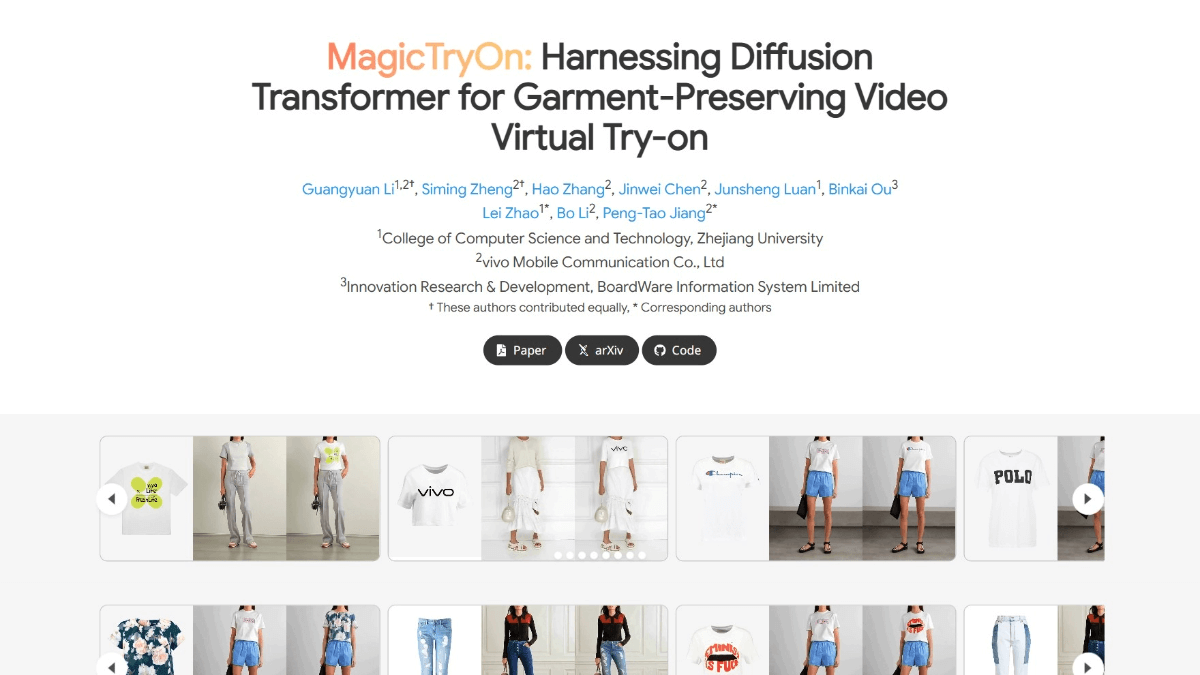

综合介绍
Dynamiq是一个开源的AI编排框架,专为代理AI和大语言模型(LLM)应用而设计。它旨在简化AI驱动应用程序的开发,特别是在检索增强生成(RAG)和LLM代理的编排方面。Dynamiq提供了丰富的功能模块和详细的文档,帮助开发者快速上手并高效地构建复杂的AI应用。
特点
Dynamiq是一个创新的 AI 框架,它通过将 LLMs 的推理能力(大脑)与执行具体操作的功能(双手)相结合,使 AI 能够像人类一样理解任务、进行推理并采取实际行动来解决现实问题
// ReAct 的定义:
- ReAct 是一个框架,它结合了 LLMs 的推理能力和执行操作的能力
- 它使 AI 能够理解、规划并与现实世界进行交互
// ReAct agents 的工作原理:
它整合了两个关键组件:
- 大脑(LLM 提供的思考能力)
- 手(执行操作的能力)
// 框架组成部分:
- Task(任务输入)
- Agent(智能体,包含 LLM 和工具)
- Environment(环境)
- Response(响应输出)
// 实际应用示例:
作者用一个判断是否需要带伞的场景来说明 ReAct agent 的工作流程:
- 接收用户询问是否需要带伞的任务
- 使用工具查询天气报告
- 进行推理分析
- 给出建议响应
// Akshay 分享的 Dynamiq 框架:
Dynamiq 是一个面向新一代 AI 开发的综合性框架,专注于简化 AI 应用的开发流程,其主要特点是能够编排和管理基于 RAG 和 LLM 的 Agents 系统。
// 主要特点:
全能性:作为一站式("all-in-one")框架,整合了开发 AI 应用所需的各种工具和功能
专业领域:
- RAG 系统的编排
- LLM Agent 的管理
- AI 应用的开发流程优化
定位:
- 作为编排框架(orchestration framework),专注于协调和管理各个 AI 组件
- 面向 Agentic AI 应用的开发
- 简化开发者在构建 AI 应用时的复杂性
功能列表
- 安装和配置:提供详细的安装指南,支持Python环境。
- 文档和示例:丰富的文档和示例代码,帮助用户快速上手。
- 简单LLM流程:提供简单的LLM工作流示例,便于用户理解和使用。
- ReAct代理:支持复杂编码任务的代理,集成E2B代码解释器。
- 多代理编排:支持多代理协同工作,适用于复杂任务的解决方案。
- RAG文档索引和检索:支持PDF文档的预处理、向量嵌入和存储,以及相关文档的检索和问题回答。
- 带记忆的聊天机器人:支持存储和检索对话历史的简单聊天机器人。
使用帮助
安装和配置
- 安装Python:确保您的计算机上已安装Python。
- 安装Dynamiq:
pip install dynamiq或者从源代码构建:
git clone https://github.com/dynamiq-ai/dynamiq.git cd dynamiq poetry install
使用示例
简单LLM流程
以下是一个简单的LLM工作流示例:
from dynamiq.nodes.llms.openai import OpenAI
from dynamiq.connections import OpenAI as OpenAIConnection
from dynamiq import Workflow
from dynamiq.prompts import Prompt, Message
# 定义翻译提示模板
prompt_template = """
Translate the following text into English: {{ text }}
"""
prompt = Prompt(messages=[Message(content=prompt_template, role="user")])
# 设置LLM节点
llm = OpenAI(
id="openai",
connection=OpenAIConnection(api_key="$OPENAI_API_KEY"),
model="gpt-4o",
temperature=0.3,
max_tokens=1000,
prompt=prompt
)
# 创建工作流对象
workflow = Workflow()
workflow.flow.add_nodes(llm)
# 运行工作流
result = workflow.run(input_data={"text": "Hola Mundo!"})
print(result.output)
ReAct代理
以下是一个支持复杂编码任务的ReAct代理示例:
from dynamiq.nodes.llms.openai import OpenAI
from dynamiq.connections import OpenAI as OpenAIConnection, E2B as E2BConnection
from dynamiq.nodes.agents.react import ReActAgent
from dynamiq.nodes.tools.e2b_sandbox import E2BInterpreterTool
# 初始化E2B工具
e2b_tool = E2BInterpreterTool(connection=E2BConnection(api_key="$API_KEY"))
# 设置LLM
llm = OpenAI(
id="openai",
