VOP:提取复杂图表与数学公式的OCR工具综合介绍 Versatile OCR Program 是一个开源的光学字符识别(OCR)工具,专门为处理复杂的学术和教育文档设计。它能从PDF、图像等文件中提取文本、表格、数学公式、图表和示意图,并生...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前053.2K
自动解析PDF内容并提取文字与表格的开源服务综合介绍 它能自动分析PDF文档的布局,识别页面中的文字、标题、图片、表格、公式等元素,并判断它们的正确顺序。工具支持OCR功能,可以把扫描PDF转为可搜索文本。它基于Docker运行,提供两种模型...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前060.3K
RolmOCR:识别手写和倾斜字符的文档OCR模型综合介绍 RolmOCR 是由 Reducto AI 团队开发的一款开源光学字符识别(OCR)工具,基于 Qwen2.5-VL-7B 视觉语言模型。它能从图片和 PDF 文件中提取文字,速度比同类工具...最新AI资源# AI开源项目# OCR1年前065.4K
uniOCR:跨平台开源的文字识别工具综合介绍 uniOCR 是一个开源的文字识别工具,由 mediar-ai 团队开发。它基于 Rust 语言编写,支持 macOS、Windows 和 Linux 系统。用户可以通过它从图片中提取文字...最新AI资源# AI开源项目# OCR1年前081.9K
