

人工智能 (AI) 模型领域总是充满惊喜,每一次技术突破都能牵动业界的神经。近日,阿里巴巴千问团队在凌晨时分发布了其最新的推理模型 QwQ-32B,再次引发了广泛关注。

根据官方发布的公告,QwQ-32B 是一款参数规模仅为 320 亿的推理模型,却宣称能够匹敌 DeepSeek-R1 等业界领先的尖端模型。 这则消息犹如一颗重磅炸弹,瞬间引爆了技术社区,并随附了指向官方博客、Hugging Face 模型库、模型下载、在线演示及使用网站的链接,方便用户进一步了解和体验。
虽然发布信息言简意赅,但其背后所代表的技术实力却绝非简单。一句 “320 亿参数媲美 DeepSeek-R1” 足以令人惊叹,要知道,通常来说,模型参数量越大,其性能往往也更强,但同时也意味着更高的计算资源需求。 QwQ-32B 以小参数量实现了与超大模型相近的性能,无疑是一项重大突破,这也自然激起了科技爱好者和专业人士的强烈兴趣。
为了更直观地展示 QwQ-32B 的性能,官方同步公开了一张基准测试图。基准测试是评估 AI 模型能力的重要手段,它通过在一系列预设的、标准化的数据集上进行测试,来衡量模型在不同任务上的表现,从而为用户提供一个客观的性能参考。

从这张基准测试图中,我们可以迅速捕捉到以下几个关键信息点:
- 现象级的传播速度: 模型发布信息在短短 12 小时内 достига́ть 了超过 169 万的阅读量,充分体现了市场对高性能 AI 模型的迫切需求和对 QwQ-32B 的高度期待。
- 卓越的性能表现: QwQ-32B 仅凭 320 亿参数,在基准测试中就能够与参数量高达 6710 亿的 DeepSeek-R1 全参数版本模型相提并论,展现出惊人的能效比。 这种小模型超越大模型的现象,无疑打破了人们对模型性能与参数规模之间关系的传统认知。
- 超越同级别蒸馏模型: QwQ-32B 的性能明显优于 DeepSeek-R1 的 32B 蒸馏版本。 蒸馏模型是一种模型压缩技术,旨在通过训练小模型来模仿大模型的行为,从而在保持性能的同时降低计算成本。 而 QwQ-32B 能够超越同为 32B 规模的蒸馏模型,进一步证明了其架构和训练方法的先进性。
- 多维度性能领先: 在多个基准测试维度上,QwQ-32B 均超越了 OpenAI 的闭源模型 o1-mini。 这表明 QwQ-32B 在通用能力上已经具备了与顶尖闭源模型竞争的实力。
尤其值得关注的是,QwQ-32B 仅仅拥有 320 亿参数,却能够比肩参数量是其 20 倍以上的巨型模型,这无疑代表着 AI 技术的又一次飞跃。 更令人振奋的是,用户现在只需配备 RTX3090 或 RTX4090 级别的消费级显卡,即可在本地轻松运行 QwQ-32B 的量化版本。 本地部署不仅降低了使用门槛,也为数据安全和个性化应用提供了更多可能。对于显卡性能较低的用户可以尝试从前推荐的云端部署方案进行上手:使用免费 GPU 算力在线部署 DeepSeek-R1 开源模型,或直接申请使用免费API,阿里百炼 提供每日100万tokens(持续180天),而 Akash 直接无需注册即可免费使用API。
DeepSeek 不再独秀,OpenAI 如何保持优势?
