

这幅图像融合了中国古典艺术与现代元素,灵感源自北宋画家王希孟的《千里江山图》。画面展现了一幅壮丽的山水长卷,青绿山水技法使得山峦起伏、江河浩渺,色彩层次丰富,细节精致入微。在这如诗如画的江山美景之上,巧妙地浮现出一个墨色淋漓的毛笔字“CogView4”,字体苍劲有力,墨迹浓淡相宜,仿佛是古代文人墨客在欣赏美景时即兴挥毫留下的印记。“CogView4”这几个字与周围的山水景致相得益彰,既不突兀也不失和谐,反而增添了一种跨越时空的对话感。整个画面既有古典山水的韵味,又融入了现代科技感的元素,呈现出一种独特的艺术张力,让人在欣赏传统美学的同时,也能感受到现代创意的碰撞与融合。
今天我们正式发布并开源了最新的图像生成模型——CogView4。
该模型具备较强的复杂语义对齐和指令跟随能力,支持任意长度的中英双语输入,能够生成在给定范围内的任意分辨率图像,同时具备较强的文字生成能力。该模型也是首个遵循 Apache 2.0协议开源的图像生成模型。
一、评测
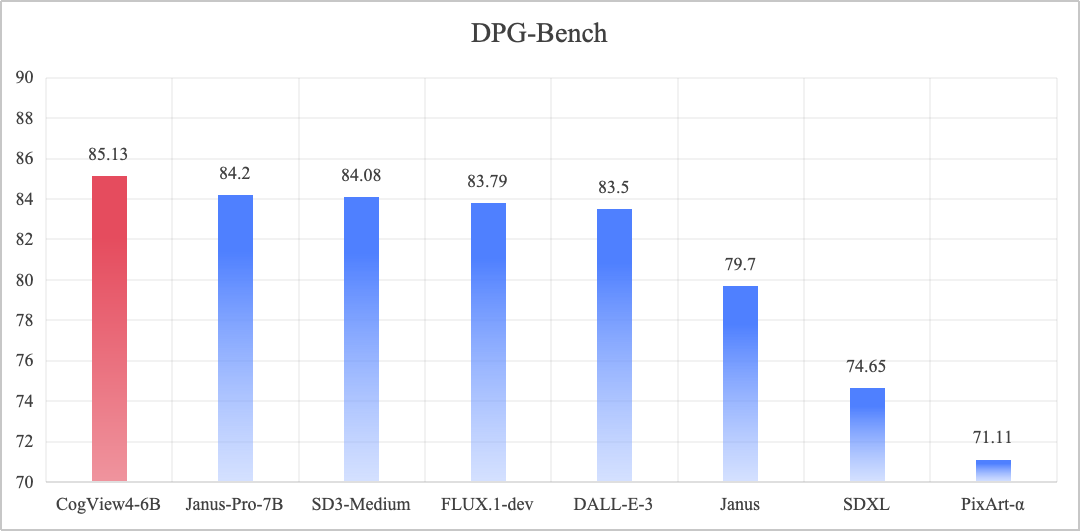
DPG-Bench(Dense Prompt Graph Benchmark)是一个用于评估文本到图像生成模型的基准测试,主要关注模型在复杂语义对齐和指令跟随能力方面的表现。
CogView4-6B,其在 DPG-Bench基准测试中的综合评分排名第一,在开源文生图模型中达到 SOTA。
二、任意长度&任意分辨率
CogView4模型实现了任意长度的文本描述和任意分辨率图像的混合训练范式。
1、图像位置编码
CogView4采用二维旋转位置编码(2D RoPE)来建模图像的位置信息,并通过内插位置编码的方式支持不同分辨率的图像生成任务。
2、扩散生成建模
模型采用Flow-matching方案进行扩散生成建模,并结合参数化的线性动态噪声规划,以适应不同分辨率图像的信噪比需求。
3、架构设计
在DiT模型架构上,CogView4延续了上一代的Share-param DiT架构,并为文本和图像模态分别设计独立的自适应LayerNorm层,以实现模态间的高效适配。
4、多阶段训练
CogView4采用多阶段训练策略,包括基础分辨率训练、泛分辨率训练、高质量数据微调以及人类偏好对齐训练。这种分阶段训练方式不仅覆盖了广泛的图像分布,还确保生成的图像具有高美感并符合人类偏好。
5、训练框架优化
从文本角度,CogView4突破了传统固定token长度的限制,允许更高的token上限,并显著减少了训练过程中的文本token冗余。当训练caption的平均长度在200-300 token时,与固定512 token的传统方案相比,CogView4减少了约50%的token冗余,并在模型递进训练阶段实现了5%-30%的效率提升。
从图像角度,混合分辨率训练使模型能够支持较大范围内的任意分辨率生成,极大地提升了创作的自由度。目标分辨率只需满足以下条件:
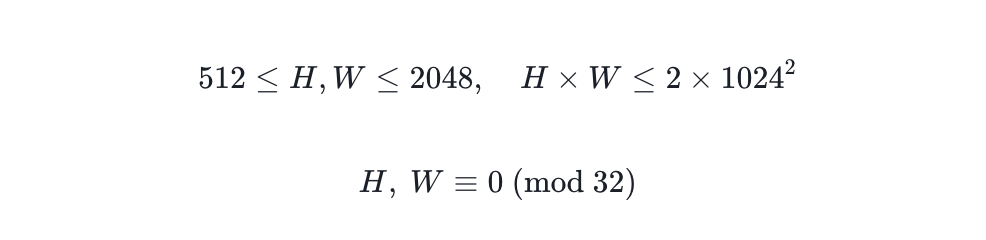
这两点可以极大提高创作的自由度。
示例:超长故事(四格漫画)

