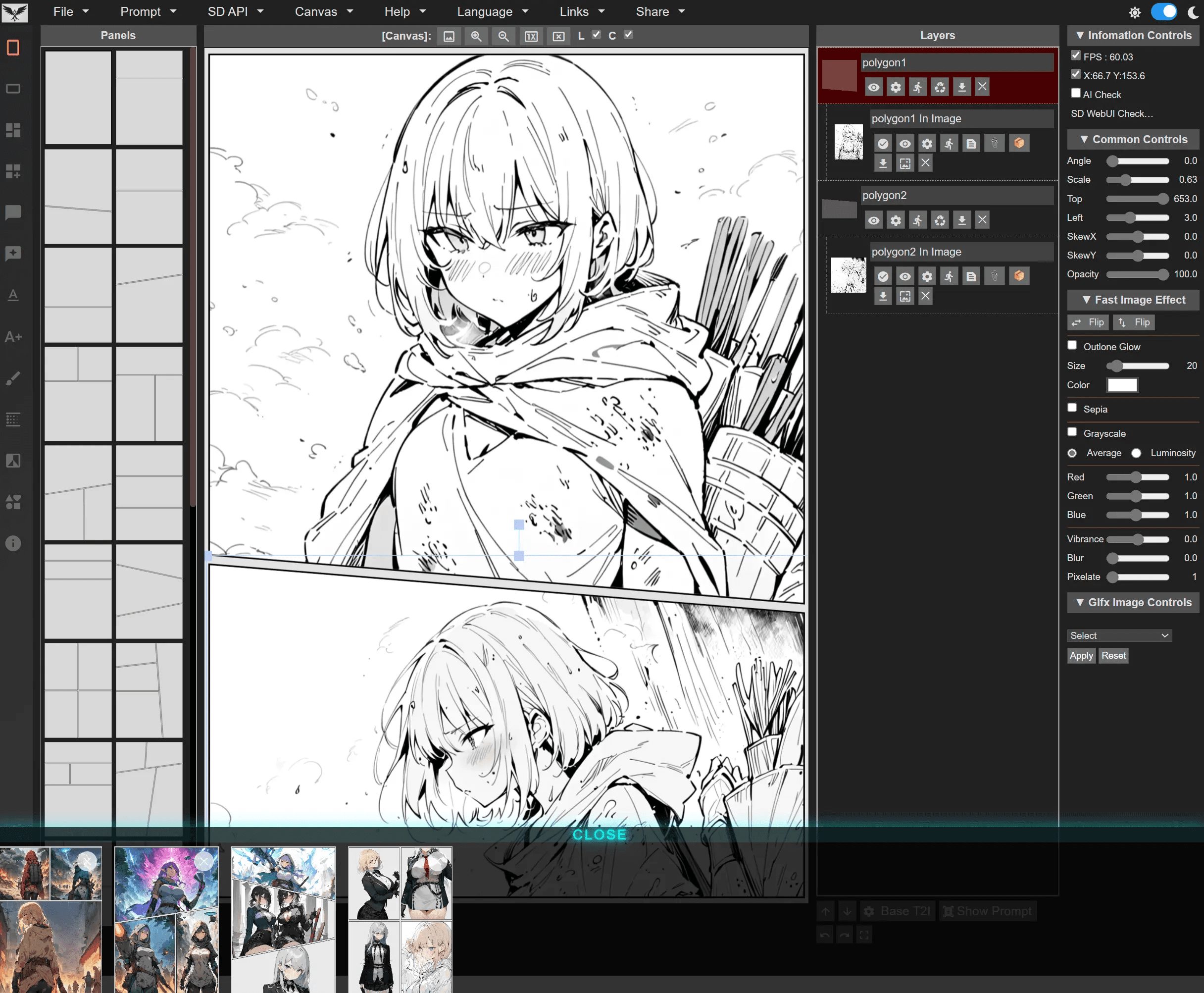
HiDream-O1-Image-1.5 - 智象未来推出的商用版图像生成大模型
Últimos recursos sobre IAPublicado hace 1 mes Círculo de intercambio de inteligencia artificial 23.1K 00

HiDream-O1-Image-1.5是什么
HiDream-O1-Image-1.5 是智象未来(HiDream.ai)推出的商用版图像生成大模型,在全球独立评测平台 Análisis artificial 的文生图榜单(Text to Image Leaderboard)中斩获 1265 ELO 评分,位列中国第一、全球第二(仅次于 OpenAI),超越 Google Nano Banana 2、NVIDIA Cosmos3-Super-Text2Image 及字节跳动 Seedream 4.0 等主流模型。

HiDream-O1-Image-1.5的功能特色
- 原生全模态统一架构(UiT):采用 Unified Transformador 架构,将图像像素、文本 Token、视频体素等原始信号直接映射到同一共享 Ficha 空间,无需独立的文本编码器与 VAE,减少跨模态转换中的细节损耗与语义错位。
- "先推理、后生成"机制:内置基于 Gemma 4 的 Reasoning-Driven Prompt Agent,在扩散模型运行前先执行思维链(CoT),将复杂 prompt 中的镜头语言、光学参数、氛围、主体等约束分开处理、汇总执行,大幅提升指令遵循精度。
- 摄影级画质生成:在人像、动物、自然风光等场景中,具备稳定的皮肤/皮毛质感、复杂光影、水下折射及空间透视控制能力,输出效果达到专业摄影级别。
- 复杂文字渲染能力:支持中英文混排、多层级卖点、数字公式、图表信息及复杂排版;在 CVTG-2K 测试中长文本渲染得分达 0.978,超越 GPT Image 2。
- 多主体与角色一致性:可围绕同一 IP 角色生成多角度视图与多种情绪表情,保持五官、发型、服饰高度统一,适用于角色设定与 IP 创作。
- 分镜与连续叙事能力:支持多宫格布局、连续画面生成,可自动维护角色、场景与视觉风格统一,适用于影视分镜、漫画创作、广告脚本等叙事场景。
- Salida de alta resolución:支持高分辨率图像生成,满足印刷、广告、电商等场景对精细度的要求。
- 商用级 API 与开源双轨:提供商用版 API 服务(vivago.ai / hiharness.ai),同时开源 8B 版本供开发者下载研究,兼顾商业落地与社区生态。
HiDream-O1-Image-1.5的核心优势
- 全球顶尖性能:在 Artificial Analysis 文生图榜单以 1265 ELO 位列中国第一、全球第二,超越 Google、NVIDIA、字节跳动等主流模型。
- 原生全模态统一架构(UiT):首创剔除 VAE 与独立文本编码器,将图像、文本、视频信号直接映射到同一共享 Token 空间,由统一 Transformer 完成理解、生成与推理,从根本上减少跨模态信息损耗。
- "先推理、后生成"的指令遵循能力:内置基于 Gemma 4 的 Reasoning-Driven Prompt Agent,通过思维链(CoT)预先解析复杂 prompt 中的镜头语言、光学参数、氛围与主体约束,实现远超传统模型的精准指令遵循。
- 业界领先的复杂文字渲染:CVTG-2K 测试得分 0.978,超越 GPT Image 2;支持中英文混排、多层级卖点、数字公式、图表信息及复杂排版,彻底解决 AI 图像"乱写字"痛点。
- 摄影级画质与细节控制:在人像皮肤质感、动物毛发、水下折射、空间透视与复杂光影等场景中表现稳定,输出达到专业摄影级别。
- 多主体与角色高度一致性:可围绕同一 IP 角色生成多角度视图与多种情绪表情,保持五官、发型、服饰高度统一,满足动画、游戏、IP 开发的资产需求。
