

1.概述
近年来,语音合成技术取得了显著进展,尤其是在实现实时、自然流畅的语音生成方面。然而,在真正的应用中,诸如延迟、发音准确度、说话人一致性等问题仍然困扰着行业,尤其是在需要高响应性的流媒体应用中。这些技术难题在处理复杂语言输入时尤为突出,比如绕口令或多音字,这超出了现有模型的处理能力。为了应对这些挑战,阿里巴巴的研究人员推出了CosyVoice 2,一款针对语音合成技术难题的升级版模型,旨在有效解决这些问题。
2.CosyVoice 2 的亮相:从基础到突破
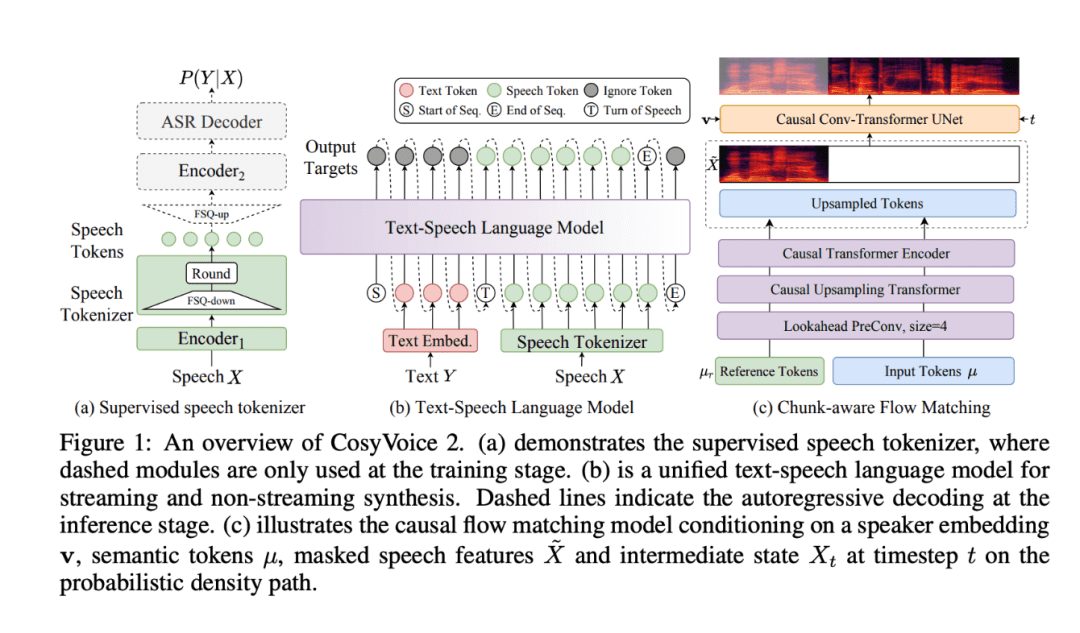 CosyVoice 2 建立在原版 CosyVoice 的基础之上,带来了语音合成技术的显著升级。这款增强型模型不仅针对流媒体应用进行了优化,还在离线应用中取得了显著进展。其在多种应用场景下的适应性、灵活性和精准度有了很大提升,尤其在文本转语音和互动语音系统中表现尤为突出。
CosyVoice 2 建立在原版 CosyVoice 的基础之上,带来了语音合成技术的显著升级。这款增强型模型不仅针对流媒体应用进行了优化,还在离线应用中取得了显著进展。其在多种应用场景下的适应性、灵活性和精准度有了很大提升,尤其在文本转语音和互动语音系统中表现尤为突出。
CosyVoice 2的核心亮点:
- 统一的流媒体和非流媒体模式:CosyVoice 2 能够无缝适应各种应用场景,无论是实时生成还是离线处理,都不影响性能表现。
- 更高的发音准确性:在复杂语言环境下,CosyVoice 2 减少了30%-50%的发音错误,特别在处理多音字或绕口令时,能够大大提高语音的清晰度。
- 增强的说话人一致性:无论是零-shot合成还是跨语言合成,CosyVoice 2 都能够确保语音输出的一致性,让每一次合成都自然流畅。
