

全球首个去中心化训练的10B参数模型诞生了!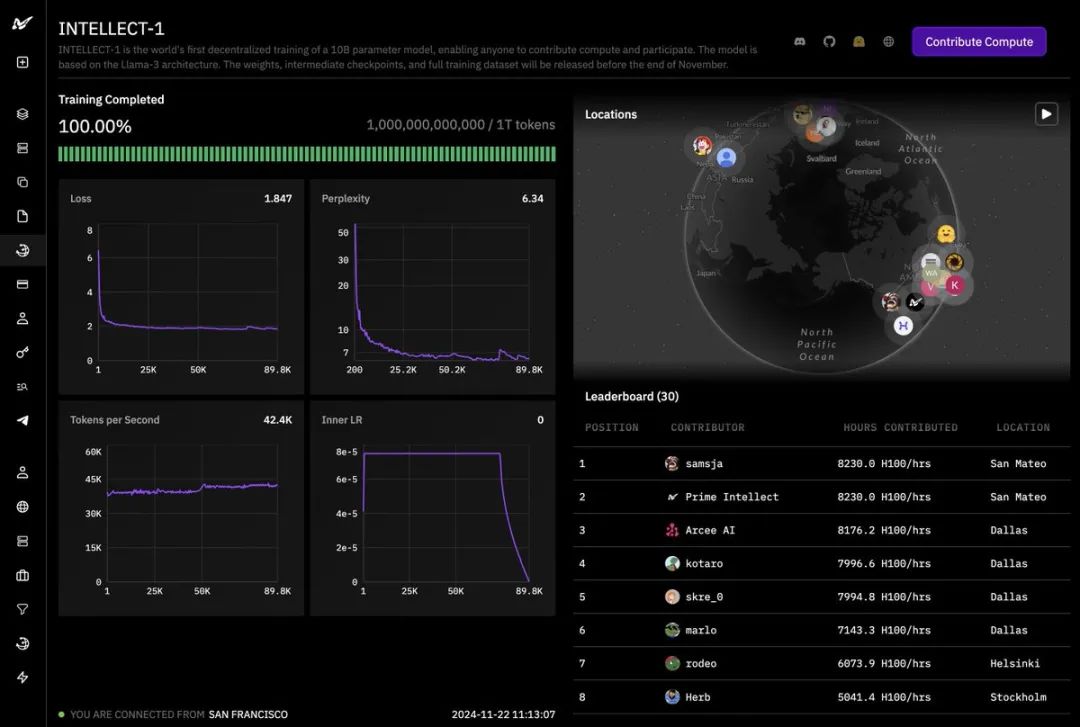 Prime Intellect团队宣布,他们完成了一项具有里程碑意义的工作:跨越美国、欧洲和亚洲的去中心化训练网络,成功训练出了一个10B参数的大模型。这标志着AI训练领域迈出了革命性的一步。
Prime Intellect团队宣布,他们完成了一项具有里程碑意义的工作:跨越美国、欧洲和亚洲的去中心化训练网络,成功训练出了一个10B参数的大模型。这标志着AI训练领域迈出了革命性的一步。
从训练面板可以看到,这个名为INTELLECT-1的项目已经完成了1万亿(1T)tokens的训练。
损失和困惑度曲线都呈现出理想的下降趋势,每秒生成的token 数也保持稳定,这表明训练过程非常成功。 这个项目的成功离不开众多合作伙伴的鼎力支持。
这个项目的成功离不开众多合作伙伴的鼎力支持。
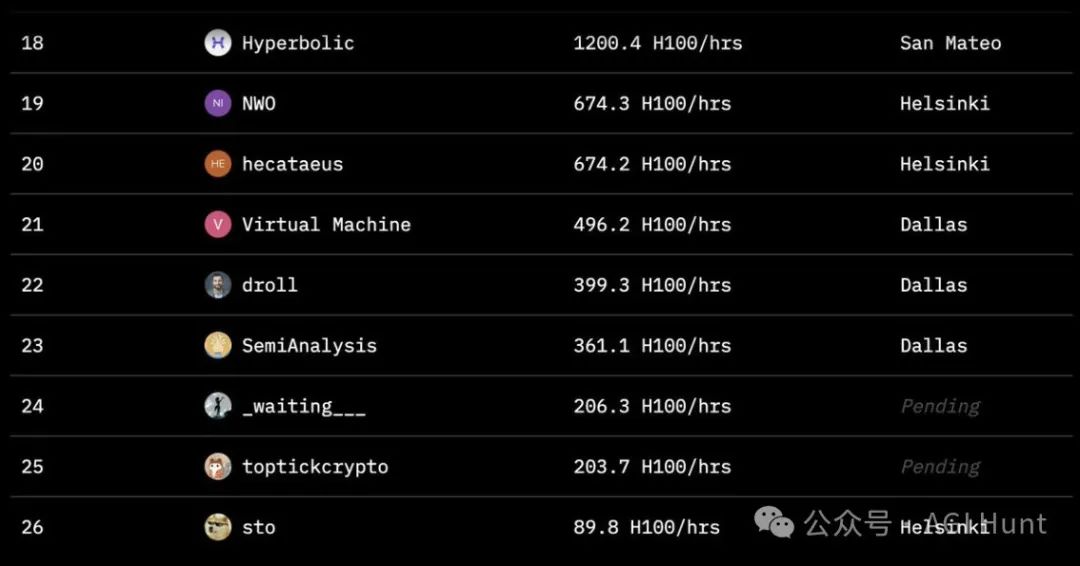
