

在AI的快速发展中,数字人(Digital Humans)已经逐渐成熟,可以低成本的快速生成。因广泛的商业应用场景,受到大家的关注。无论是在虚拟现实(VR)、增强现实(AR)还是影视制作、游戏开发、品牌宣传,数字人都发挥着重要作用。
广义上数字人有3D建模(包含动作捕捉)数字人、静态2D形象数字人(含真人)、真人换脸类数字人。
本文主要介绍个人形象克隆形象类数字人,属于静态2D形象数字人,包含三个基本功能点:真人形象、语音克隆、口型同步。
注1:部分项目不包含语音生成(克隆)部分,这并不是重点,请可单独部署,市场中有很多优秀的AI语音克隆项目。
注2:目前2D静态数字人质量差异主要在口型同步,以及“视频动作”是否自然。你可以尝试单独优化口型同步节点。
注3:换脸+克隆声音也是快速生成数字人的方法,适合维持公共发言人形象、声音不变,不包含在以下方案中。先进的视频换脸普技术普及后存在风险,因此不介绍。
AIGCPanel:开源克隆数字人整合系统,一键部署免费数字人客户端
AigcPanel是一款面向所有用户的一站式AI数字人制作系统,采用electron+vue3+typescript技术栈开发,支持Windows系统一键部署。系统设计以用户友好为核心,即使是技术基础薄弱的用户也能轻松掌握。主要功能包括视频数字人合成、语音合成、语音克隆等,并提供完善的本地模型管理功能。系统支持多语言界面(包含简体中文和英语),集成了 MuseTalk 、 cosyvoice 等多个成熟模型的一键启动包。特别值得一提的是,系统在视频合成方面支持视频画面和声音的换口型匹配技术,在语音合成方面提供丰富的声音参数设置选项。作为一个开源项目,AigcPanel基于AGPL-3.0协议发布,同时强调合规使用,明确禁止用于任何违法违规业务。

DUIX:实时互动的智能数字人,支持多平台一键部署
DUIX(Dialogue User Interface System)是由硅基智能创建的AI驱动的数字人交互平台。通过开源数字人交互功能,开发者可以轻松集成大规模模型、自动语音识别(ASR)和文本转语音(TTS)功能,实现与数字人的实时交互。DUIX支持在Android和iOS等多个平台上一键部署,使每个开发者都能轻松创建智能和个性化的数字人代理,并将其应用于各个行业。该平台具有低部署成本、低网络依赖性和多样化功能,能够满足视频、媒体、客户服务、金融、广播电视等多个行业的需求。

