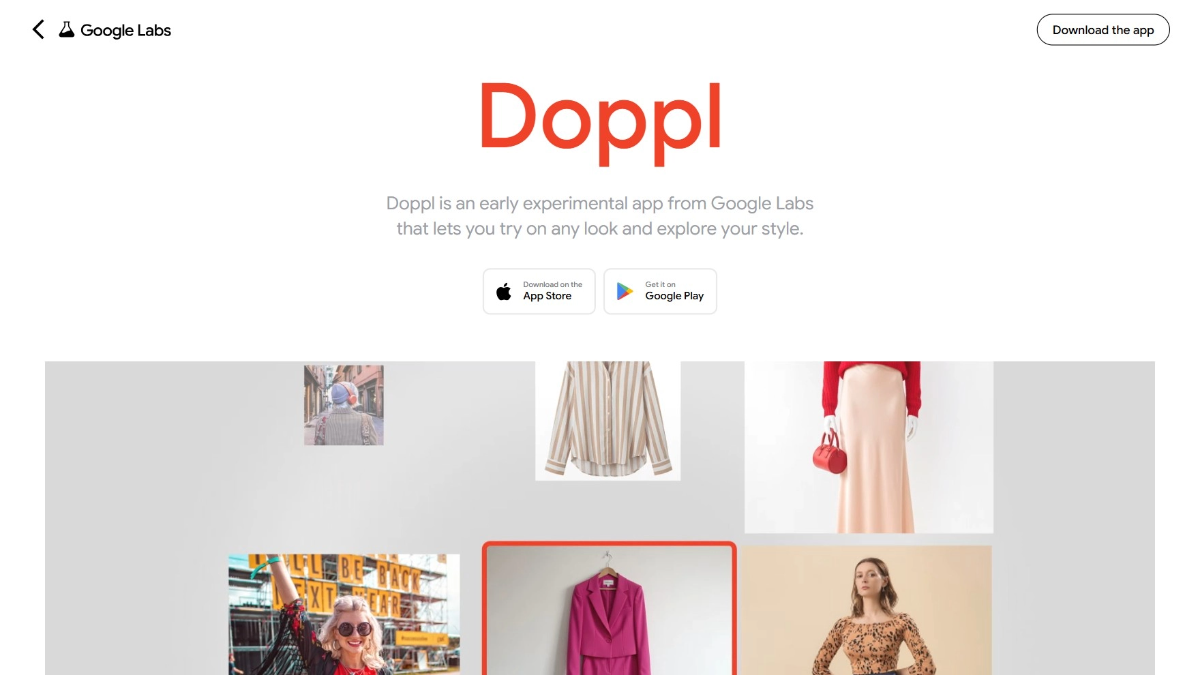
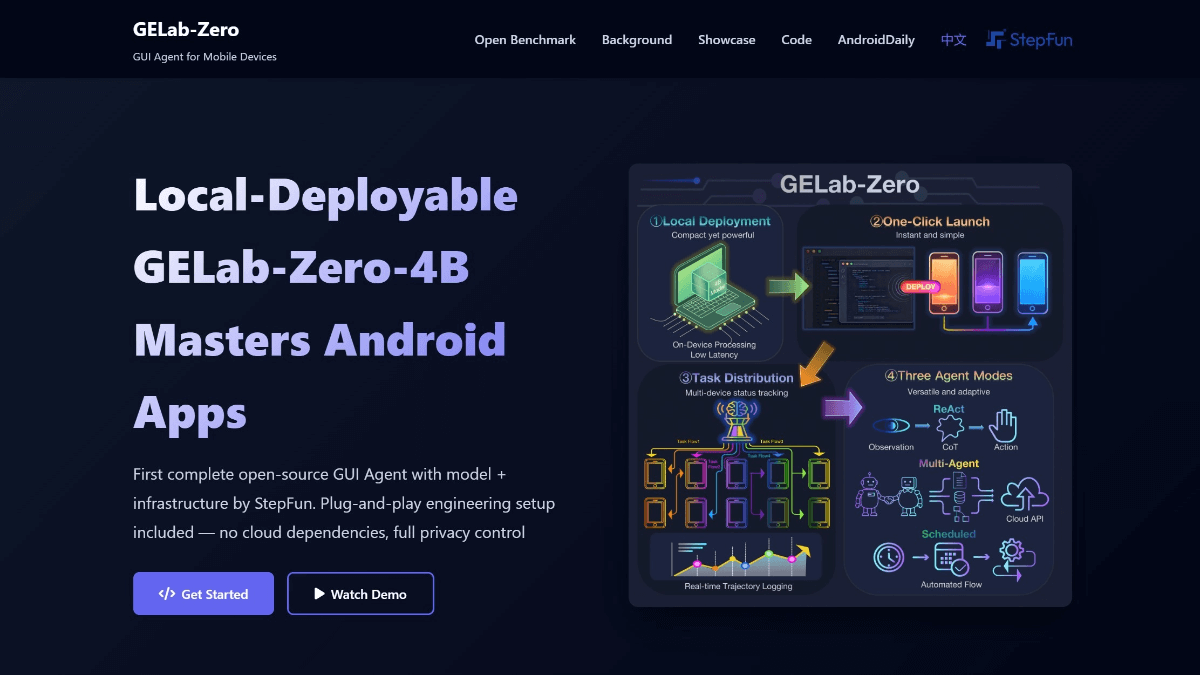
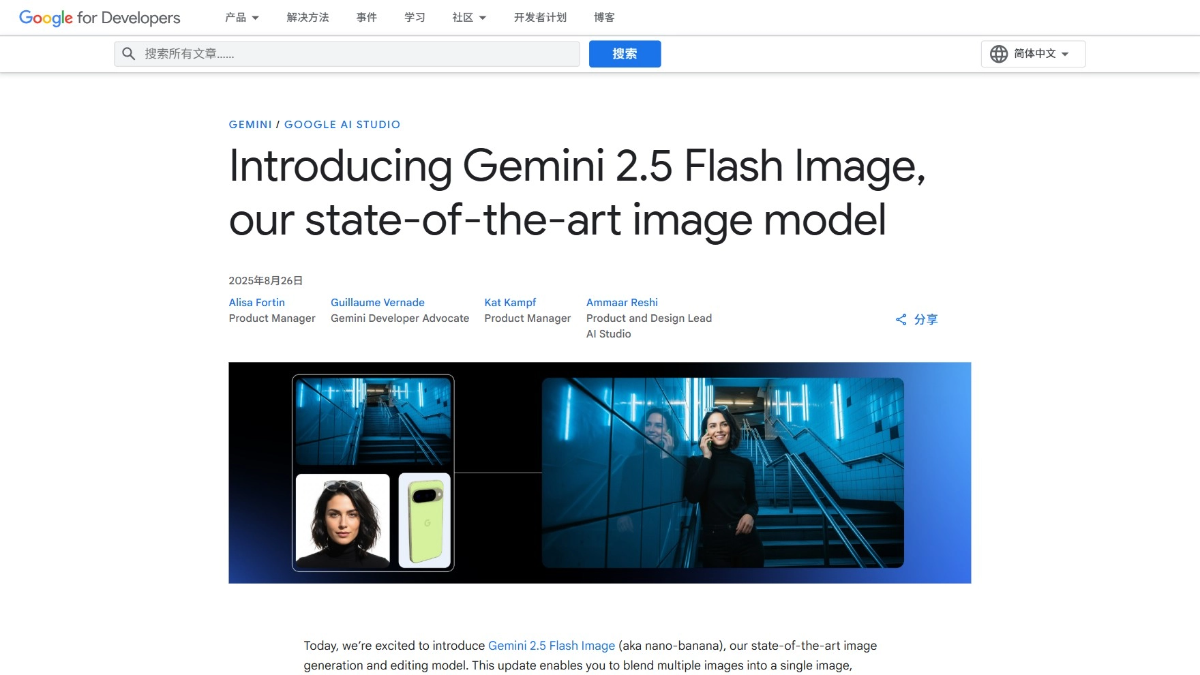
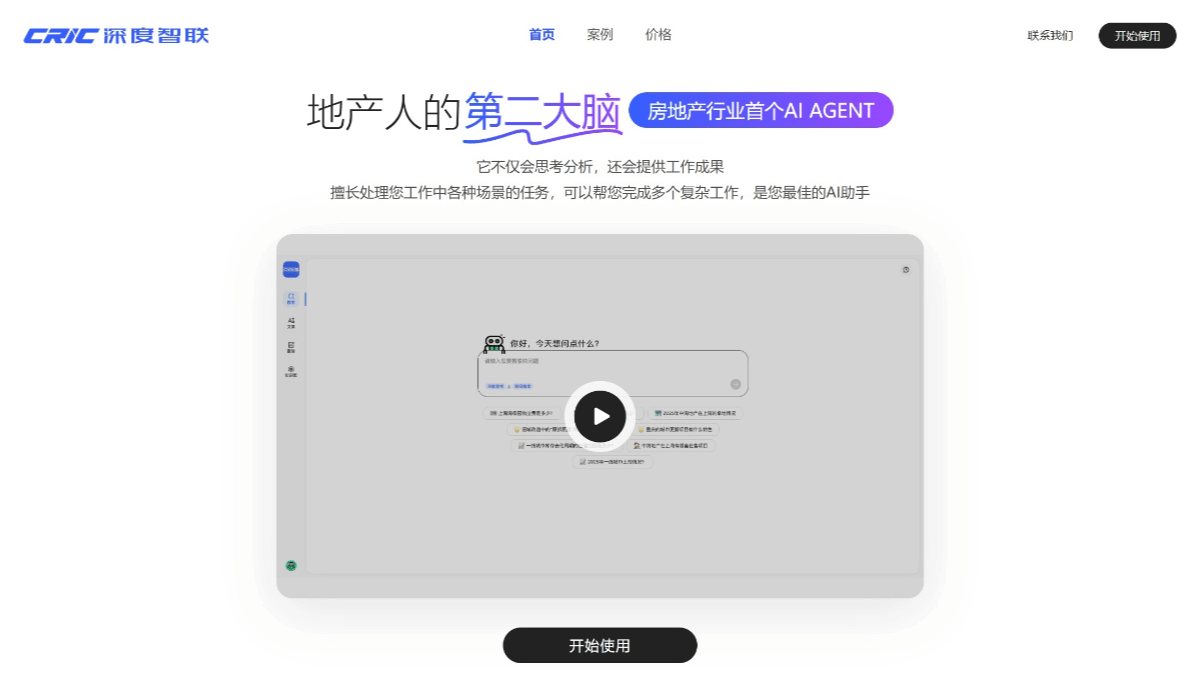
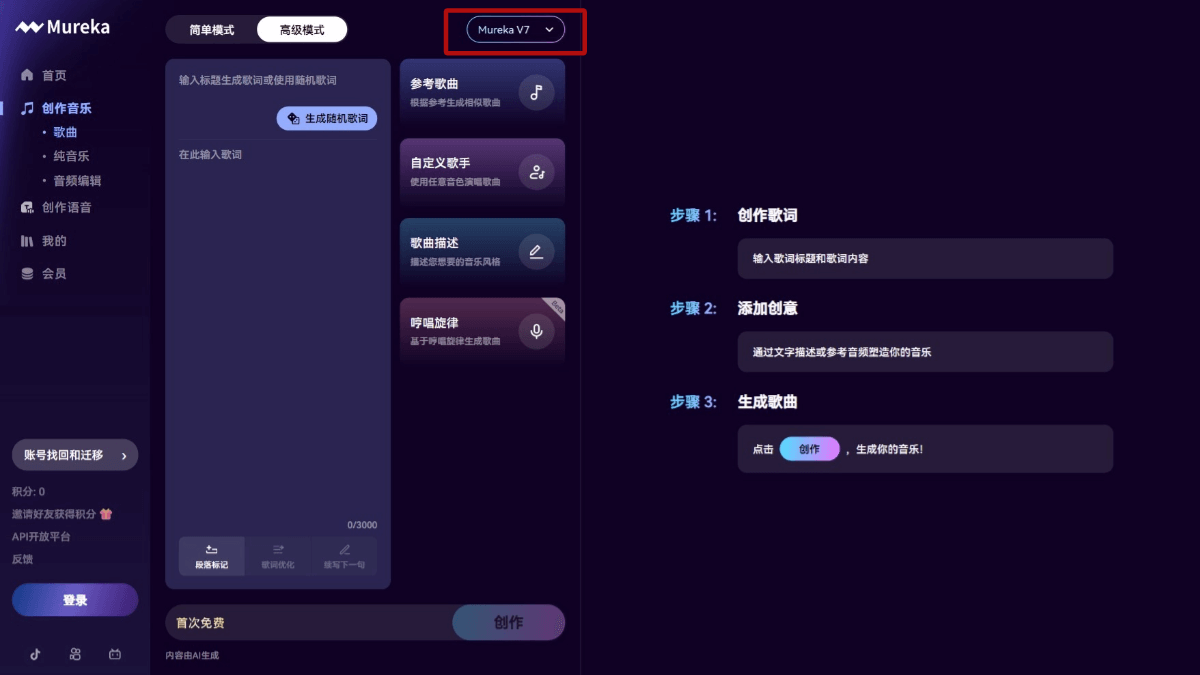
도플은 구글의 AI 가상 피팅 앱입니다. 사용자가 전신 사진을 업로드하면 애플리케이션은 자신의 신체 디지털 버전에 옷 사진이나 스크린샷을 '착용'하고, 정적인 사진에서 AI가 생성한 동영상으로 변환하여 사용자가 옷이 신체에 미치는 효과를 더욱 실감나게 느낄 수 있도록 지원합니다.
