

SkillOpt是什么
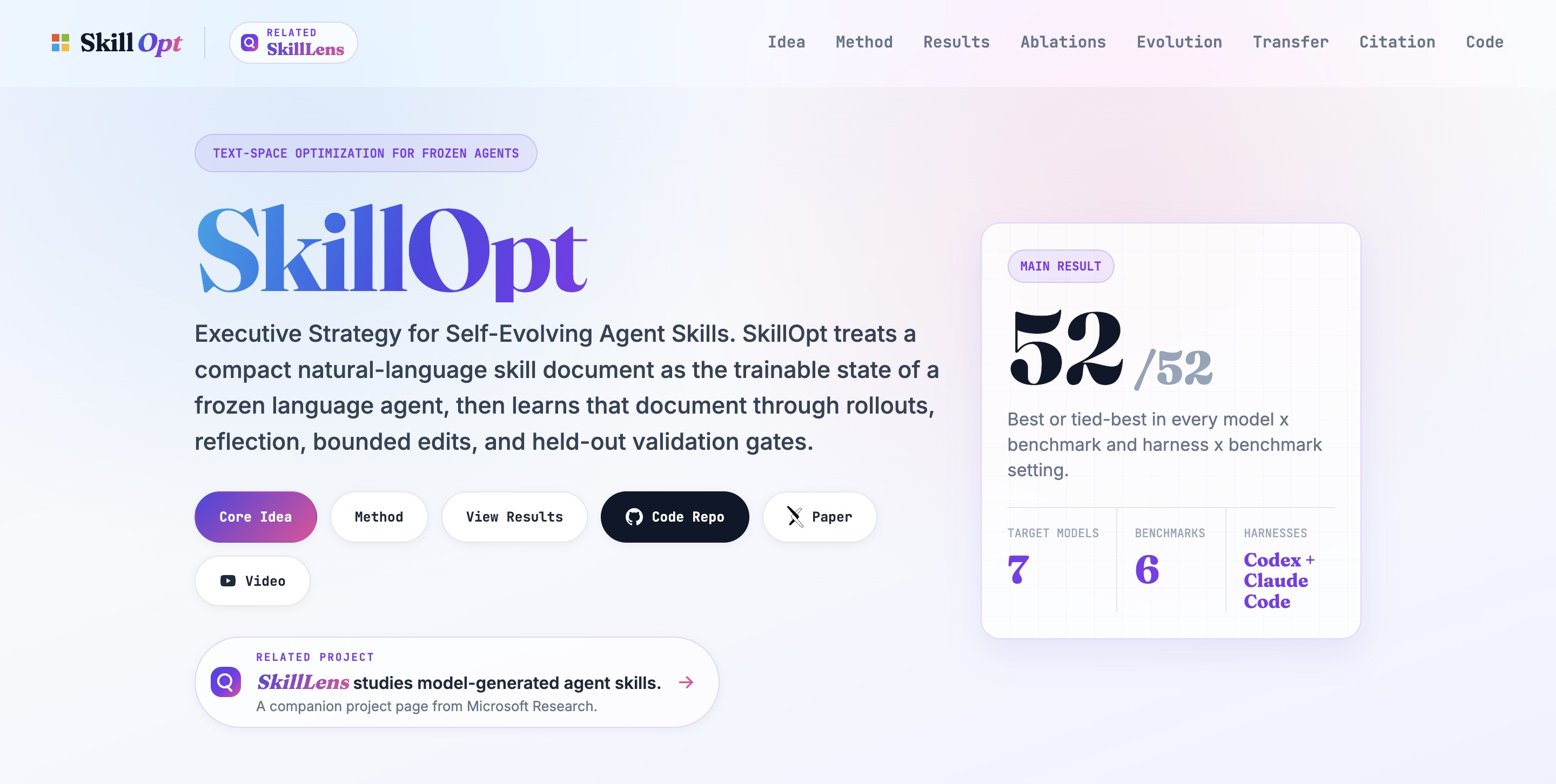
SkillOpt 是微软研究院开源的 Agent 技能自进化框架,核心创新在于将自然语言编写的技能文档视为可训练的外部参数,无需修改底层大模型权重。系统通过"执行-反思-编辑-验证"闭环运作:冻结的目标模型基于当前技能批量执行任务并生成轨迹;独立优化器分析成败案例,提出增删改等原子编辑;所有编辑受限于文本学习率预算以防止破坏性重写,并须经留出验证集严格门控,仅当性能确实提升时才被采纳。最终产出仅是一份数百至两千 token 的 Markdown 技能文件,却能让冻结的 LLM 在特定任务上获得超过20个百分点的性能跃升,可无缝跨模型、跨执行环境迁移,实现零推理成本的持续进化。
SkillOpt的功能特色
- 文本空间技能优化:将自然语言编写的技能文档视为可训练的外部参数,无需修改底层 LLM 权重即可实现 Agent 能力进化
- 四步训练闭环:通过 Rollout(执行)→ Reflect(反思)→ Edit(编辑)→ Gate(验证门控)的完整循环,系统性地迭代优化技能
- 原子编辑操作:优化器模型针对轨迹分析结果,提出 add(增)、delete(删)、replace(替)三种结构化编辑建议
- 编辑预算约束:引入文本学习率预算机制,限制单次更新幅度,防止有效规则被大面积重写覆盖
- 验证门控筛选:候选技能必须在独立留出验证集上严格评估,仅当得分严格高于当前版本时才被接受,避免过拟合
- 拒绝编辑缓冲区:自动记录被拒绝的编辑方向,作为负反馈帮助优化器避免重复提出有害修改
- 慢更新与元技能:每轮结束后进行 Epoch-wise 慢更新,提炼长期有效的模式并更新优化器侧元技能,提升训练稳定性
- Mini-batch 分别反思:将成功与失败轨迹拆分为独立 mini-batch 分别分析,在修正错误的同时保留已有有效行为
- Batch-level 编辑合并:对多批次产生的原子编辑进行去重、冲突解决与排序,确保编辑的一致性与合理性
- 跨模型规模迁移:优化后的技能文档可在不同参数规模的模型间直接复用(如 GPT-5.4 → GPT-5.4-nano)
- 跨执行环境迁移:同一技能文件可无缝适配不同 Agent 框架(如 Codex CLI、Claude Code、直接对话等)
- 轻量零成本部署:最终产物仅为 300–2,000 tokens 的 Markdown 文件,推理时零额外成本,人类可读且易于版本管理
SkillOpt的核心优势
- 无需模型微调:完全冻结目标 LLM 权重,通过优化外部技能文档实现能力进化,适用于闭源模型且零部署推理成本
