

度小满开源全球首个金融行业推理大模型——轩辕-FinX1!
该模型是金融领域首个类GPT-O1推理大模型,采用创新的“思维链+过程奖励+强化学习”训练范式,显著提升逻辑推理能力,并可展示O1模型未公开的完整思考过程,为金融决策提供更深入的洞察。轩辕-FinX1针对金融场景中的分析、决策和数据处理任务进行了深度优化。
轩辕-FinX1由度小满AI-Lab研发,本次发布的是预览版本,现已在开源社区开放免费下载。后续优化版本也将持续开源,供用户下载使用。
Github地址:https://github.com/Duxiaoman-DI/XuanYuan
基准测试结果
在金融评测基准 FinanceIQ 上,初代轩辕-FinX1 展现了卓越的表现。在CPA、银行从业资格、证券从业资格等 10 大类金融权威资格认证中,均超越了 GPT-4o 和开源模型 Qwen2.5-72B,并相较上一版 XuanYuan3 实现了大幅提升。尤其是在精算师这一类别,此前所有大模型得分普遍偏低,而轩辕-FinX1 将分数从 37.5 提升至 65.7,显著体现了其在金融逻辑推理和数学计算方面的强大优势。 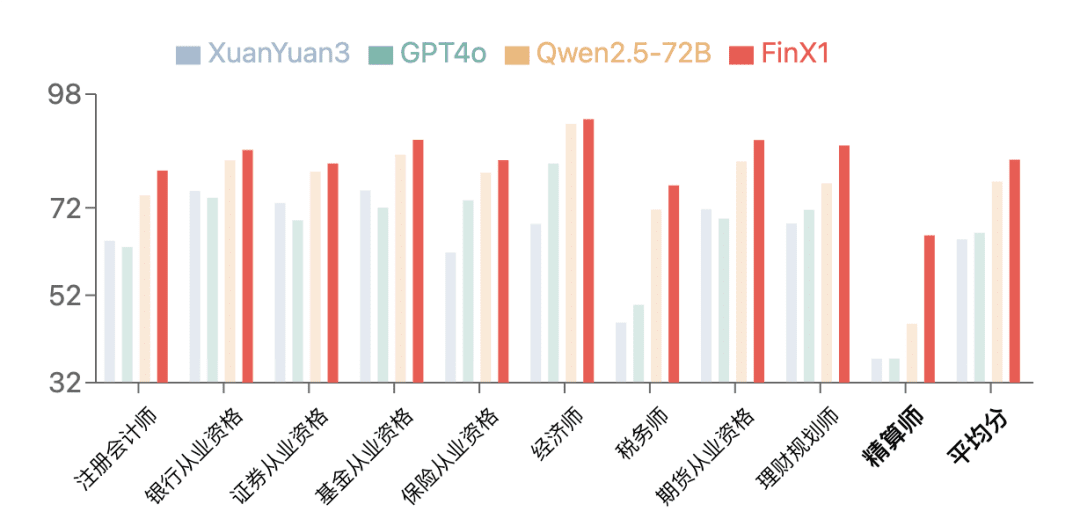
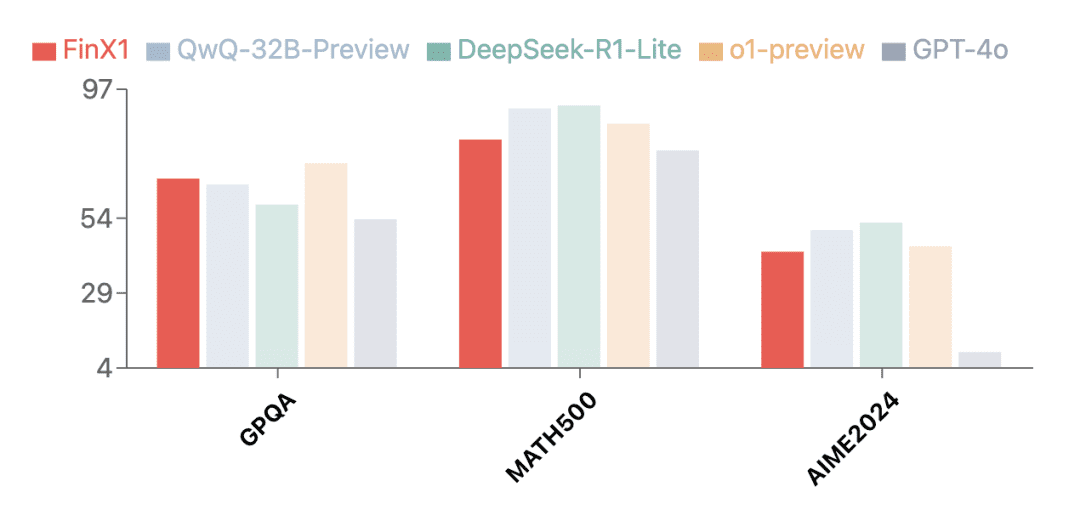
除了金融领域,初代轩辕-FinX1 也展现了突出的通用能力。在多个权威评测集上的测试结果显示,轩辕-FinX1 不仅在GPQA(科学推理)、MATH-500(数学)和AIME2024(数学竞赛)等评测中取得卓越成绩,还超越了 GPT-4o,与 O1 以及国内最新发布的推理版大模型共同位列顶尖梯队,验证了其强大的基础推理能力。
打破“黑盒”:完整呈现思维链
轩辕 FinX1 的一大特色在于,它能够在生成回答前先呈现完整的思考过程,构建从问题拆解到最终结论的全透明思维链。通过这一机制,轩辕 FinX1 不仅提升了推理的可解释性,也解决了传统大模型的“黑盒”问题,为金融机构提供了更加可信的决策支持工具。

轩辕 FinX1的思维链生成示例
专注金融复杂分析决策
当 OpenAI 的 GPT-O1 以卓越的“思考能力”引发行业瞩目时,一个关键命题浮现:如何让这种深度推理能力在金融专业场景中创造实质价值?度小满轩辕 FinX1 给出了创新答案——首次将大模型深度推理能力注入金融领域,从而推动大模型应用从通用场景深入到风控决策等核心业务层面。