EchoMimic:音频驱动的逼真肖像动画
EchoMimic 是一个开源项目,旨在通过音频驱动生成逼真的肖像动画。该项目由蚂蚁集团的终端技术部门开发,利用可编辑的标志点条件,结合音频和面部标志点生成动态的肖像视频。EchoMimic 在多个公共数据集和自有数据集上进行了全面比较,展示了其在定量和定性评估中的优越性能。
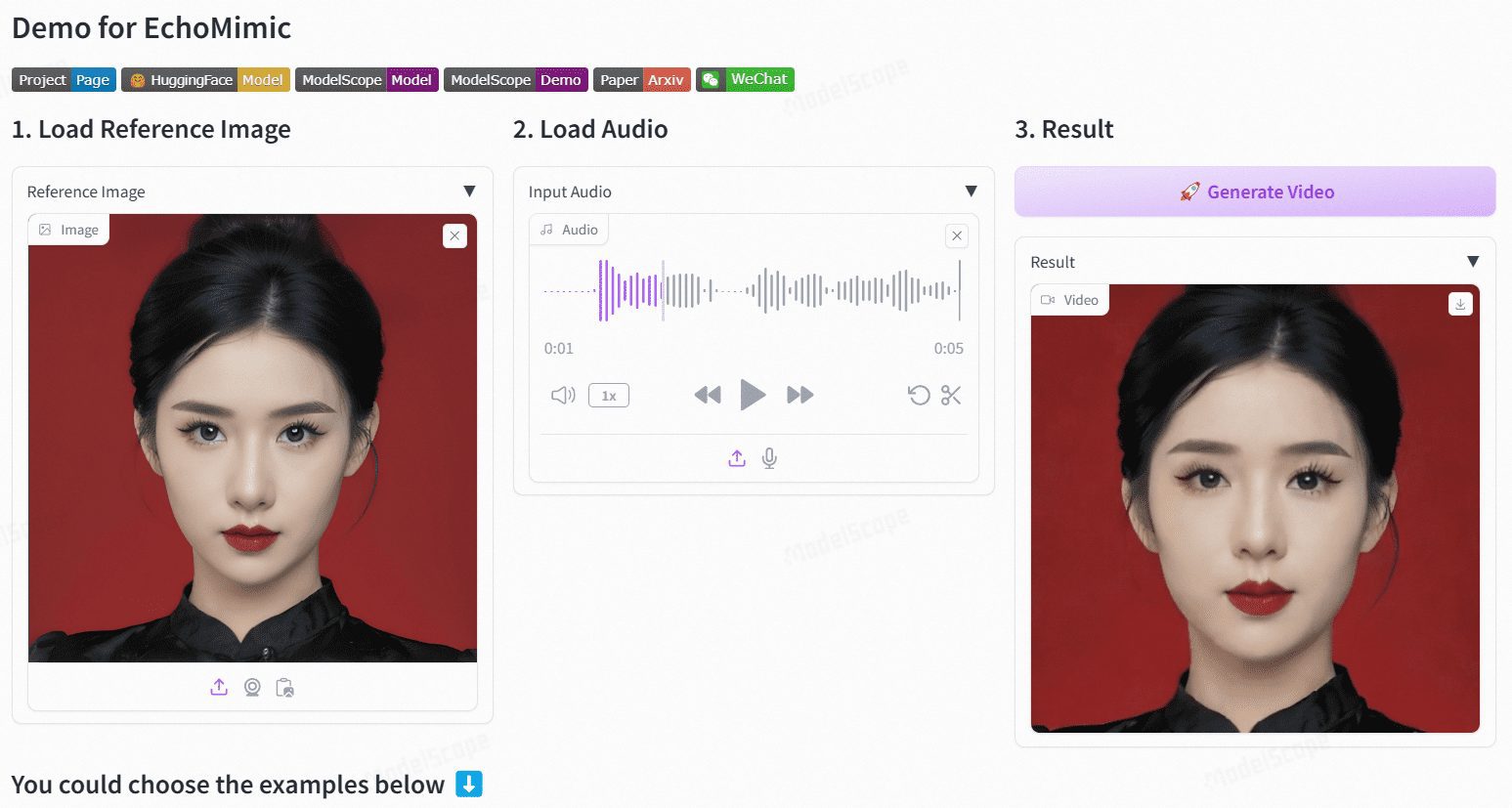
Sonic:全新数字人开源方案,音频驱动生成面部表情生动的数字人口播视频
Sonic 是一个专注于全球音频感知的创新平台,旨在通过音频驱动生成生动的肖像动画。该平台由腾讯和浙江大学的研究团队开发,利用音频信息来控制面部表情和头部运动,从而生成自然流畅的动画视频。Sonic 的核心技术包括上下文增强音频学习、运动解耦控制器和时间感知位置移位融合模块。这些技术使得 Sonic 能够在不同风格的图像和各种类型的音频输入下,生成稳定且逼真的长视频。
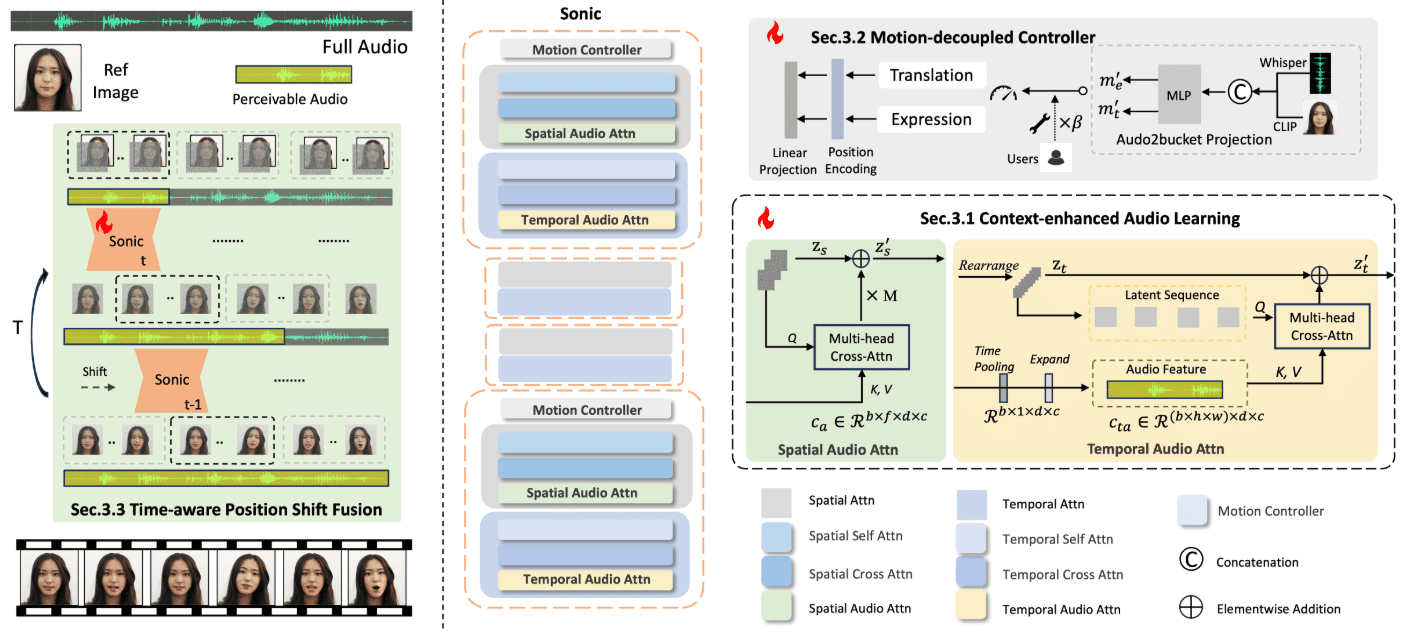
Hallo2:音频驱动生成口型/表情同步的肖像视频(含Windows一键安装)