connection=OpenAIConnection(api_key="$API_KEY"),
model="gpt-4o",
temperature=0.3,
max_tokens=1000,
)
# 创建ReAct代理
agent = ReActAgent(
name="react-agent",
llm=llm,
tools=[e2b_tool],
role="Senior Data Scientist",
max_loops=10,
)
# 运行代理
result = agent.run(input_data={"input": "Add the first 10 numbers and tell if the result is prime."})
print(result.output.get("content"))
多代理编排
以下是一个多代理协同工作的示例:
from dynamiq.connections import OpenAI as OpenAIConnection, ScaleSerp as ScaleSerpConnection, E2B as E2BConnection
from dynamiq.nodes.llms import OpenAI
from dynamiq.nodes.agents.orchestrators.adaptive import AdaptiveOrchestrator
from dynamiq.nodes.agents.orchestrators.adaptive_manager import AdaptiveAgentManager
from dynamiq.nodes.agents.react import ReActAgent
from dynamiq.nodes.agents.reflection import ReflectionAgent
from dynamiq.nodes.tools.e2b_sandbox import E2BInterpreterTool
from dynamiq.nodes.tools.scale_serp import ScaleSerpTool
# 初始化工具
python_tool = E2BInterpreterTool(connection=E2BConnection(api_key="$E2B_API_KEY"))
search_tool = ScaleSerpTool(connection=ScaleSerpConnection(api_key="$SCALESERP_API_KEY"))
# 初始化LLM
llm = OpenAI(connection=OpenAIConnection(api_key="$OPENAI_API_KEY"), model="gpt-4o", temperature=0.1)
# 定义代理
coding_agent = ReActAgent(
name="coding-agent",
llm=llm,
tools=[python_tool],
role="Expert agent with coding skills. Goal is to provide the solution to the input task using Python software engineering skills.",
max_loops=15,
)
planner_agent = ReflectionAgent(
name="planner-agent",
llm=llm,
role="Expert agent with planning skills. Goal is to analyze complex requests and provide a detailed action plan.",
)
search_agent = ReActAgent(
name="search-agent",
llm=llm,
tools=[search_tool],
role="Expert agent with web search skills. Goal is to provide the solution to the input task using web search and summarization skills.",
max_loops=10,
)
# 初始化自适应代理管理器
agent_manager = AdaptiveAgentManager(llm=llm)
# 创建编排器
orchestrator = AdaptiveOrchestrator(
name="adaptive-orchestrator",
agents=[coding_agent, planner_agent, search_agent],
manager=agent_manager,
)
# 定义输入任务
input_task = (
"Use coding skills to gather data about Nvidia and Intel stock prices for the last 10 years, "
"calculate the average per year for each company, and create a table. Then craft a report "
"and add a conclusion: what would have been better if I had invested $100 ten years ago?"