在金融行业数智化转型浪潮中,“决策与风控能力”、“研究分析能力”和“数据智能能力”构成了推动业务创新和价值提升的关键维度。这些能力分别通过精准的风险识别与管控、深入的市场研判与价值发现、高效的数据建模与分析,为机构带来持续价值增长。
轩辕 FinX1 通过创新的训练范式,将深度推理能力与金融专业知识深度融合,让这三大能力在具体场景中得到充分释放,为金融行业带来全新的智能化解决方案。

01 决策与风控能力
决策与风控能力是金融机构的生命线,关乎其稳健经营和可持续发展。在风险识别与预测、风控模型构建、策略制定等核心任务中,轩辕 FinX1 凭借强大的推理能力和完整的思维链机制,能够系统分析风险因素间的关联与传导路径,为机构提供全面深入的风险洞察。例如,根据用户授权上传的银行流水,轩辕 FinX1 能够从上千条交易记录中精准识别高频彩票消费、游戏消费等风险信号,并结合收入水平和债务负担,科学评估用户的还款能力和信贷风险。

轩辕 FinX1回复片段
02 研究分析能力
研究分析能力是金融决策的基础支撑,通过对宏观、行业、公司层面的深入洞察,提升资本配置的科学性。轩辕 FinX1 能对宏观经济数据、市场情绪、政策影响等进行多维度分析,通过清晰的逻辑链条逐步拆解复杂问题。例如,在根据经济数据预测美联储2025年降息情况时,模型通过分析各种经济因素,并基于不同的假设情景,探讨了多种可能性,全面客观地展现了美联储2025年降息的前景,目前与多家机构预测分析观点一致。 
03 数据智能能力
数据智能能力是金融机构实现精准决策的重要支撑,其核心是高效的数据处理能力和深度的分析能力。轩辕 FinX1可帮助金融机构快速挖掘数据背后的业务逻辑与价值。例如,将某公司季度财务数据输入轩辕 FinX1,模型能够精准提取核心信息,直观展示资产质量、流动性与业务动态。通过分析“流动性压力”“资产扩张驱动”等关键指标,轩辕 FinX1 在量化比较的基础上补充定性解释,揭示财务数据背后的潜在风险与增长机会,助力企业优化决策。 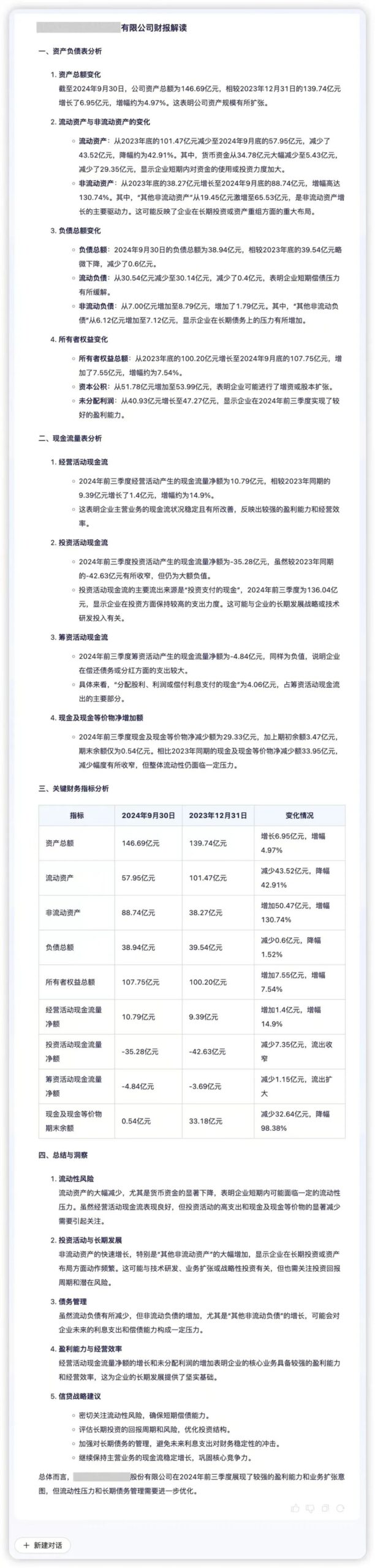
轩辕-FinX1的技术实现
为了实现大模型具备类O1的推理能力,尤其是在金融领域复杂的决策分析场景中,我们经过大量的探索和验证,提出包含三个关键步骤的技术方案:构建稳定的思维链生成模型、金融决策加强的双奖励模型、PRM和ORM双引导下的强化学习微调。
01 初步构建稳定的思维链生成模型
针对金融领域复杂的决策分析场景,我们构建了具备稳定思维链生成能力的基础模型。首先是高质量COT/Answer的数据合成,先根据问题生成思考过程,再根据问题与思考过程生成最终答案。通过这种策略,模型能够专注于每个阶段的任务,产生更连贯的推理链条和答案。
