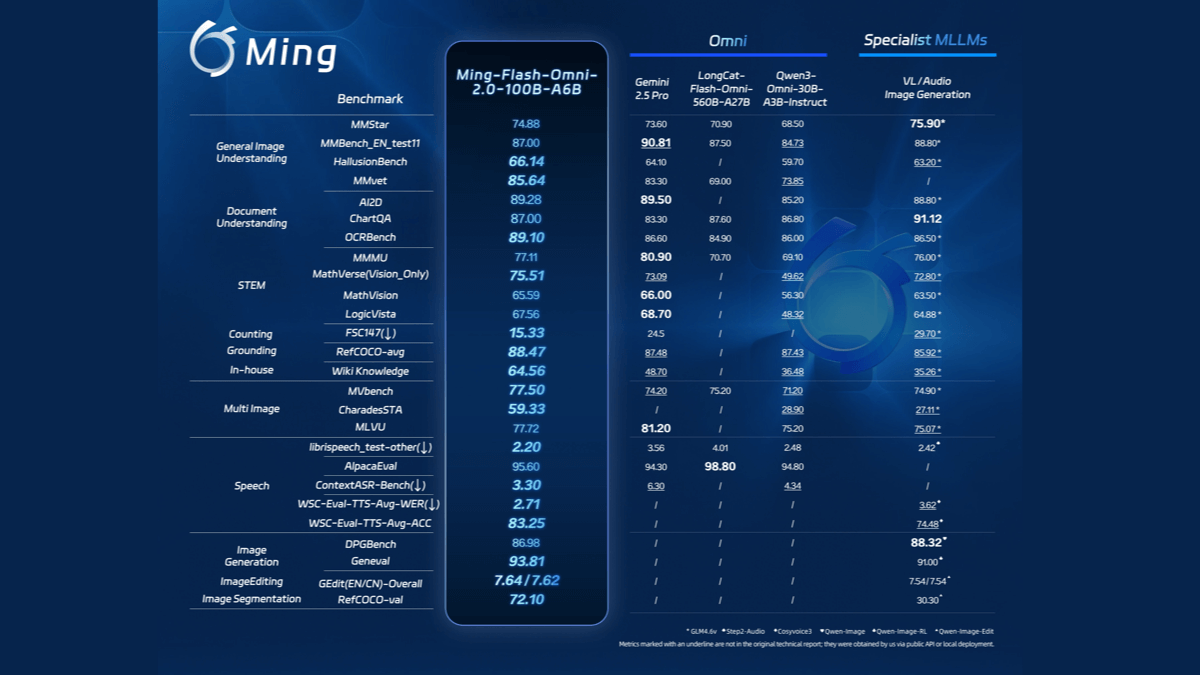

综合介绍
SemHash 是一个轻量级且灵活的工具,用于通过语义相似性来去重数据集。它结合了 Model2Vec 的快速嵌入生成和 Vicinity 的高效 ANN(近似最近邻)相似性搜索。SemHash 支持单数据集去重(例如,清理训练集)和多数据集去重(例如,确保测试集和训练集之间没有重叠)。它适用于简单的数据集,如文本列表,以及更复杂的数据集,如多列 QA 数据集。此外,它还包括检查去重结果的功能,使您更容易理解和优化数据清理过程。
功能列表
- 快速嵌入生成:使用 Model2Vec 生成嵌入,速度快且准确。
- 高效相似性搜索:通过 Vicinity 实现高效的 ANN 相似性搜索。
- 单数据集去重:清理单个数据集,去除重复数据。
- 多数据集去重:确保多个数据集之间没有重叠,防止数据泄漏。
- 多列数据集去重:支持复杂数据集的去重,如 QA 数据集。
- 去重结果检查:提供去重结果的详细检查功能,帮助优化数据清理过程。
使用帮助
安装流程
- 打开终端或命令行工具。
- 输入以下命令安装 SemHash:
pip install semhash
使用方法
单数据集去重
- 加载数据集:
from datasets import load_dataset
from semhash import SemHash
texts = load_dataset("ag_news", split="train")["text"]
- 初始化 SemHash 实例:
semhash = SemHash.from_records(records=texts)
- 去重数据集:
deduplicated_texts = semhash.self_deduplicate().deduplicated
多数据集去重
- 加载两个数据集:
train_texts = load_dataset("ag_news", split="train")["text"]
test_texts = load_dataset("ag_news", split="test")["text"]
- 初始化 SemHash 实例:
semhash = SemHash.from_records(records=train_texts)
- 去重测试数据集:
deduplicated_test_texts = semhash.deduplicate(records=test_texts, threshold=0.9).deduplicated
多列数据集去重
- 加载多列数据集:
dataset = load_dataset("squad_v2", split="train")
records = [dict(row) for row in dataset]
- 初始化 SemHash 实例:
semhash = SemHash.from_records(records=records, columns=["question", "context"])
- 去重数据集:
deduplicated_records = semhash.self_deduplicate().deduplicated
去重结果检查
- 查看去重后的文本:
result = semhash.self_deduplicate(records=texts, threshold=0.99)
for duplicate in result.duplicates:
print("RECORD:")
print(duplicate.record)
if duplicate.exact:
print("Exact match!")