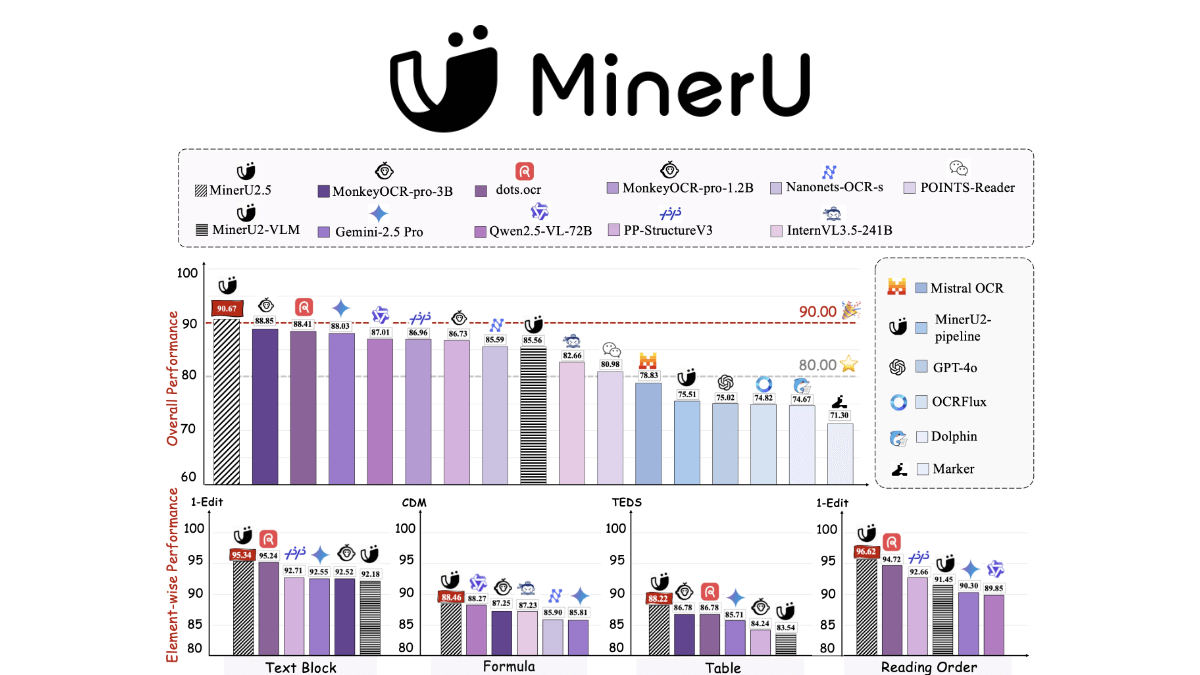
MinerU2.5는 상하이 인공지능 연구소와 북경대학교 팀이 공동으로 개발한 분리형 시각 언어 모델로, 고해상도 문서 이미지 구문을 효율적으로 처리하는 데 중점을 두고 있습니다. 핵심 혁신은 "글로벌 레이아웃 감지 후 로컬 콘텐츠 인식"의 2단계 설계에 있습니다. 첫 번째 단계는 저해상도...
스텝오디오 2 미니는 스텝오디오의 오픈 소스 엔드투엔드 음성 매크로 모델입니다. 기존의 음성 모델 구조를 깨고 진정한 엔드투엔드 멀티모달 아키텍처를 채택하여 원시 오디오 입력을 짧은 지연 시간으로 음성 응답 출력으로 직접 변환하고 언어학적 정보 및 비음성 신호를 이해합니다.
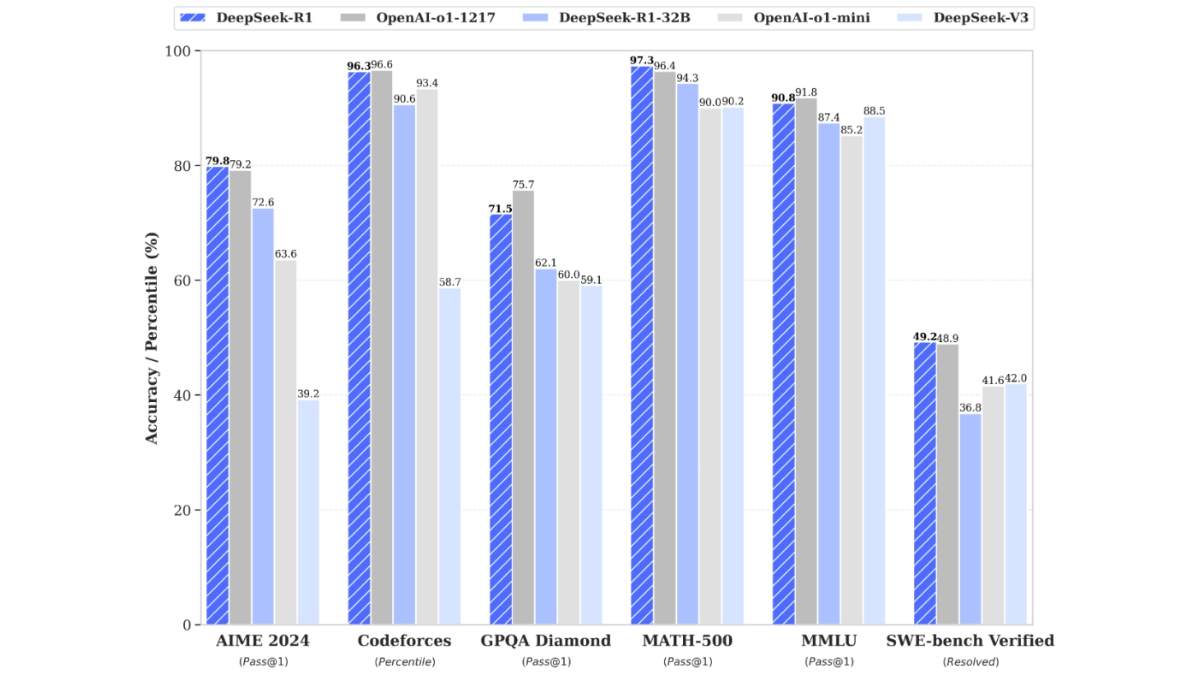
DeepSeek-R1은 항저우에 본사를 둔 DeepSeek에서 출시한 고성능 AI 추론 모델로, OpenAI의 o1 공식 버전을 벤치마킹했습니다. 이 모델은 대규모 강화 학습 기법을 기반으로 사후 학습되며 수학, 코드 및 자연어로 추론하는 데 매우 적은 양의 레이블 데이터만 필요합니다.
텐센트 하이브리드 오픈 소스 번역 모델 버전 1.5는 1.8B와 7B 두 가지 모델을 포함하여 33 개 국제 언어와 5 가지 중국어 및 중국어 / 방언 번역을 지원하는 텐센트 하이브리드 오픈 소스 번역 모델 버전 1.5입니다.1.8B 모델은 휴대 전화 및 기타 소비자 등급 장치에 특별히 최적화되어 있으며 1GB의 RAM 만 얻을 수 있습니다.
Ovis-U1은 알리바바 그룹의 Ovis 팀이 30억 개의 매개변수 규모로 도입한 멀티모달 통합 모델입니다. 이 모델은 멀티모달 이해, 텍스트-이미지 생성, 이미지 편집의 세 가지 핵심 기능을 갖추고 있으며 고급 아키텍처 설계와 협업 및 통합 교육 방법을 통해 고충실도 이미지 구현을 지원합니다.
영국에 본사를 둔 초보안 하드웨어 및 소프트웨어 회사인 SECQAI는 양자 컴퓨팅 기술을 기존 AI 모델에 통합하여 계산 효율성과 문제 해결 능력을 향상시키는 세계 최초의 양자 대용량 언어 모델(QLM)을 출시했다고 발표했습니다. 양자 역학 + AI = 더 강력한 AI?...
Klic Studio(구 Krillin AI)는 동영상 제작자와 콘텐츠 내보내기를 위해 설계된 AI 기반 동영상 번역, 더빙 및 음성 복제 도구입니다. 전체 프로세스의 원클릭 배포를 지원하여 한 번의 클릭으로 다운로드부터 완성된 출력까지 비디오를 완성할 수 있으며, Jieyin, Xiaohongshu, B ...에 맞게 조정되었습니다.