在 QwQ-32B 展现出如此强劲的竞争力之后,OpenAI 的现有产品,无论是定价 200 美元的 Pro 版本还是 20 美元的 Plus 版本,在性价比方面都面临着严峻的挑战。 尤其考虑到 OpenAI 模型有时表现出的性能波动,即用户所诟病的 “降智” 现象, QwQ-32B 的出现无疑给市场带来了新的思考。 尽管如此,OpenAI 在 AI 领域仍然拥有深厚的积累和广泛的生态系统,其在特定领域的模型微调和应用优化方面可能仍具备优势。 但 QwQ-32B 的发布,无疑打破了市场原有格局,迫使所有参与者重新审视自身的技术优势和市场策略。
为了更全面地评估 QwQ-32B 的实际应用能力,我们有必要对其进行本地安装和详细测试,特别是要考察其在本地运行环境下的推理性能和“智商”水平。
幸运的是,得益于 Ollama 等工具的出现,如今在个人电脑上本地部署和运行大型语言模型已经变得非常简单。 Ollama 作为一个开源的轻量级模型运行框架,极大地简化了用户部署和管理本地大模型的流程。
Ollama 以其出色的效率和易用性而备受赞誉。 在 QwQ-32B 发布后不久,Ollama 迅速宣布支持该模型,进一步降低了用户体验最新 AI 技术的门槛,使得人人都能轻松上手体验 QwQ-32B 的强大功能。
1. Ollama 的安装与运行
首先,访问 Ollama 官方网站 ollama.com,点击 Download 按钮,根据您的操作系统下载相应的安装包。
