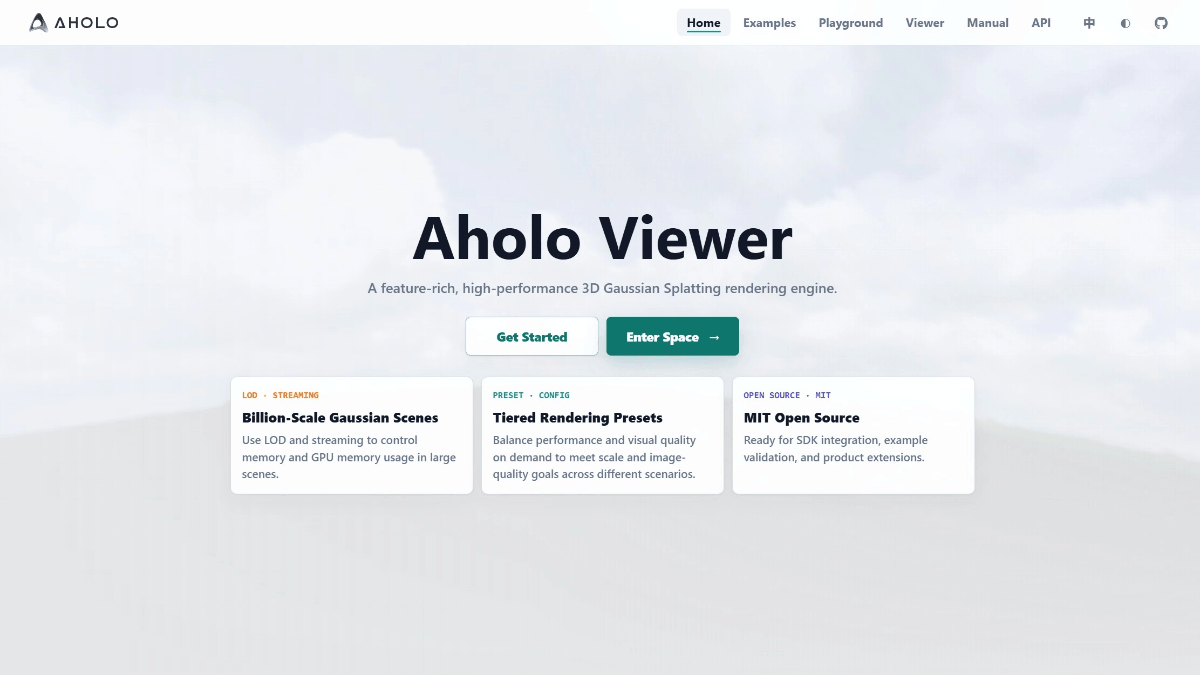
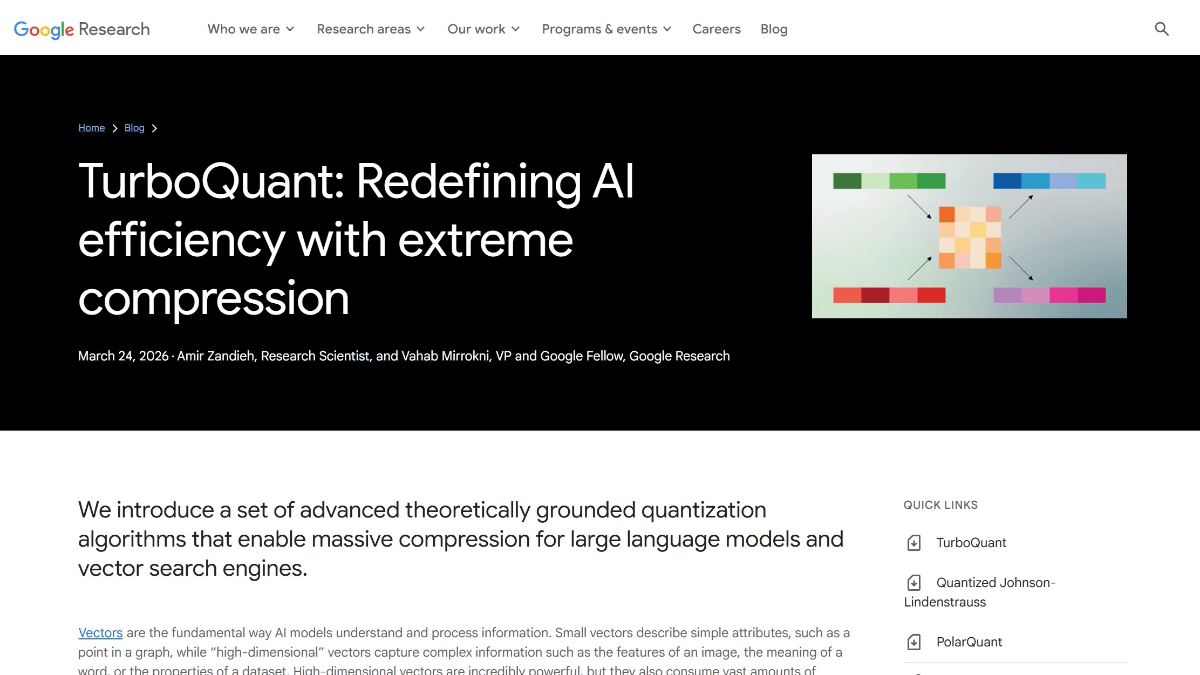
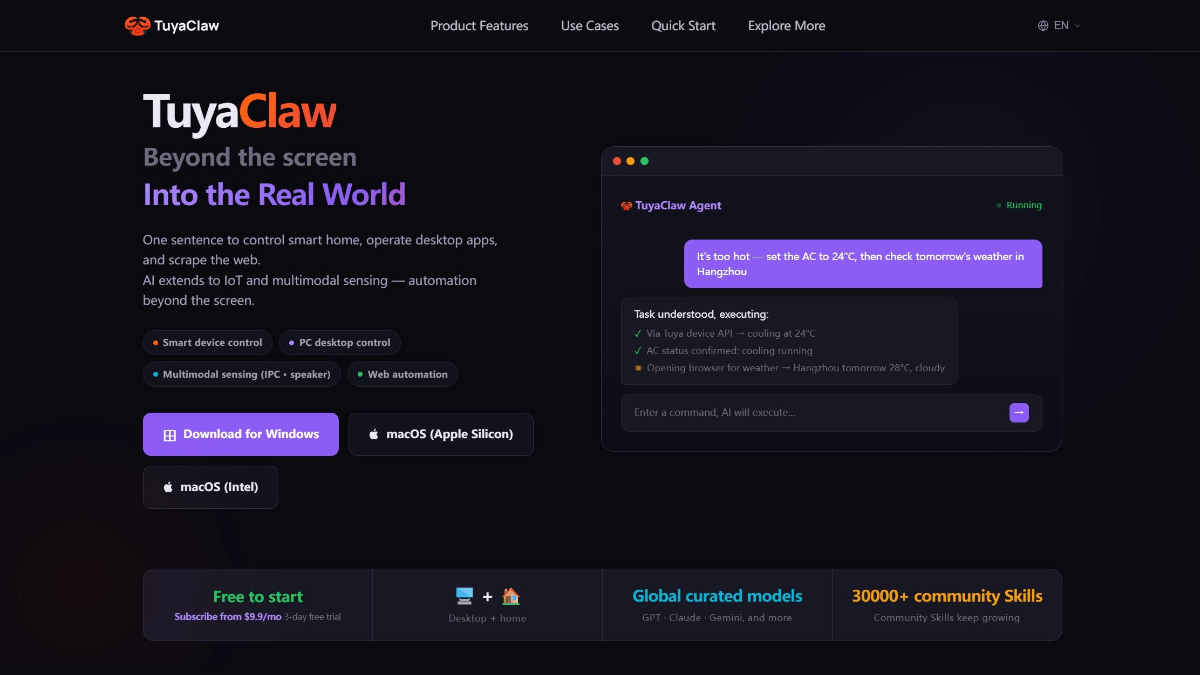
Kimi K2-0905は、Dark Side of