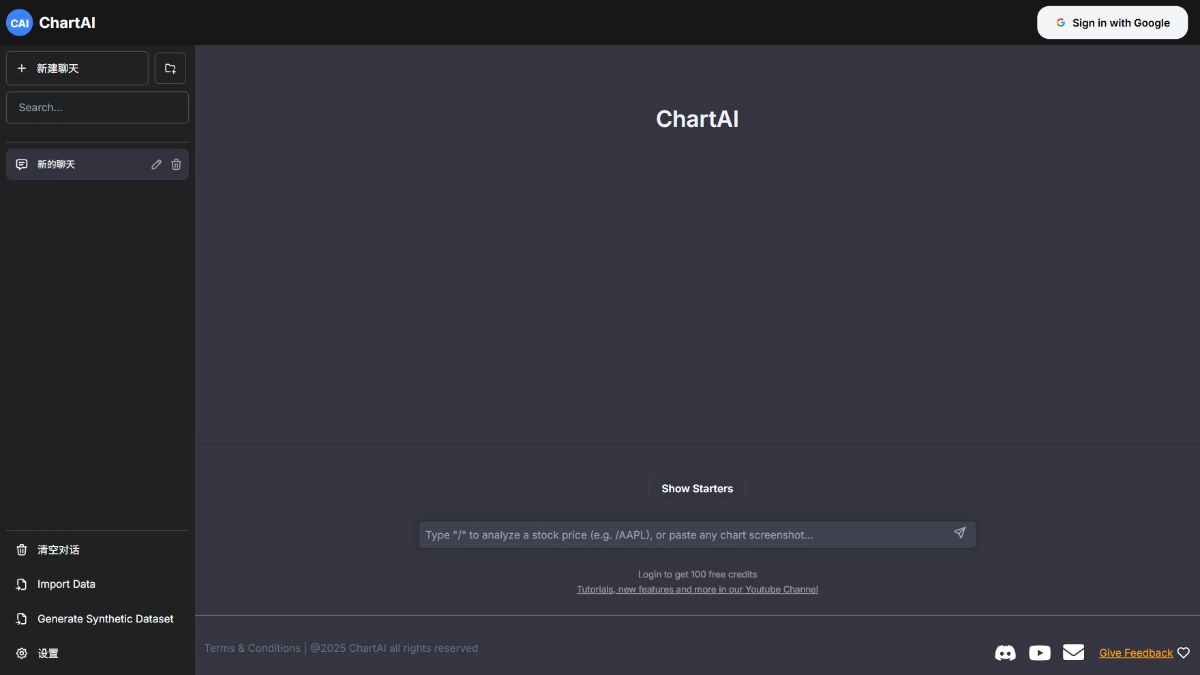
ChartAI는 AI 기술을 기반으로 데이터를 자동으로 분석하여 복잡한 정보를 빠르게 이해할 수 있는 직관적인 차트를 생성하는 효율적인 데이터 시각화 도구로, 다양한 데이터 형식(예: Excel, CSV)의 가져오기를 지원하며 가장 적합한 차트를 지능적으로 추천합니다...
AudioFly는 텍스트에서 음향 효과를 생성하기 위한 오픈 소스 AI 모델입니다. 10억 개의 파라미터가 포함된 잠재적 확산 모델 아키텍처를 기반으로 AudioSet, AudioCaps, TUT 및 내부 데이터 세트와 같은 대규모의 다양한 오디오 텍스트 데이터 세트에 대해 학습된 모델입니다.
샹탕 루잉은 샹탕 테크놀로지가 출시한 AI 디지털 휴먼 동영상 제작 플랫폼입니다. 이 플랫폼은 빅 모델 기술을 기반으로 얼굴 특징, 의상, 헤어스타일 등을 포함한 매우 사실적인 디지털 인간 이미지와 개인화 제작을 지원합니다. 이 플랫폼은 사운드 복제, 비디오 생성, 자동화된 데이터 주석, 실시간 상호 작용 및 기타 기능을 갖추고 있습니다....
Paper2Slides는 홍콩대학교 데이터 인텔리전스 연구소의 오픈 소스 AI 도구로, 클릭 한 번으로 학술 논문을 전문적인 슬라이드나 포스터로 변환해 줍니다. 네트워크 정보에 의존하지 않고 문서 내용을 직접 구문 분석하는 RAG(검색 증강 생성) 기술을 사용하여 생성된 PPT가 원본과 매우 일치하도록 보장합니다.
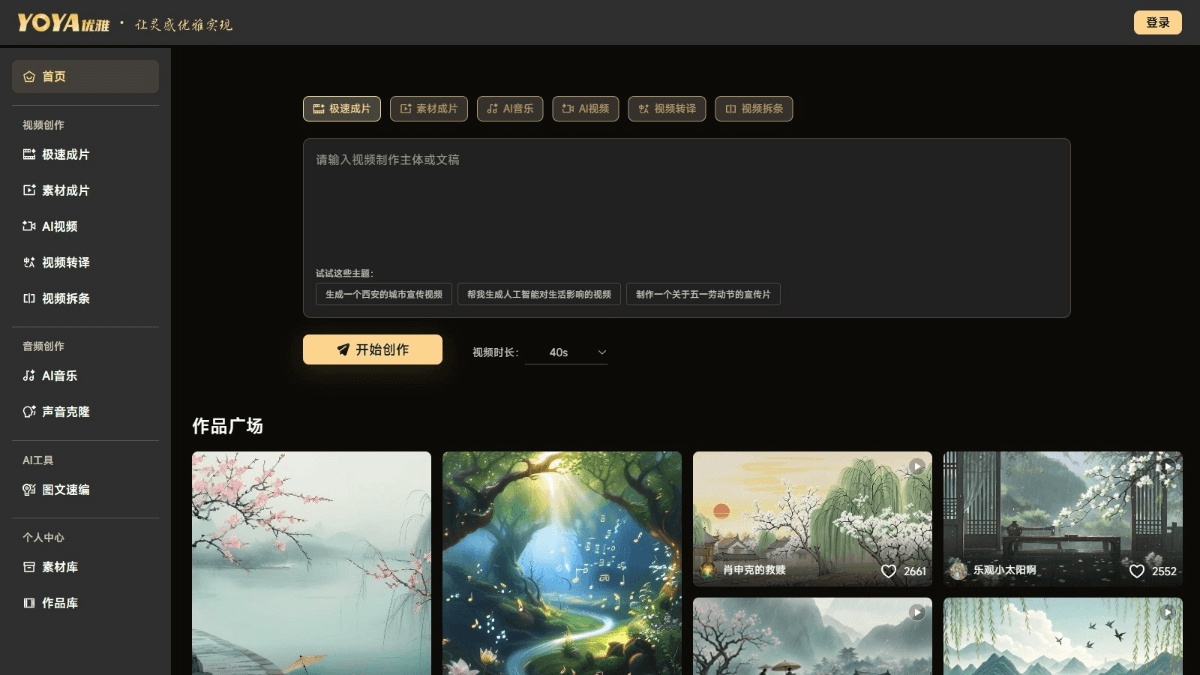
우아한 요야는 중커 웬지가 출시한 멀티모달 리터러티브 비디오 플랫폼으로, AI 멀티모달 기술을 기반으로 비디오 콘텐츠 제작의 전체 체인을 강화합니다. 사용자는 테마 요구 사항 만 입력하면 플랫폼에서 스크립트, 이미지, 비디오를 빠르게 생성 할 수 있으며 지능형 편집, 음성 합성 및 캐릭터 입 드라이브 및 기타 작업, 출력을 완료 할 수 있습니다 ...
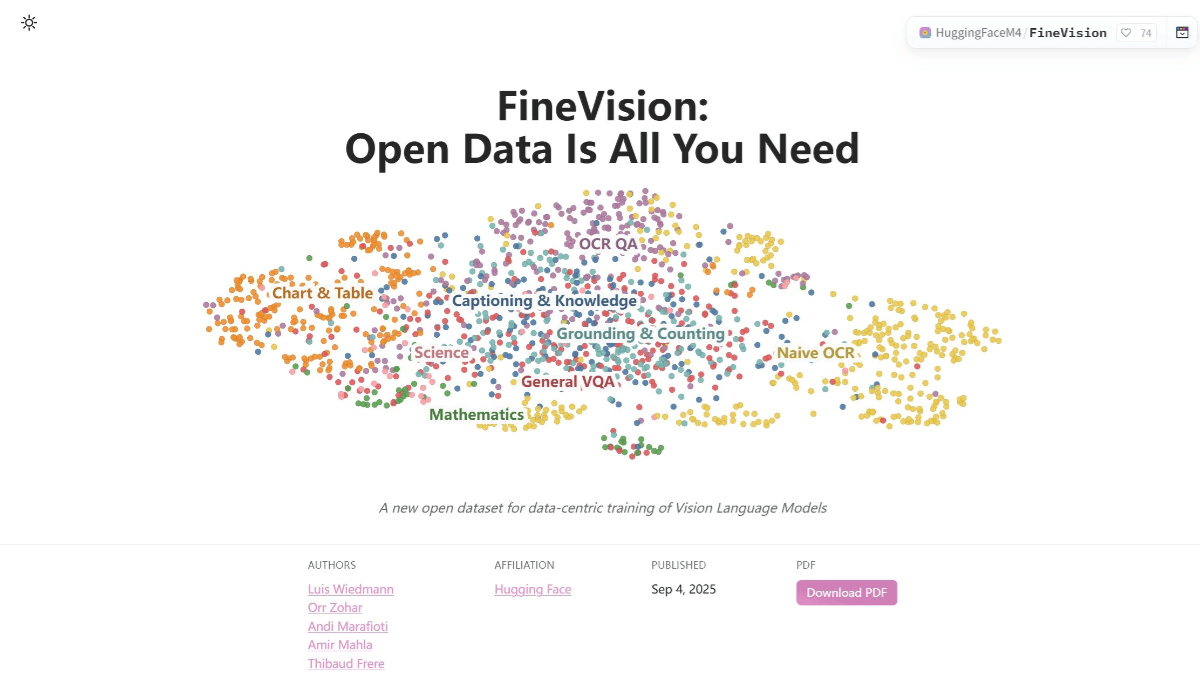
FineVision은 고급 시각 언어 모델 학습을 위한 허깅 페이스의 오픈 소스 시각 언어 데이터 세트입니다. 여기에는 1,730만 개의 이미지, 2,430만 개의 샘플, 8,890만 건의 대화, 95억 개의 답변 토큰이 포함되어 있습니다. 데이터 세트는 다음과 같이 집계됩니다...
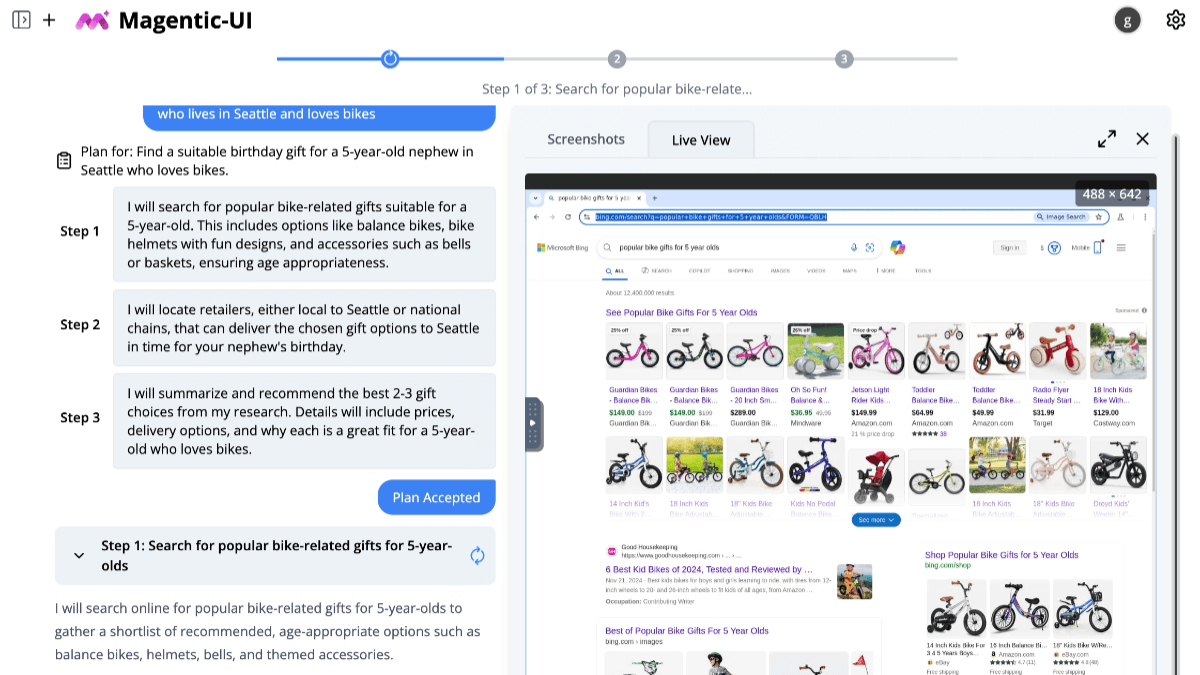
Magentic-UI는 Microsoft의 오픈 소스 인간-컴퓨터 협업 AI 에이전트 연구 도구로, 웹 탐색, 코드 실행, 파일 처리와 같은 복잡한 웹 작업을 용이하게 하기 위해 사용자와 긴밀하게 협력하는 것을 기반으로 합니다. 이 도구는 협업 계획을 강조하여 사용자가 ...