PDF Craft:PDF扫描文件转Markdown的开源工具综合介绍 PDF Craft 是一个开源工具,专为扫描书籍的PDF设计,能将其转换为Markdown格式。它由 oomol-lab 开发,托管在 GitHub 上,适合喜欢整理电子书的用户。工具通过本...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前083.4K
SmolDocling:小体积高效处理文档的视觉语言模型综合介绍 SmolDocling 是由 ds4sd 团队与 IBM 合作开发的一个视觉语言模型(VLM),基于 SmolVLM-256M 打造,托管在 Hugging Face 平台。它体积小,只有 ...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前053.3K
Mistral OCR:94.89%总体精度,1000 页/30秒,只需1美元在人类文明的历史长河中,每一次信息获取和解析方式的飞跃,都深刻地推动着社会进步。从远古的象形文字,到便携的纸莎草,再到后来出现的印刷术以及当今的数字化浪潮,每一次技术革新都极大地拓展了人类知识的传播范...最新AI资源# AI开放服务# OCR# 文档提取与清洗1年前061.2K
Ollama OCR:使用Ollama中视觉模型提取图像中的文本综合介绍 Ollama OCR是一个强大的光学字符识别(OCR)工具包,它利用Ollama平台提供的最先进视觉语言模型来从图像中提取文本。该项目既可作为Python包使用,也提供了用户友好的Strea...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前0107K
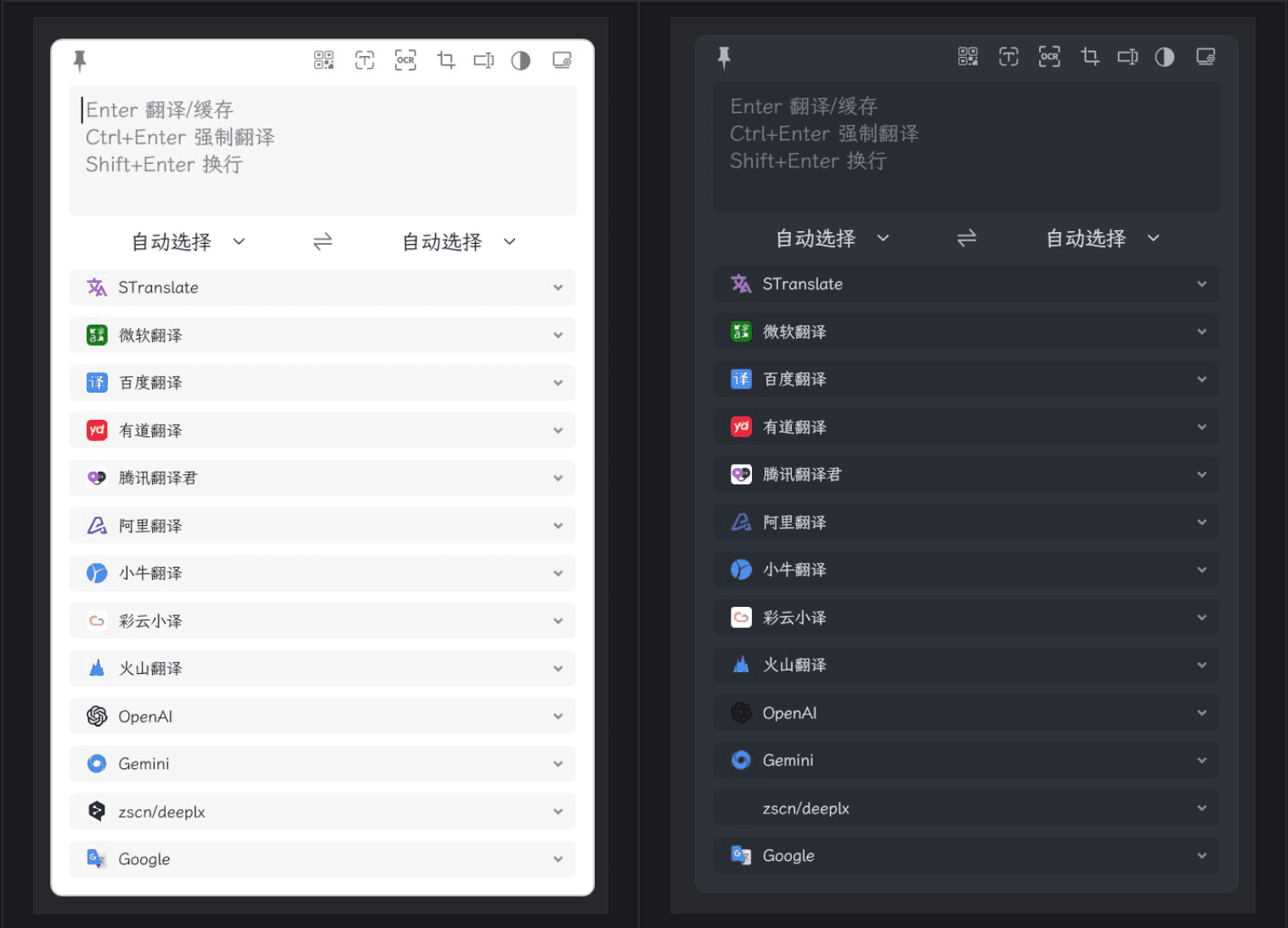
STranslate:集成多种翻译接口和OCR功能的轻便翻译工具综合介绍 STranslate 是一个由 WPF 开发的即用即走的翻译和 OCR 工具。该工具旨在提供高效、便捷的翻译和光学字符识别(OCR)功能,适用于各种语言和文本类型。STranslate 是开...最新AI资源# AI翻译# OCR1年前062.8K
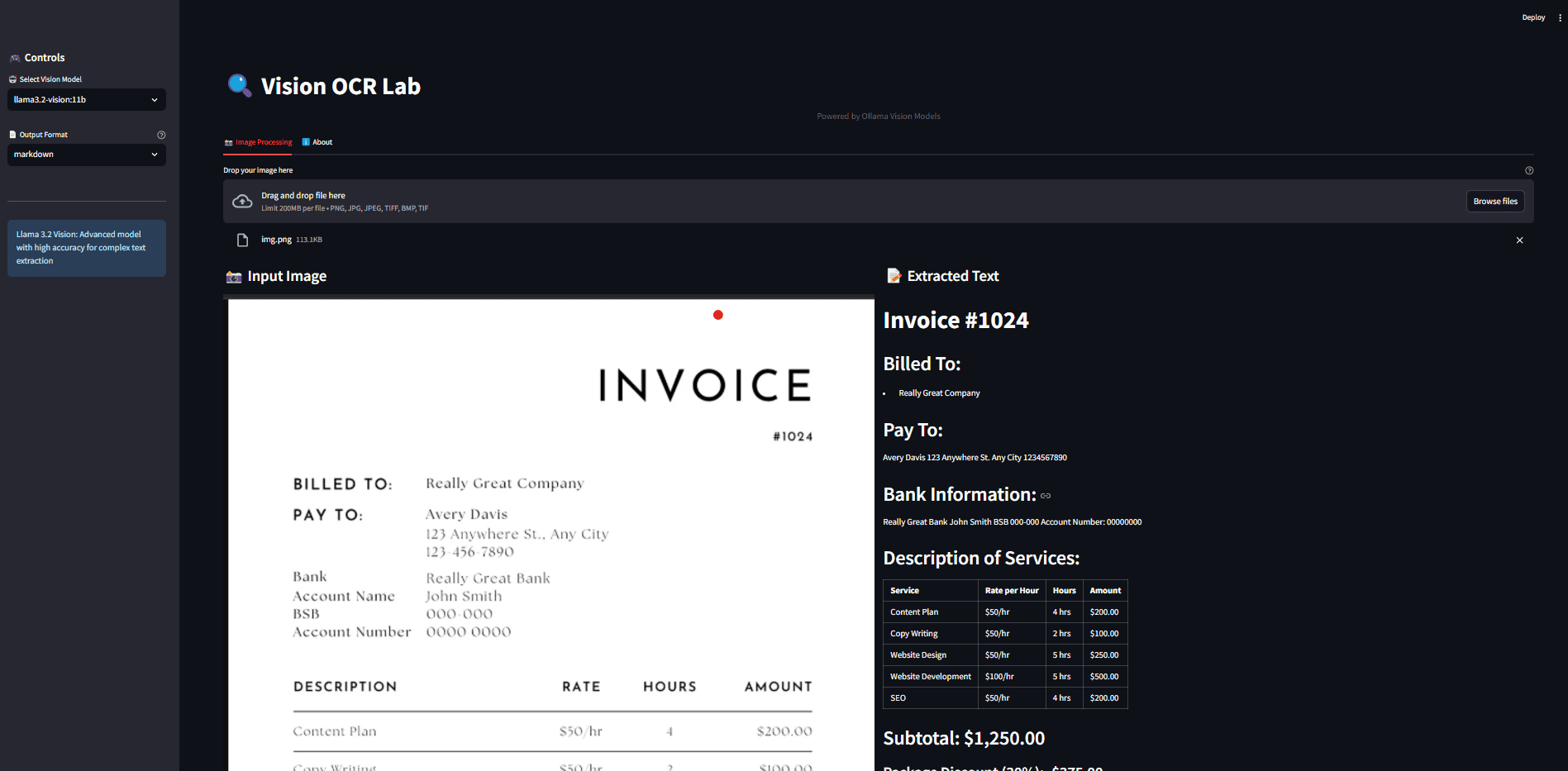
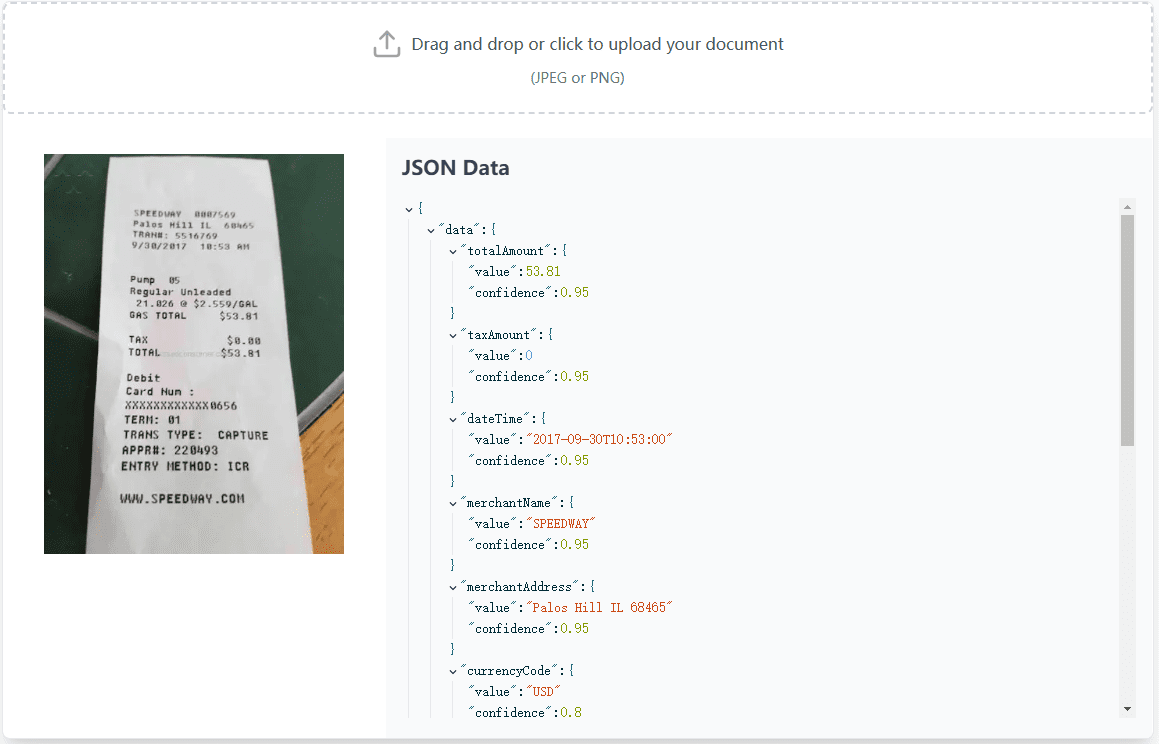
VisionParser:高精度处理收据和发票的OCR工具,提供API综合介绍 VisionParser是一款专为处理收据和发票而设计的OCR(光学字符识别)工具。通过先进的生成式AI技术,VisionParser能够快速、准确地将各种收据和发票转换为结构化数据,适用于...最新AI资源# OCR1年前058.9K
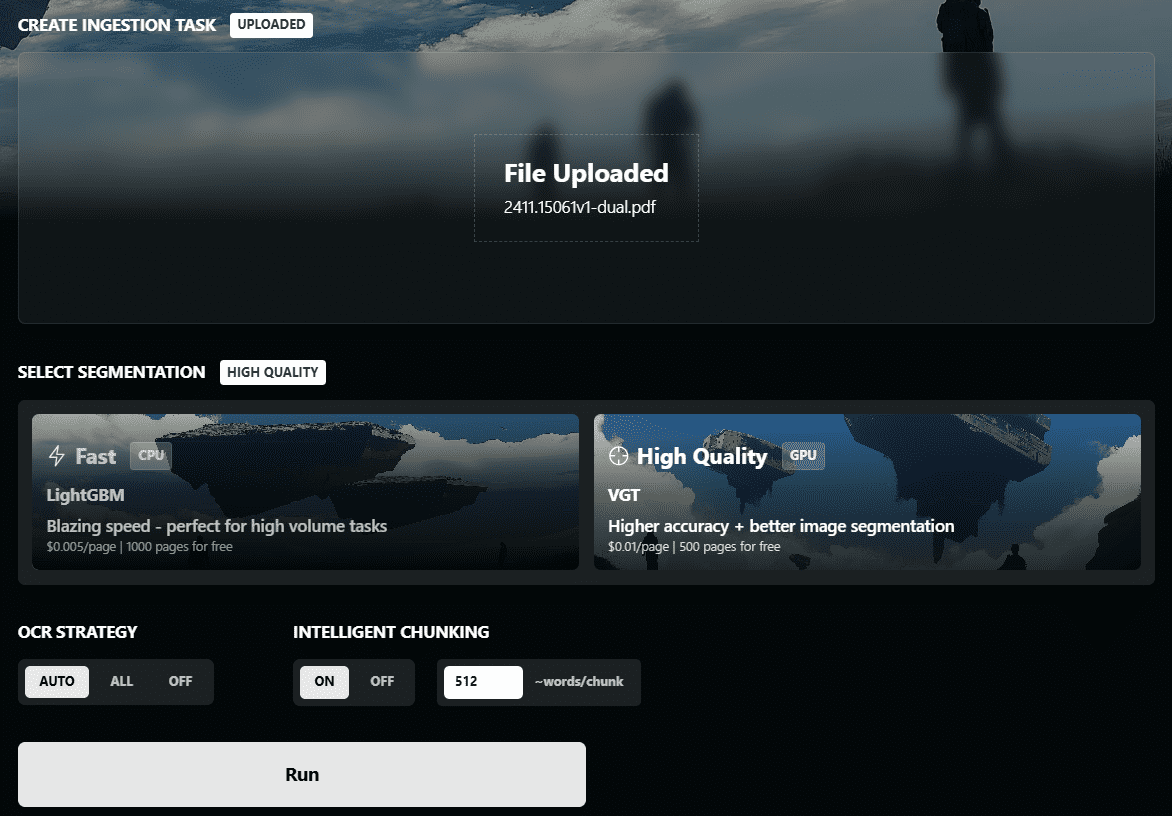