Hallo2 是由复旦大学和百度联合开发的一个开源项目,旨在通过音频驱动生成高分辨率的人像动画。该项目利用先进的生成对抗网络(GAN)和时间对齐技术,实现了4K分辨率和长达1小时的视频生成。Hallo2 还支持通过文本提示增强生成内容的多样性和可控性。
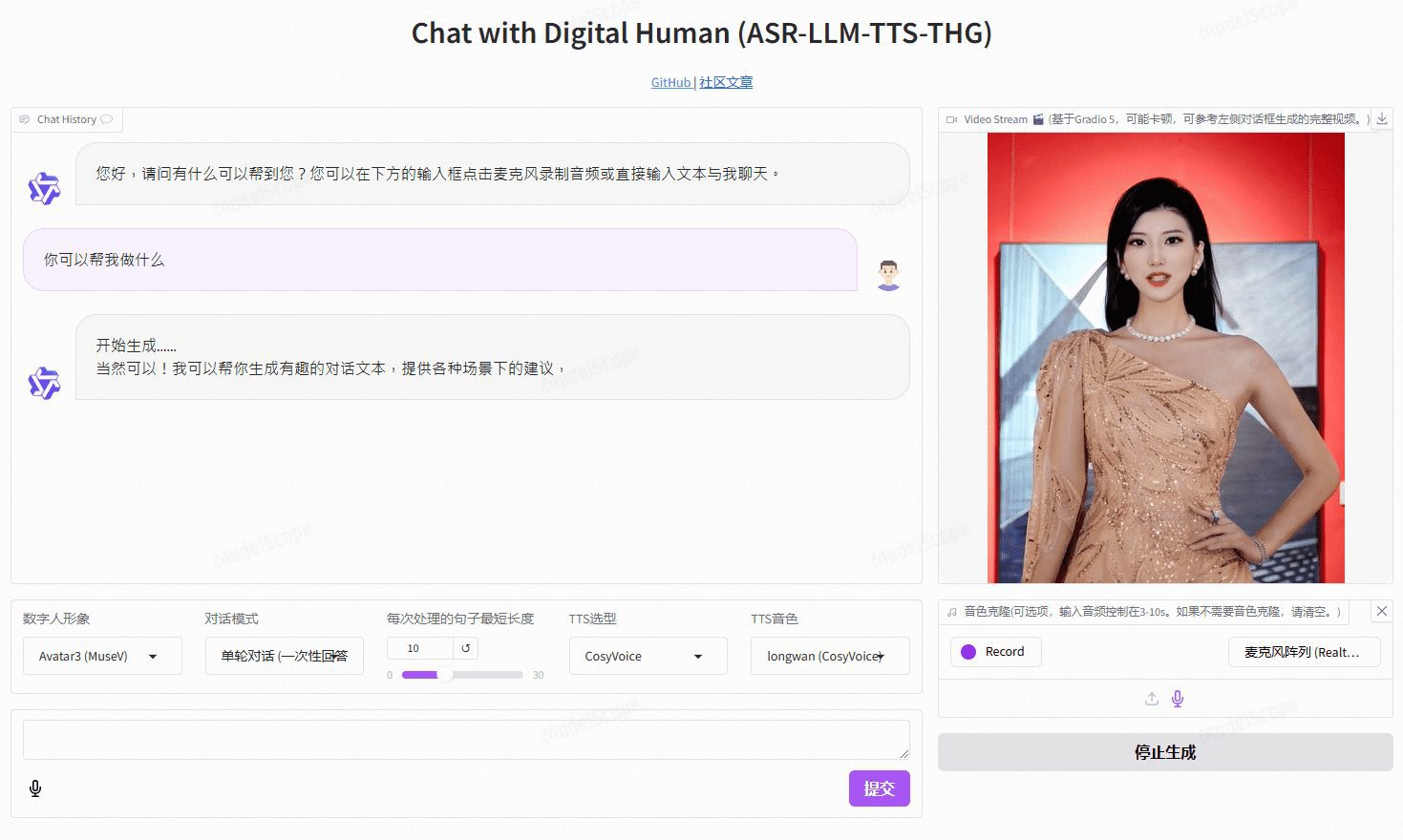
VideoChat:自定义形象和音色克隆的实时语音交互数字人,支持端到端语音方案和级联方案
VideoChat 是一个基于开源技术的实时语音交互数字人项目,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。该项目允许用户自定义数字人的形象与音色,并支持音色克隆及唇形同步,支持视频流输出,首包延迟低至3秒。用户可以通过在线demo体验其功能,或通过详细的技术文档进行本地部署和使用。
TalkingAvatar:创建和编辑AI虚拟形象视频平台,基于本地算力Windows客户端
TalkingAvatar 是一个领先的AI虚拟形象平台,提供完整AI数字人解决方案。提供用户创建、编辑和个性化视频内容的革命性方式。通过先进的AI技术,用户可以轻松重写视频、克隆语音、同步唇形,并创建自定义视频。无论是重新配音现有视频还是从头开始创建新故事,TalkingAvatar 都能满足您的需求。