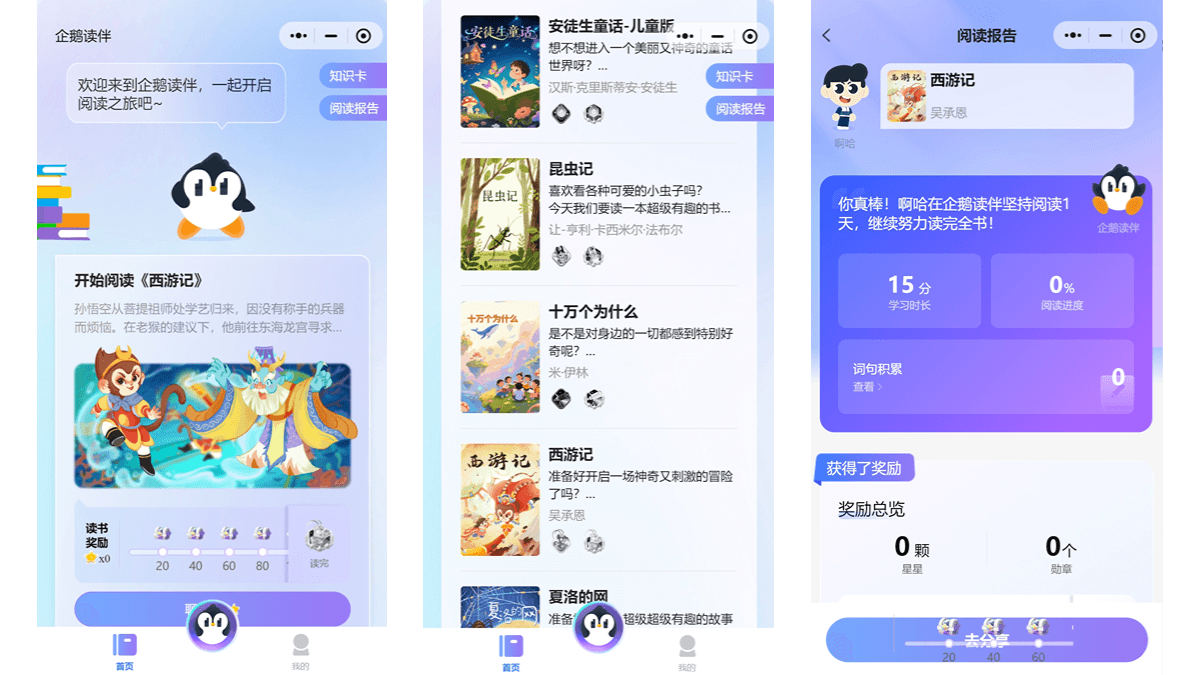
펭귄 리딩 컴패니언은 초등학생과 중고등학생을 위해 설계된 텐센트의 인공지능 독서 도우미입니다. 펭귄 리딩 컴패니언은 텐센트의 하이브리드 빅 모델과 메타머신 플랫폼을 의무 교육 언어 교과 과정 프로그램 및 교과 과정 표준(2022년판)과 결합하여 학생들에게 개인화된 독서 추천, 다양한 독서 모드(집중, 소리 내어 읽기, 듣기...)를 제공합니다.
VoxCPM 1.5는 Facade Intelligence에서 출시한 오픈 소스 음성 생성 모델로, 스플리터 없이 텍스트 음성 변환(TTS) 기술을 기반으로 몇 가지 혁신과 개선 사항을 적용했습니다. 엔드 투 엔드 확산 자동 회귀 아키텍처를 채택하여 텍스트에서 직접 연속 음성 파형을 생성하므로 기존 세분화 방법의 한계를 피할 수 있습니다....
Qwen-Image-Layered는 Ali 팀의 오픈 소스 AI 이미지 편집 모델로, 일반 이미지를 독립적인 투명 레이어로 지능적으로 분해하여 포토샵과 같은 정밀 편집을 구현합니다. 이 모델은 Apache 2.0 프로토콜을 사용하여 오픈 소스이며 유연한 레이어 제어를 지원합니다....
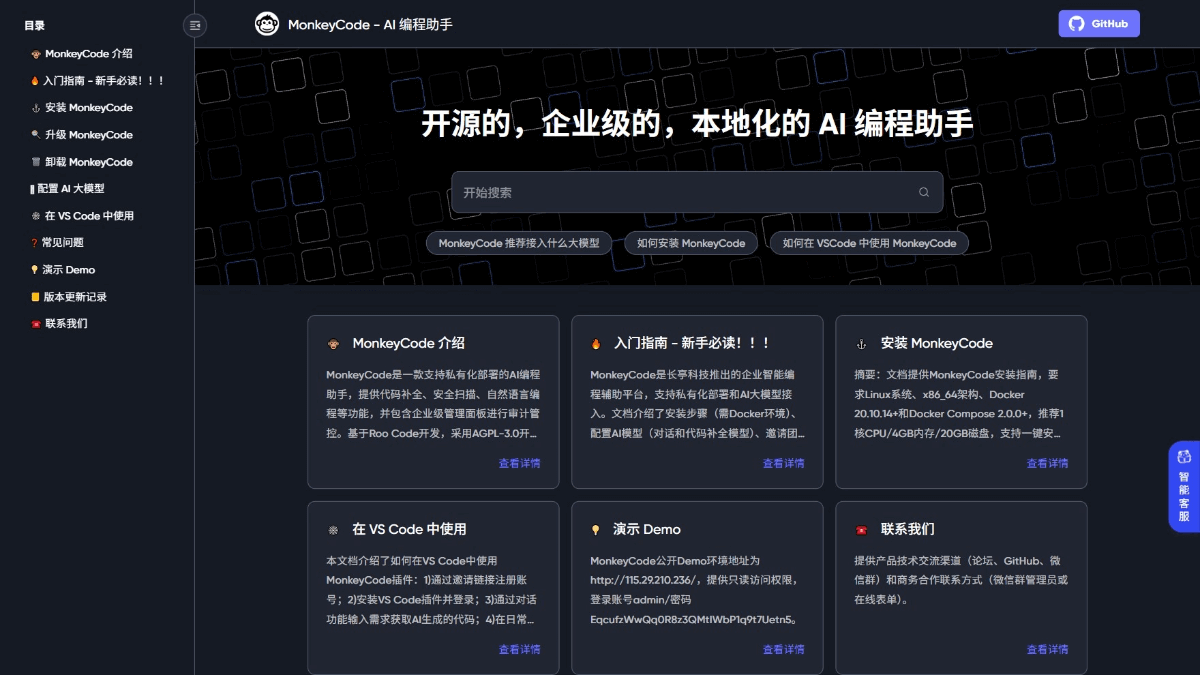
개인 정보 보호 및 보안에 민감한 개발 팀을 위해 설계된 오픈 소스 엔터프라이즈급 네이티브 AI 프로그래밍 도우미입니다.MonkeyCode는 코드 데이터 보안을 보장하기 위해 비공개 배포 및 오프라인 사용을 지원합니다. MonkeyCode는 코드 데이터의 보안을 보장하기 위해 비공개 배포 및 오프라인 사용을 지원합니다 ...
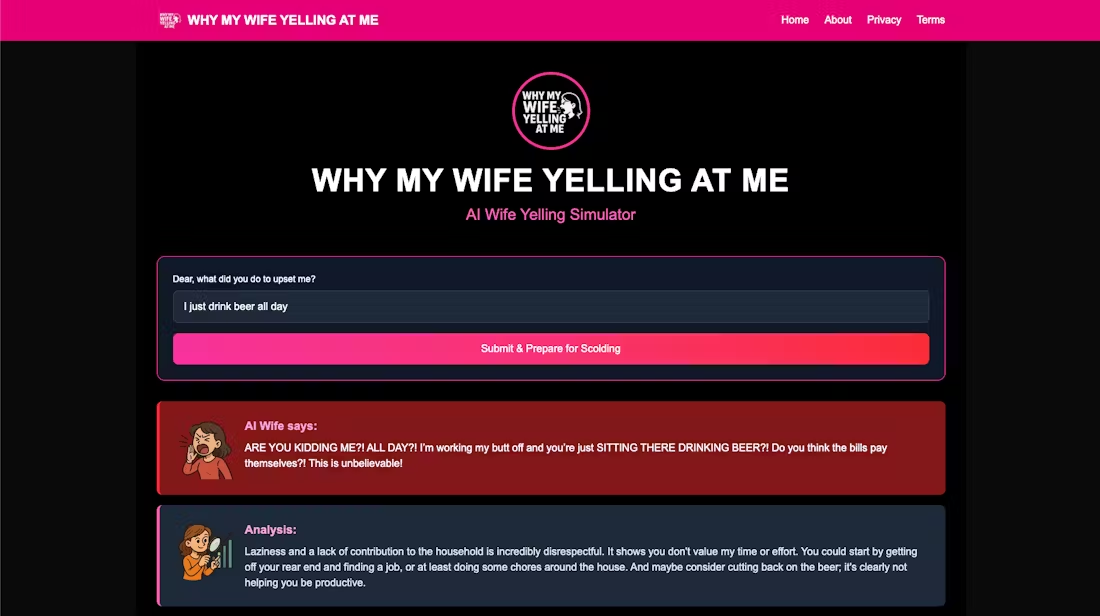
일반 소개 "아내가 나에게 소리치는 이유"는 인공지능을 통해 파트너의 감정 반응과 의사소통 패턴을 이해할 수 있도록 설계된 독특한 결혼 관계 시뮬레이션 웹사이트입니다. 사용자는 다양한 시나리오를 입력하고 가상 파트너의 반응을 경험하며 실제와 같은 시뮬레이션을 할 수 있습니다.