- 人类可读且可迁移:产出为紧凑的 Markdown 技能文件,可跨模型规模(如 GPT-5.4 → GPT-5.4-nano)、跨执行环境(Codex ↔ Claude Code)直接复用
- 稳定可控的优化机制:引入文本学习率预算、验证门控、拒绝编辑缓冲区和慢更新机制,防止技能"跑偏"或退化,确保训练过程稳定收敛
- 显著性能提升:在 6 大基准、7 个目标模型、3 种执行环境的 52 个评估单元中全部取得最佳或并列最佳,平均提升超过 20 个百分点
- 轻量零成本部署:最终产物仅 300–2,000 tokens,推理时无需加载优化器记忆,零额外计算开销
- 通用覆盖能力强:同时适用于搜索问答、电子表格操作、办公文档处理、数学推理、视觉问答和具身智能等多种任务类型
- 训练纪律性完备:模拟深度学习的 mini-batch、验证检查、学习率调度等机制,将"凭感觉改提示"转化为可量化、可复现的系统化优化
SkillOpt官网是什么
- 项目官网:https://microsoft.github.io/SkillOpt/
- GitHub仓库:https://github.com/microsoft/SkillOpt
SkillOpt的操作步骤
- 环境准备与安装:克隆
microsoft/SkillOpt仓库,安装依赖,配置目标模型与优化器模型的 API 密钥(如 Azure OpenAI、OpenAI 等) - 准备数据集:按 Train(生成 rollout evidence)、Validation(update gate)、Test(locked until final report)划分任务数据,确保验证集独立于训练过程
- 编写初始技能文档:创建一份紧凑的 Markdown 技能文件(),描述 Agent 执行目标领域任务的基础指令与程序模式
- 配置训练超参数:设定编辑预算(textual learning rate)、mini-batch 数量、验证门控阈值、慢更新周期等关键参数
- 启动训练循环:运行主训练脚本,系统自动执行 Rollout(冻结目标模型批量执行任务并记录轨迹)→ Reflect(优化器分析成败 mini-batch)→ Edit(生成原子编辑并合并)→ Gate(验证集筛选)
- 监控训练动态:通过可选的 WebUI 实时观察训练 rollout 得分、selection best 得分、被拒绝编辑数量及技能文档的逐轮变化
- 迭代优化与调参:根据消融实验反馈调整学习率预算、优化器模型强度或数据集划分,利用 rejected-edit buffer 和 slow update 机制提升稳定性
