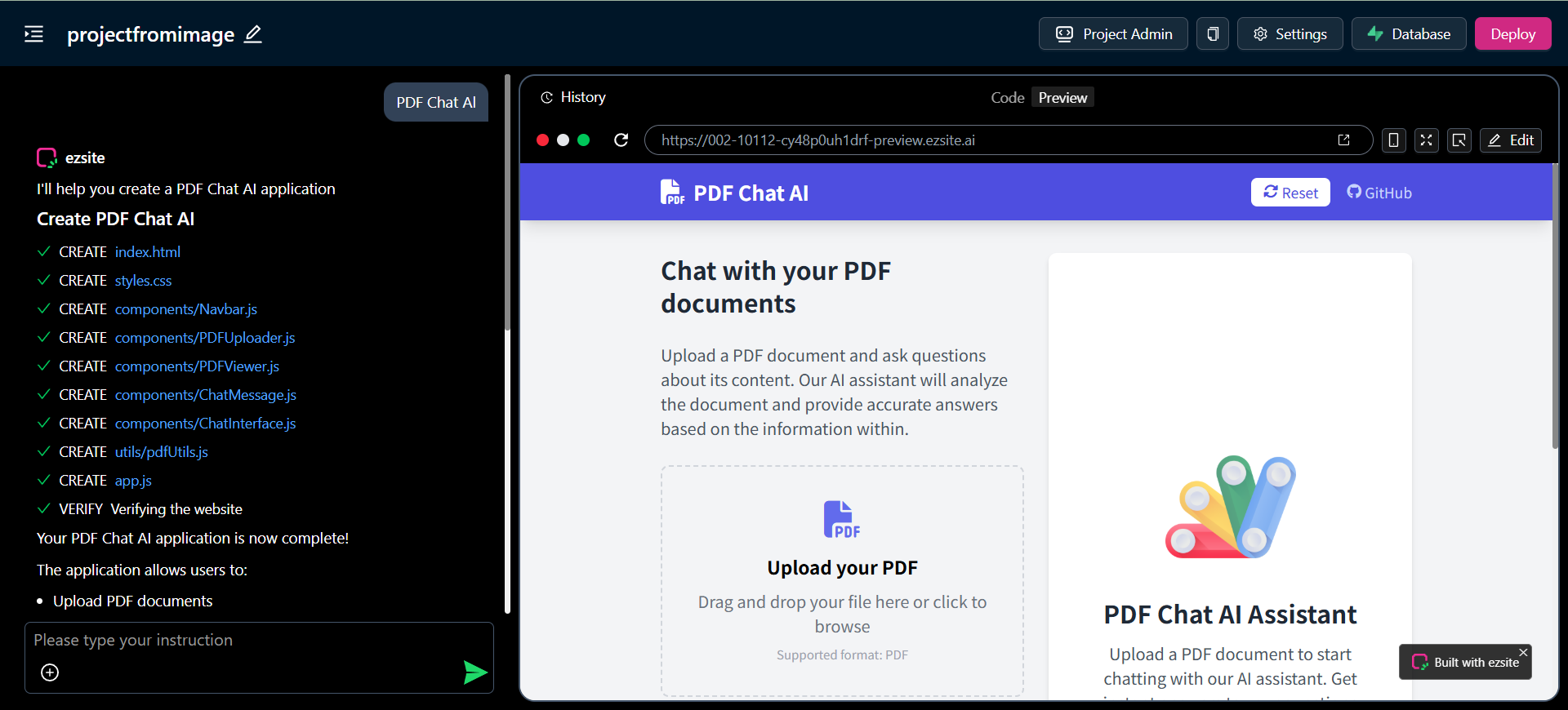

综合介绍
LaWGPT 是由南京大学机器学习与数据挖掘研究组支持的一个开源项目,致力于打造基于中文法律知识的大语言模型。它在通用中文模型(如 Chinese-LLaMA 和 ChatGLM)的基础上,扩展了法律领域专有词表,并通过大规模法律语料预训练和法律问答数据集的指令精调,显著提升了模型在法律场景下的语义理解和对话能力。该项目由多个协作者共同推进,适用于法律对话、司法考试训练等场景。尽管目前模型仍受限于数据和容量,输出可能存在不确定性,但其开源性质和社区支持使其成为法律领域AI研究的重要资源。

功能列表
- 法律问答生成:根据输入的法律问题生成准确的回答,适用于咨询和学习。
- 司法考试训练:提供基于中国司法考试数据集的问答训练,帮助用户备考。
- 法律语料理解:通过预训练,能解析复杂的法律文书和法规内容。
- 命令行批量推理:支持开发者通过脚本批量处理法律相关数据。
- 交互模式对话:在无预设数据时,以交互方式实时回答用户提问。
- 模型权重支持:提供 LoRA 权重,允许用户结合原始模型进行自定义调整。
使用帮助
安装流程
LaWGPT 是一个基于 GitHub 的开源项目,使用前需要安装环境和依赖。以下是详细的安装步骤:
- 克隆项目代码
打开终端,输入以下命令将代码下载到本地:
git clone git@github.com:pengxiao-song/LaWGPT.git
cd LaWGPT
这会将 LaWGPT 的代码库克隆到你的电脑,并进入项目目录。
- 创建虚拟环境
使用 Conda 创建一个独立的 Python 环境,避免依赖冲突:
conda create -n lawgpt python=3.10 -y
conda activate lawgpt
激活环境后,后续操作将在 lawgpt 环境中进行。
- 安装依赖
项目提供了requirements.txt文件,列出了所需库。运行以下命令安装:
pip install -r requirements.txt
依赖包括 transformers、peft、gradio 等,确保网络畅通以完成下载。
- 获取模型权重
由于 LLaMA 和 Chinese-LLaMA 未开源完整权重,LaWGPT 仅提供 LoRA 权重。你需要:
- 从官方渠道获取 Chinese-LLaMA 或其他基础模型的权重。
- 将 LoRA 权重与基础模型合并(具体合并方法见项目文档)。
- 验证安装
运行示例脚本确认环境无误:
bash scripts/infer.sh
若成功进入交互模式,说明安装完成。
使用方法
主要功能操作:法律问答与推理
- 交互模式
