
Mamoda2.5是什么
Mamoda2.5 是字节跳动 Mamoda Team 研发的全球首个 25B 级统一多模态生成模型,模型基于自回归-扩散(AR-Diffusion)框架,采用 Qwen3-VL-8B 理解模块与 DiT-MoE 生成架构,拥有 128 个专家和 Top-8 路由机制,总参数约 250 亿,但每次推理仅激活约 30 亿参数(约 12%)。Mamoda2.5 支持文生图、文生视频、图像编辑与视频编辑等全任务,在多项基准测试中达到 SOTA 水平,推理速度较同类开源模型快 12 倍以上,视频编辑延迟低至 9.2 秒,性能接近闭源的 Sora 和 Kling。
Mamoda2.5的功能特色
- 텍스트-이미지 변환(TI):根据文本提示生成高质量静态图像,支持复杂语义理解与细节渲染。
- 文生视频(Text-to-Video):支持从文本描述直接生成视频内容,720p 93 帧视频生成约 110 秒。
- 图像编辑(Image Editing):基于指令对输入图像进行语义级编辑,如风格转换、对象替换等。
- 비디오 편집:支持指令驱动的视频编辑任务,如人物变换、天气环境修改、性别转换等,4 步蒸馏模型延迟仅约 9.2 秒。
- 멀티모달 이해:继承 Qwen3-VL-8B 能力,支持对图像和视频内容的深度理解与推理。
- 文本渲染优化:集成 ByT5 字节级编码器,显著提升视频中字幕、标牌等文本的拼写准确率和布局保真度。
Mamoda2.5的核心优势
- 极致稀疏激活效率:总参数 25B,单次前向传播仅激活约 3B 参数,训练和推理成本大幅降低。
- 推理速度领先:视频生成速度比阿里 Wan2.2 A14B 快 12 倍以上,比美团 LongCat Video 快 18 倍。
- 视频编辑速度突破:4 步蒸馏模型编辑延迟仅 9.2 秒,比 VInO 快 95.9 倍,比 OmniVideo2 快 41.7 倍。
- 统一架构设计:单一模型同时支持理解、生成和编辑任务,避免传统方案中多模型分离的复杂链路。
- 基准测试成绩优异:在 OpenVE-Bench、FiVE-Bench、Reco-Bench 视频编辑测试中均排名第一,VBench 2.0 得分 61.64 分,与腾讯 훈위안비디오 1.5 相当。
- 开源可商用:采用 Apache-2.0 协议发布,支持商业使用,降低企业和开发者接入门槛。
- 低部署门槛:激活参数仅 3B,可在单张高端消费级 GPU(如 RTX 4090)或服务器 GPU 上运行。
Mamoda2.5官网是什么
- 프로젝트 웹사이트:https://mamoda25.github.io/
- GitHub 리포지토리:https://github.com/bytedance/mammothmoda
- arXiv 기술 논문:https://arxiv.org/pdf/2605.02641
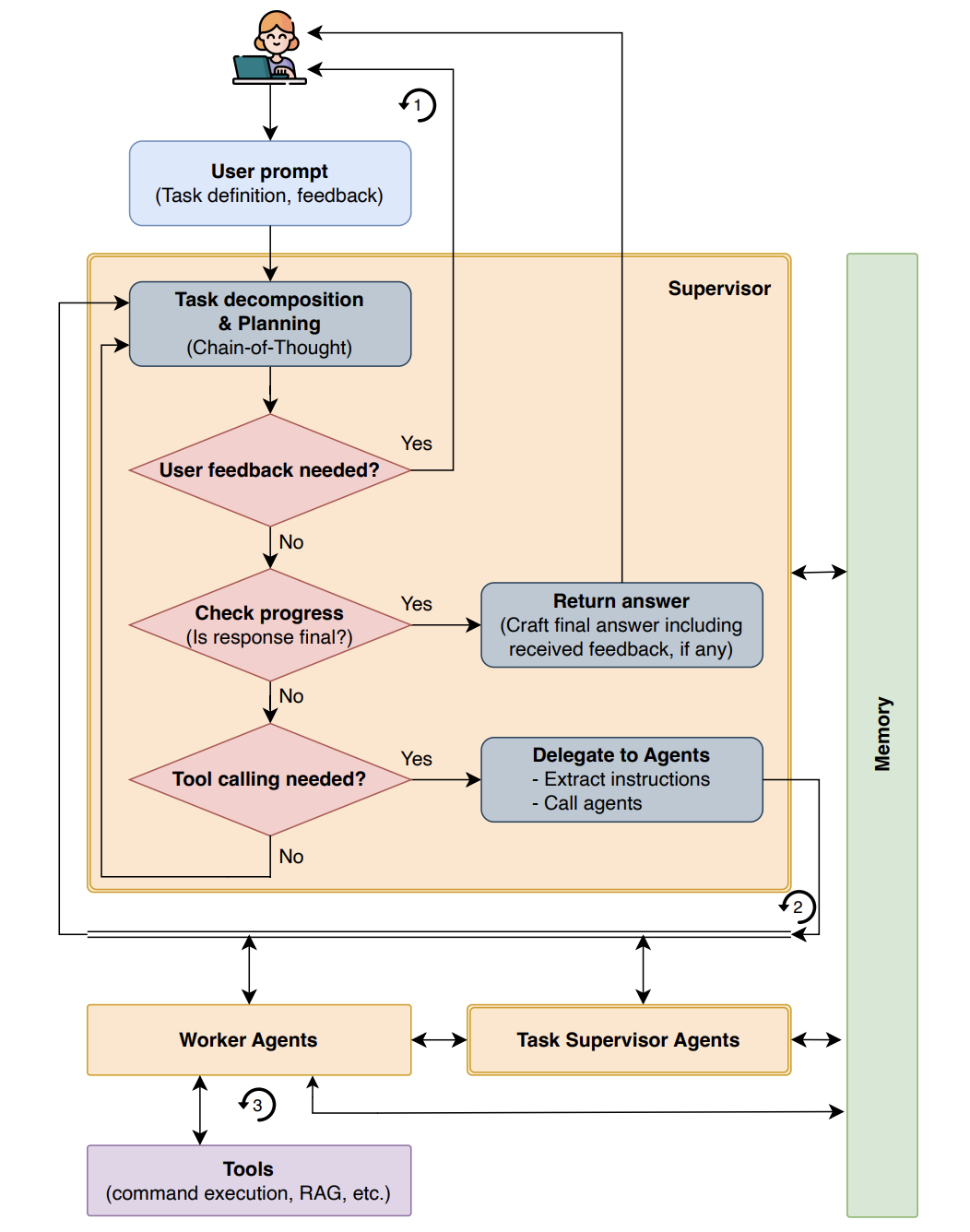
Mamoda2.5的操作步骤
- 모델 가중치 가져오기:前往官方 GitHub 或 Hugging Face 仓库下载 Mamoda2.5 的模型权重与配置文件(
.safetensors(형식). - 환경 준비:配置支持 PyTorch 的 Python 环境,确保 GPU 显存满足推理需求(推荐高端消费级或服务器级 GPU)。