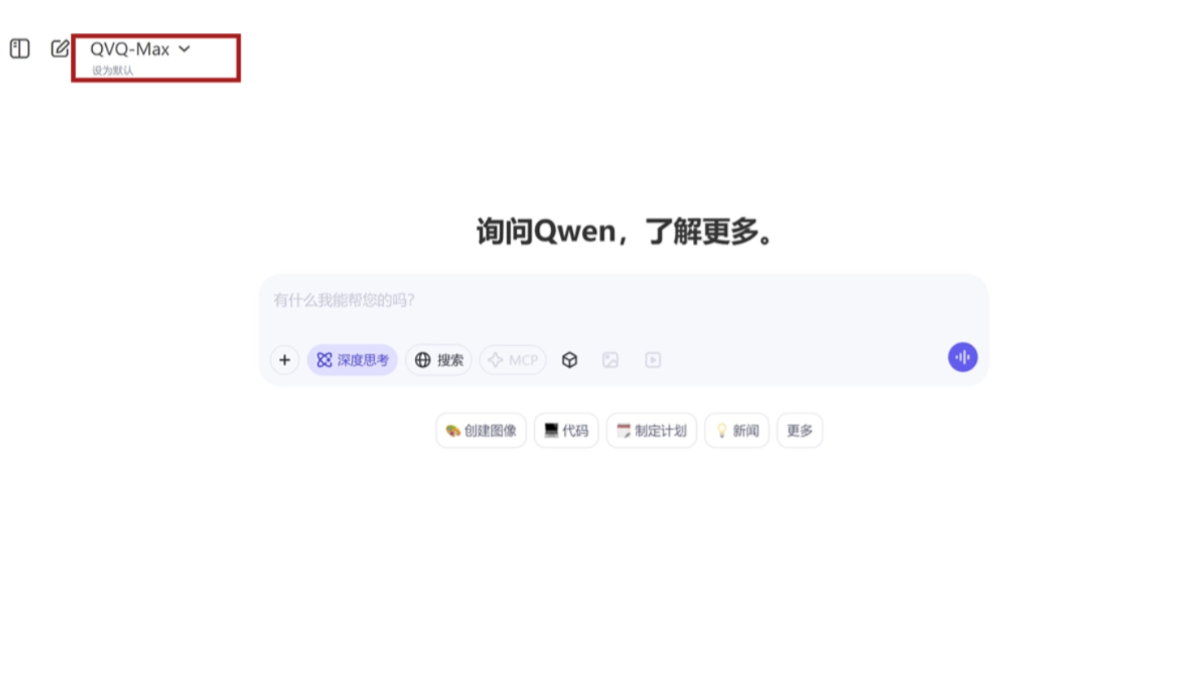
QVQ-Max는 이미지와 비디오 콘텐츠를 "읽기"하고 분석 및 문제 해결을 위한 정보와 결합할 수 있는 알리토닉스의 최첨단 시각 추론 모델로, QVQ-72B-Preview의 업그레이드 버전입니다. QVQ-Max는 이미지 및 비디오 콘텐츠를 "읽기"하고 분석, 추론 및 문제 해결을 위해 정보를 결합할 수 있는 QVQ-72B-Preview의 업그레이드 버전입니다.QVQ-Max의 주요 기능에는 이미지 구문 분석, 비디오 분석 및 ...
Lumina-DiMOO는 세계 인공지능 컨퍼런스 2025에서 화웨이 라이즈와 함께 상하이 인공 지능 연구소(AIL)가 출시한 차세대 멀티모달 생성 및 이해를 위한 통합 모델입니다. Rise AI 기본 하드웨어 및 소프트웨어 플랫폼과 MindSpeed MM 멀티모달 대형 모델 제품군을 기반으로 ...
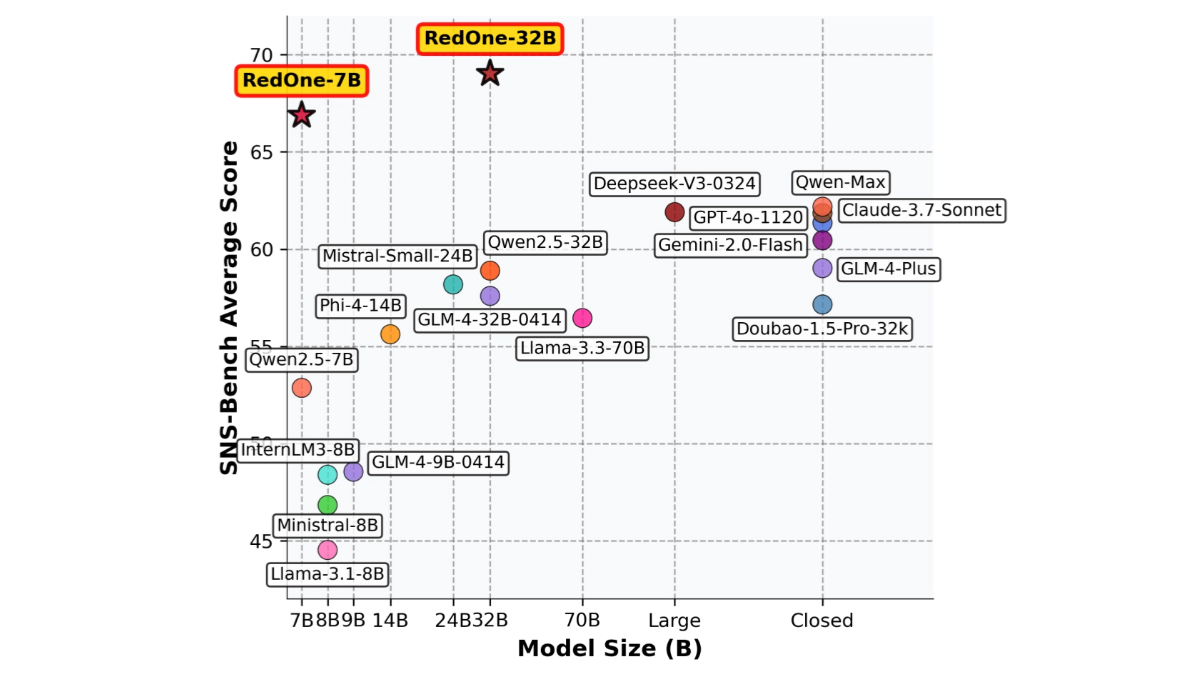
레드원은 리틀 레드북에서 도입한 소셜 네트워크에 특화된 대규모 언어 모델입니다. 이 모델은 사회 및 문화적 지식을 통합하고, 멀티태스킹 기능을 강화하며, 인간의 선호도를 조정하는 3단계 훈련 전략을 통해 훈련되며, RedOne은 소셜 작업 성능, 유해 콘텐츠 탐지 및 검색에서 기본 모델보다 훨씬 뛰어난 성능을 발휘합니다....
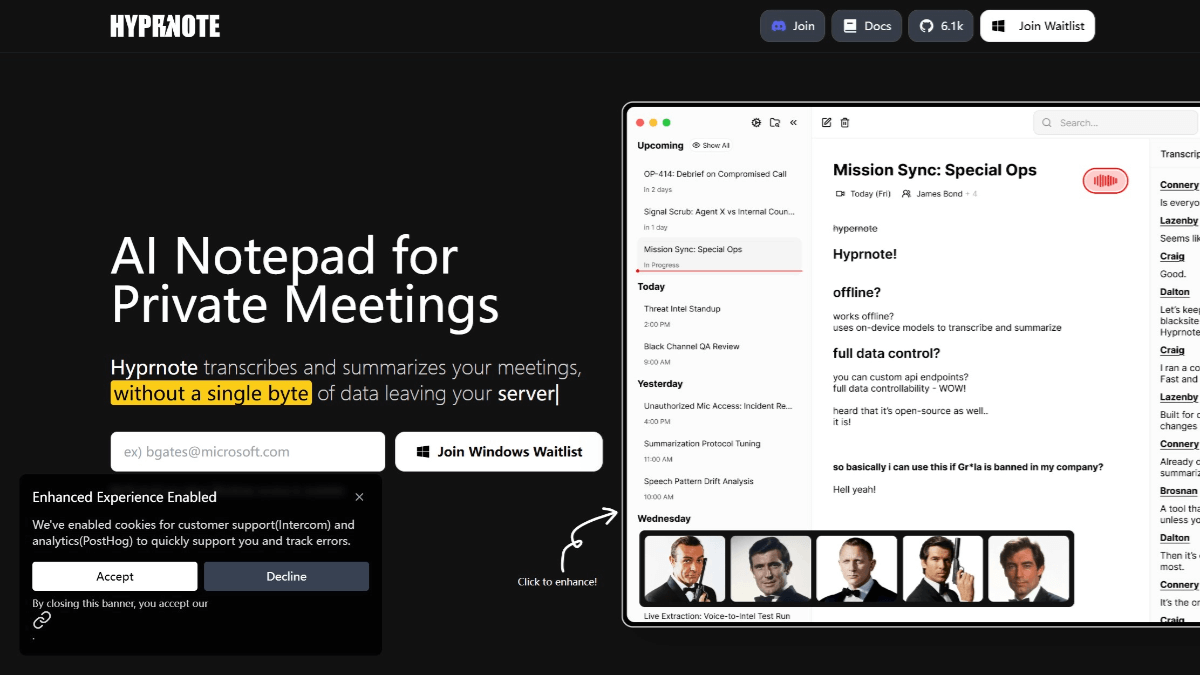
하이프노트는 사용자의 개인정보를 보호하고 회의 효율성을 개선하기 위해 전문가를 위해 설계된 로컬 우선의 오픈 소스 AI 회의 노트 필기 도구입니다. '로컬 우선' 원칙을 채택하여 모든 데이터 저장과 처리가 사용자의 로컬 장치에서 이루어지므로 데이터 보안을 보장하고 오프라인 작업을 지원합니다.
칸딘스키 5.0은 러시아 AI 팀이 개발한 최신 비디오 생성 모델 시리즈로, 가벼운 디자인과 고성능 성능에 중점을 두고 있습니다. 이 시리즈의 첫 번째 모델인 칸딘스키 5.0 비디오 라이트는 매개 변수가 20억 개에 불과하지만, 특히 유사한 14억 개에 달하는 모델을 능가합니다.
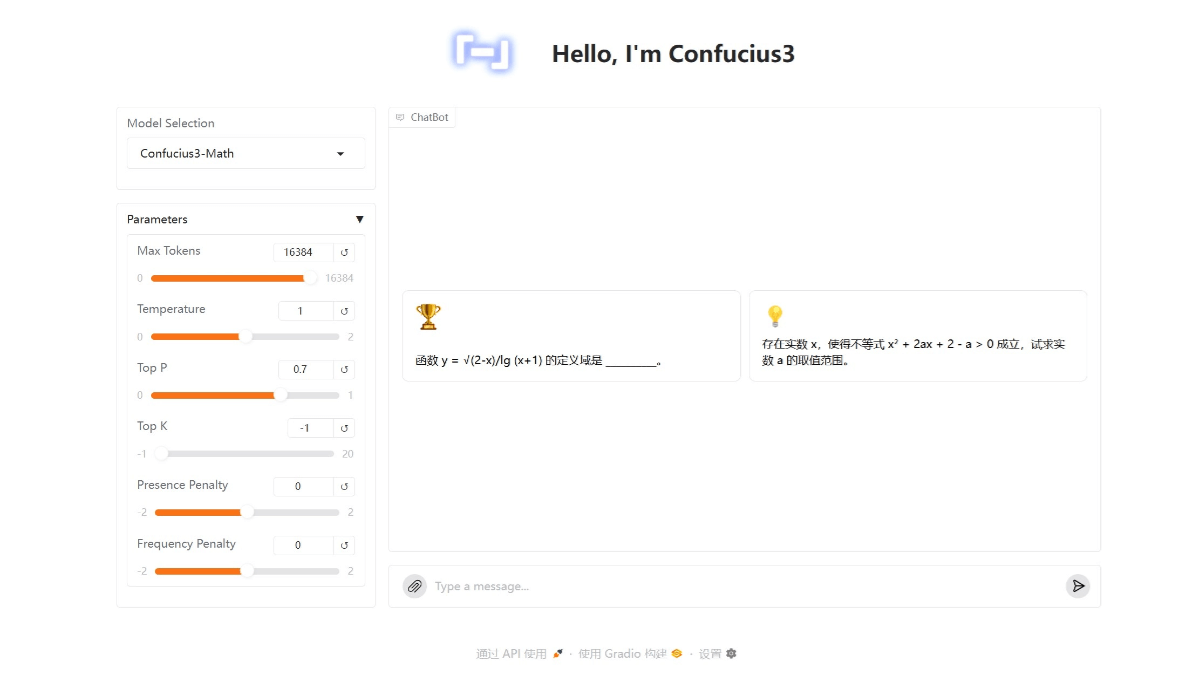
Confucius3-Math는 넷이즈유다오가 오픈소스로 공개한 국내 최초의 수학 교육용 오픈소스 추론 모델입니다. 초중고 수학 교육 시나리오에 최적화된 140억 개의 매개 변수를 사용하여 단일 소비자용 GPU(예: RTX 4090D)에서 효율적으로 실행할 수 있으며, 추론 성능은 약...