Chunkr:使用视觉模型进行文档摄取以及根据文本段落层级智能分块的一体化服务综合介绍 Chunkr 是一个自托管的 API,专门用于将 PDF、PPTX、DOCX 和 Excel 文件转换为适合 RAG(检索增强生成)和 LLM(大语言模型)使用的数据。该项目由 Lumina...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前055.7K
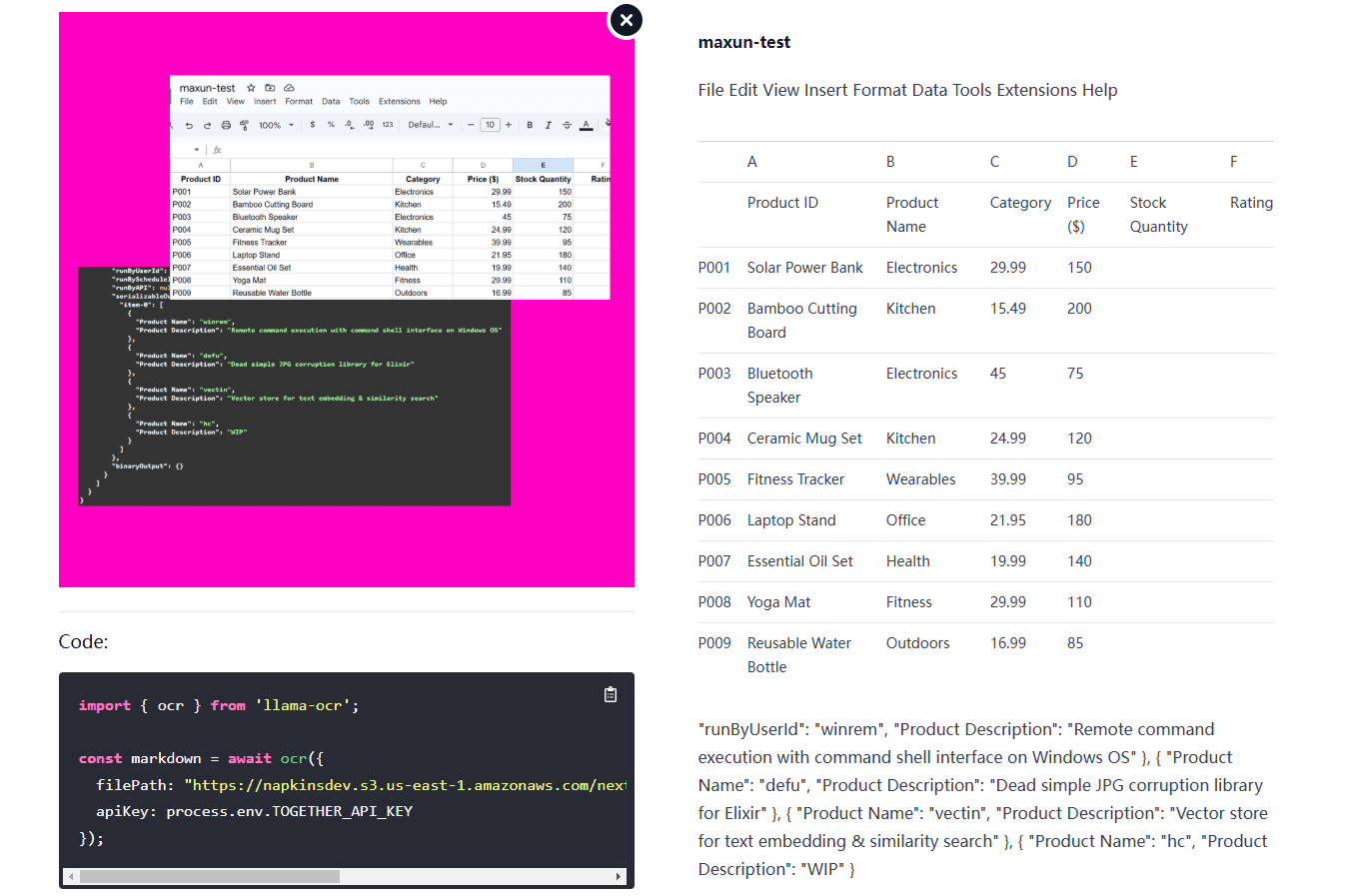
Llama OCR:利用免费Llama 3.2 Vision接口,三行代码将图像转换为Markdown的OCR库综合介绍 Llama OCR 是一个基于 Llama 3.2 Vision 的 OCR(光学字符识别)库,能够将文档转换为 Markdown 格式。该库由 Nutlope 开发,使用 Together...最新AI资源# AI开源项目# OCR# 免费大模型API1年前063.3K
Docling:支持多种格式文档解析并导出为Markdown和JSON,PDF支持OCR综合介绍 Docling 是一个强大的文档解析和导出工具,支持多种文档格式,包括 PDF、DOCX、PPTX、XLSX、图像、HTML、AsciiDoc 和 Markdown。它能够将这些文档解析并导...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前0110.1K