- 更精准的指令控制:用户可以通过自然语言指令,精确控制语音的语气、风格以及口音,甚至根据情感需求调整语音表现。
3.创新背后的技术与优势
CosyVoice 2 之所以能够解决语音合成领域的多项难题,得益于其在技术上的多项创新。
- 有限标量量化(FSQ)技术:FSQ取代了传统的向量量化方法,优化了语音标记词汇表的使用,提升了语义表示能力和合成质量。这一技术创新不仅增强了模型的表现力,还有效减少了数据处理的复杂性。
- 简化的文本到语音架构:CosyVoice 2 以预训练的大型语言模型(LLMs)为基础,摒弃了额外的文本编码器,简化了模型架构,提高了跨语言的表现能力。这一结构设计使得CosyVoice 2在处理多种语言时,效率和准确度均得到了显著提升。
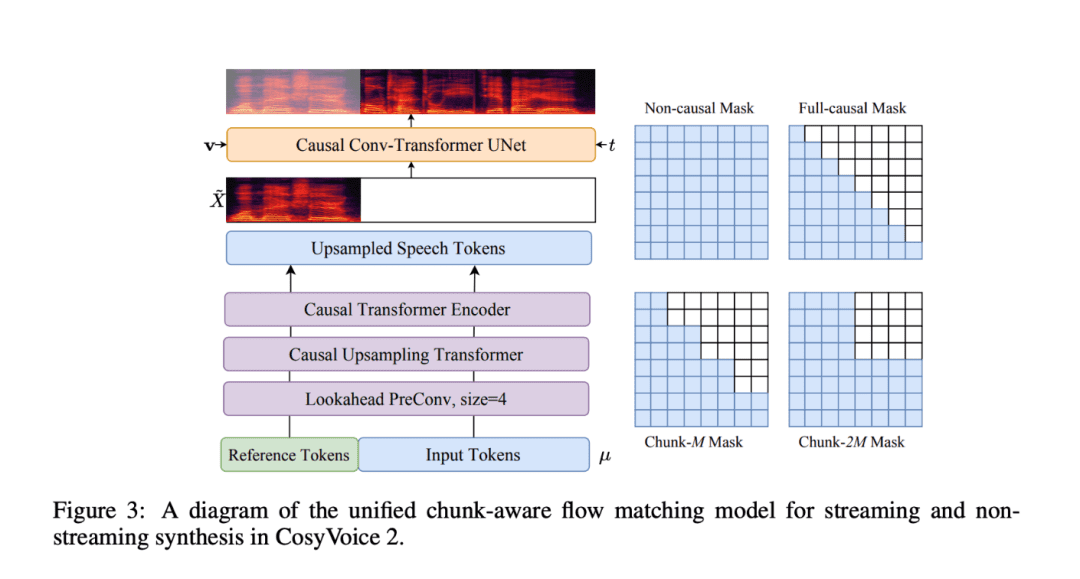
- 基于块感知的因果流匹配技术:这一创新技术使得语义和声学特征能够在最小的延迟下进行对齐,使得CosyVoice 2 能够在实时语音生成中表现出色,尤其适用于实时语音交互和流媒体应用。
- 扩展的指令数据集:CosyVoice 2 通过超过1500小时的训练数据,增加了对不同口音、情感以及语音风格的细致控制,使得语音合成变得更加灵活和富有表现力。无论是温暖的语气,还是紧张的情感,CosyVoice 2 都能够精准地捕捉并表现。
4.CosyVoice 2的性能表现:如何解决实际问题
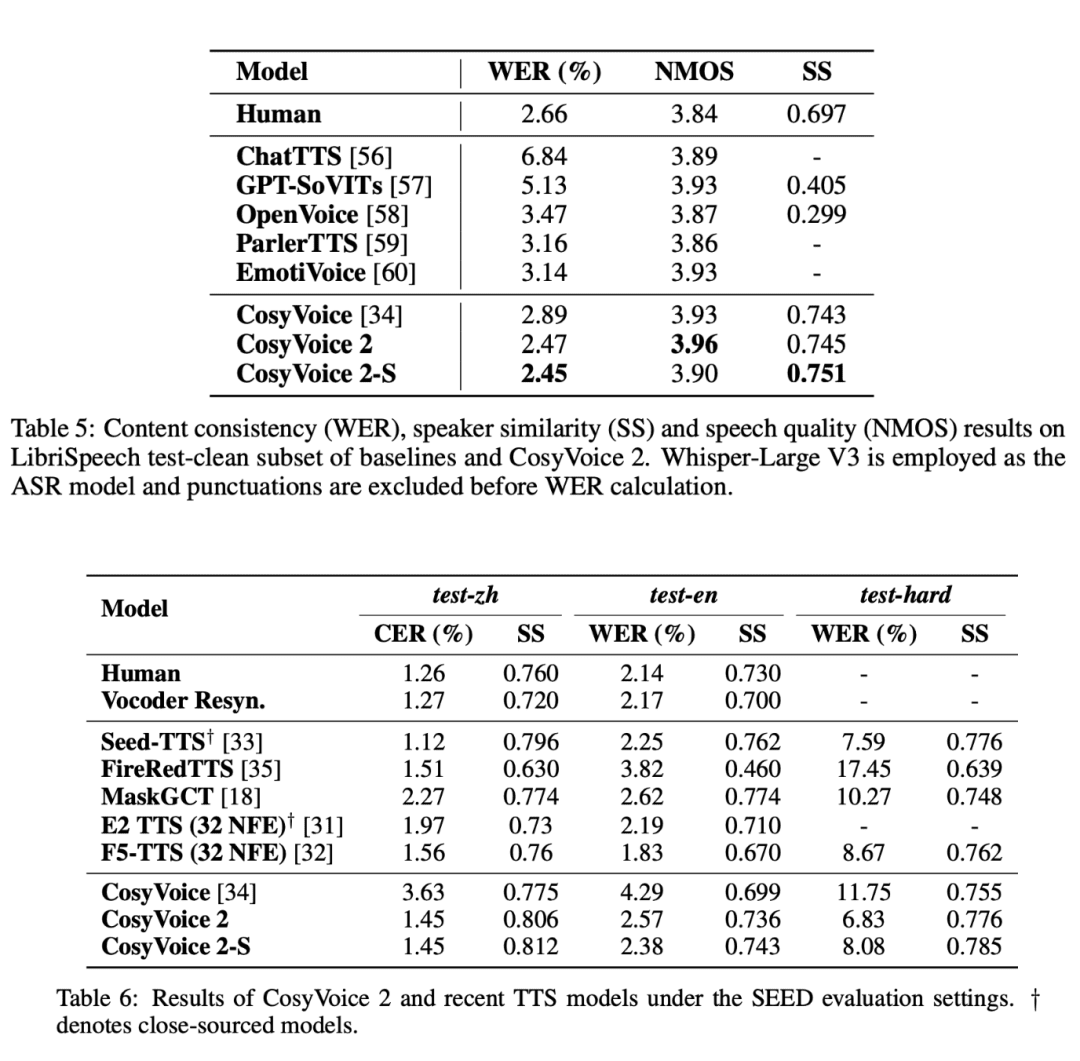
在一系列严格的评估测试中,CosyVoice 2 展现出了不容忽视的优势,特别是在低延迟、高准确性和语音一致性方面表现突出。
- 低延迟与高效性:CosyVoice 2 在语音生成中的响应时间可以低至150毫秒,这意味着它能够非常适合用于实时语音应用,例如语音聊天和流媒体互动。
