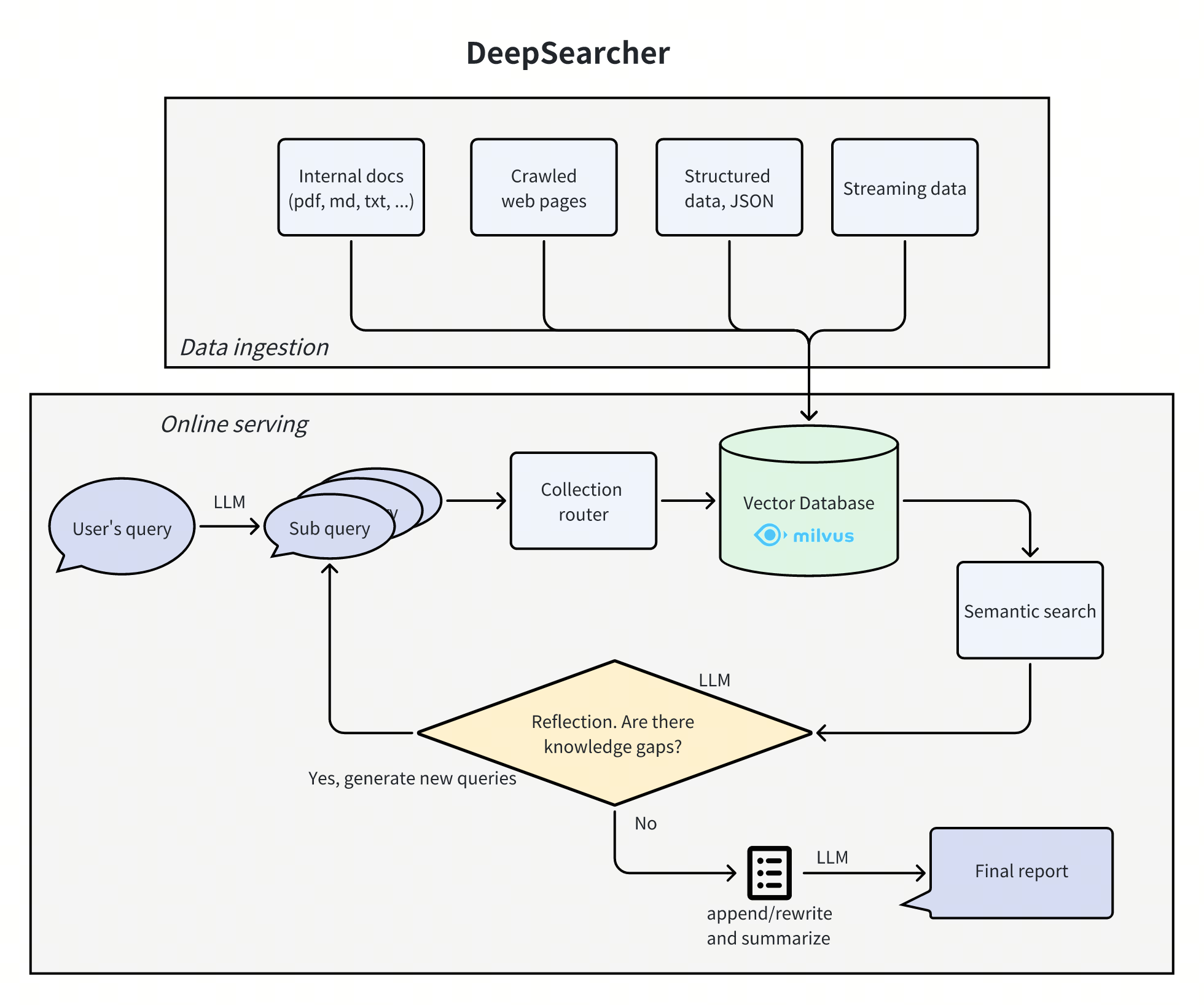
Hy-MT2 - 腾讯混元开源的多语言机器翻译模型家族
Últimos recursos sobre IAPublicado hace 2 meses Círculo de intercambio de inteligencia artificial 32.4K 00

Hy-MT2是什么
Hy-MT2 是腾讯混元开源的多语言机器翻译模型家族,专为复杂真实场景设计。包含 1.8B、7B 和 30B-A3B(MoE) 三个尺寸,均支持 33种语言 之间的互译,具备多语言翻译指令遵循能力。通过自研的 AngelSlim 极端量化技术,1.8B 模型可压缩至仅 440MB 存储空间,在苹果 A15 芯片上的推理速度较上一代提升 1.5倍,实现了高质量的端侧本地部署。
Hy-MT2的功能特色
- 33种语言互译:覆盖全球主流语种及少数民族语言,支持任意方向的高质量翻译。
- 翻译指令遵循:支持风格控制、格式保留(如分隔符、SRT字幕)、术语约束、法律脱敏、注释辅助等复杂翻译指令。
- 多精度量化部署:提供 FP16、8-bit、4-bit、2-bit 及 1.25-bit 等多种精度格式,适配从云端高并发到端侧低功耗的全场景需求。
- 专业领域翻译:针对金融、法律、政治、科技、医疗、教育六大领域进行专项优化,术语翻译精准。
- 真实场景鲁棒翻译:覆盖网页、会议、书籍、社交内容、新闻、文档等六大真实业务场景,对复杂输入分布具备强适应能力。
- 离线本地推理:1.8B 端侧模型可在无网络或弱网环境下运行,解决网络受限场景的翻译需求。
Hy-MT2的核心优势
- 性能超越开源大模型:7B 和 30B-A3B 模型在快思考模式下,性能超越 DeepSeek-V4-Pro、Kimi K2.6、Qwen3.5-397B-A17B 等开源基线,接近甚至部分超越 Géminis 3.1 Pro 和 GPT-5.5。
- 轻量模型 surpass 商业 API:1.8B 模型在 WMT25 等基准上整体超越微软翻译和豆包翻译等主流商业 API,实现小参数量的高效能。
- 极致端侧压缩:基于 AngelSlim 1.25-bit 稀疏三值量化,1.8B 模型仅需 440MB 存储,推理速度提升 1.5 倍,为目前端侧部署效率极高的翻译模型之一。
- MoE 架构高效平衡:30B-A3B 采用混合专家架构,在保持顶级翻译质量的同时,相比同等性能稠密模型显著降低推理成本。
- 定向指令优化:在翻译专用指令遵循基准 IFMTBench 上,30B-A3B 在中小模型中取得最佳综合得分,复杂多约束指令处理能力突出。
Hy-MT2官网是什么
- Página web del proyecto:https://aistudio.tencent.com/llm/en?tabIndex=0
- Repositorio GitHub:https://github.com/Tencent-Hunyuan/Hy-MT2
- Biblioteca de modelos HuggingFace:https://huggingface.co/collections/tencent/hy-mt2
Hy-MT2的操作步骤
- 普通用户快速体验:打开微信,搜索并进入「腾讯Hy翻译」小程序,无需下载安装即可直接输入文本或使用语音进行33种语言的实时互译,支持离线模式时提前下载端侧模型包。
- 开发者获取模型:访问 Hugging Face 或 ModelScope 平台,搜索