- 모델 로드:使用官方提供的
modeling_mamoda.py노래로 응답config.json加载模型,或集成至 vLLM、SGLang 等支持 MoE 的高效推理框架。 - 입력:根据任务类型(文生图、文生视频、图像编辑、视频编辑)构造对应的文本提示和条件输入。
- 执行生成/编辑:调用模型进行推理,生成目标内容;视频编辑任务可选用 4 步蒸馏版本以获得更快响应。
- 结果解码:通过 VAE 解码器将潜在空间表示转换回像素空间,获取最终图像或视频输出。
Mamoda2.5的适用人群
- AI 研究者与算法工程师:需要研究统一多模态架构、MoE 稀疏激活机制或扩散模型的技术人员。
- AIGC 内容创作者:从事短视频、广告、社交媒体内容生产的创意人员。
- 视频编辑与后期制作人员:需要快速完成视频风格转换、对象替换、环境修改等编辑任务的专业人士。
- 开发者与创业公司:希望在本地或私有云部署高性能多模态生成能力的工程团队。
- 광고 및 마케팅 팀:需要批量生成和编辑广告素材、提升内容审核与创意修复效率的商业用户。
Mamoda2.5的常见问题
Q:个人开发者能否在本地部署 Mamoda2.5?
A: 可以。由于每次推理仅激活约 3B 参数,显存需求显著降低,官方暗示可在单张高端消费级 GPU(如 RTX 4090)上运行 720p 视频生成任务。完整权重和推理代码已在 GitHub / Hugging Face 开源。
A: 可以。由于每次推理仅激活约 3B 参数,显存需求显著降低,官方暗示可在单张高端消费级 GPU(如 RTX 4090)上运行 720p 视频生成任务。完整权重和推理代码已在 GitHub / Hugging Face 开源。
Q:Mamoda2.5 支持音频生成吗?
A: 目前版本主要支持统一的图像和视频生成与编辑,尚未整合音频处理。团队表示下一步将探索音频-视频同步生成与编辑,以扩展在影视创作中的应用范围。
A: 目前版本主要支持统一的图像和视频生成与编辑,尚未整合音频处理。团队表示下一步将探索音频-视频同步生成与编辑,以扩展在影视创作中的应用范围。
Q:模型权重基于什么底座训练?是否依赖特定生态?
A: Mamoda2.5 的理解模块基于 Qwen3-VL-8B,生成骨干的 DiT 部分权重通过"上循环"(Upcycling)策略从 Wan2.2 5B 稠密模型初始化转换而来。因此与阿里通义生态有一定技术渊源,但架构和条件注入机制已大幅重构。
A: Mamoda2.5 的理解模块基于 Qwen3-VL-8B,生成骨干的 DiT 部分权重通过"上循环"(Upcycling)策略从 Wan2.2 5B 稠密模型初始化转换而来。因此与阿里通义生态有一定技术渊源,但架构和条件注入机制已大幅重构。
Q:Mamoda2.5 的文本渲染能力如何?
A: 模型专门集成了 ByT5 字节级编码器,直接处理 UTF-8 序列而非子词令牌,能更准确地渲染视频中的字幕、标牌和场景文字,拼写准确率和布局保真度显著优于传统词级编码方案。
A: 模型专门集成了 ByT5 字节级编码器,直接处理 UTF-8 序列而非子词令牌,能更准确地渲染视频中的字幕、标牌和场景文字,拼写准确率和布局保真度显著优于传统词级编码方案。
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...