包括Hugging Face、SemiAnalysis、Arcee.ai、Hyperbolic Labs、Olas、Akash、Schelling AI等在内的多家机构都为这次训练贡献了宝贵的算力资源。这种前所未有的合作模式,展示了AI领域的新型协作方式。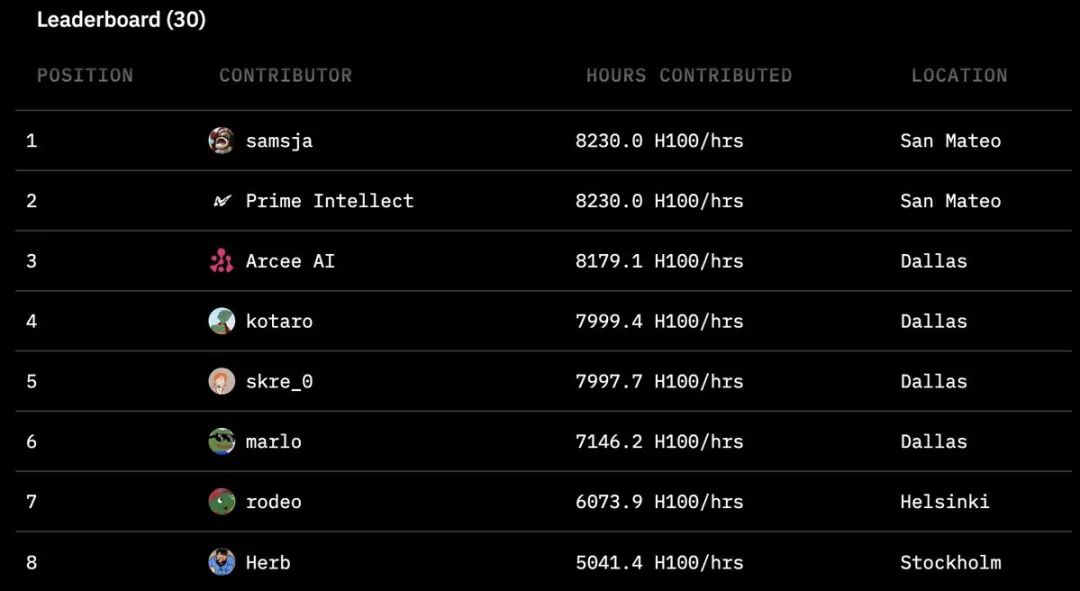 从项目的排行榜可以看到,来自全球各地的贡献者们提供了惊人的计算时间。最高的贡献者达到了8230小时,参与者遍布圣马特奥、达拉斯、赫尔辛基和斯德哥尔摩等地。这种全球化的算力协作模式,让AI训练不再局限于少数科技巨头的数据中心。
从项目的排行榜可以看到,来自全球各地的贡献者们提供了惊人的计算时间。最高的贡献者达到了8230小时,参与者遍布圣马特奥、达拉斯、赫尔辛基和斯德哥尔摩等地。这种全球化的算力协作模式,让AI训练不再局限于少数科技巨头的数据中心。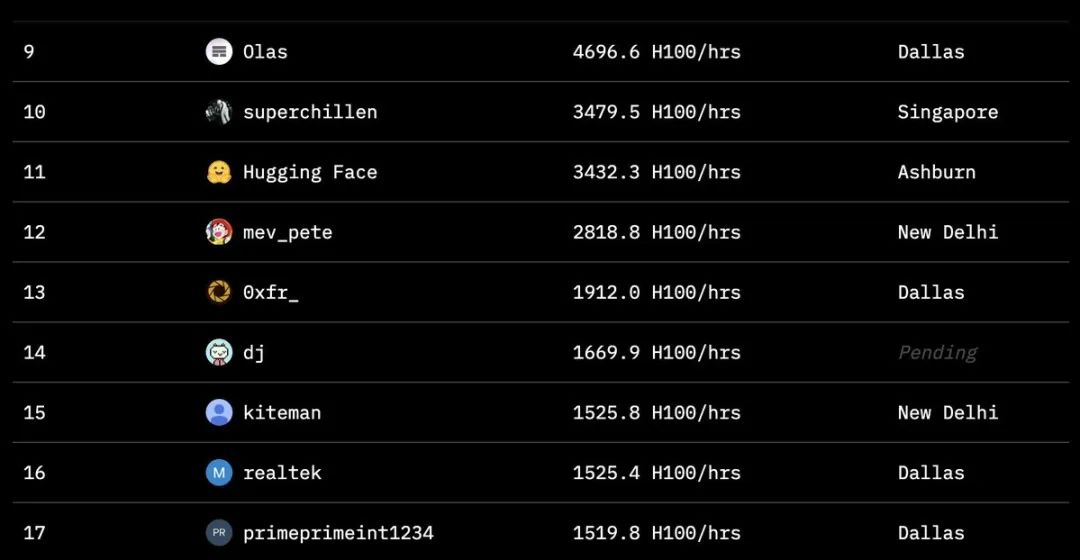
在技术层面,这个项目的创新同样令人印象深刻。
团队采用了DiLoCo分布式训练技术,解决了跨地域训练的难题。为了应对分布式环境下的各种挑战,研究团队还实现了容错训练机制和异步分布式检查点技术。
在内存优化方面,团队选择了升级到FSDP2框架,成功解决了FSDP1中存在的内存分配问题。
同时,通过张量并行计算技术的应用,显著提升了训练效率。
这些技术创新的背后,是一个强大的研究团队在默默付出。项目负责人特别感谢了Tristan Rice和Junjie Wang在容错训练方面的贡献,以及Chien-Chin Huang和Iris Zhang在异步分布式检查点方面的工作。同时,Yifu Wang在张量并行计算方面的建议也功不可没。
更令人期待的是,团队宣布将在一周内发布完整的开源版本,包括基础模型、检查点文件、后训练模型和训练数据集。这意味着全球的研究者和开发者很快就能基于这个模型进行创新和开发。
已经有开发者迫不及待地开始了实验。一位开发者展示了在美国西海岸和欧洲的两块4090显卡上进行模型推理的尝试。虽然两地的网络连接并不理想,但这个实验证明了模型的灵活性和适应性。
这个项目的成功,不仅仅是技术上的突破,更是AI 全民民主化的重要里程碑。
它证明了通过全球协作,我们完全可以突破传统AI训练的限制,让更多机构和个人参与到AI发展的浪潮中来。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章




暂无评论...