Ollama 提供了对包括 macOS (Intel 和 Apple Silicon)、Windows 以及 Linux 在内的主流操作系统的全面支持, 确保了用户可以在各种平台上便捷地使用 QwQ-32B 模型。
下载完成后,双击安装程序,按照向导提示完成安装过程。 安装成功后,在 Windows 系统的任务栏托盘或 macOS 系统的菜单栏中,您将看到一个可爱的羊驼图标,这表明 Ollama 已经成功启动并在后台运行,随时准备为您服务。
2. QwQ-32B 模型的下载
在成功安装并运行 Ollama 之后,接下来就可以开始下载 QwQ-32B 模型了。

打开 Ollama 客户端,在 Models 模型页面,您会发现 QwQ-32B 模型已经迅速攀升至热门模型排行榜的首位, 足见其受欢迎程度之高。 找到 “qwq” 模型条目,点击进入模型详情页面。 在详情页中,复制红色边框突出显示的命令。
打开本地终端 (macOS/Linux) 或命令提示符 (Windows)。
在终端或命令提示符中,粘贴并执行以下命令:ollama run qwq
ollama run qwq
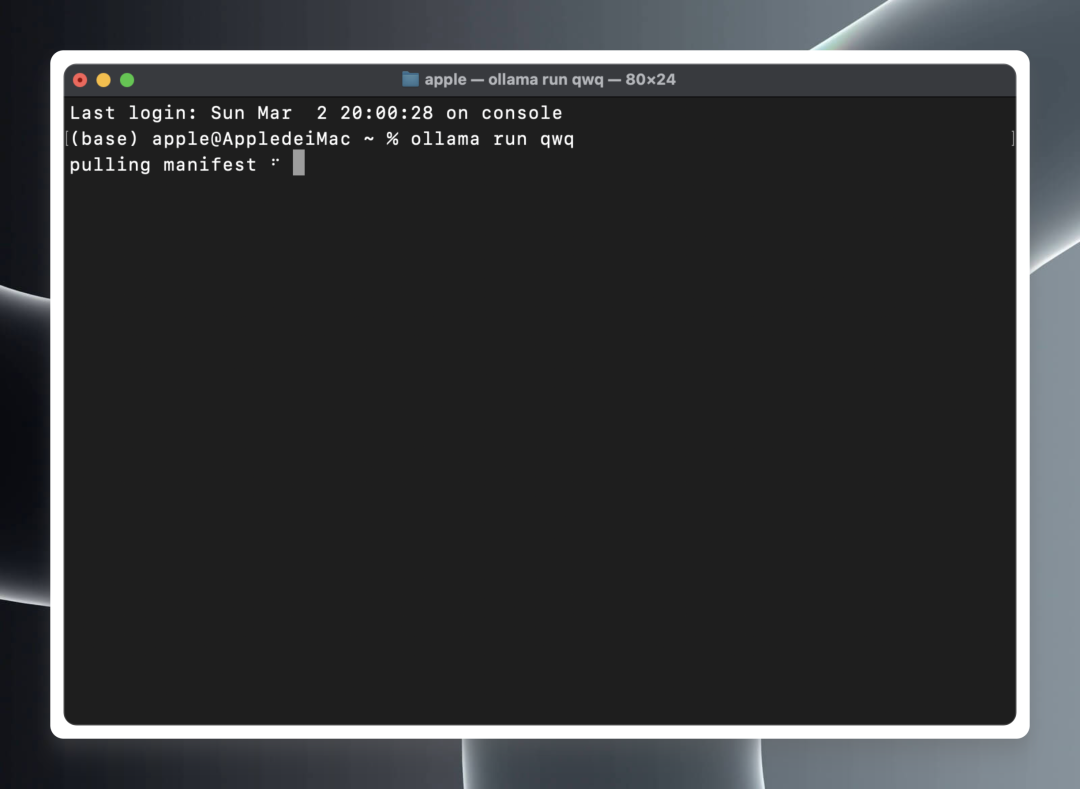
Ollama 将自动开始从云端下载 QwQ-32B 模型文件,并在下载完成后自动启动模型运行环境。
值得一提的是,模型下载过程似乎并不需要用户进行额外的网络配置, 这对于国内用户来说无疑是一个非常友好的特性。 毕竟,接近 20GB 的模型文件,如果下载速度过慢或者需要特殊网络环境,将会大大降低用户的使用体验。