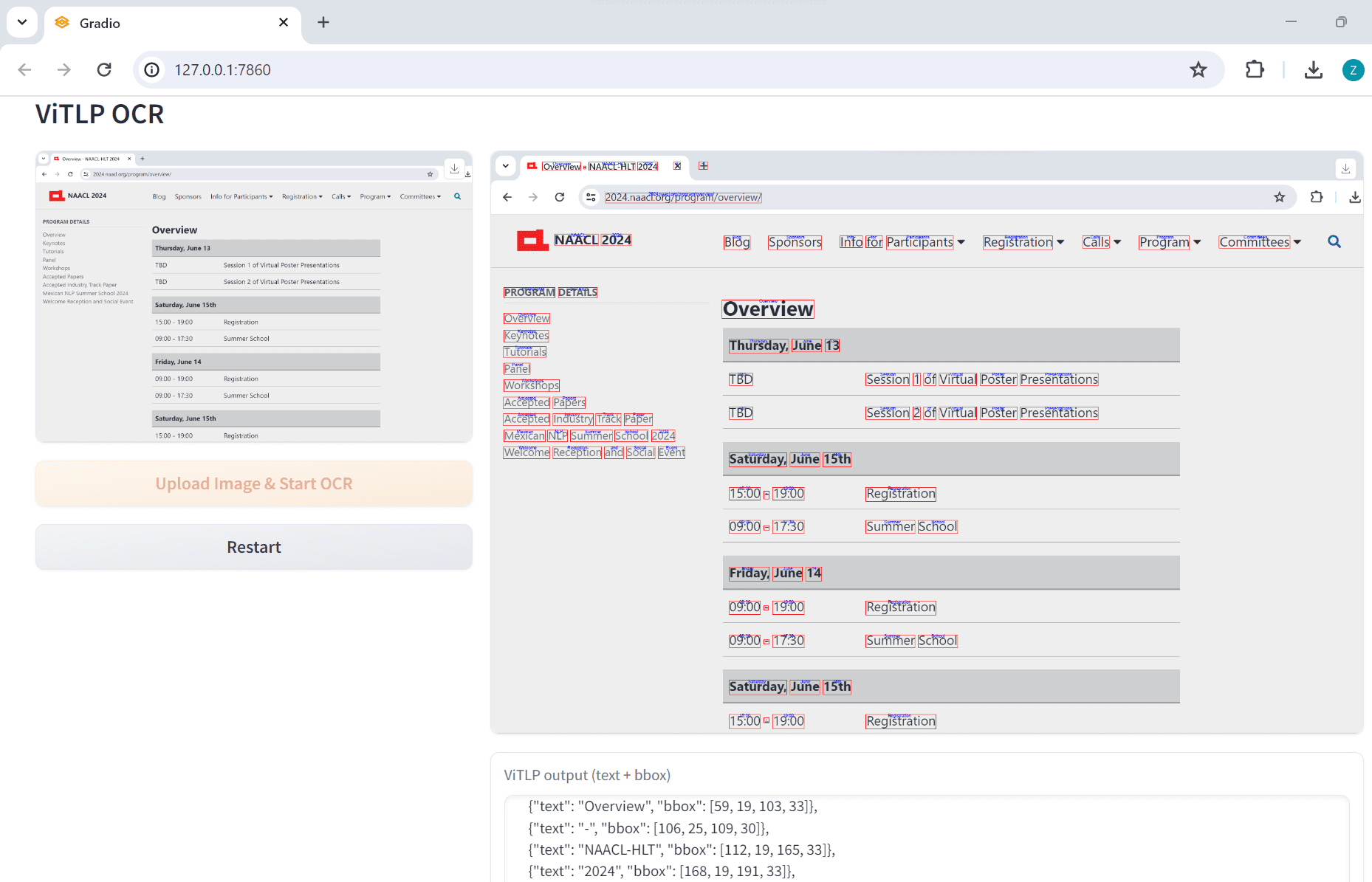
ViTLP:排版复杂PDF文档提取结构化数据,视觉引导生成文本布局预训练模型综合介绍 ViTLP(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)是一个开源项目,旨在通...最新AI资源# OCR# 文档提取与清洗1年前055K
ScreenPipe:24小时收集录屏和操作信息并转换为本地知识库,通过AI助手对话、总结、回顾知识综合介绍 ScreenPipe 是一款由 mediar-ai 开发的 AI 助手工具,专注于 24 小时不间断的录制屏幕内容、捕获截图和音频。它结合了 rewind.ai 和 cursor.com 的...最新AI资源# AI文本与音频/视频总结工具# AI笔记# OCR1年前067.8K
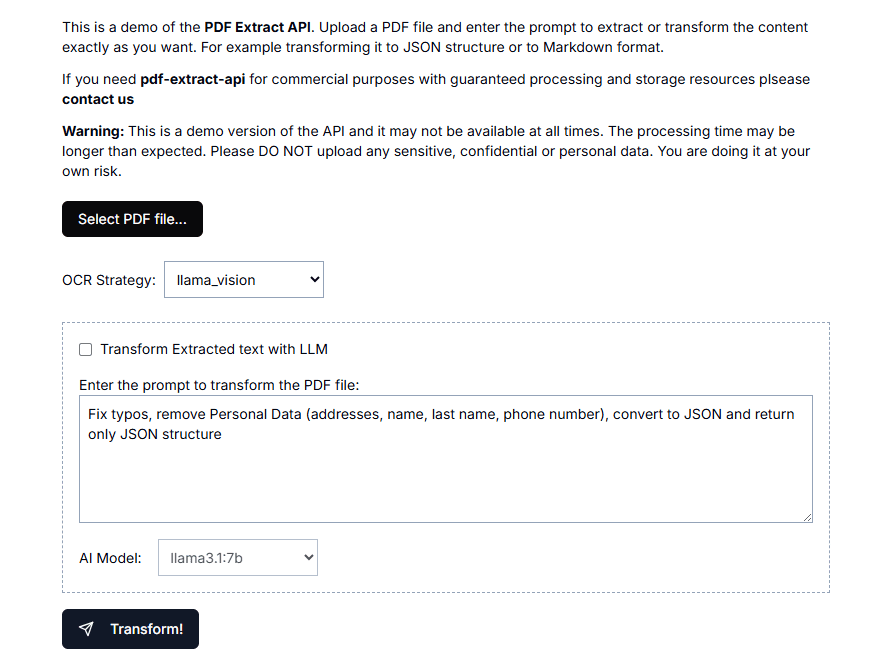
文本提取API(text-extract-api):视觉提取文本信息,匿名化的PDF提取工具综合介绍 文本提取API(text-extract-api)是一个强大的工具,旨在从各种文档格式(如PDF、Word、PPTX等)中提取和解析内容。该API利用最先进的光学字符识别(OCR)技术和Ol...最新AI资源# AI开源项目# OCR# 文档提取与清洗1年前058.3K
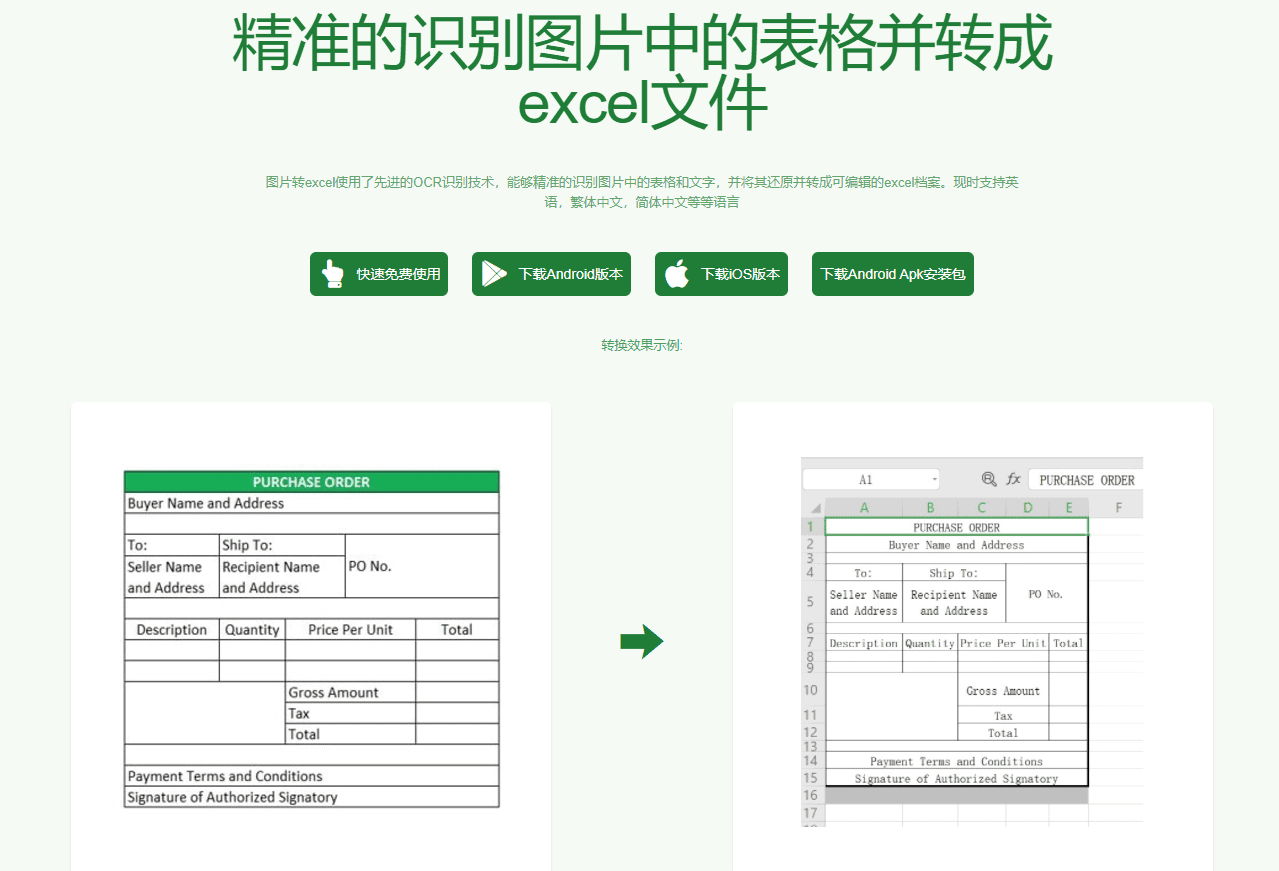