- 分镜与连续叙事能力:支持多宫格布局与连续画面生成,自动维护角色、场景与视觉风格统一,直接适用于影视分镜、漫画创作、广告脚本等叙事工作流。
HiDream-O1-Image-1.5的操作步骤
- 网页端直接使用: Acceso vivago 商用平台 https://vivago.ai/ tal vez https://hiharness.ai/ 官网,注册/登录账号后,在文本输入框中描述所需图像内容,点击生成即可获取图片。
- 优化 Prompt 输入:在输入框中尽可能详细描述画面需求,包括主体、场景、风格、镜头语言、光影氛围、文字内容等;模型内置的 Reasoning-Driven Prompt Agent 会自动解析并优化复杂指令。
- 选择生成参数(如适用):根据平台界面选项,设置图像尺寸、分辨率、风格倾向等参数,以匹配广告、电商、影视分镜等不同场景需求。
- Desarrollo de integración de API:通过官方提供的商用 API,将 HiDream-O1-Image-1.5 接入自有应用或工作流;调用时传入文本 Prompt 与相关参数,获取生成结果用于批量生产或自动化流程。
- Modelos de código abierto para implantación local:前往 GitHub 或 Hugging Face 下载 HiDream-O1-Image(8B 开源版),配置本地运行环境后加载模型权重,通过代码脚本输入 Prompt 进行图像生成。
- 分镜与多图生成:如需连续叙事或多宫格画面,在 Prompt 中明确描述分镜需求、角色一致性要求及画面序列,模型将自动维护角色、场景与视觉风格的统一。
- 结果下载与二次编辑:生成完成后下载高清图像,根据实际业务需求进行后期排版、裁切或与其他设计工具配合完成最终物料。
HiDream-O1-Image-1.5的适用人群
- 广告营销从业者:需要快速生成商品海报、品牌物料、社媒种草图及融合中英文营销文案的复杂排版内容。
- 电商运营与设计人员:用于制作详情页、主图、促销 banner,支持高分辨率商品展示与复杂文字信息排版。
- 影视与动画创作者:需要生成影视分镜、连续叙事画面、角色三视图及保持角色一致性的前期美术资产。
- 漫画与插画师:利用多宫格布局与连续画面生成能力,辅助漫画分镜、角色表情变化及场景设计。
- 游戏美术与策划:用于生成场景概念图、角色设定、风格化资产,并保持 IP 角色在多张图中的高度一致性。
- 品牌与 IP 运营方:围绕同一 IP 角色生成多角度视图与多种情绪表情,维护五官、发型、服饰的统一性。
HiDream-O1-Image-1.5的常见问题
Q:它的核心架构与传统扩散模型有何不同?
A:采用原生全模态 Unified Transformer(UiT) 架构,剔除了传统 VAE 和独立文本编码器,将图像像素、文本 Token、视频体素等信号直接映射到同一共享 Token 空间,由统一 Transformer 完成理解与生成,显著减少跨模态信息损耗。
Q:"先推理、后生成"具体指什么?
A:模型内置基于 Gemma 4 的 Reasoning-Driven Prompt Agent,在正式扩散生成前先执行一轮思维链(CoT),将 prompt 中的镜头语言、光学参数、氛围、主体等复杂约束分开解析、汇总执行,从而大幅提升指令遵循精度。
Q:在文字渲染方面的表现如何?
A:在 CVTG-2K 长文本渲染测试中得分 0.978,超越 GPT Image 2(0.961)。支持中英文混排、多层级卖点、数字公式、图表信息及复杂排版,有效解决 AI 图像"乱写字"问题。
Q:如何保证多图之间的角色一致性?
A:模型具备强大的角色一致性能力,可围绕同一 IP 角色生成多角度视图与多种情绪表情,自动保持五官、发型、服饰的高度统一,适用于角色设定、动画前期美术等场景。
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...