Qwen VLo는 통이 첸첸 팀이 도입한 멀티모달 통합 이해 및 생성 모델입니다. Qwen VLo는 세계를 '이해'하고 그 이해를 바탕으로 고품질로 재창조하여 인식에서 생성으로의 도약을 실현할 수 있습니다. VLo는 이미지의 내용을 정확하게 이해할 수 있으며, 이를 바탕으로 일관되고 고품질의 생성을 수행할 수 있습니다.
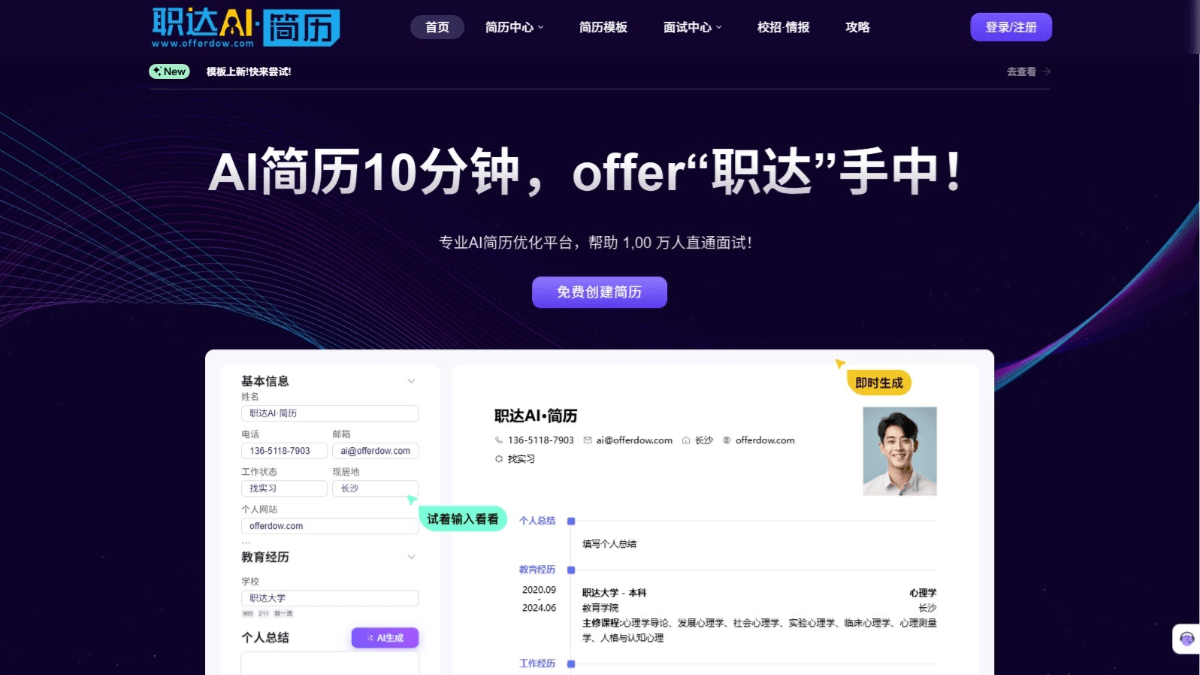
Job AI 이력서는 효율적이고 편리한 지능형 이력서 생성 및 최적화 플랫폼입니다. 이 플랫폼은 AI 기술을 기반으로 사용자가 전문적이고 개인화된 이력서를 빠르게 생성할 수 있도록 도와줍니다. 사용자는 기본 정보와 경력만 입력하면 다양한 직무를 포괄하는 2800개 이상의 아름다운 템플릿을 제공하여 단시간에 고품질의 이력서를 생성할 수 있습니다.
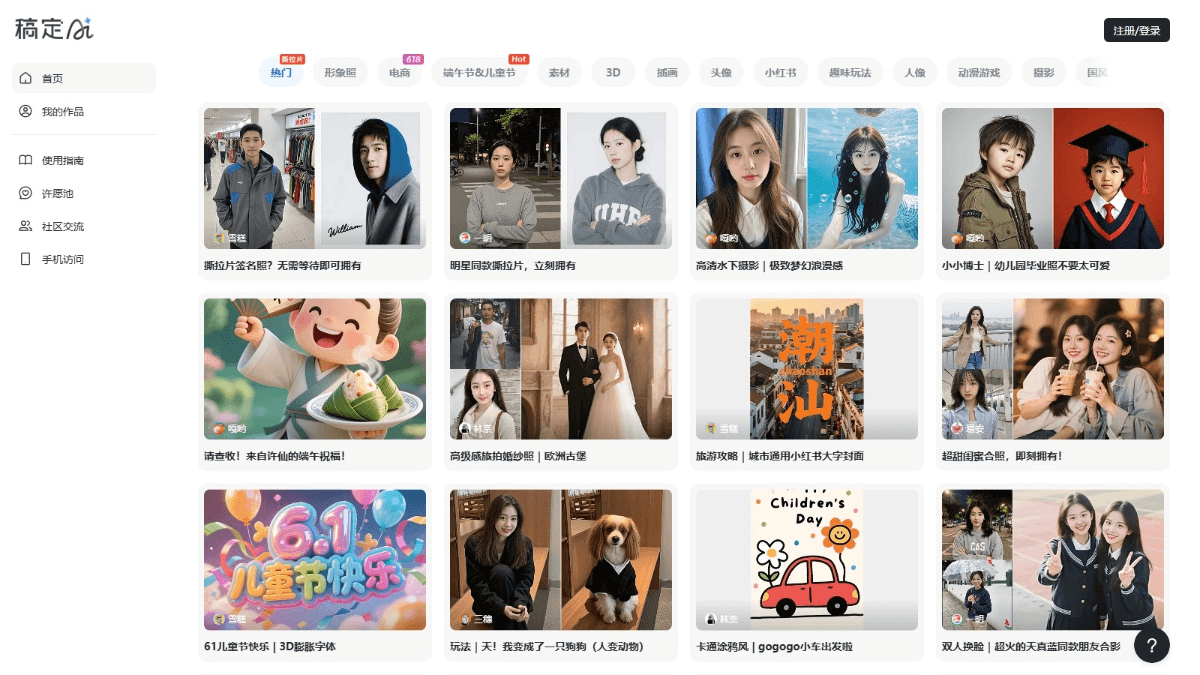
드래프팅 AI 커뮤니티는 사용자에게 풍부한 창의적인 디자인 리소스와 도구를 제공하는 온라인 AI 창작 영감 플랫폼입니다. 이 플랫폼은 이미지 사진, 전자상거래 디자인, 명절 테마, 3D 일러스트레이션, 아바타 디자인, 샤오홍슈 소재, 인물 디자인 등 다양한 디자인 분야를 다루며 다양한 사용자의 요구를 충족합니다.
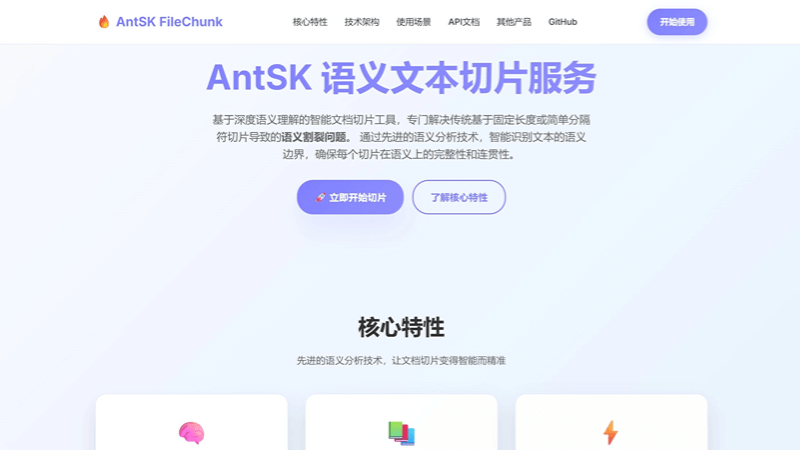
AntSK FileChunk는 RAG(검색 증강 생성) 애플리케이션을 위해 설계된 무료 지능형 문서 슬라이싱 도구입니다. 시맨틱을 핵심으로 하여 문서를 의미적으로 완전하고 일관된 세그먼트로 지능적으로 슬라이스하고, 다국어를 지원하며, 슬라이스 크기를 동적으로 조정하여 문맥의 일관성을 보장합니다.
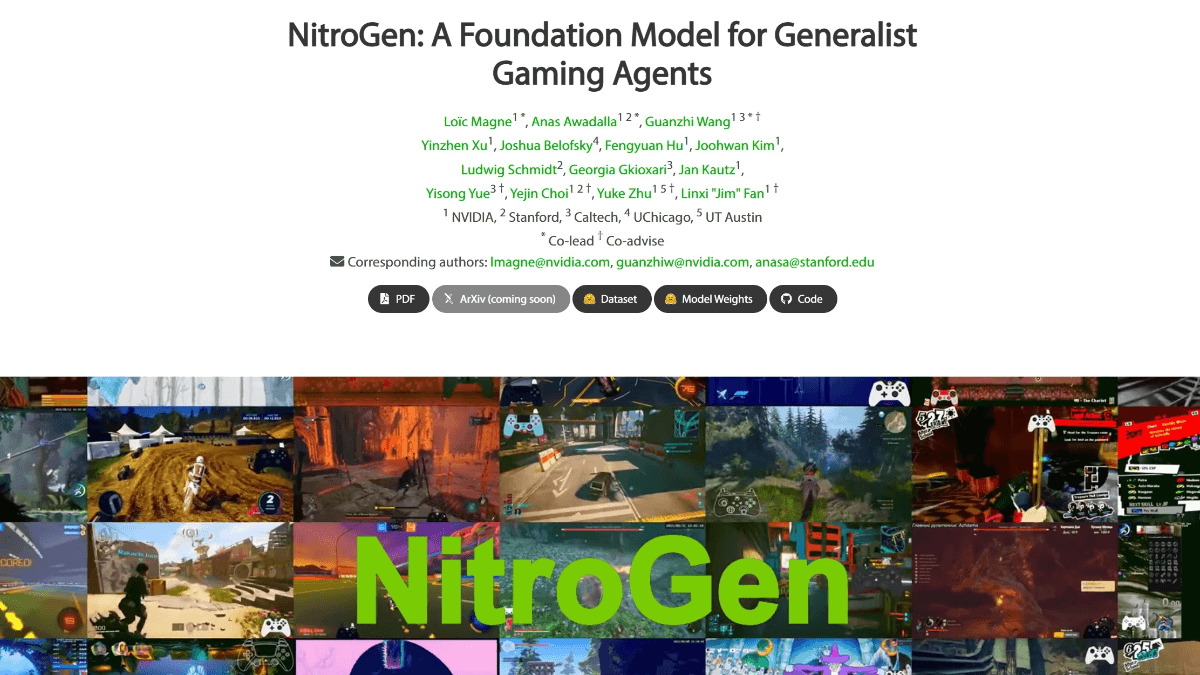
NitroGen은 NVIDIA가 스탠포드 대학, 칼텍 및 기타 기관과 함께 개발한 오픈 소스 게임 AI 모델로, 1,000개 이상의 다양한 유형의 게임을 플레이할 수 있습니다. 이 모델은 GROOT N1.5 아키텍처를 기반으로 하며, 40,000시간의 게임 비디오 데이터(조이스틱 조작 주석 포함)를 분석하여 완성되었습니다....