else:
print("DUPLICATES:")
for corpus_duplicate in duplicate.duplicates:
print(corpus_duplicate)
print("-" * 25)
通过以上步骤,您可以快速上手使用 SemHash 进行数据集的语义去重,提升数据清理效率。
semhash详细说明
我们非常激动地宣布发布 semhash,我们的语义去重和数据集多功能工具(其他功能即将推出)。
简介
最近一个受关注的领域,特别是在训练大语言模型(LLM)方面,是拥有大量数据固然好,但拥有少量高质量数据会更好。一个很好的例子可以在 fineweb 博客文章 中找到,作者从一个非常大的通用爬虫转储数据集开始,对该数据集执行许多质量检查,包括去重和一系列质量检查。
在 Minish,我们有兴趣通过构建非常快速的模型来解锁新的可能性。您可能知道,我们创建了世界上最好的最小的快速模型 potion-base-8m。我们感兴趣的领域之一是 近似去重:我们希望从语料库中删除语义上非常相似的文档。以前的文本去重算法,如 minhash 或 simhash,对字符或单词 n 元语法进行操作,因此只能找到字形相似的序列之间的相似性,而忽略语义相似性。
虽然去重听起来像是只能有利于大语言模型训练的东西,但它对于检查小数据集的重叠也真的很有益:即使训练集和测试集之间存在近似重叠也会导致性能高估,并且在训练集中存在近似重复会导致计算资源的浪费、特征重要性的高估以及潜在的其他问题。
此外,去重技术还可以用于让您对更大的数据集一览无余:使用 semhash 检查近似重复只需(毫)秒,并且允许您查看数据集中哪些项目看起来相似。如果这些有意义:太棒了!如果没有重复……也很棒!一切都比在不正确的数据上训练要好。
如何使用去重?
这里有一些很酷的用例,让您了解何时进行去重是有意义的:
分类
如上所述,重要的是训练集和测试集之间的信息没有重叠。存在重叠通常意味着您高估了性能,因为模型不再需要泛化才能表现良好。但是,从训练集中删除重复项也可能非常有用。在训练集中拥有大量相同记录的重复项会使模型高估该记录的特征的重要性,并且在任何情况下都会导致计算资源的浪费和模型拟合的高估。
RAG 系统
RAG 系统中的重复项听起来很罕见,直到您考虑到大多数 RAG 系统都是使用块构建的:虽然拥有完全重复的文档可能很罕见,但在文档之间或文档内拥有重复的块要常见得多。在您的知识库中拥有重复的块会增加存储成本,增加检索到不相关块的风险,并迫使您比必要更早地实施多样化策略。
解释您的语料库
通过使用低阈值运行 semhash,您可以快速了解哪些文档与哪些文档相似,以及哪些文档不相似。这使您可以很好地了解要关注什么,您的数据中缺少哪些内容,以及您的文档如何相互关联。
它如何工作?