图片转Excel免费工具:高效识别图片中复杂格式的表格并转换为Excel文件综合介绍 图片转Excel免费工具是一款高效的在线工具,能够快速准确地识别并转换图片中的表格数据至Excel文件。该工具支持多种图片格式,如JPG和PNG,并且可以在网页、iOS应用和Android应...最新AI资源# OCR1年前079.3K
Datalab:专用OCR识别AI模型,PDF转Markdown(开源/API)综合介绍 Datalab 提供了一系列先进的AI模型,专注于OCR、布局分析、PDF转Markdown等功能。这些模型不仅性能卓越,而且易于使用,并且是开源的。平台上的Marker模型可以快速准确地将...最新AI资源# AI开放服务# AI开源项目# OCR1年前066.9K
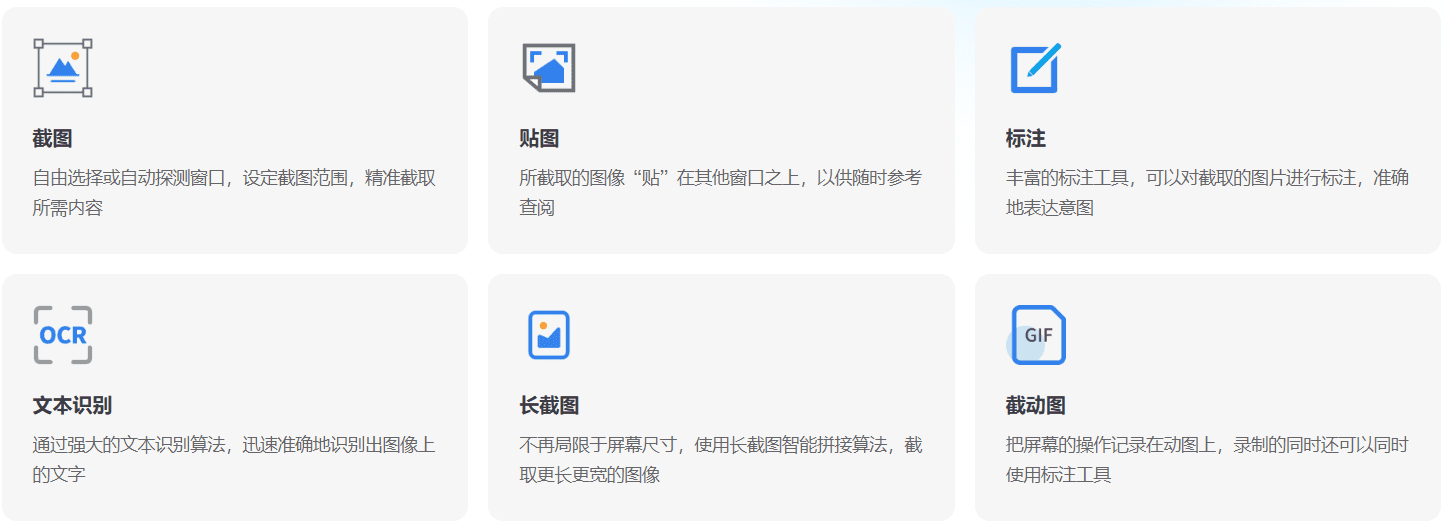
eSearch:多功能跨平台OCR工具,集成搜索|翻译|搜图|录屏等功能综合介绍 eSearch 是一款由 xushengfeng 开发的开源跨平台截图工具,支持 Windows、macOS 和 Linux 系统。它集成了多种功能,包括截图、OCR 识别、搜索、翻译、贴图...最新AI资源# OCR2年前059.5K
Surya:专业多语言文档OCR工具,开源本地部署综合介绍 Surya是一个开源的多语言文档OCR工具包,支持90多种语言的文本识别。它不仅能够进行逐行文本检测,还能进行布局分析、阅读顺序检测和表格识别。Surya的性能与云服务相媲美,适用于各种类型...最新AI资源# AI开源项目# OCR2年前0121.3K