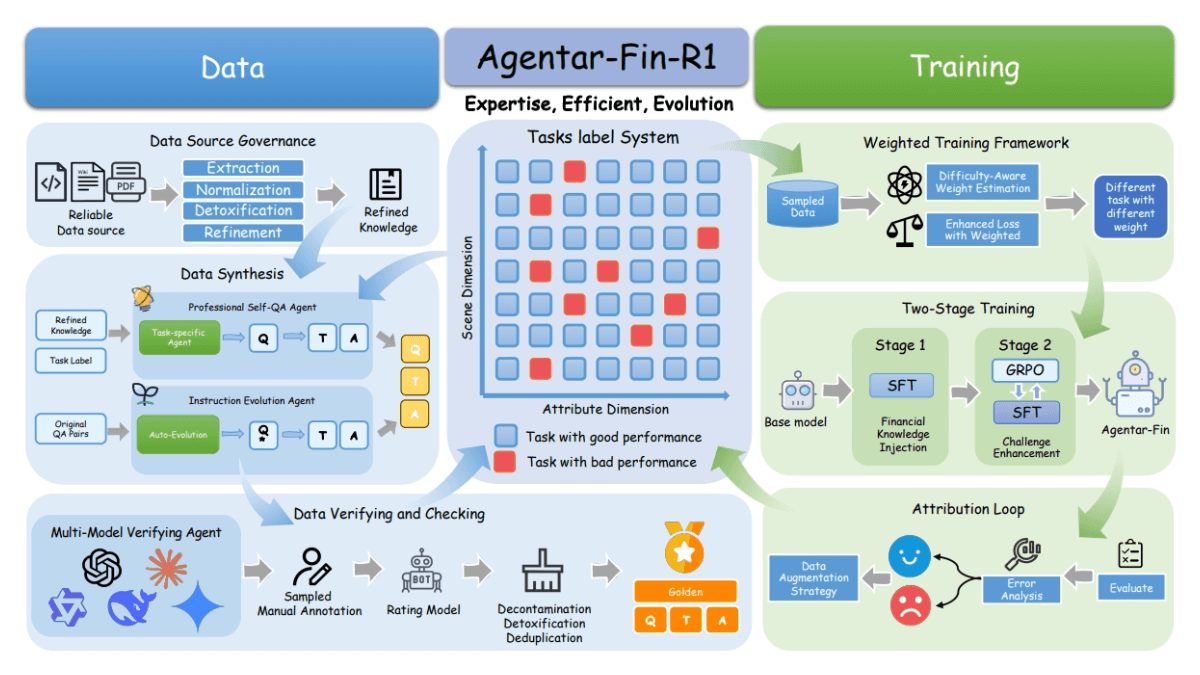
Agentar-Fin-R1은 Anthem에서 도입한 금융 분야를 위한 최첨단 대규모 언어 모델입니다. 강력한 Qwen3 아키텍처를 기반으로 개발된 이 모델은 8B와 32B의 두 가지 파라미터 스케일 버전을 제공하며 다단계 분석, 위험 평가, 전쟁 등 복잡한 재무 추론 작업을 정확하게 처리할 수 있습니다.
MoE-TTS는 사전 학습된 대규모 언어 모델(LLM)과 음성 전문가 모듈을 결합하는 혼합 전문가(MoE) 아키텍처를 기반으로 하는 쿤룬완웨이가 도입한 음성 합성 프레임워크로, 텍스트 모듈 파라미터는 고정하고 음성 모듈 파라미터만 업데이트하여 강력한 텍스트 추론 기능을 유지합니다...
Qwen3Guard는 보안 탐지를 위해 설계된 Qwen3 기본 모델을 기반으로 미세 조정된 보안 보호 모델입니다. 프롬프트 및 응답에 대한 정확한 보안 분류를 제공하고 위험 수준을 제공하며 영어, 중국어 및 다국어 환경을 지원합니다.Qwen3Guard는 두 가지 프로 버전으로 제공됩니다.
마인드링크는 쿤룬 월드와이드웹에서 출시한 오픈소스 추론의 대규모 모델입니다. 적응 형 추론 메커니즘을 통해 작업의 복잡성에 따라 유연한 전환 추론 모드, 간단한 작업 빠르게 생성, 복잡한 작업 심층 추론, 효율성과 정확성을 고려합니다. "생각"태그를 제거하기위한 계획 중심 추론 패러다임, 감소 ...
샤오미 미모 오디오는 다국어 대화, 음성 연속, 적은 샘플 일반화 및 오디오 이해와 같은 강력한 기능을 갖춘 샤오미의 오픈 소스 70억 개 파라미터 엔드투엔드 음성 매크로 모델로, 음성 지능 및 오디오 이해 벤치마크에서 구글 제미를 능가하는 SOTA 레벨에 도달할 수 있습니다.
미즈윅스는 메이퇀의 M17 팀이 모델의 지시를 따르는 능력을 평가하기 위해 사용하는 오픈 소스 대규모 모델 평가 세트입니다.미즈윅스는 3단계 평가 프레임워크를 사용하여 모델이 매크로에서 마이크로 수준까지 사용자의 지시에 따라 답변을 생성할 수 있는지 종합적으로 측정하며 답변 내용에 대한 지식은 긍정적으로 평가하지 않습니다.
미니맥스 뮤직 1.5는 사용자의 자연어 설명을 기반으로 최대 4분 분량의 음악 생성을 지원하는 고급 AI 음악 생성 도구입니다. 이 모델은 다양한 음악 스타일과 분위기 사용자 지정을 지원하며 자연스럽고 완전한 보컬 톤, 부드러운 전환 및 풍부한 레이어 편곡을 생성합니다....
웬신 빅 모델 X1.1은 언어 이해와 생성을 개선하는 데 중점을 둔 하이브리드 강화 학습 프레임워크를 기반으로 바이두에서 출시한 심층 사고 모델입니다. 이 모델은 복잡한 질문을 처리하고, 지시를 따르고, 지능의 행동을 시뮬레이션하는 데 탁월하며, 지식이 풍부한 답변과 고품질 텍스트 콘텐츠를 정확하게 제공할 수 있습니다.
플라이카운트 자바AI는 플라이카운트 테크놀로지에서 출시한 지능형 자바 개발 어시스턴트입니다. 이 플랫폼은 자연어 입력을 지원하여 요구사항 분석부터 코드 생성까지 지능형 개발의 전 과정을 지원합니다. 개발자는 요구 사항에 대한 설명만 입력하면 Flycount JavaAI가 완전한 엔지니어링 코드 프레임워크인 플랫폼을 정확하게 이해하고 생성할 수 있습니다.
Qwen3-Max-Preview는 통이췐웬에서 출시한 최신 플래그십 대형 언어 모델입니다. Qwen3 제품군에서 가장 많은 파라미터를 가진 모델로, 파라미터 크기가 1조 개가 넘습니다. 이 모델은 추론, 명령어 추종, 다국어 지원 및 롱테일 지식 범위에서 상당한 개선을 이루었습니다...
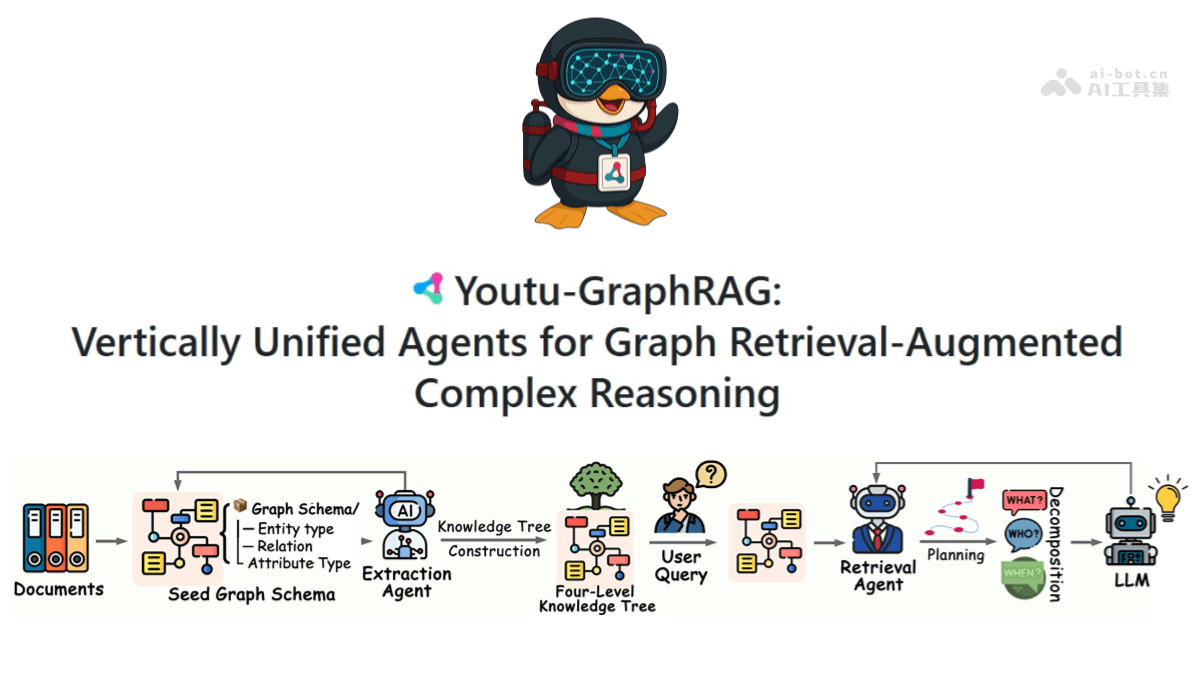
Youtu-GraphRAG는 대규모 언어 모델이 복잡한 Q&A 작업을 보다 정확하게 처리할 수 있도록 지원하는 텐센트 유투 연구소의 오픈 소스 그래프 검색 증강 생성 프레임워크입니다. 4계층 지식 트리를 구성하여 지식을 속성, 관계, 키워드 및 커뮤니티의 네 가지 수준으로 분해하여 행위의 자기 숙달에 대한 교차 도메인 지식을 달성합니다....
완싱 캐노피는 완싱 테크놀로지가 출시한 AIGC 동영상 제작 플랫폼으로, 동영상, 사진, 오디오 생성의 3대 창작 분야를 다루며 미디어 및 문화 산업 종사자, 영화 및 텔레비전/포스트 프로덕션 종사자, 예술 및 디자인 종사자, 광고 및 마케팅 실무자 등을 위해 특별히 설계되어 원스톱 전문 창작 솔루션을 제공합니다.