对于不同领域(如数学、逻辑推理、金融分析等),我们设计了专门的数据合成方法,比如对于金融分析类任务,我们设计一种迭代式合成方法,确保分析过程全面性,之后基于XuanYuan3.0模型采用指令微调进行训练,采用统一的<thinking>思考过程</thinking> <answer>答案</answer>输出格式(我们本次也会将粗粒度的思考节点进行公开),同时重点构造了较多的长文本数据来增强模型的长上下文处理能力,使其能够“先生成详细的思考过程,再生成答案”,这为后续的过程监督训练和强化学习优化奠定了坚实基础。
02 金融决策加强的双奖励模型
为了评估模型在金融决策场景下的表现,我们设计了结果导向(ORM)和过程级(PRM)两个互补的奖励模型。其中ORM延续了XuanYuan3.0的技术方案,采用对比学习和逆强化学习的方式训练;PRM则是我们针对推理过程的创新,重点解决了开放性金融问题(如市场分析、投资决策等)的评估难题。
对于PRM的训练数据构建,我们针对不同场景采用了不同策略:对于风险评级等有确定答案的问题,使用基于MCTS的反向验证方法;对于开放性的金融分析问题,则通过多个大模型从正确性、必要性、逻辑性等维度进行标注,并通过下采样和主动学习解决了数据不平衡问题。在训练过程中,PRM使用有监督微调方式,通过对每个思考步骤的评分来优化模型。03 PRM和ORM双引导下的强化学习微调在强化学习阶段,我们采用PPO算法进行模型优化,将PRM和ORM作为奖励信号。对于<thinking>和</thinking>之间的思考过程,使用PRM在每个思考步骤进行打分,及时发现和纠正思考路径中的错误;对于答案部分,则针对不同类型的问题采用不同的评估策略:对有确定答案的金融问题(如风险等级评估)采用规则匹配计算奖励,对开放性问题(如市场分析)则使用ORM进行整体评分。在训练过程中同时引入了动态KL系数和优势函数归一化等技术来稳定训练过程。这种基于双重奖励的训练机制,不仅克服了单一奖励模型的局限性,也通过稳定的强化学习训练显著提升了模型在金融决策场景下的推理能力。
可以看出,上述路线中的关键是对不同于数学或者逻辑的金融分析类开放问题的思维链数据的构造和奖励模型的评估,目前我们仍在仍在不断优化和迭代,会持续探索更有效的技术路线。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...