- 改进的发音准确性:CosyVoice 2 对复杂语言结构(如多音字、绕口令等)有了显著提升,极大地改善了发音的准确性,减少了在日常语音合成中的错误。
- 一致的说话人表现:CosyVoice 2 能够在不同的合成任务中保持高度一致性,无论是跨语言合成,还是零-shot合成,语音的自然度和稳定性都得到了极大的保证。
- 多语言能力:CosyVoice 2 在日语和韩语等语言的基准测试中也表现出色,尽管在某些重叠字符集的处理上还有挑战,但它依然展现了跨语言合成的强大能力。
- 在挑战性场景中的韧性:CosyVoice 2 在一些极具挑战性的语音场景(如绕口令)中,表现出比之前的模型更好的清晰度和准确度,超越了以往的技术局限。
5.结语
CosyVoice 2 的推出,是语音合成技术的一次重要进步。它通过解决延迟、准确度和说话人一致性等关键问题,提供了一个更加成熟和稳定的解决方案。FSQ和块感知因果流匹配等创新技术,为模型的性能和易用性提供了强有力的支撑,而庞大的训练数据集和对语音风格的精确控制,则使其能够应对各种复杂的语音应用场景。
尽管CosyVoice 2 在多语言支持和复杂语言场景的处理上还有待进一步完善,但它为未来的语音合成技术奠定了坚实的基础,尤其是在流媒体和实时语音生成的应用中,具有广阔的发展前景。无论是在AI语音助手、智能客服,还是实时翻译等领域,CosyVoice 2 都展示了其强大的潜力,并为语音合成技术的进一步突破铺平了道路。
参考:
- https://arxiv.org/abs/2412.10117
- https://huggingface.co/spaces/FunAudioLLM/CosyVoice2-0.5B
- https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...