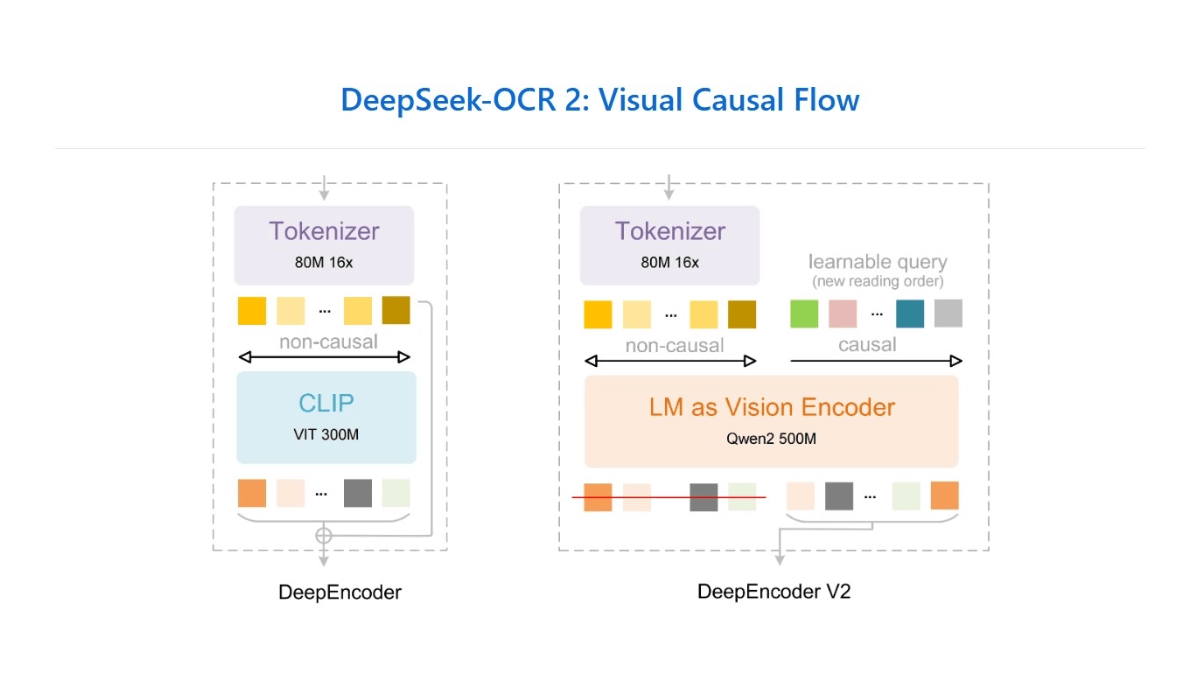
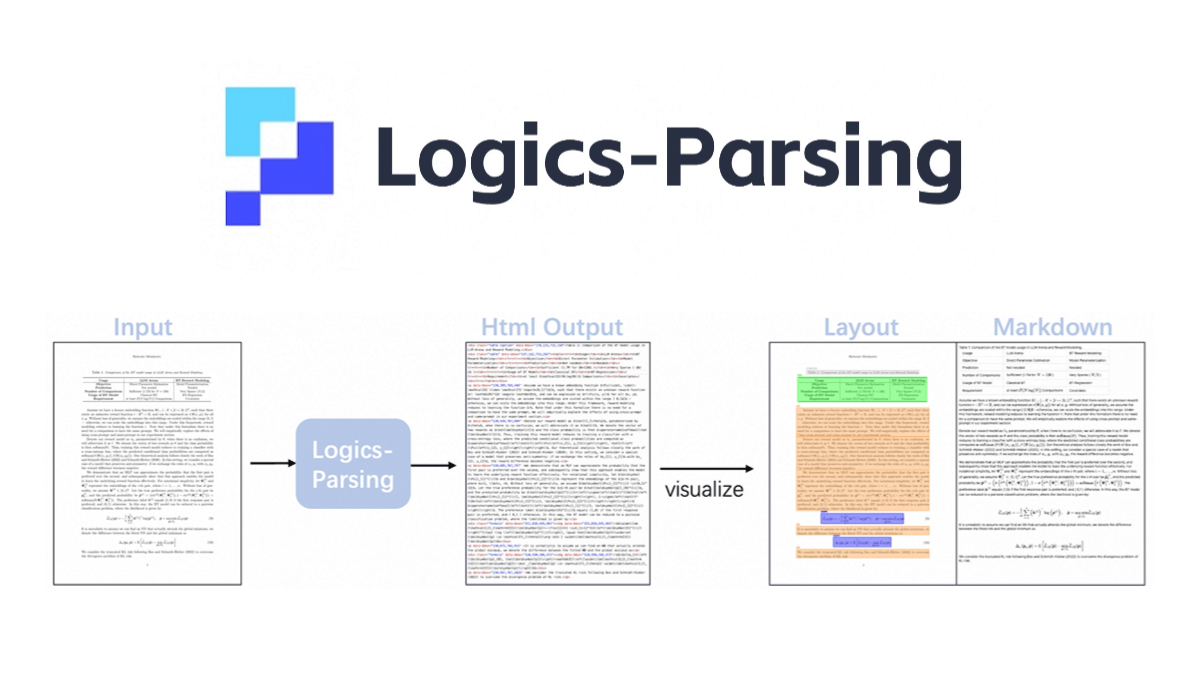
논리 구문 분석은 Qwen2.5-VL-7B를 기반으로하는 Ali 오픈 소스 엔드 투 엔드 문서 구문 분석 모델입니다. 강화 학습을 통해 문서 레이아웃 분석 및 읽기 순서 추론을 최적화하고 PDF 이미지를 구조화 된 HTML 출력으로 변환하고 다양한 콘텐츠를 지원할 수 있습니다 ...
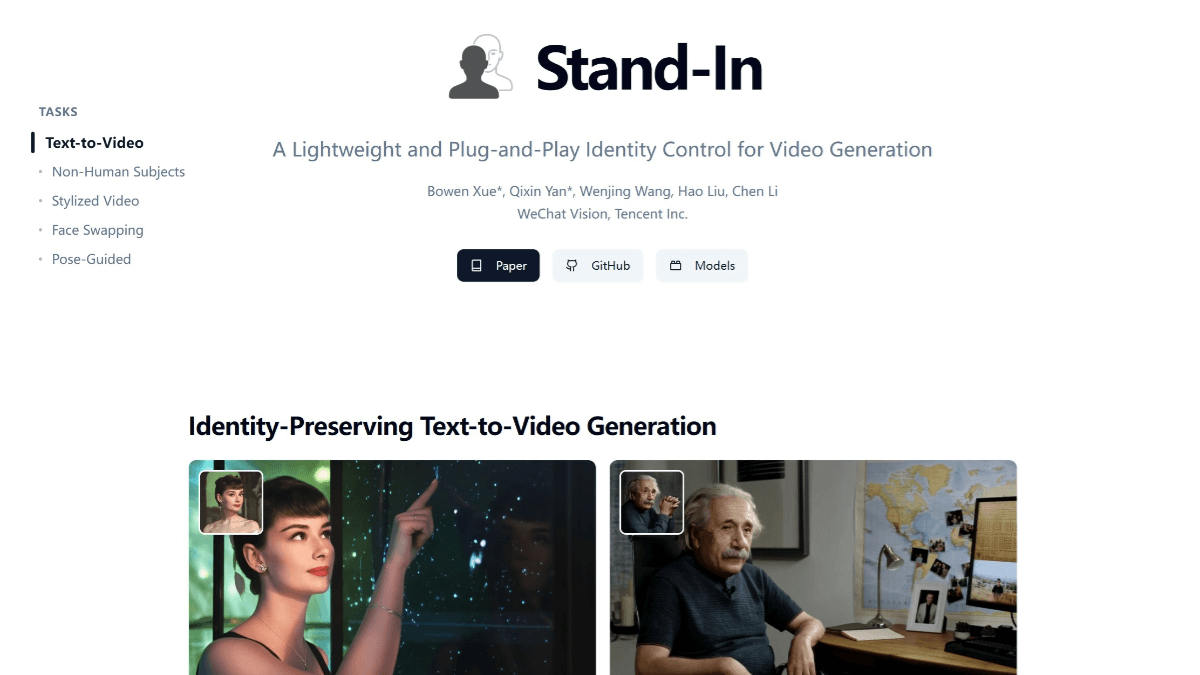
스탠드인(Stand-In)은 텐센트 WeChat 비전 팀이 개발한 가벼운 플러그 앤 플레이 방식의 신원 보존 동영상 생성 프레임워크입니다. 동영상 생성 시 특정 신원 특징을 보존하는 데 초점을 맞춘 이 프레임워크는 기본 모델 1%의 추가 파라미터만 학습하면 얼굴 유사성과 자연스러움에서 탁월한 결과를 얻을 수 있습니다.
모비에이전트는 상하이교통대학교 IPADS 연구소의 오픈 소스 모바일 지능형 바디 툴 체인으로, 사용자가 자신만의 모바일 지능형 비서를 구축할 수 있도록 도와줍니다. 사용자의 동작 궤적을 기록하고 고품질 데이터를 생성하여 자연어 명령을 이해할 수 있는 지능형 바디를 훈련시킵니다. 핵심 기능에는 효율적인...
후위안 월드-보이저(줄여서 후위안 보이저)는 텐센트에서 출시한 업계 최초의 초장거리 로밍 월드 모델로, 네이티브 3D 재구성을 지원합니다. 단일 이미지에서 사용자 정의 카메라 경로의 3D 포인트 클라우드 시퀀스를 생성하는 새로운 비디오 확산 프레임워크로, 다음을 지원합니다.
원캣은 메이투안이 상하이교통대학교와 함께 출시한 새로운 통합 멀티모달 모델로, 멀티모달 이해, 텍스트-이미지 생성, 이미지 편집 기능을 원활하게 통합하는 순수 디코더 아키텍처를 채택하고 있습니다. 이 모델은 외부 시각 코더와 모달리티별 디스모게이터에 의존하는 기존 멀티모달 모델의 설계를 버리고 모달리티별 ...
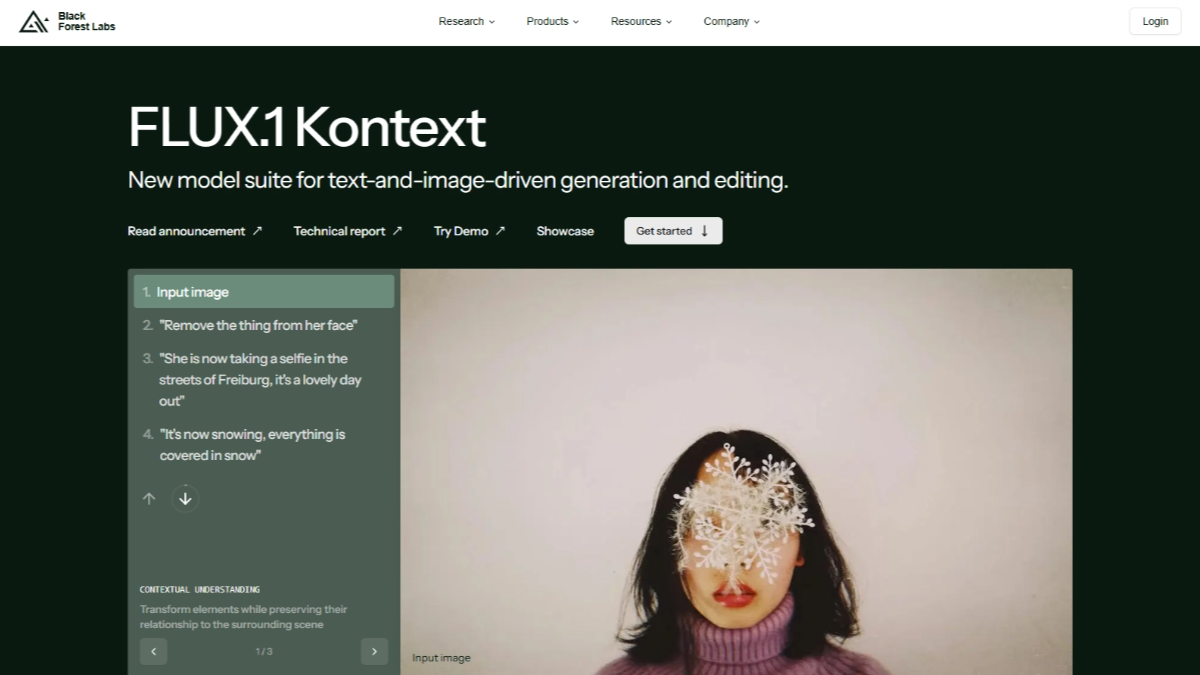
FLUX.1 Kontext는 문맥 인식 이미지 처리 기술을 제공하는 Black Forest Labs의 이미지 생성 및 편집 모델입니다. 이 모델은 텍스트 및 이미지 단서에 대한 반응을 이해하고 개체 수정, 스타일 변환, 배경 교체와 같은 작업을 수행하면서 모서리를 유지합니다.