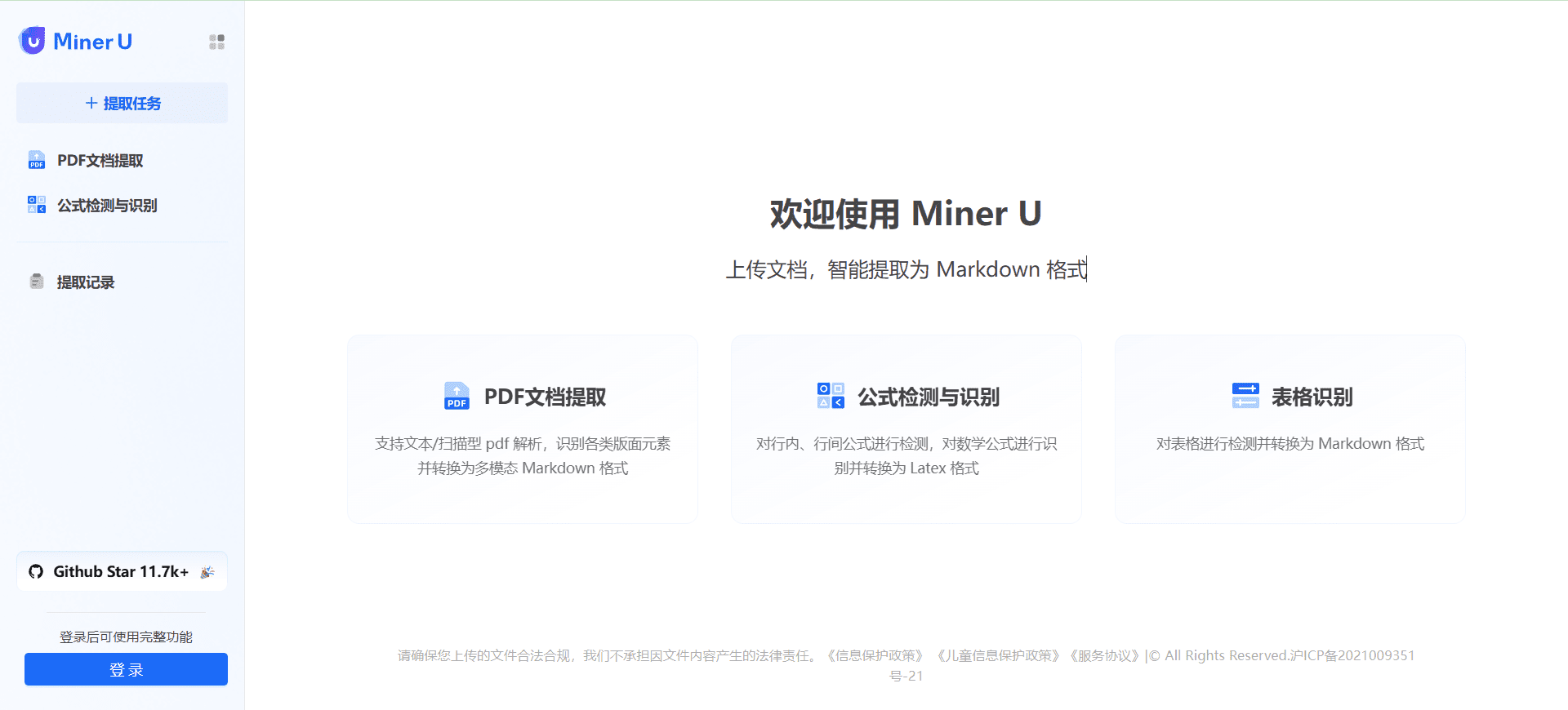
MinerU:PDF文档提取转换为多模态Markdown格式,支持电子书OCR扫描综合介绍 MinerU是由上海人工智能实验室OpenDataLab团队开发的一款开源数据提取工具,专注于从复杂的PDF文档、网页和电子书中高效提取内容。它能够将包含图片、公式、表格等元素的多模态PDF...最新AI资源# AI开源项目# OCR# 文档提取与清洗2年前0142K
PixPin:长截图和动态截图,内置本地文字识别(OCR)综合介绍 PixPin是一款功能强大的截图和贴图工具,旨在提升用户的工作效率。无论是日常办公还是专业需求,PixPin都能提供便捷的截图、贴图、长截图、文字识别(OCR)和动态截图功能。其简洁的界面和...最新AI资源# OCR2年前0112.8K
GOT-OCR2.0:基于 QWen2 0.5B 端到端的多模态OCR模型综合介绍 GOT-OCR2.0是一个阶跃星辰联合推出de 开源光学字符识别(OCR)模型,旨在通过一个统一的端到端模型推动OCR技术向OCR-2.0迈进。该模型支持多种OCR任务,包括普通文本识别、格...最新AI资源# AI开源项目# OCR2年前066.4K
