

AI 研究助理兴起:谁能真正帮你做好功课?
信息时代的研究工作,常常意味着在海量数据中跋涉。过去,研究者需要手动搜索、筛选、整理信息,再将关键内容喂给像 ChatGPT 这样的大语言模型进行分析。但随着 OpenAI 推出其 Deep Research 功能,局面开始改变。这类新型 AI 工具承诺能自动化整个研究流程:用户只需提出问题,AI 就能自主搜索网络、分析资料,并生成一份带引用的报告。这背后通常由先进的大语言模型驱动,如 OpenAI 的 o3,它们不仅利用预训练知识,还能主动获取最新信息并执行多步推理。
OpenAI 的尝试迅速引发了行业跟随。2023年3月以来,多家公司纷纷推出了自家的自动化研究工具或 AI 代理(Agent),它们通常被称为 "AI 搜索助理" 或 "深度研究" 工具。这些工具的核心理念相似:利用强大的 AI 模型能力,结合网络搜索,自主执行研究任务并交付成果。

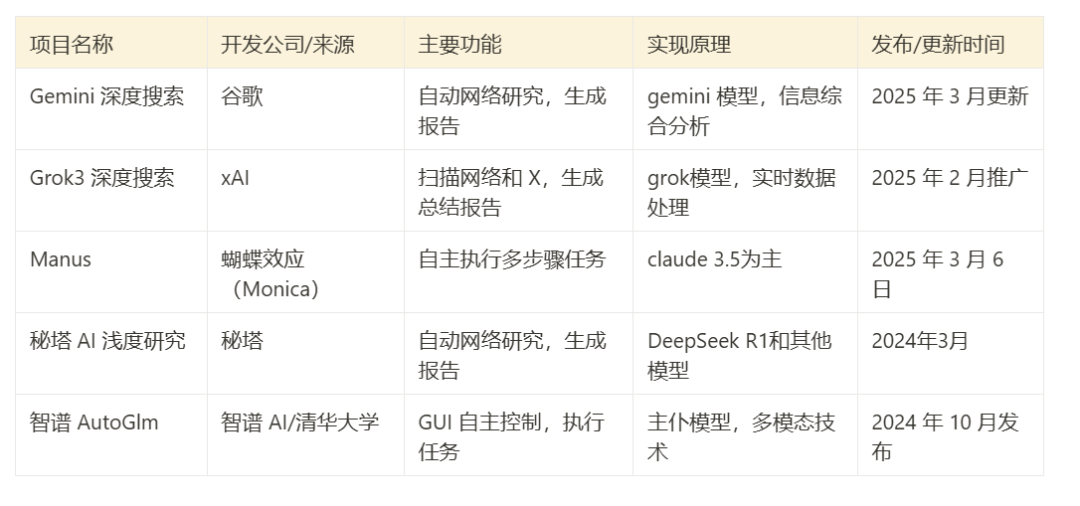
本文将目光投向市面上几款备受关注的此类产品,旨在通过一次实际测试,探究它们的表现差异、能力边界以及各自的最佳适用场景。参与此次对比的工具包括:
- Gemini Deep Search:基于 Google 的 Gemini 系列模型,强调信息综合分析能力。
- Grok 3 Deep Search:利用 xAI 的 Grok 3 模型,设计用于独立执行任务,可能更侧重实时信息。
- Manus:一个支持多种 AI 模型(如 Anthropic 的 Claude 和阿里的 Qwen)的平台,以执行多步骤任务见长。
- Mita AI 浅度研究:结合其 R1 模型进行逻辑框架拆解,并使用自研模型执行网页搜索与整合。
- Zhipu AutoGLM:基于 Zhipu AI 的大语言模型,通过图形用户界面(GUI)模拟用户操作,自主控制数字设备进行信息收集与处理。
为了解这些工具的实际表现,我们向这五款产品提出了同一个相对复杂的研究任务。
对比测试:生成 AI 模型研究报告
任务要求:
根据以下提纲,交付一篇约5000字的 AI 模型研究报告:
- 当代大语言模型概览(如 GPT 系列、Claude、LLaMA、DeepSeek 等)
- 各家模型特点与适用场景对比
- 模型能力边界与局限性分析
- 开源与闭源模型选择策略
- 模型 API 基础使用教程
- 大模型技术原理简明解读
执行情况:
- Gemini Deep Search:耗时 8 分钟,搜索超过 300 个网页。
- Grok 3 Deep Search:耗时 6 分钟,搜索超过 160 个网页。
- Manus:耗时 21 分钟,报告执行了 8 个子任务。
- Mita AI 浅度研究:耗时 7 分钟,搜索超过 300 个网页。
- Zhipu AutoGLM:耗时 16 分钟,搜索 71 个网页。
