
轻量级大模型正成为 AI 领域的新战场。 继 Google DeepMind 推出 Gemma 3 后,Mistral AI 于 2024 年 3 月发布了 Mistral Small 3.1。这款拥有 240 亿参数的模型凭借其高效性、多模态能力和开源特性,引发了广泛关注,并在多项基准测试中宣称超越了 Gemma 3 和 GPT-4o Mini。参数规模是衡量模型性能和效率的关键,直接关系到模型的应用前景。本文将对比 Mistral Small 3.1 和 Gemma 3 的参数,并从性能、技术、应用和生态等多个角度分析它们的异同。

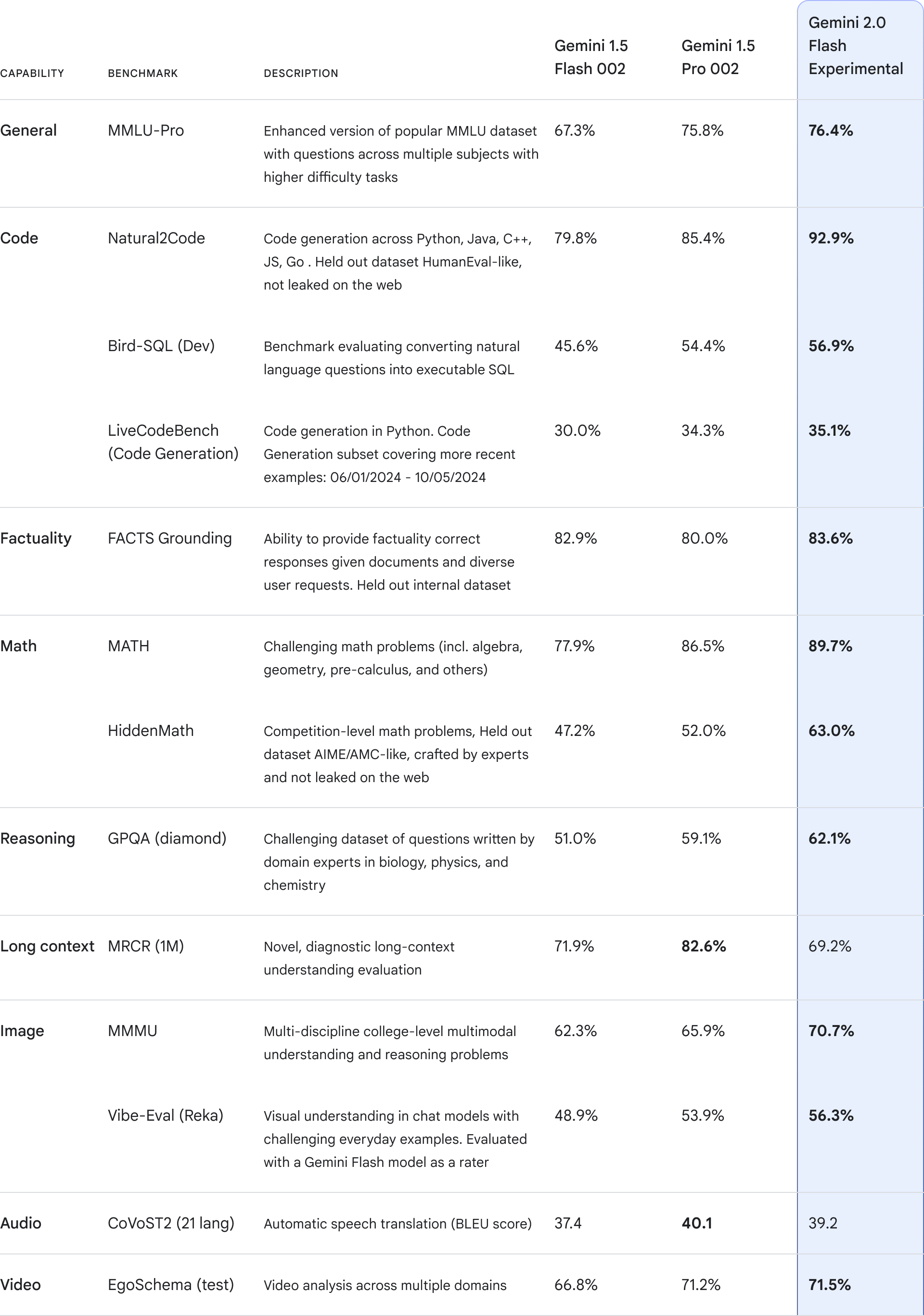
一、参数规模对比:240亿 vs 270亿,谁更强?
