

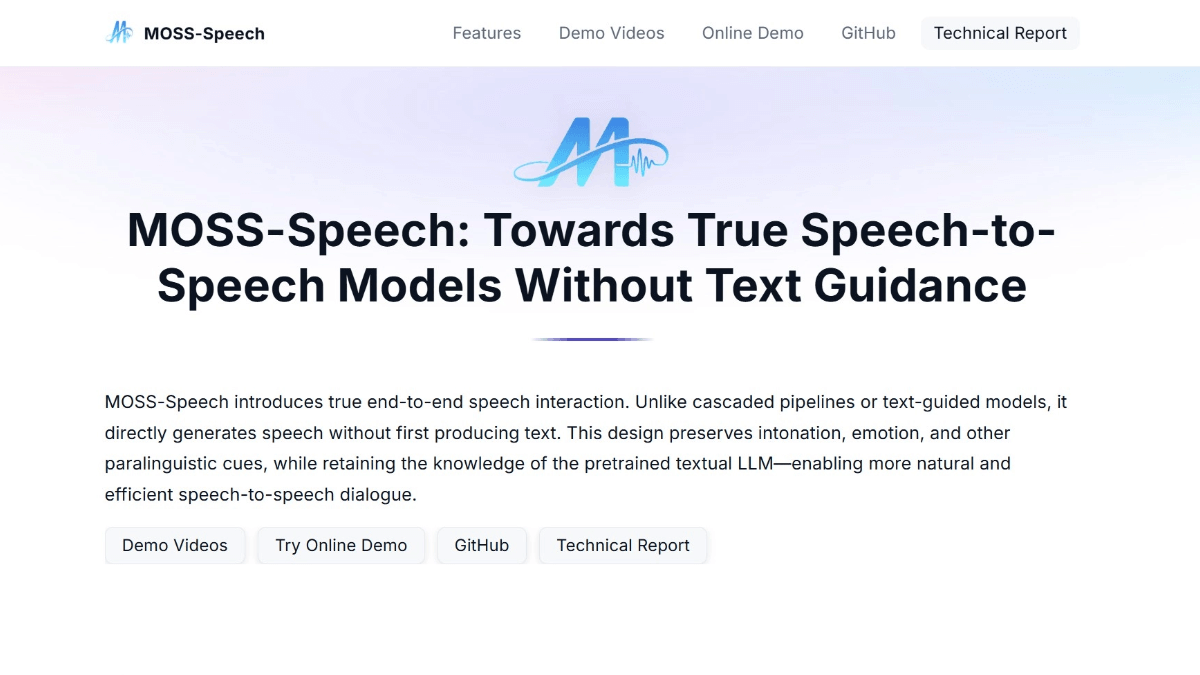
MOSS-Speechs是什么
MOSS-Speech是复旦大学邱锡鹏教授团队开源的语音到语音(Speech-to-Speech)大模型。突破传统语音处理方式,无需文本引导,直接对语音进行理解和生成,能捕捉语调、情绪等非文字要素,使语音交互更自然。模型基于预训练文本LLM设计,通过模态分层和两阶段预训练,融合语音理解与生成能力,同时支持语音和文本输入输出,实现跨模态交互。MOSS-Speech采用先进的语音编码技术,让模型在压缩语音的同时理解其含义。冻结预训练策略在保留原LLM能力的基础上,引入语音处理能力。
MOSS-Speechs的功能特色
- 语音到语音直接交互:无需文本转换,直接处理语音输入并生成语音输出,支持自然流畅的语音对话。
- 语音理解与生成:能理解语音中的语义、语调和情绪,并生成带有情感和语调的语音,使交流更加生动自然。
- 跨模态交互:支持语音和文本的双向交互,用户可以选择语音或文本输入,模型会以相应模态输出,满足不同场景需求。
- 多场景应用:适用于智能语音助手、语音交互设备等,为用户提供高效、自然的语音交互体验,提升设备的交互性能。
- 强大的语音建模能力:在语音建模和口语问答任务中表现优异,能够处理复杂的语音信息,提供准确的语音理解和生成结果。
MOSS-Speechs的核心优势
- 真正的语音到语音建模:直接处理语音输入和输出,无需依赖文本转换,保留了语音的自然特性和情感表达。
- 双模态原生支持:同时支持语音和文本交互,用户可以根据需求选择输入和输出方式,实现灵活的跨模态交流。
- 先进的语音编码技术:通过特殊的编码系统,既能理解语音的含义,又能保留其声学特征,提升语音交互的准确性和自然度。
- 冻结预训练策略:在保留文本LLM的强大推理能力和知识储备的同时,引入语音理解和生成能力,实现高效的知识迁移和模态融合。
- 卓越的性能表现:在语音建模和口语问答任务中取得领先结果,证明了其在语音理解和生成方面的强大能力。
- 丰富的应用场景:适用于智能语音助手、语音交互设备等,为用户提供更自然、高效的语音交互体验,满足多种实际应用需求。
MOSS-Speechs官网是什么
- 项目官网:https://moss-speech.open-moss.com/
- Github仓库:https://github.com/OpenMOSS/MOSS-Speech
- HuggingFace模型库:https://huggingface.co/collections/OpenMOSS-Team/moss-speech
- arXiv技术论文:https://arxiv.org/pdf/2510.00499
- 在线体验Demo:https://huggingface.co/spaces/OpenMOSS-Team/MOSS-Speech
MOSS-Speechs的适用人群
- 智能设备制造商:可集成MOSS-Speech到智能音箱、智能车载系统等设备中,提升产品的语音交互体验。
- 软件开发者:能利用其API或开源代码开发语音交互应用,如语音助手、语音客服等。
- 人工智能研究者:可用于研究语音识别、语音合成和多模态交互等领域的前沿技术。
- 企业客户:适用于需要高效语音交互解决方案的企业,如客服中心、智能家居等领域。
- 普通用户:可直接使用基于MOSS-Speech开发的语音助手或设备,享受更自然、便捷的语音交互服务。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...