Tencent-Hunyuan/Hy-MT2,根据硬件条件选择下载 1.8B、7B 或 30B-A3B(MoE)模型权重。 - 选择精度格式:根据部署场景选取对应量化版本——云端高并发推荐 FP16 或 8-bit,本地 PC 推荐 4-bit,移动端或 IoT 设备推荐 2-bit 或 1.25-bit(1.8B 模型最低仅需 440MB 存储)。
- 加载模型与配置环境:使用 PyTorch 或 vLLM 等推理框架加载模型,配置目标语言对及翻译指令参数(如风格控制、术语约束、格式保留等),30B-A3B 需确保显存或内存满足 MoE 架构需求。
- 执行翻译任务:输入待翻译文本或文档,调用模型推理;可通过 Hy-MT2-Translator Skill 快速集成到现有工作流,支持批量处理、SRT 字幕翻译及法律脱敏等高级指令。
- 端侧离线部署(1.8B):将 1.25-bit 量化后的 440MB 模型包集成到手机 App 或小程序中,利用 AngelSlim 引擎在苹果 A15 等芯片上本地运行,实现无网络环境下的低延迟翻译。
- 效果验证与调优:在 WMT25、IFMTBench 等基准或自有测试集上验证翻译质量,针对金融、法律等六大专业领域调整术语表和指令模板,必要时使用 FCPT 后训练流程进行领域定向优化。
Hy-MT2的适用人群
- 出海企业与跨境电商:需要高质量、多语种、专业领域(如法律合同、产品说明)翻译的团队。
- 移动端用户:需要在无网络环境(如境外漫游、飞行模式)下获得可靠翻译体验的个人用户。
- 翻译从业者与本地化团队:对术语一致性、风格控制、格式保留有严格要求的职业译者。
- AI 开发者与研究者:需要集成开源多语言翻译能力或研究低比特量化部署的工程师。
- 内容创作者与自媒体:处理多语言素材、字幕翻译、跨文化内容适配的创作者。
Hy-MT2的常见问题
Q:Hy-MT2 与 Hy-MT1.5 相比有哪些主要提升?
A:Hy-MT2 在五个维度进行了系统性升级:专业领域翻译质量、真实场景鲁棒性、翻译指令遵循能力、模型规模扩展(新增 30B-A3B MoE)、端侧部署效率(1.25-bit 量化仅需 440MB,速度提升 1.5 倍)。
Q:1.25-bit 量化是否会导致翻译质量严重下降?
A:FP8 和 4-bit 版本在大多数基准上接近 BF16 原版性能;2-bit 和 1.25-bit 版本在通用翻译和领域翻译上仍保持竞争力,但在复杂指令遵循任务(如 IFMTBench)上会有更明显折损,适合对存储和速度要求极高的场景。
Q:Hy-MT2 是否只能用于翻译任务?
A:虽然核心优化面向翻译,但 30B-A3B 在通用指令遵循基准(IFEval、MaXIFE)上仍保持扎实表现。不过其主要优势在于翻译专用指令遵循,而非通用多轮对话。
Q:如何获取和使用 Hy-MT2?
A:模型已开源在 Hugging Face 和 ModelScope,GitHub 仓库为 Tencent-Hunyuan/Hy-MT2,同时提供 Hy-MT2-Translator Skill 便于快速集成。普通用户也可通过微信小程序「腾讯Hy翻译」直接体验。
Q:Hy-MT2 支持哪些语言?
A:支持 33 种语言之间的互译,涵盖全球主流商业语种,并特别优化了普通话与少数民族语言之间的双向翻译。
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...