SadTalker:让照片说话|嘴型同步音频|合成口型同步视频|免费数字人
SadTalker是一个开源工具,能够将单张静态人像照片和音频文件结合,创造出逼真的说话头像视频,适用于个性化信息、教育内容等多种场景。革命性地使用3D建模技术,如ExpNet和PoseVAE,优秀地捕获细微的面部表情和头部动作。用户可以在个人项目和商业项目中使用SadTalker技术,例如信息传递、教学或市场营销。

AniPortrait:音频驱动图片或视频动作生成逼真的数字人讲话视频
AniPortrait是一个由音频驱动生成逼真的肖像动画的创新框架。该项目由腾讯游戏知己实验室的华为伟、杨泽俊和王志声开发。AniPortrait能够通过音频和参考肖像图像生成高质量的动画,甚至可以提供视频进行面部重现。通过使用先进的3D中间表示和2D面部动画技术,该框架能够生成自然流畅的动画效果,适用于影视制作、虚拟主播和数字人等多种应用场景。

MuseV+Muse Talk:完整数字人视频生成框架|人像转视频|姿态转视频|唇形同步
MuseV是一个GitHub上的公共项目,旨在实现无限长度和高保真度的虚拟人视频生成。它基于扩散技术,并提供了Image2Video、Text2Image2Video、Video2Video等多种功能。提供了模型结构、使用案例、快速开始指南、推理脚本和致谢等详细信息。

DreamTalk:使用一张头像图片即可生成表情丰富的说话视频
DreamTalk是一个扩散模型驱动的表情说话头生成框架,由清华大学、阿里巴巴集团和华中科技大学联合开发。主要由降噪网络、风格感知嘴唇专家和风格预测器三部分构成,能够基于音频输入生成多样而真实的说话头像。该框架能处理多种语言和噪声音频,提供高质量的面部运动和准确的嘴型同步。

Translation Starter:开源视频内容翻译同步工具|语言转换|唇形同步
Translation Starter是一个由Sync Labs开发的开源项目,旨在帮助开发者快速集成视频内容的多语言支持。它提供必要的API和文档,以便开发者轻松创建需要视频翻译与唇动同步的应用程序。其基于强大的AI技术,如Sync Lab的完美唇形同步、Open AI的Whisper翻译技术及Eleven Labs的声音合成。

© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...