semhash 的核心是将字符串或字典的集合作为输入。您首先使用一组参考文档初始化模型,然后使用这组文档对传入的集合进行去重。任何与参考集中文档相似的传入文档都会被删除,并与其在参考集中的近似重复项分开存储。
from datasets import load_dataset
from semhash import SemHash
dataset = load_dataset("ag_news")
train = dataset["train"]
test = dataset["test"]
# 这会在您的训练集上创建一个索引。所有记录都完整存储。
semhash = SemHash.from_records(records=train, columns=["text"])
# 这会参考 `train` 对您的文本进行去重。任何在 train 中出现的项目都会
# 从 test 中删除。
result = semhash.deduplicate(test, threshold=0.9)
# 没有重复的集合
result.deduplicated
# 重复项
result.duplicates
在拟合期间,所有文档首先由编码器编码。默认编码器是 potion-base-8m,一个 model2vec 模型。然后,这些文档存储在由 usearch 支持的 vicinity 向量存储中。然后,对于传入的文档集,我们首先使用指定的编码器对它们进行编码,然后从向量存储中检索最近的邻居。每个具有相似度高于阈值的最近邻居的传入文档都会被删除。
由于所有这些组件都非常快,因此即使是非常大的数据集的去重也只需要几分钟。例如,对整个 Squad-2.0 数据集 数据集进行去重,该数据集有 130000 个样本,仅需 7 秒。这包括向量化、拟合索引和实际的去重。较小的数据集只需花费一小部分时间,而即使包含数百万个文档的数据集也只需几分钟。有关全面的基准测试,请参阅 我们的基准测试。
可解释性
semhash 还可以用于调查您的数据集。通过使用 self_deduplicate,您可以对训练集本身进行去重,我们将以此作为起点:
from datasets import load_dataset
from semhash import SemHash
dataset = load_dataset("ag_news")
train = dataset["train"]
test = dataset["test"]
# 这会在您的训练集上创建一个索引。所有记录都完整存储。
semhash = SemHash.from_records(records=train, columns=["text"])
result = semhash.self_deduplicate(threshold=0.9)
让我们深入了解您可以使用 result 做什么。首先,您可以只获取所有去重的记录:
result.deduplicated
这些记录与您放入的记录完全相同,允许您在其他 ML 管道中使用 semhash。semhash 不会更改您的数据,它只是减小了数据的大小。
您可以轻松地看到重复记录的比例:
result.duplicate_ratio
或精确的重复项:
result.exact_duplicate_ratio
您还可以看到哪些被标记为重复项,以及原因。每个重复的文档都与其索引中导致其被标记为重复项的示例一起存储。精确的重复项被标记为精确的重复项。以下代码示例演示了基本用法。
for duplicated_record in results.duplicates:
print(duplicated_record.record)
if duplicated_record.exact:
print("Exact match")
continue
for index_duplicate in duplicated_record.duplicates:
print(index_duplicate)
print("-" * 25)
为了方便使用,我们还提供了一个辅助函数,该函数显示您的重复项集中最不相似的去重记录:
result.get_least_similar_from_duplicates(1)
如果这个记录对于其重复的记录来说仍然被认为是一个重复项,那么您的重复策略就是有意义的!如果不是,您可以选择重新设置结果集的阈值。通过这样做,您将创建一个新的阈值,从而删除重复项。如下所示:
print(result.duplicate_ratio)
result.rethreshold(0.95)
print(result.duplicate_ratio)
因此,一个通用的策略可能是从相对较低的阈值开始,直到 result.get_least_similar_from_duplicates 返回的结果开始有意义。但是,在我们的实验中,0.9 的阈值(这是默认值)效果很好,但请务必检查您的具体用例。
多列数据
semhash 还支持多列数据集,允许您对在多列中包含文本的数据集进行去重。例如,在问答数据集中,您不仅要对相似的问题或相似的上下文进行去重,还要只计算两个字段都足够相似的项目为重复项。
这是一个难以解决的问题,但 semhash 也可以处理这个问题。
以下代码片段演示了它是如何工作的:
from datasets import load_dataset
from semhash import SemHash
dataset = load_dataset("rajpurkar/squad_v2")
train = dataset["train"]
# 这会在您的训练集上创建一个索引。所有记录都完整存储。
semhash = SemHash.from_records(records=train, columns=["context", "question"])
result = semhash.self_deduplicate(threshold=0.9)
这将计算相似度,并且仅返回两个字段都相似的记录。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...