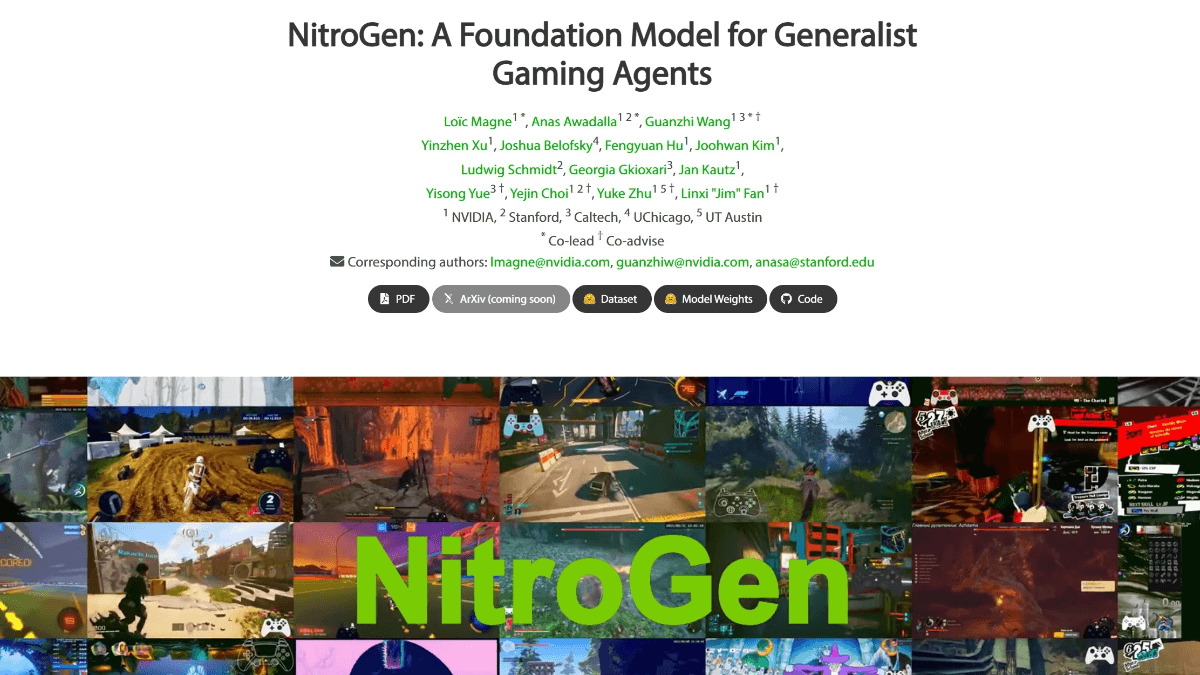

综合介绍
RapBank 是一个专为说唱歌词生成而设计的数据集和工具集。该项目由 NZqian 创建,旨在通过收集和处理来自 YouTube 的说唱歌曲,为研究人员和开发者提供一个高质量的说唱歌词数据集。RapBank 包含超过 9 万首说唱歌曲,涵盖 84 种语言,提供了详细的处理管道和使用说明,帮助用户高效地进行数据处理和模型训练。该项目的数据和代码均在 GitHub 上开源,遵循 CC BY-NC-SA 4.0 许可协议。
人声的模型(目前开放了数据集)-1")
功能列表
- 数据集下载:提供超过 9 万首说唱歌曲的数据集,涵盖多种语言。
- 数据处理管道:包括源分离、分段、歌词识别等步骤,帮助用户高效处理数据。
- 详细文档:提供完整的使用说明和示例代码,帮助用户快速上手。
- 开源代码:所有代码和数据均在 GitHub 上开源,方便用户进行二次开发。
- 许可协议:数据和代码遵循 CC BY-NC-SA 4.0 许可协议,确保用户在合法范围内使用。
使用帮助
安装流程
- 克隆项目仓库:
git clone https://github.com/NZqian/RapBank.git
cd RapBank
- 安装依赖:
pip install -r requirements.txt
- 下载数据集并放置在指定文件夹中,例如
/path/to/your/data/wav。
数据处理
- 使用提供的脚本处理数据:
bash pipeline.sh /path/to/your/data /path/to/save/features start_stage stop_stage
start_stage和stop_stage参数用于指定处理的起始和结束阶段,范围为 0 到 5。- 建议使用多 GPU 以加快处理速度。
功能操作流程
- 数据集下载:访问 GitHub 页面,下载所需的数据集文件。
- 数据处理:按照上述步骤安装依赖并运行处理脚本,生成所需的特征文件。
- 模型训练:使用处理后的数据进行模型训练,具体步骤请参考项目文档中的示例代码。
- 结果分析:使用生成的模型进行说唱歌词生成,并对结果进行分析和优化。
详细功能介绍
- 数据集下载:提供了一个包含 9 万多首说唱歌曲的数据集,用户可以根据需要下载并使用这些数据进行研究和开发。
- 数据处理管道:包括源分离、分段、歌词识别等多个步骤,帮助用户高效地处理和分析数据。
- 详细文档:项目提供了完整的使用说明和示例代码,帮助用户快速上手并进行二次开发。
- 开源代码:所有代码和数据均在 GitHub 上开源,用户可以自由下载和使用。
- 许可协议:数据和代码遵循 CC BY-NC-SA 4.0 许可协议,确保用户在合法范围内使用。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...