当未指定测试数据路径时,运行bash scripts/infer.sh会进入交互模式。你可以直接输入法律问题,例如:
请解释《中华人民共和国合同法》第十条的内容。
模型会实时生成回答,适用于快速咨询或学习。
- 批量推理
若需处理多个问题,准备一个 JSON 文件(格式参考resources/example_instruction_train.json),如:
{"instruction": "离婚后财产如何分割?", "output": ""}
将文件路径传入脚本:
bash scripts/infer.sh --infer_data_path ./test.json
模型会逐行处理并输出结果,结果可保存用于后续分析。
特色功能操作:司法考试训练
- 准备数据集
LaWGPT 支持基于司法考试数据集的训练。你可以参考Awesome Chinese Legal Resources下载公开数据集,或自行构造问答对,格式如下:{"instruction": "下列哪项不属于犯罪构成要件?", "output": "A. 犯罪主体 B. 犯罪客体 C. 犯罪动机 D. 犯罪客观方面"}保存为 JSON 文件,例如
exam_data.json。 - 运行训练
使用finetune.py脚本进行指令精调:python finetune.py --data_path ./exam_data.json --base_model <path_to_base_model> --lora_weights <path_to_lora>参数说明:
--data_path:数据集路径。--base_model:基础模型路径。--lora_weights:LoRA 权重路径。
训练完成后,模型将更适应司法考试类问题。
Web 界面使用
- 启动 WebUI
项目支持通过 Gradio 提供图形界面。运行:bash scripts/webui.sh启动后,浏览器会打开一个本地页面(通常是
http://127.0.0.1:7860)。 - 操作流程
- 在输入框中输入法律问题,例如:“如何申请专利保护?”
- 点击“提交”,等待模型生成回答。
- 查看输出结果,可复制或保存。
Web 界面适合非技术用户,操作直观。
注意事项
- 硬件要求:建议使用 GPU(如 Tesla V100)加速推理,CPU 运行可能较慢。
- 模型选择:默认使用
LaWGPT-7B-alpha,若需beta1.0或beta1.1,需调整脚本中的模型参数。 - 局限性:模型可能因数据限制生成不准确内容,使用时需验证结果,尤其在真实法律场景中。
通过以上步骤,你可以轻松上手 LaWGPT,无论是进行法律问答还是备战司法考试,都能获得高效支持。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...