the Moon Technologies Ltd.の先進的なAIモデルであり、プログラミング支援に優れ、効率的にコードを生成し、フロントエンド開発において整然とした標準化されたコードの生成をサポートします。モデルのコンテキスト長は256Kまで拡張され、複雑なタスクにも対応します。
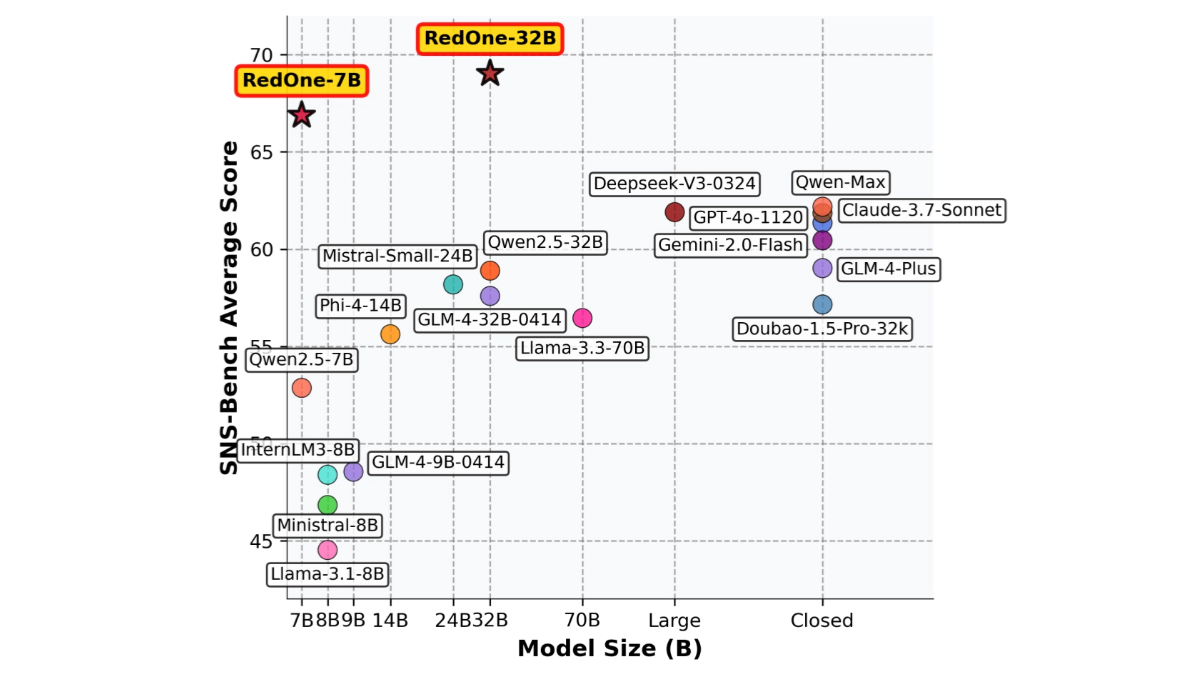
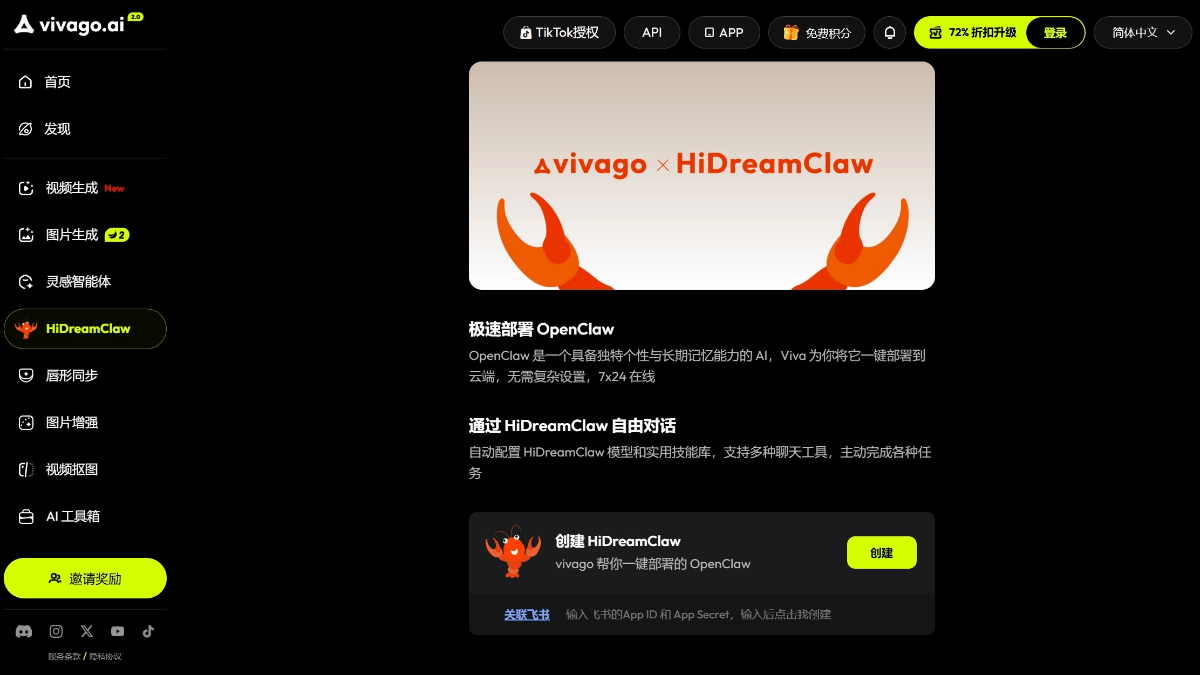
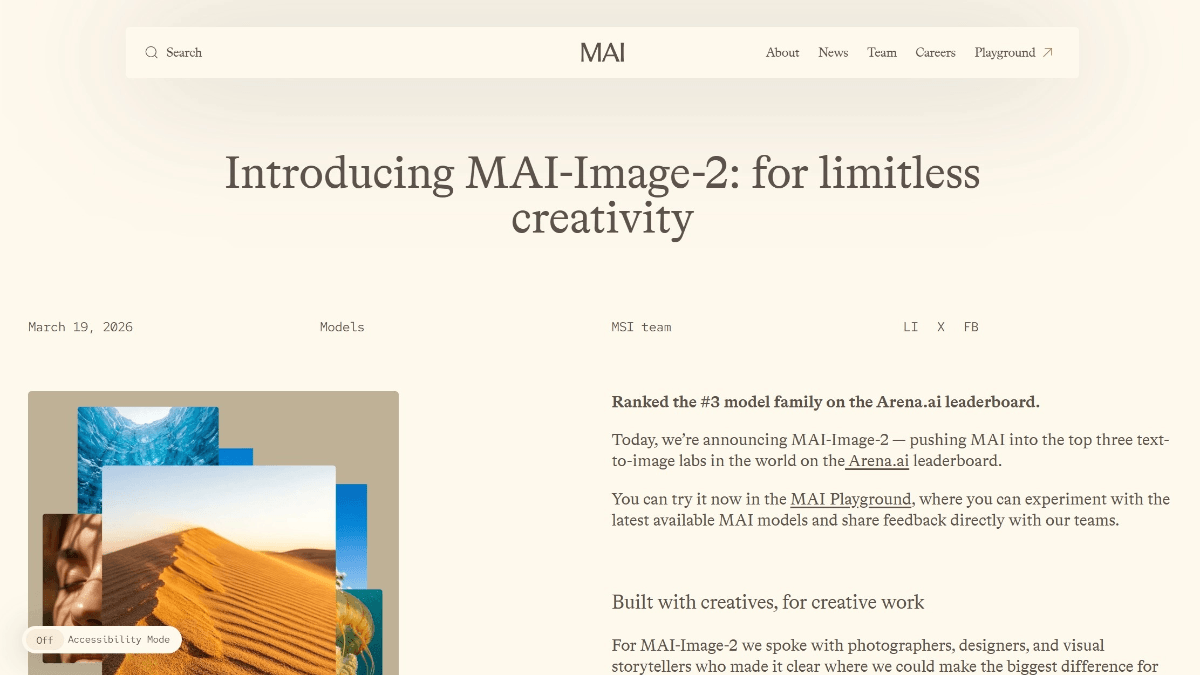
RedOneは、Little Red Bookによって導入されたソーシャルネットワーク用に調整された大規模言語モデルである。RedOneは、社会的・文化的知識を取り入れ、マルチタスク能力を強化し、人間の嗜好を調整する3段階の学習戦略によって学習される。RedOneは、社会的タスクのパフォーマンス、有害コンテンツの検出とブラウジングにおいて、基本モデルを大幅に上回る。