注: 等待时长和搜索量仅为本次测试的参考数据,实际表现可能因任务复杂度、网络状况和服务器负载而异。
各工具回答摘要:

(图片展示了各工具生成报告的部分截图或摘要)
独立评估:Claude 3.7 的犀利点评
为了获得一个相对客观的第三方视角,我们将这五份生成的报告提交给 Anthropic 的 Claude 3.7 模型进行评估。以下是 Claude 3.7 对各份报告的评价摘要:
Zhipu AutoGLM
报告试图模仿学术论文格式,引用了71个参考文献,但这反而显得内容空洞。语言过于学术化,像是在用华丽辞藻掩盖实质内容的不足。对模型优劣的分析如同复述产品说明,缺乏深度洞察。
Manus
报告走向了另一个极端,以“面向决策者”为名,过度简化了复杂的技术问题,将深度分析变成了肤浅的营销文案。如同用儿童读物讲解量子物理,既不深入也不够准确。
Gemini Deep Search
报告采用了学术写作风格,但大量引用标记干扰了阅读流畅性。行文冗长,解释简单概念也占用过多篇幅,并未增加实质信息。声称面向非技术人员,却仍充斥未解释的专业术语,目标未能达成。
Grok 3 Deep Search
提供了简明和详细两个版本是其特点,但也暴露了内容一致性问题。简明版过于简化,详细版中的一些预测(如对2025年的预测)缺乏充分的论证基础和必要的假设说明,显得有些投机。
Mita AI 浅度研究
大量使用表格来结构化信息,提高了信息获取效率,但过度依赖表格和分隔符导致内容呈现机械化,缺乏叙事连贯性和深度。技术解释与实际应用场景联系不足,商业成本分析也缺乏针对不同规模企业的差异化考量,建议显得“一刀切”。
Claude 3.7 的总体看法:
这五份报告都试图用不同的“包装”来掩盖内容上的短板。无论是学术风、商业风还是技术风,似乎都未能触及核心——对技术本质的深入理解和对实际应用的深度思考。例如,报告中对 DeepSeek 的过度关注可能反映了行业对新技术的普遍追捧,而对数据隐私、伦理合规等关键问题的轻描淡写则暴露了分析视角的局限。一份优秀的技术调研报告应提供真知灼见和务实分析,而非玩弄文字游戏。从这个标准看,这五份报告均有提升空间。
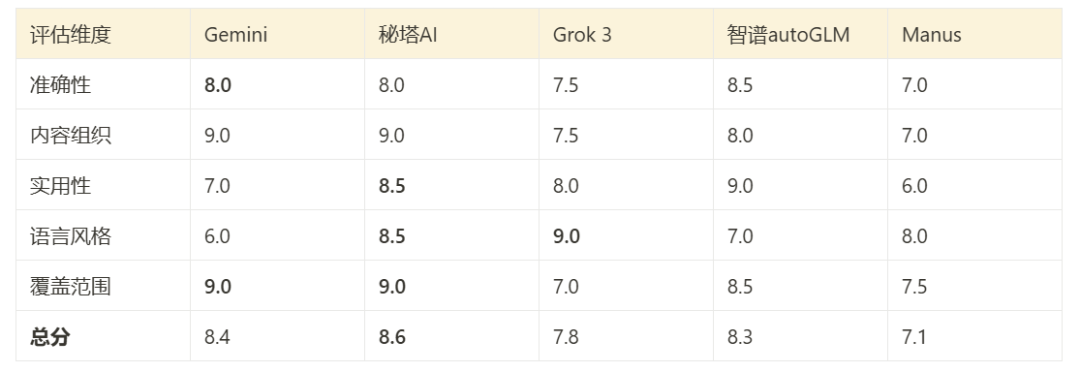
综合表现与评分
基于 Claude 3.7 的评价和对报告内容的直接审阅,可以对各工具在本次测试中的表现进行一个综合评估:
(图片展示了基于测试结果的综合打分图)
- Gemini Deep Search:内容组织较好,覆盖范围广,多语言支持是其优势。
- Mita AI 浅度研究:表现全面且平衡,在技术深度和可读性之间结合得较好。
- Grok 3 Deep Search:语言风格灵活(双版本),实用性导向较强。
- Zhipu AutoGLM:技术内容准确性较高,但可读性对非专业人士有限。