然而,由于 QwQ-32B 模型目前非常热门,下载用户较多,实际下载速度可能会受到一定影响,导致下载时间有所延长,这需要用户耐心等待。
经过一段时间的等待,模型终于下载完成。 笔者在一台配备了 12GB 显存的 RTX3060 桌面级显卡的电脑上,抱着尝试的心态运行了 QwQ-32B 模型,结果令人惊喜: 模型不仅成功加载,而且能够根据用户输入的内容给出较为流畅的回答,更重要的是,整个运行过程没有出现显存溢出的问题。 这意味着,即使是主流级别的显卡,也能够基本满足 QwQ-32B 量化模型的运行需求。

从实际的推理表现来看,QwQ-32B 的能力已经超越了一些被用户戏称为 “智商下线” 的 OpenAI 模型。 这也从侧面印证了 QwQ-32B 在性能上的优越性。
通过 Windows 任务管理器,我们可以实时监测模型运行时的资源占用情况。 结果显示,在模型推理过程中,CPU、内存以及显存均处于高负荷运转状态,这也反映出本地运行大模型对硬件资源的较高要求。
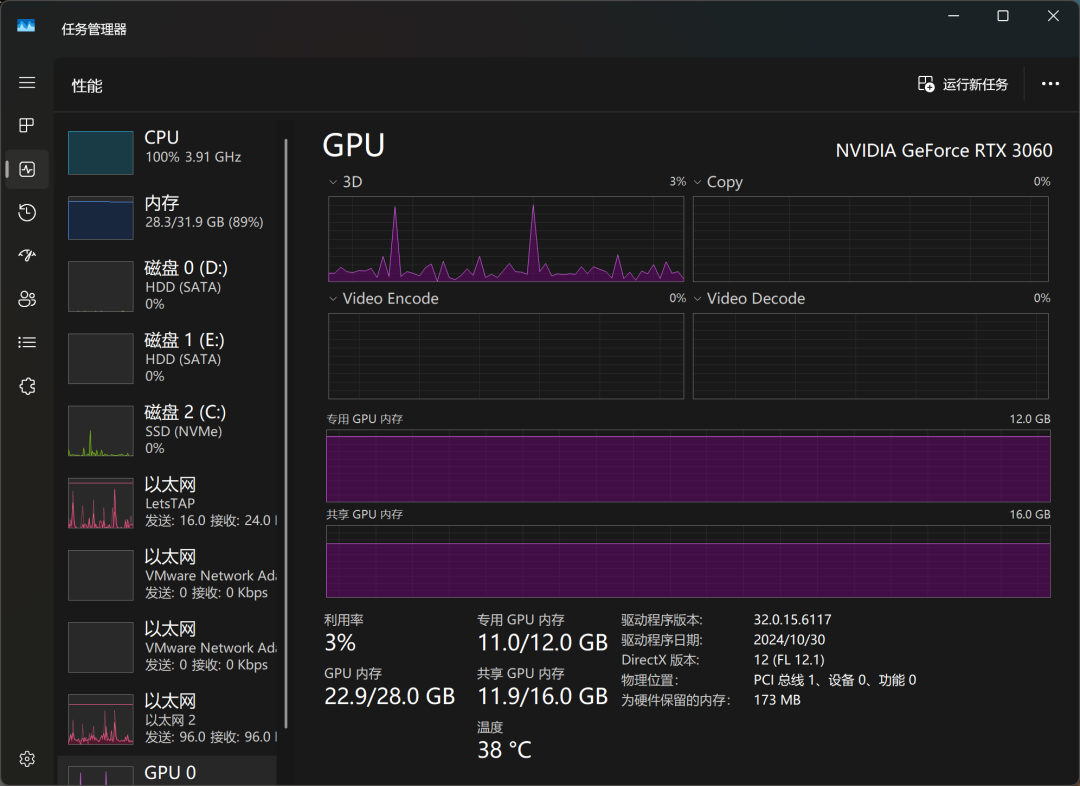
在 RTX3060 显卡上,QwQ-32B 的回答速度大约为 “哒、哒、哒…” 的节奏, 可以满足基本的使用需求,但在响应速度和流畅性方面仍有提升空间。 如果追求更极致的本地模型运行体验,可能需要更高级别的硬件配置。
