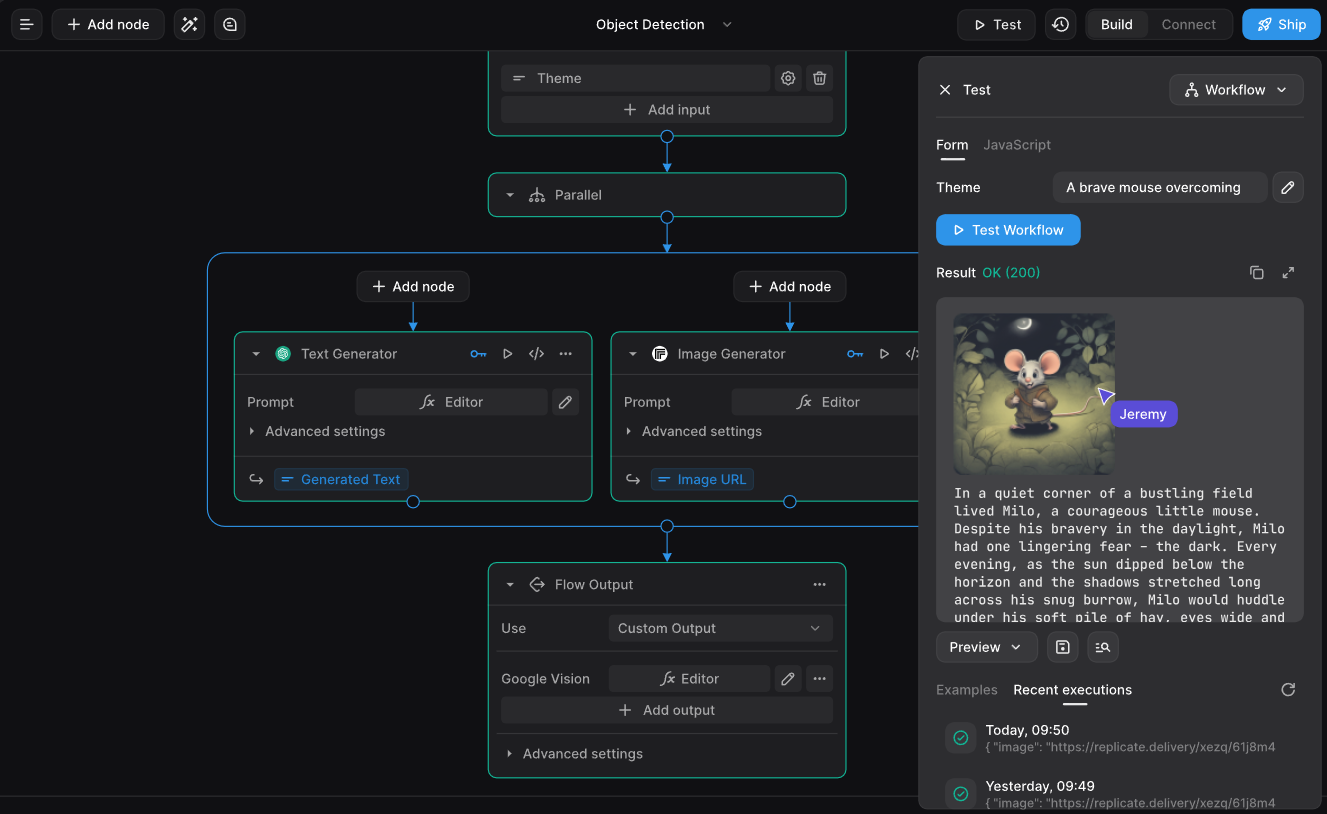

通义DeepResearch是什么
通义DeepResearch(Tongyi DeepResearch)是阿里巴巴推出的开源智能体,专为深度信息检索和复杂任务推理设计,具备300亿参数,支持多种推理模式,包括ReAct模式和深度模式,后者通过迭代研究范式显著提升复杂推理能力。通义DeepResearch用全流程合成数据方案,能自动生成高质量数据集,无需人工干预,突破能力上限。通义DeepResearch训练流程包括持续预训练、监督微调和强化学习,形成完整的端到端训练链路。通义DeepResearch已在多个领域成功应用,如高德地图的AI出行Agent和法律领域的“通义法睿”,展现出强大的实用性和价值。
通义DeepResearch的功能特色
- 深度信息检索:支持处理长周期、多步骤的复杂信息检索任务,适用于学术研究、市场分析等场景。
- 多模式推理:支持ReAct模式和深度模式,后者通过迭代研究范式(IterResearch)提升复杂推理能力。
- 数据自动生成:基于全流程合成数据方案,无需人工干预即可生成高质量数据集,突破智能体能力上限。
- 强化学习优化:通过定制化的强化学习算法,确保智能体的行为与高阶目标保持一致,提升模型在动态环境中的适应性和稳定性。
- 应用赋能:已成功应用于多个实际场景,如高德地图的AI出行Agent和法律领域的“通义法睿”,展现出强大的实用性和价值。
通义DeepResearch的核心优势
- 强大的推理能力:通过迭代研究范式(IterResearch),将复杂任务分解为多个研究回合,逐步精简工作区并动态重构,有效提升复杂推理和决策的质量。
- 全流程合成数据:无需人工干预,自动生成高质量数据集,支持从预训练到微调再到强化学习的完整训练链路,突破了智能体的能力上限。
- 端到端强化学习:采用定制化的强化学习算法,确保智能体的行为与高阶目标保持一致,提升模型在动态环境中的适应性和稳定性,同时避免训练过程中的不稳定性和过早收敛问题。
- 高效的数据管理:在训练动态的指导下实时优化数据,通过全自动数据合成和数据漏斗动态调整训练集,确保训练的稳定性和性能提升。
通义DeepResearch的官网是什么
- 项目官网:https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
- Github仓库:https://github.com/Alibaba-NLP/DeepResearch
- HuggingFace模型库:https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
- arXiv技术论文:https://arxiv.org/pdf/2509.13310
通义DeepResearch的适用人群
- 科研人员:帮助科研人员高效完成复杂的学术研究任务,提升研究效率。
- 企业分析师:为企业提供竞争对手分析、行业趋势报告等,助力企业制定精准的市场策略,是企业分析师的得力助手。
- 法律从业者:在法律领域,如“通义法睿”应用,自动检索法条、类案和裁判文书,为法律从业者提供强大的生产力工具。
- 数据科学家:通过全流程合成数据方案和端到端强化学习,为数据科学家提供了强大的工具,用于生成高质量数据集和优化模型训练。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...