)
# 运行编排器
result = orchestrator.run(input_data={"input": input_task})
print(result.output.get("content"))
RAG文档索引和检索
Dynamiq支持检索增强生成(RAG),可以通过以下步骤实现:
- 文档预处理:将输入的PDF文件转换为向量嵌入并存储在向量数据库中。
- 文档检索:根据用户查询检索相关文档并生成答案。
以下是一个简单的RAG工作流示例:
from io import BytesIO
from dynamiq import Workflow
from dynamiq.connections import OpenAI as OpenAIConnection, Pinecone as PineconeConnection
from dynamiq.nodes.converters import PyPDFConverter
from dynamiq.nodes.splitters.document import DocumentSplitter
from dynamiq.nodes.embedders import OpenAIDocumentEmbedder
from dynamiq.nodes.writers import PineconeDocumentWriter
# 初始化工作流
rag_wf = Workflow()
# PDF文档转换器
converter = PyPDFConverter(document_creation_mode="one-doc-per-page")
rag_wf.flow.add_nodes(converter)
# 文档拆分器
document_splitter = (
DocumentSplitter(split_by="sentence", split_length=10, split_overlap=1)
.inputs(documents=converter.outputs.documents)
.depends_on(converter)
)
rag_wf.flow.add_nodes(document_splitter)
# OpenAI向量嵌入
embedder = (
OpenAIDocumentEmbedder(connection=OpenAIConnection(api_key="$OPENAI_API_KEY"), model="text-embedding-3-small")
.inputs(documents=document_splitter.outputs.documents)
.depends_on(document_splitter)
)
rag_wf.flow.add_nodes(embedder)
# Pinecone向量存储
vector_store = (
PineconeDocumentWriter(connection=PineconeConnection(api_key="$PINECONE_API_KEY"), index_name="default", dimension=1536)
.inputs(documents=embedder.outputs.documents)
.depends_on(embedder)
)
rag_wf.flow.add_nodes(vector_store)
# 准备输入PDF文件
file_paths = ["example.pdf"]
input_data = {
"files": [BytesIO(open(path, "rb").read()) for path in file_paths],
"metadata": [{"filename": path} for path in file_paths],
}
# 运行RAG索引流程
rag_wf.run(input_data=input_data)
带记忆的聊天机器人
以下是一个带记忆功能的简单聊天机器人示例:
from dynamiq.connections import OpenAI as OpenAIConnection
from dynamiq.memory import Memory
from dynamiq.memory.backend.in_memory import InMemory
from dynamiq.nodes.agents.simple import SimpleAgent
from dynamiq.nodes.llms import OpenAI
AGENT_ROLE = "helpful assistant, goal is to provide useful information and answer questions"
llm = OpenAI(
connection=OpenAIConnection(api_key="$OPENAI_API_KEY"),
model="gpt-4o",
temperature=0.1,
)
memory = Memory(backend=InMemory())
agent = SimpleAgent(
name="Agent",
llm=llm,
role=AGENT_ROLE,
id="agent",
memory=memory,
)
def main():
print("Welcome to the AI Chat! (Type 'exit' to end)")
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
break
response = agent.run({"input": user_input})
response_content = response.output.get("content")
print(f"AI: {response_content}")
if __name__ == "__main__":
main()
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
Related posts



暂无评论...