为了进一步提升模型运行速度,笔者又在一台配备了 RTX3090 顶级显卡的设备上,再次下载并运行了 QwQ-32B 模型。 实验结果表明,更换更高端的显卡后,模型运行速度得到了显著提升,用 “健步如飞” 来形容也毫不为过。 这也再次验证了硬件配置对本地大模型运行体验的重要性。
3. 将 QwQ-32B 集成到客户端
虽然直接在命令行界面与模型进行对话是一种简单直接的方式,但对于需要频繁使用或追求更佳交互体验的用户来说,使用图形化客户端无疑是更方便的选择。 目前市面上已经涌现出许多优秀的 AI 模型客户端软件,此前我们已经介绍过不少,例如 ChatWise。 选择 ChatWise 的主要原因是其界面设计简洁直观,操作逻辑清晰易懂,能够为用户提供良好的使用体验。
下面简要介绍将 QwQ-32B 模型配置到 ChatWise 客户端的步骤。
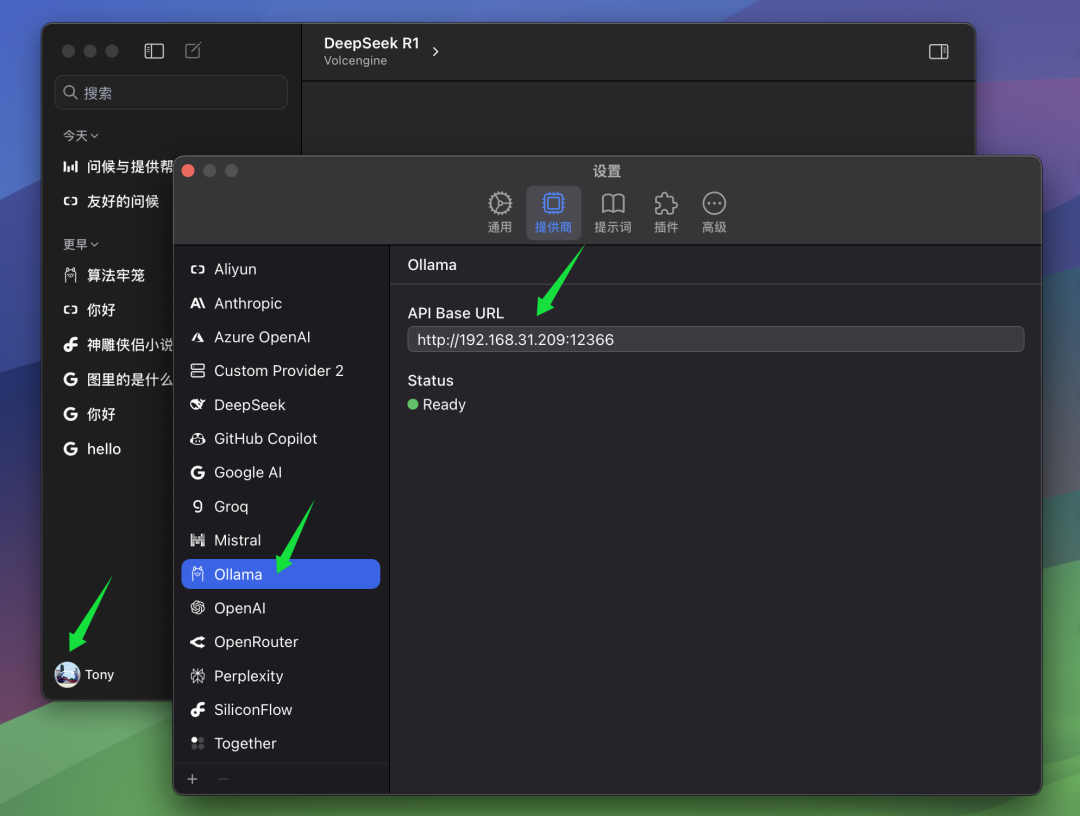
如果您的 ChatWise 客户端和 Ollama 服务运行在同一台计算机上,那么通常情况下,您无需进行任何额外的配置,打开 ChatWise 客户端即可直接使用 QwQ-32B 模型。 大部分用户都属于这种情况,即 Ollama 服务和客户端应用都安装在同一台设备上。
但如果您像笔者一样,将 Ollama 服务安装在另一台电脑上(例如服务器),而 ChatWise 客户端运行在本地电脑上,那么您需要手动修改 ChatWise 的 BaseURL 设置, 以便客户端能够连接到远程 Ollama 服务。 在 BaseURL 设置中,您需要填写运行 Ollama 服务的计算机的 IP 地址,以及您在 Ollama 服务端配置的端口号。 Ollama 默认端口为 13434,如果您没有进行特殊配置,则使用默认端口即可。
