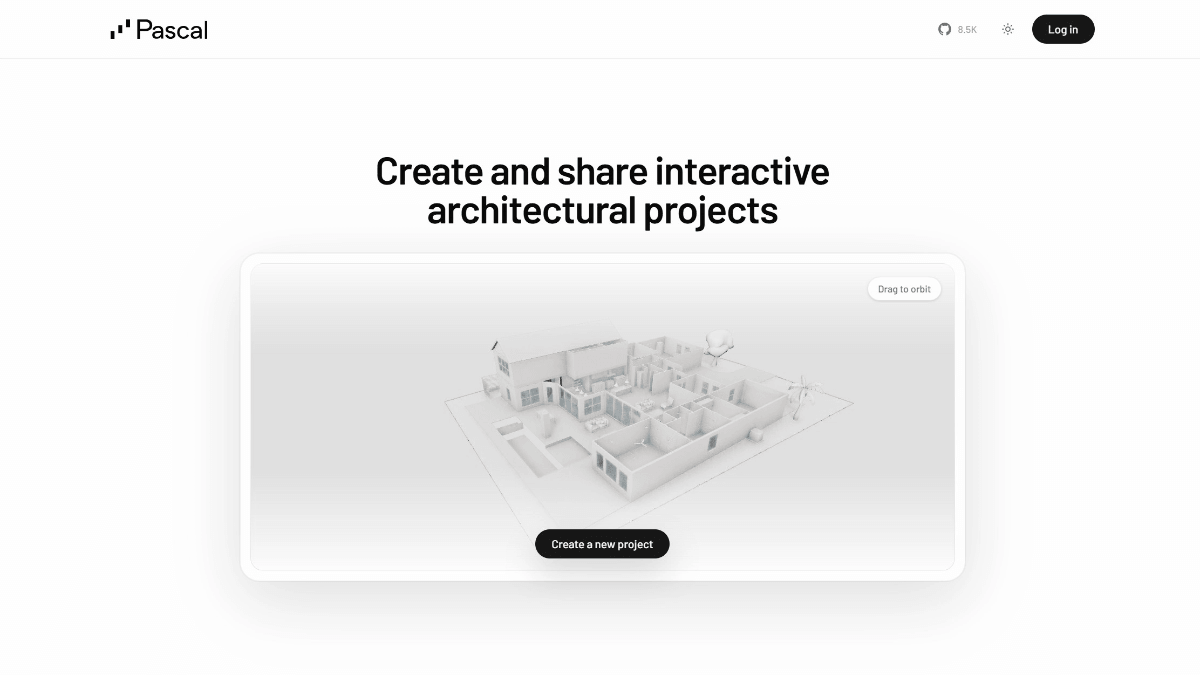
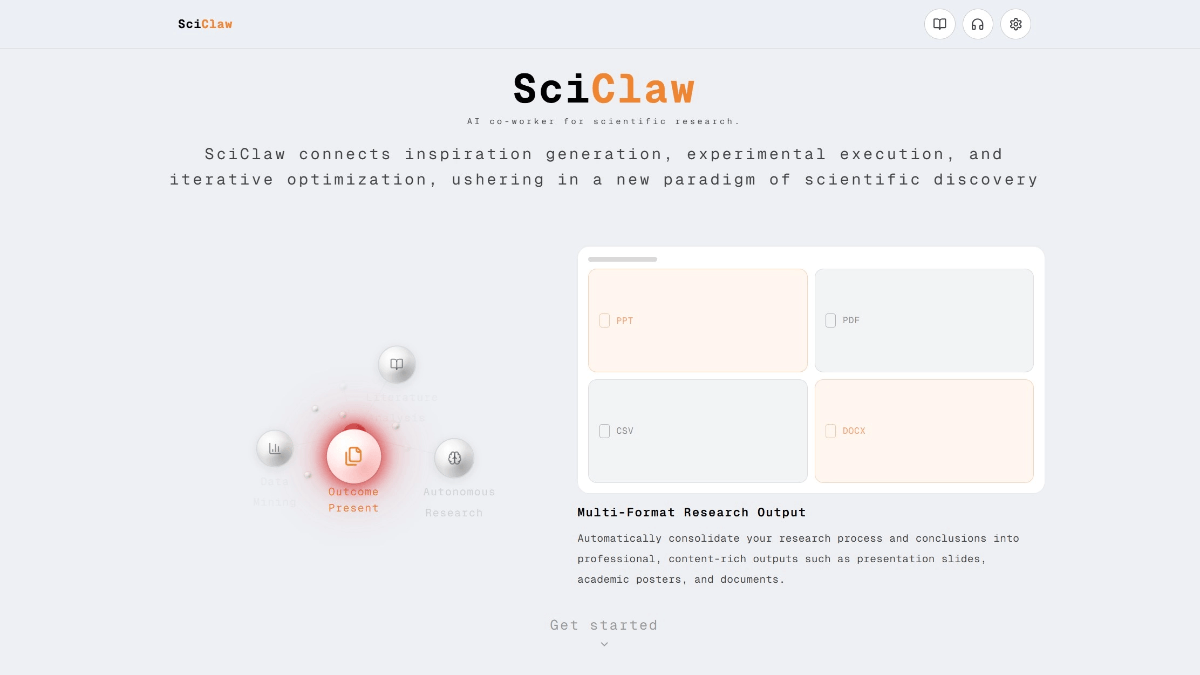
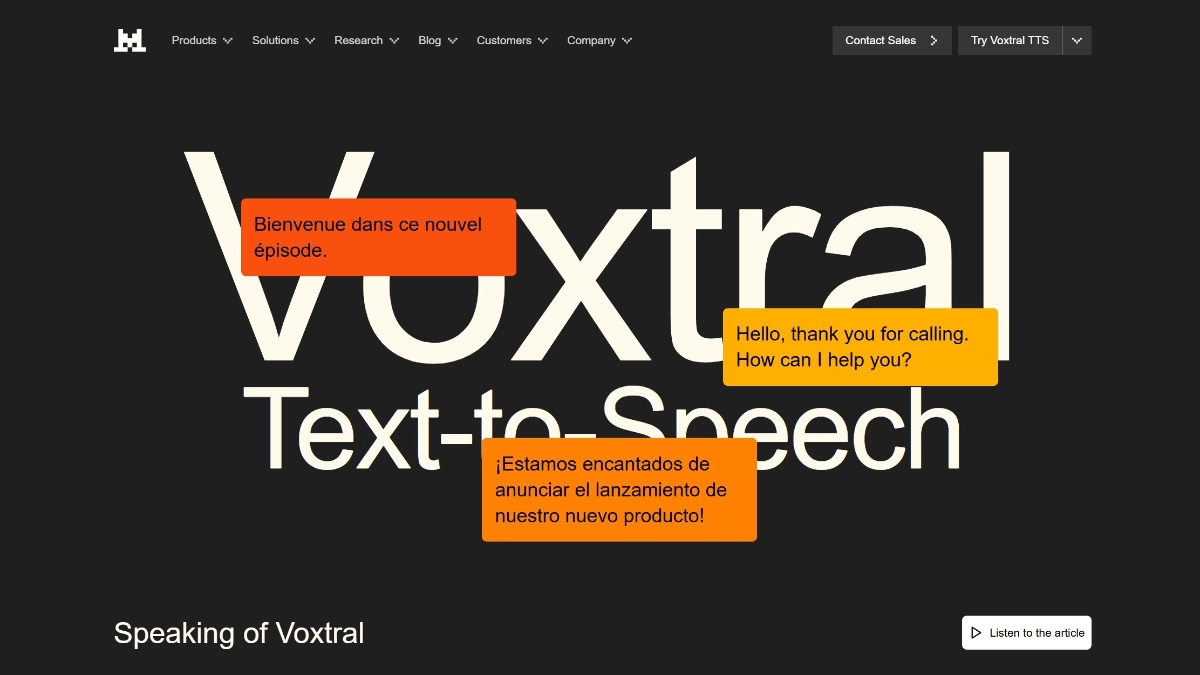
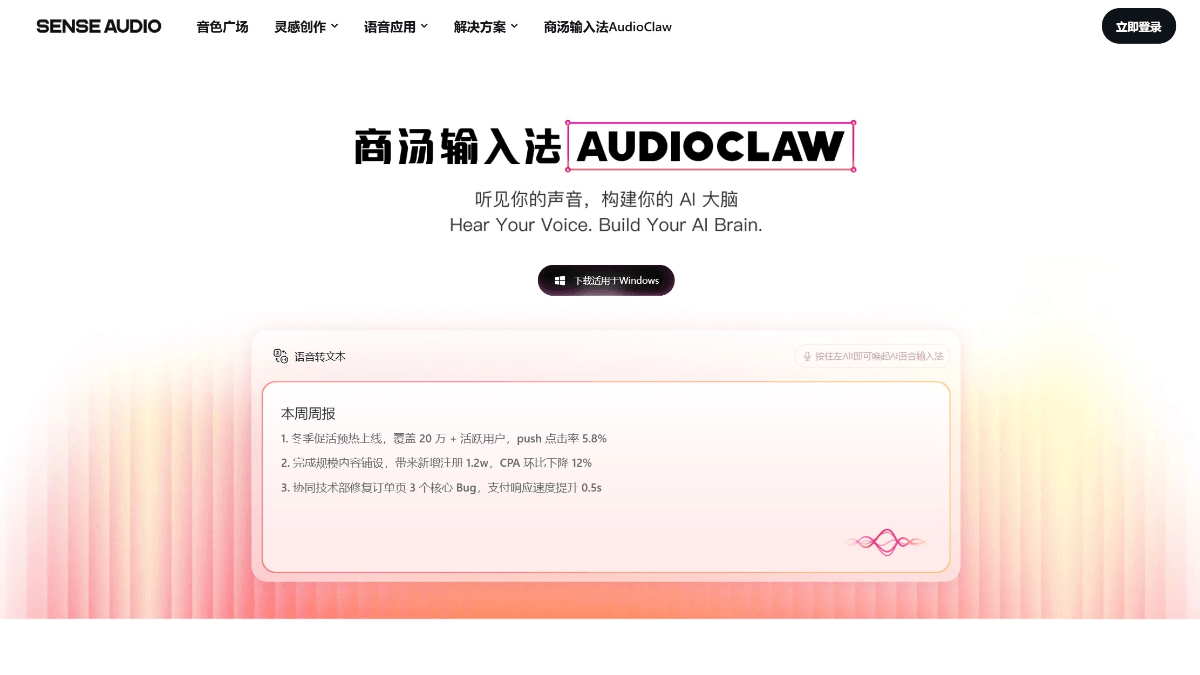
GLM-4.6V - Serie de modelos multilingües multimodales de código abierto Wisdom Spectrum AI
GLM-4.6V es una serie de grandes modelos lingüísticos multimodales de código abierto de Smart Spectrum AI. La serie contiene dos versiones: GLM-4.6V (106B-A12B), la versión base para escenarios de nube y clúster de alto rendimiento, con la arquitectura Mixed Expert (MoE), un total de unos 106.000 millones de referencias y una activación...