PaddleOCR:基于飞桨的多语言OCR工具库,支持80多种语言识别综合介绍 PaddleOCR 是一个基于 PaddlePaddle 的多语言 OCR 工具包,旨在提供实用且超轻量级的 OCR 系统。它支持超过 80 种语言的识别,并提供数据标注和合成工具,支持在服...最新AI资源# AI开源项目# OCR1年前088.4K
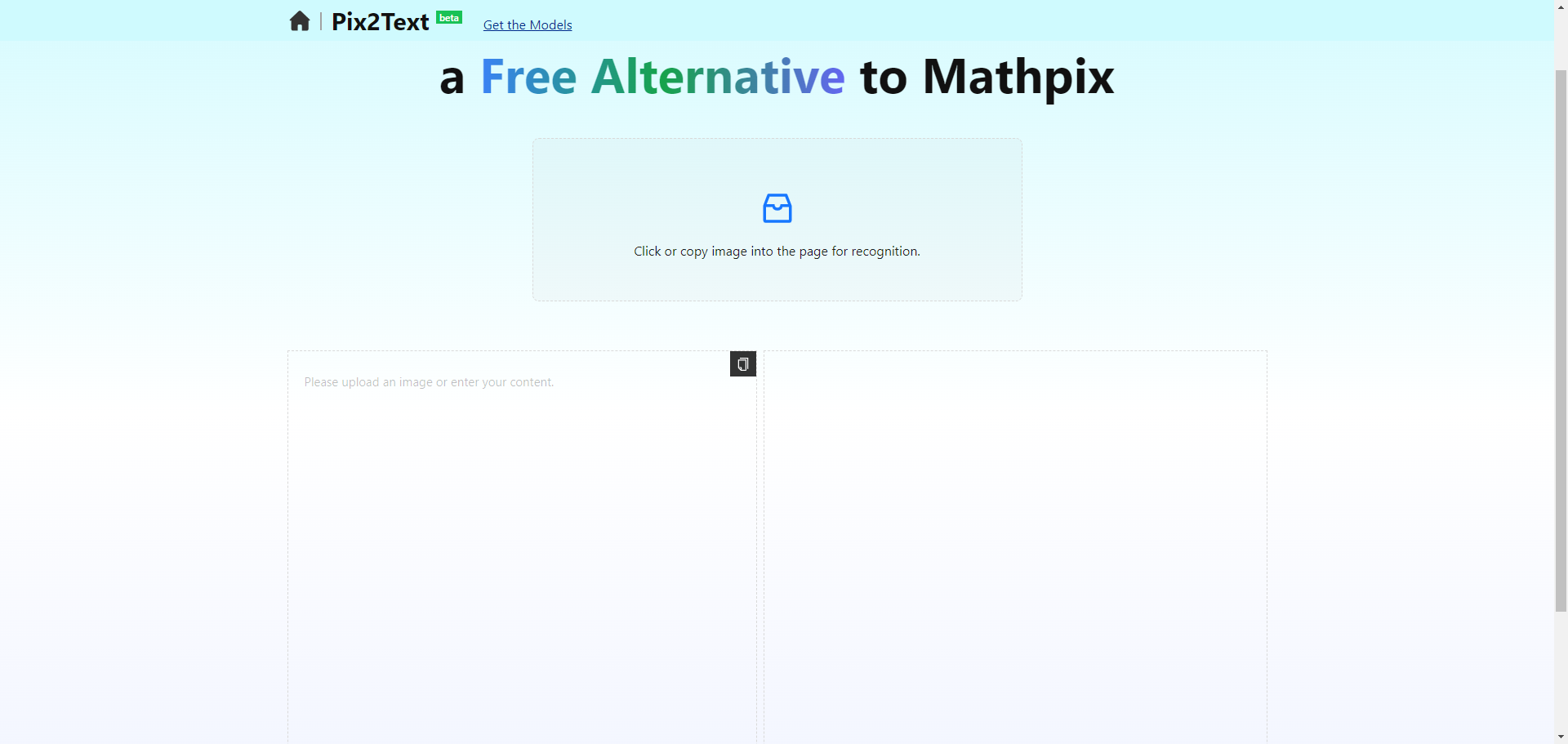
Pix2Text:开源免费图片文字识别工具Pix2Text 综合介绍 Pix2Text (P2T) 是一个开源的免费工具,旨在替代 Mathpix,提供图片文字和数学公式识别功能。用户可以通过网页版免费使用该工具,每天最多识别 10000 个...最新AI资源# OCR2年前072.1K
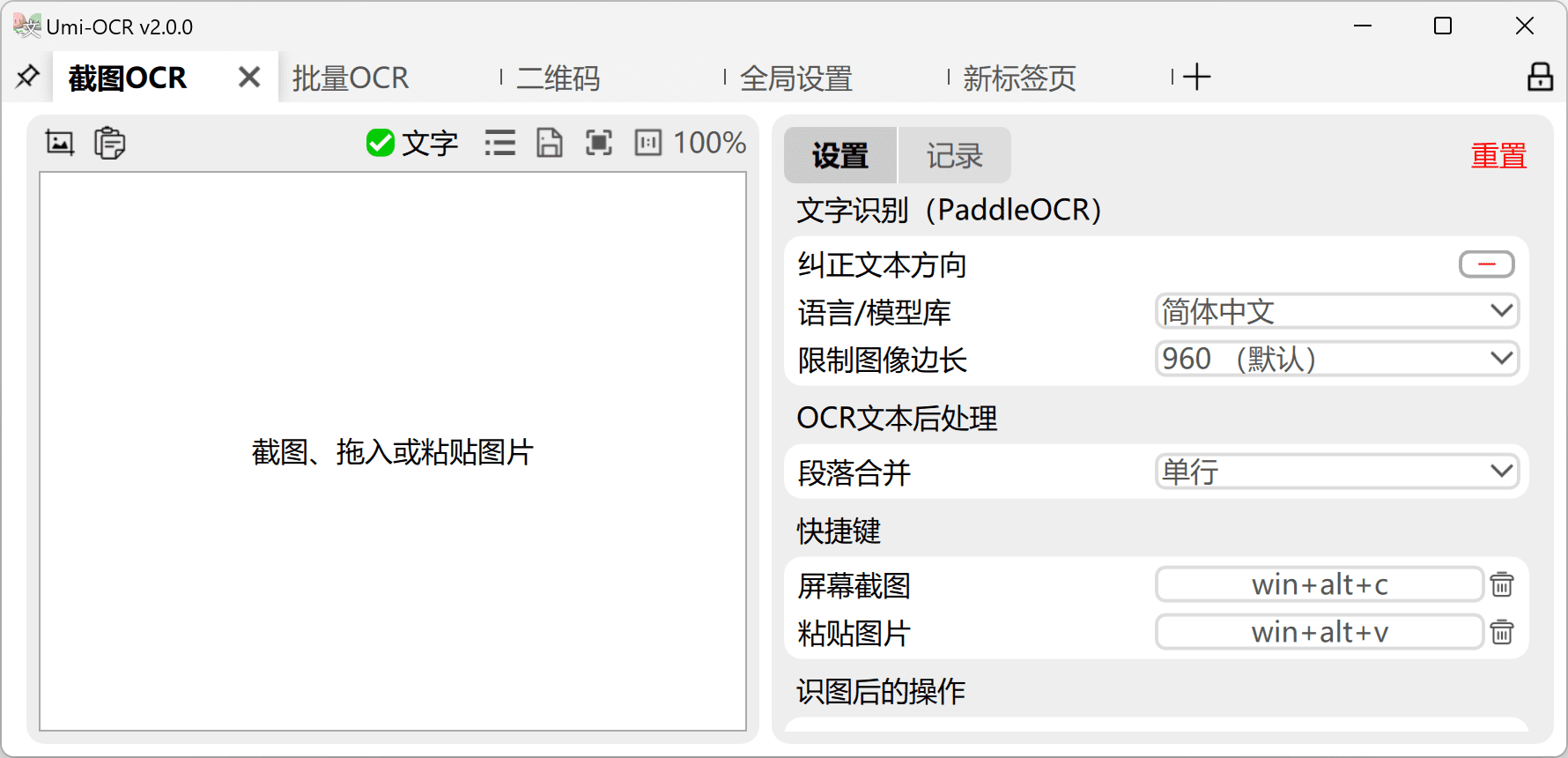
Umi-OCR:开源离线OCR软件,批量图片识别和PDF识别Umi-OCR 综合介绍 Umi-OCR是一款开源、免费的离线OCR软件,支持截屏、批量导入图片、PDF文档识别、排除水印和页眉页脚、扫描和生成二维码。该软件内置多国语言库,适用于Windows和Li...最新AI资源# OCR2年前0104.1K
TTime:图片你文字识别和文字翻译软件TTime 综合介绍 TTime 是由 InkTimeRecord 发布在 GitHub 上的项目,是一款简洁高效的翻译软件。它主要提供输入、截图、划词及悬浮球翻译等功能,支持多种翻译源和文字识别服务...最新AI资源# AI翻译# OCR2年前054.9K