完成 BaseURL 配置后,您就可以在 ChatWise 客户端中选择要使用的模型了。
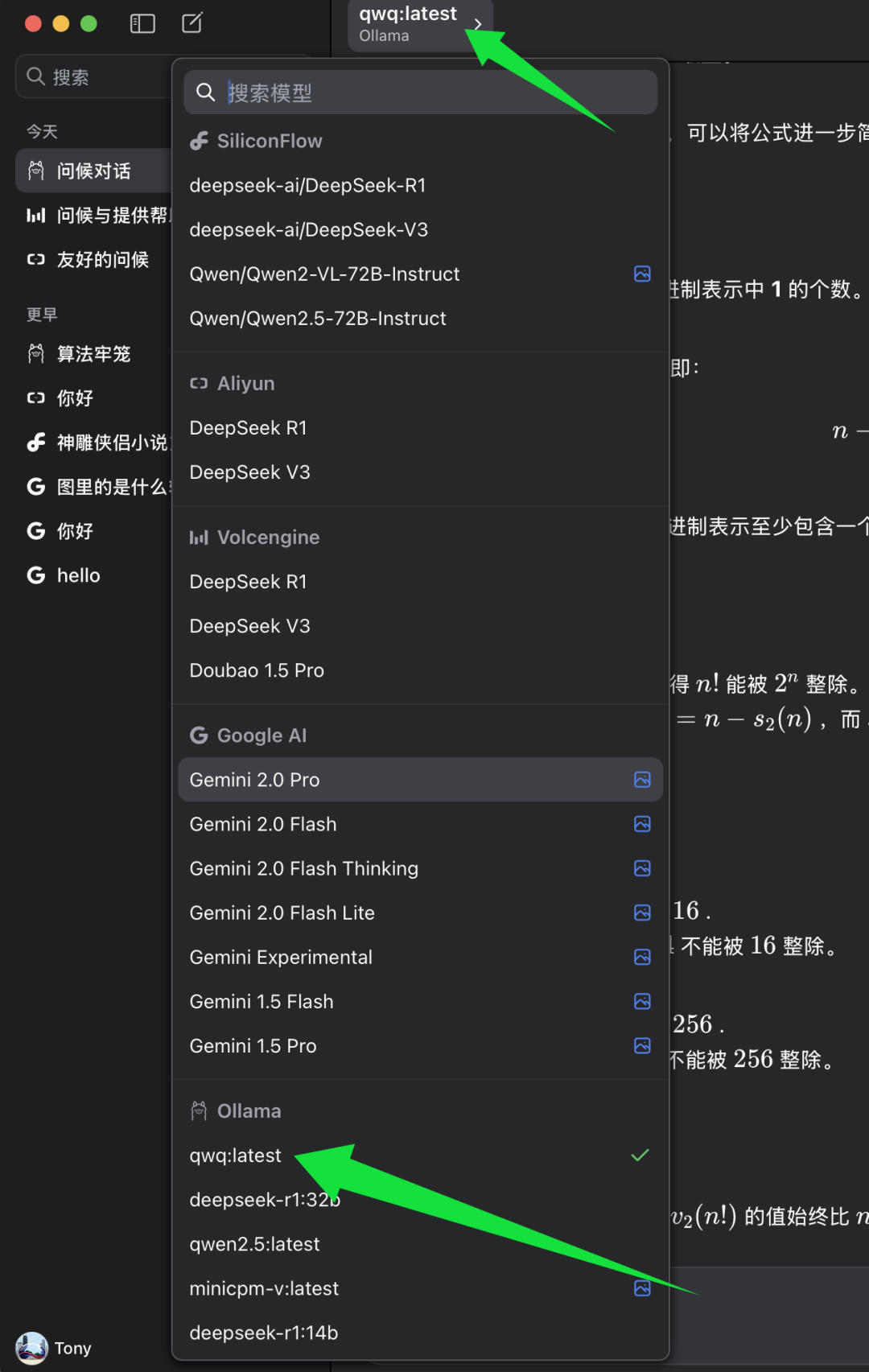
在 ChatWise 的模型选择列表中,找到 Ollama 模型分类,并在其下方选择 qwq:latest。 qwq:latest 代表 QwQ-32B 模型的最新版本,通常也是 4-bit 量化版本。 选择 qwq:latest 后,您就可以在 ChatWise 客户端中开始体验 QwQ-32B 模型的强大功能了。
4. QwQ-32B 模型智力水平测试
为了更客观地评估 QwQ-32B 模型的智力水平,我们采用了一组此前在测试 OpenAI 模型 “降智” 问题时总结出的经典问题。 这组测试题包含四个精心挑选的问题, 经验表明,如果 ChatGPT (特别是 GPT-3 或 GPT-4 模型) 出现用户反馈的 “降智” 情况,则通常难以正确回答这些问题。 因此,这组问题在一定程度上可以作为检验大模型智力水平的参考。
接下来,我们将逐一测试本地运行的 QwQ-32B 模型,观察其是否能够成功解答所有问题。
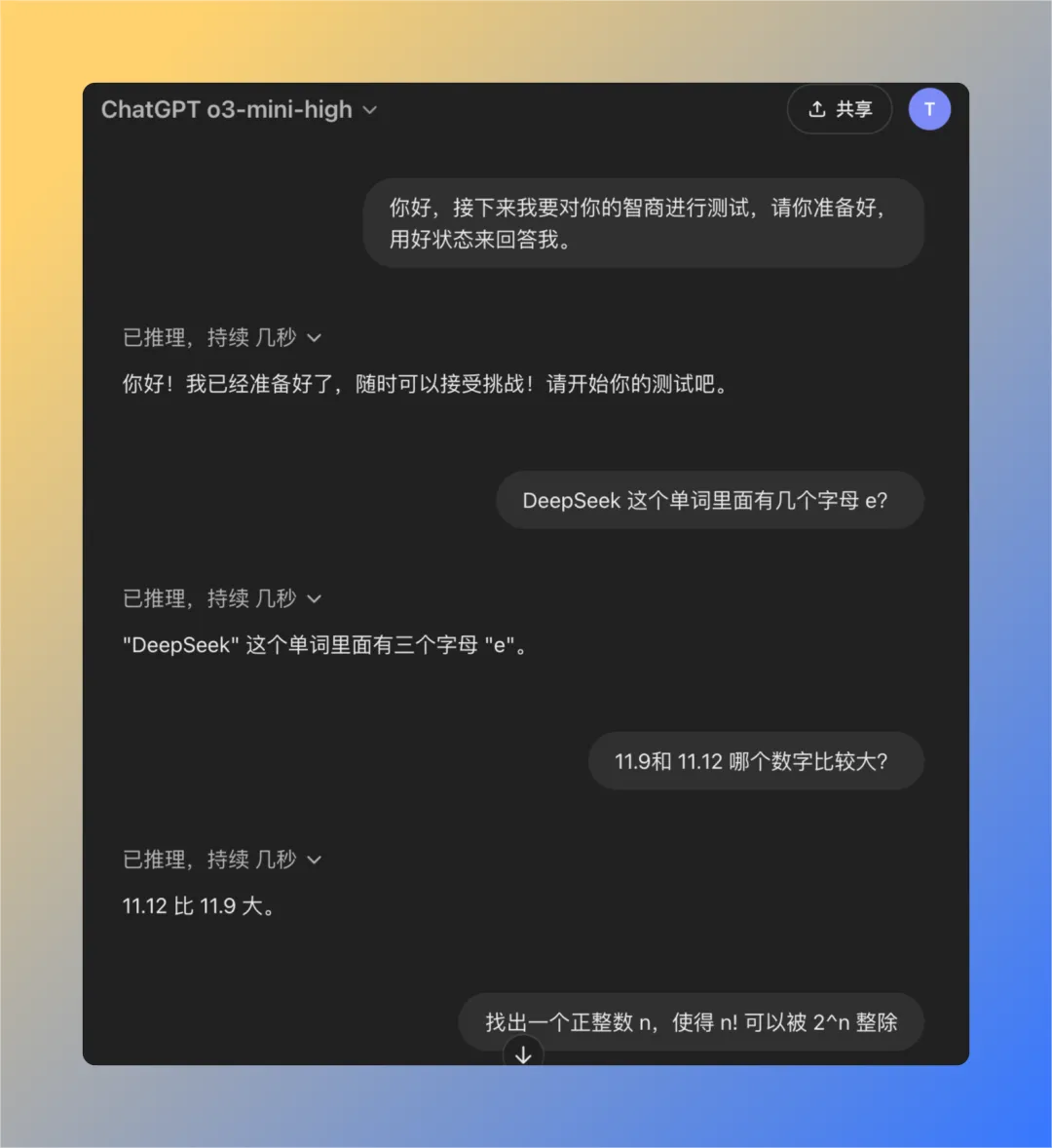
问题 1:deepseek 这个单词里面有几个字母 e?