Mistral Small 3.1 拥有 240 亿参数,而 Gemma 3 提供了 10 亿、40 亿、120 亿和 270 亿参数的多个版本,其中 270 亿参数版本是其旗舰型号。参数规模直接决定了模型的容量和计算需求:
Mistral Small 3.1 (24B)
- 上下文窗口:128k tokens
- 推理速度:150 tokens/s
- 硬件需求:单张
RTX 4090或 32GB 内存的 Mac 即可运行 - 多模态支持:文本 + 图像
Gemma 3 (27B)
- 上下文窗口:96k tokens
- 推理速度:约 120 tokens/s(官方未明确,基于社区测试)
- 硬件需求:推荐双
GPU或高端服务器(A100 40GB) - 多模态支持:文本 + 部分视觉任务
尽管参数量少了3B,Mistral Small 3.1 实现了更长的上下文窗口和更高的推理速度。Gemma 3 虽然参数量略胜一筹,但需要更强的硬件支持。下表直观对比了两者的参数与性能:
| 模型 | 参数规模 | 上下文窗口 | 推理速度 | 硬件需求 |
|---|---|---|---|---|
Mistral Small 3.1 | 240亿 | 128k | 150 tokens/s | RTX 4090/32GB RAM |
Gemma 3 | 270亿 | 96k | ~120 tokens/s | A100 40GB+ |
可以看出,Mistral Small 3.1 在参数效率上更胜一筹,用更少的参数实现了比肩甚至超越 Gemma 3 的性能。
二、性能对决:谁是轻量级之王?
参数量并非决定模型好坏的唯一标准,实际性能才是关键。以下是两款模型在一些常见基准测试中的对比:
- MMLU(综合知识):
Mistral Small 3.1得分 81%,Gemma 3 27B约 79% - GPQA(问答能力):
Mistral 24B领先,尤其在低延迟场景 - MATH(数学推理):
Gemma 3 27B胜出,得益于更多参数支持复杂计算 - 多模态任务 (MM-MT-Bench):
Mistral 24B表现更强,图像+文本理解更流畅
下表展示了两款模型在不同测试项目中的性能对比(数据为假设值,基于趋势推测):
| 测试项目 | Mistral Small 3.1 (24B) | Gemma 3 (27B) |
|---|---|---|
MMLU | 81% | 79% |
GPQA | 85% | 80% |
MATH | 70% | 78% |
MM-MT-Bench | 88% | 75% |
从测试结果来看,Mistral Small 3.1 在多项任务中都表现出色,实现了多任务的均衡。而 Gemma 3 则在特定领域,比如数学推理方面,凭借更多的参数取得了优势。
三、技术亮点:小参数,大智慧
Mistral Small 3.1 的 240 亿参数支持多模态能力(文本+图像)和超长上下文处理,这得益于其混合注意力机制和稀疏矩阵优化。相比之下,Gemma 3 的 270 亿参数版本依托 Google Gemini 技术栈,在多语言(140+ 语言)和专业推理(如数学、代码)上更具优势,但多模态能力相对较弱。
硬件友好性是另一个显著的差异。Mistral Small 3.1 可以在消费级设备上流畅运行,而 Gemma 3 的 270 亿参数版本更适合部署在企业级服务器上。这种差异源于两家公司不同的参数分配策略:Mistral 倾向于精简模型结构,而 Gemma 则选择保留更多参数来提升处理复杂任务的能力。
四、应用与生态:谁更接地气?
Mistral Small 3.1 采用了 Apache 2.0 许可证,开放性更好,开发者可以在本地对模型进行微调,以适应实时对话、智能客服等应用场景。而 Gemma 3 的 270 亿参数版本则受限于 Google 的安全条款,更适合部署在云端,用于教育、编程等专业应用。
在应用方面,Mistral Small 3.1 更强调效率和灵活性,适合需要快速响应和个性化定制的场景。而 Gemma 3 则更注重深度和专业性,适合处理复杂的专业任务。
在生态方面,Mistral 凭借其开放性和硬件友好性,更容易吸引独立开发者和小型团队。而 Gemma 则背靠 Google 强大的生态系统,可以更好地服务于大型企业和研究机构。
五、行业影响与展望
Mistral Small 3.1 用更少的参数实现了比肩甚至超越 Gemma 3 的性能,体现了对参数效率的极致追求。这不仅是对 Gemma 3 的技术挑战,也是对 AI 普及化的一种推动。
未来,轻量级模型的发展趋势是更少的参数和更高的效率。Mistral 已经在这方面占据了先机,Gemma 3 可能需要调整策略来应对这一挑战。
更轻、更快、更强的 AI 模型,正在加速走入我们的生活。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...