公主:人类女性,美丽优雅,穿着华丽的公主服饰,被囚禁在怪兽的老巢。
国王:人类男性,威严而仁慈,穿着华丽的王者服饰,坐在王国的宝座上。
火焰龙:怪兽,全身覆盖着火焰般的鳞片,口吐火焰,体型庞大。
黑暗魔王:怪兽,体型巨大,全身笼罩在黑暗中,拥有强大的魔法力量。
Scene 1: 小明踏上征程
创建一个动漫风格的场景,背景是壮丽的王国庭院。场景中的主要角色是小明(人类男孩,拥有一颗勇敢的心,手持宝剑,穿着简易的战士服装),他正以踏上征程的姿势展现。包括庭院中的花草和远处城堡的细节,晨曦的光照传达出勇敢和决心。质量:杰作,最佳质量,超详细,4k
Scene 2: 小明战胜火焰龙
创建一个动漫风格的场景,背景是炽热的火山口。场景中的主要角色是小明(人类男孩,拥有一颗勇敢的心,手持宝剑,穿着简易的战士服装),他正处于战胜火焰龙的瞬间。包括火山口的岩石和熔岩的细节,火红的光照传达出激烈和勇气。质量:杰作,最佳质量,超详细,4k
Scene 3: 小明与黑暗魔王激战
创建一个动漫风格的场景,背景是阴暗的怪兽老巢。场景中的主要角色是小明(人类男孩,拥有一颗勇敢的心,手持宝剑,穿着简易的战士服装),他正处于与黑暗魔王激战的场景中。包括老巢的黑暗和魔法能量的细节,阴沉的光照传达出激烈和紧张。质量:杰作,最佳质量,超详细,4k
Scene 4: 小明救出公主
创建一个动漫风格的场景,背景是荒废的城堡内部。场景中的主要角色是小明(人类男孩,拥有一颗勇敢的心,手持宝剑,穿着简易的战士服装)和公主(人类女性,美丽优雅,穿着华丽的公主服饰),他们正处于小明救出公主的温馨场景中。包括城堡内部废墟和昏暗光线的细节,温柔的光照传达出感动和救赎。质量:杰作,最佳质量,超详细,4k
三、支持中英文
在技术实现上,CogView4将文本编码器从纯英文的T5 encoder 换为具备双语能力的GLM-4 encoder,并通过中英双语图文对进行训练,使CogView4模型具备双语提示词输入能力。
目前来看,CogView4 是首个支持中英双语提示词输入的开源文生图模型,尤其擅长理解和遵循中文提示词,并能在画面中生成汉字。这两点特性更加适合国内广告、短视频等领域广泛的创意需求。

四、Apache协议
CogView4-6B模型支持Apache2.0协议,后续会陆续增加ControlNet、ComfyUI等生态支持,全套的微调工具包也即将推出。
模型仓库:
https://huggingface.co/THUDM/CogView4-6B
https://modelscope.cn/models/ZhipuAI/CogView4-6B
最新的 CogView4 模型将于3月13日上线智谱清言(chatglm.cn)。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...