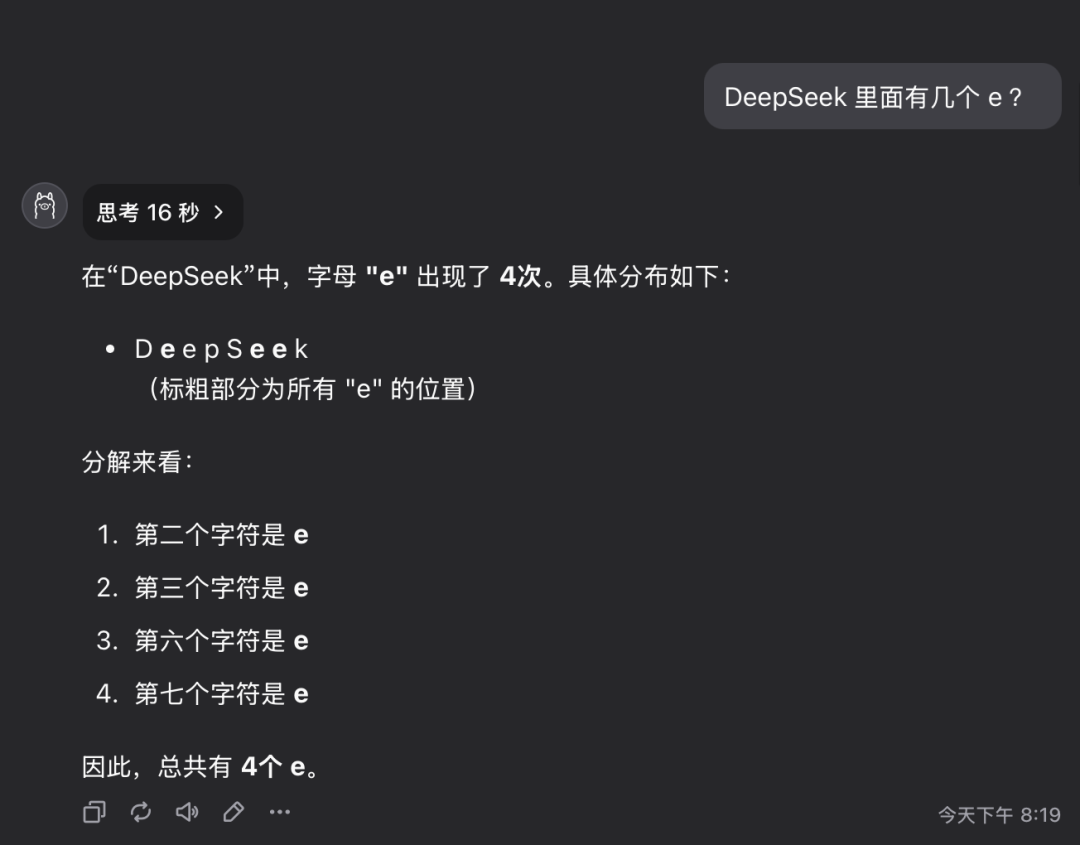
QwQ-32B 模型在 16 秒内给出了正确回答:3个。 回答正确。
这个问题看似简单,但实际上考察的是模型对细节信息的准确理解和提取能力。 令人意外的是,目前仍有相当一部分大型模型无法准确回答此类问题。
问题 2:11.9 和 11.12 哪个数值更大?

QwQ-32B 模型在 47 秒内给出了正确回答:11.12 更大。 回答正确。
这同样是一个看似基础但却十分经典的问题。 很多大型模型在进行简单的数值比较时,也会出现混淆或错误判断的情况, 这反映出模型在基础逻辑推理方面可能存在不足。
问题 3:请找出一个正整数 n,使得 n 的阶乘 (n!) 可以被 2 的 n 次方 (2^n) 整除

QwQ-32B 模型在 121 秒内给出了正确回答:不存在这样的正整数 n。 回答正确。
这个问题的重点并非是找到具体的数值答案,而是考察模型是否具备抽象思维和逻辑推理能力,能否理解问题的本质,并最终得出 “不存在” 这一结论。 QwQ-32B 能够正确解答此题,表明其在逻辑推理方面具备一定的能力。
问题 4: 经典逻辑推理题 - 帽子颜色谜题
“有 5 个人排成一排,他们每人头上戴着一顶帽子,帽子颜色可能是红色或蓝色。 每个人只能看到排在自己前面的人的帽子颜色,但看不到自己头上的帽子颜色。 主持人预先告知大家:“这 5 个人中,至少有一顶红帽子。” 现在,从排在最后面的人开始,依次向前询问每个人:“你是否知道自己帽子是什么颜色?” 每个人只能回答 “是” 或 “否”。 假设第 5 个人回答 “否”,第 4 个人回答 “是”,请问所有可能的帽子颜色分布情况是怎样的?”