- 导出最佳技能文件:训练结束后,系统输出
best_skill.md——即验证集上得分最高的精炼技能文档 - 部署到生产环境:将
best_skill.md直接接入目标 Agent 的提示词系统,无需加载优化器,零额外推理成本运行
SkillOpt的适用人群
- AI Agent 开发者与工程师:直接构建和运维 Agent 系统的技术人员,SkillOpt 提供了一套可自动迭代、可版本控制的技能优化流水线,替代手工维护冗长提示词
- 提示词工程师(Prompt Engineer):需要将"凭感觉调提示"升级为系统化、可量化的技能优化工作流,利用验证门控和编辑预算实现科学迭代
- 企业自动化与 RPA 团队:在财务、法务、运营等垂直场景中部署 LLM 自动化流程的团队,可通过 SkillOpt 让冻结模型持续适应业务规则变化
- 闭源模型使用者:无法或不愿对商业 API 模型进行微调的团队,SkillOpt 完全在文本空间操作,适用于 GPT、Claude 等任何提供 API 的模型
- 多模型/多平台部署团队:需要同一套 Agent 能力同时部署在轻量端侧模型和云端大模型上的团队,SkillOpt 产出的技能文件可跨模型规模与环境直接迁移
- AI 应用产品经理:负责设计和迭代 AI 功能的产品人员,可通过可视化的训练动态和验证门控,直观评估技能迭代的 ROI 与稳定性
SkillOpt的常见问题
Q:SkillOpt 与手动写提示词(Prompt Engineering)有什么区别?
A: 手动调提示依赖工程师的经验和直觉,难以量化评估且容易过拟合个别案例。SkillOpt 将提示优化转化为系统化的训练过程——通过 mini-batch 分析、编辑预算约束、验证门控筛选等机制,确保技能文档在统计意义上稳定提升,而非针对个别样本的"trick"。
Q:SkillOpt 适用于闭源模型(如 GPT-4、Claude)吗?
A:完全适用。SkillOpt 不修改任何模型权重,仅通过 API 调用让模型读取和遵循外部技能文档。因此无论是 OpenAI、Anthropic 的闭源 API,还是本地开源模型,都可以作为目标模型或优化器模型使用。
Q:SkillOpt 支持哪些任务类型?
A: 官方论文在以下 6 类基准上验证了有效性:
- 搜索问答(SearchQA)
- 电子表格操作(SpreadsheetBench)
- 办公文档问答(OfficeQA)
- 视觉文档问答(DocVQA)
- 数学推理(LiveMath)
- 具身智能(ALFWorld)
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...