- Manus:报告简洁易懂,但牺牲了分析深度。
如何选择:不同场景下的使用建议
基于本次测试和各工具的特点,以下是一些选择建议:
搜索特点概览:
- Gemini Deep Search:搜索范围广阔,擅长整合全球多语言资源,但在理解深度中文内容方面可能不如本土化产品。
- Grok 3 Deep Search:实时性强,尤其在商业信息和新闻方面表现突出,但技术内容的深度相对较弱。
- Zhipu AutoGLM:引用的参考文献质量较高,对技术概念理解深入,但搜索范围相对聚焦。
- Mita AI 浅度研究:中英文信息整合能力强,对专业领域的覆盖较全面,结构化信息提取准确。
- Manus:(本次测试侧重报告生成,其搜索特点未充分展现,但平台设计支持多源信息整合和复杂工作流)。
搜索与研究能力初步排名 (基于本次测试):
- Mita AI 浅度研究:在专业领域的深度搜索、中英文双语处理方面表现突出。
- Gemini Deep Search:通用性最强,全球资源覆盖面广。
- Zhipu AutoGLM:处理中文技术文献和深度理解方面有优势。
- Grok 3 Deep Search:在获取实时商业信息和新闻方面领先。
- Manus:强项可能在于任务执行的灵活性和多模型调用,而非单纯的搜索排名。
场景化推荐:
- 学术研究:优先考虑 Zhipu AutoGLM (参考文献质量高),其次是 Mita AI (专业领域覆盖)。
- 商业分析:优先考虑 Grok 3 (实时性、商业信息),其次是 Gemini (全球视野)。
- 技术开发:优先考虑 Mita AI (文档理解、结构化提取),其次是 Zhipu AutoGLM (技术深度)。
- 日常信息获取/通用研究:优先考虑 Gemini (覆盖广),其次是 Grok 3 (时效性)。
- 深度中文内容研究:优先考虑 Zhipu AutoGLM 或 Mita AI,它们对本土语言和语境的理解更优。
重要提示:
- 交叉验证:对于关键信息或重要决策,强烈建议使用至少两款不同的工具进行对比验证,以确保信息的准确性和完整性。
- 任务匹配:没有万能工具。选择哪款产品,很大程度上取决于具体的研究任务、所需信息的类型(实时 vs. 深度,技术 vs. 商业)以及对报告格式和深度的要求。
- 测试局限性:本次对比仅基于单一任务。像 Manus 这样强调任务流和多格式交付能力的工具,其优势可能在其他类型的任务中才能完全体现。此外,用户界面、成本、API 集成能力等也是实际选择中需要考虑的因素。
这些 AI 研究助理工具无疑代表了信息获取和分析方式的未来趋势。虽然目前各有优劣,但它们的发展速度很快,值得持续关注。选择合适的工具,并学会有效地使用它们,将大大提升研究和决策的效率。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...