相较于前三个问题,这个逻辑推理题的难度明显提升,对模型的逻辑分析和推理能力提出了更高的要求。
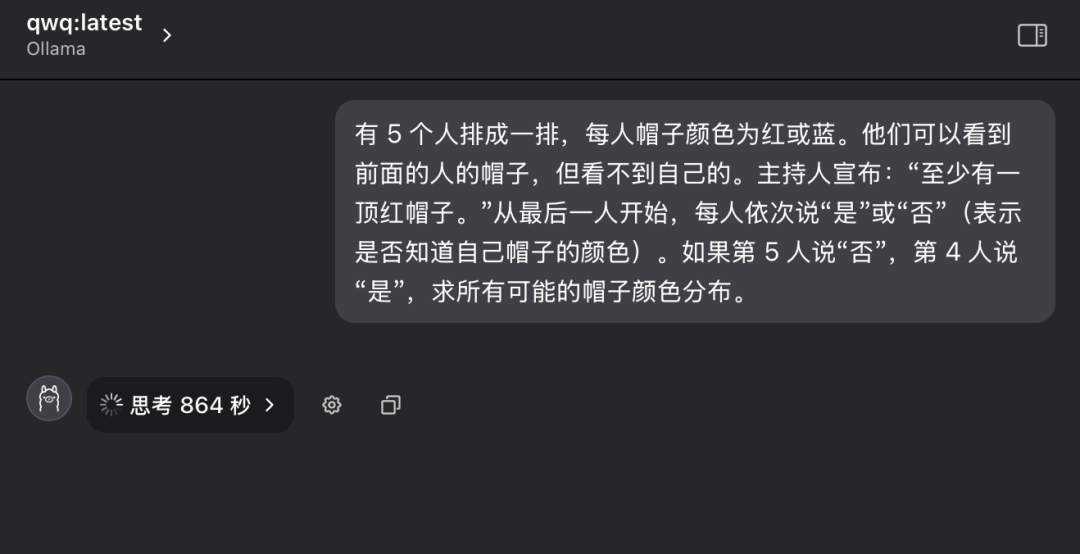
在第一次提问时,QwQ-32B 模型进入了长时间的思考状态, 屏幕上不断闪烁着 “思考中…” 的字样, 仿佛 “大脑” 正在高速运转,甚至让人开始担心硬件是否能够承受如此高强度的计算负载。 考虑到时间和硬件运行状况,在经过十多分钟的等待后,笔者手动中断了模型的思考过程。
随后,笔者重新开启了一个新的对话会话,再次向 QwQ-32B 模型提出相同的问题。

这一次,QwQ-32B 模型最终在 196 秒后给出了完全正确的答案, 并详细解释了推理过程。 回答正确。
通过查看模型的推理过程记录, 可以感受到,尽管 QwQ-32B 的参数规模相对较小,但在面对复杂的逻辑推理问题时,它仍然展现出了非常 “努力” 的思考和分析过程。 模型在后台进行了大量的逻辑运算和可能性推演,最终才得出正确结论。
经过上述一系列严谨而细致的智力测试,我们可以初步得出结论: QwQ-32B 4-bit 量化版本模型已经展现出了令人印象深刻的综合性能,特别是在逻辑推理和知识问答方面, 表现出了超越同级别模型的实力。 由此,我们有理由相信,未经量化的 QwQ-32B 完整版模型,其性能表现无疑将更加卓越, 32B 满血版模型性能测评报告 提供了更全面的性能数据和分析。 因此,我们可以基本判断,阿里巴巴千问团队在 QwQ-32B 模型发布时所做的性能宣传并非言过其实, QwQ-32B 确实是一款非常出色的新型推理模型,它以 320 亿的参数规模,实现了与 6710 亿参数 DeepSeek-R1 模型正面竞争的实力。
国产开源大模型的快速崛起, 充分展现了中国在 AI 技术领域的蓬勃创新活力和巨大发展潜力。
更令人欣喜的是, QwQ-32B 32B 版本模型,仅需一张配备 24GB 显存的显卡即可流畅运行, 并且运行速度相当可观。 要知道,在几年前,要运行如此高性能的大型模型,可能需要数百万元的专业设备投入, 而现在,借助 QwQ-32B 和 Ollama 等技术的进步,用户在一台万元级别的个人电脑上即可实现本地部署和体验。 QwQ-32B 模型的发布,预示着高性能 AI 模型正在加速走向普及化, “AI 普惠” 的时代正在加速到来, 高性能 AI 技术在个人终端设备和各行各业中都将拥有更加广阔的应用前景。
现在,正是行动起来,深入探索和充分利用 QwQ-32B 强大功能的最佳时机! 让我们共同迎接 AI 技术带来的美好未来!
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...