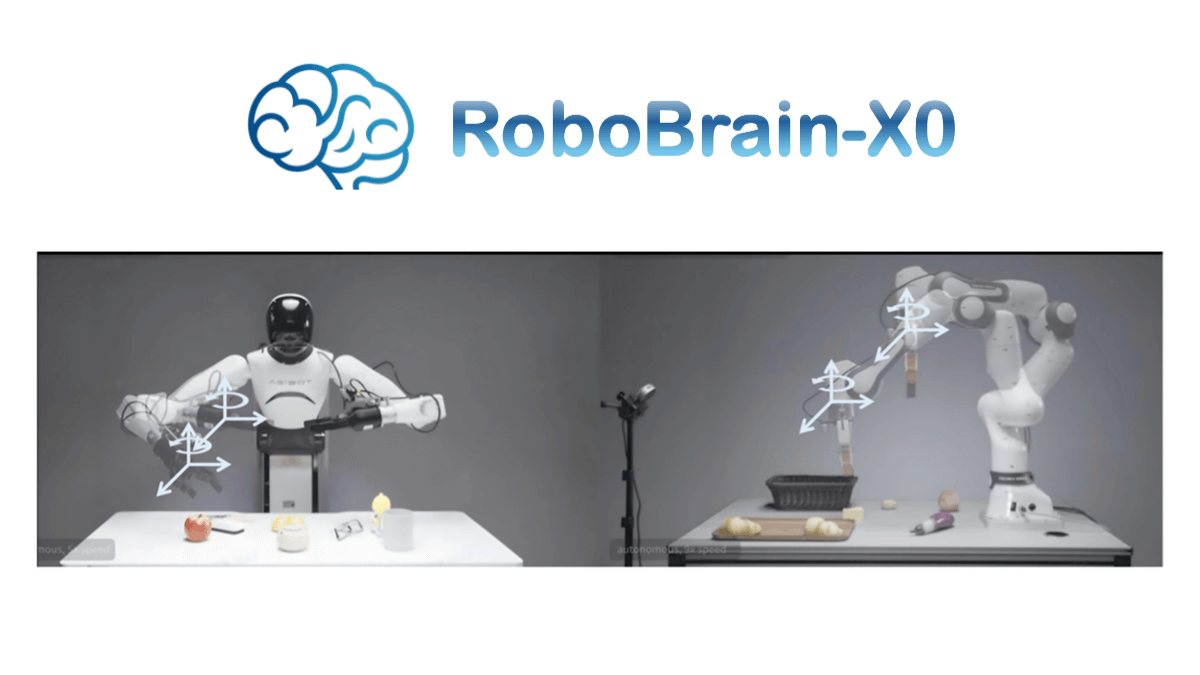
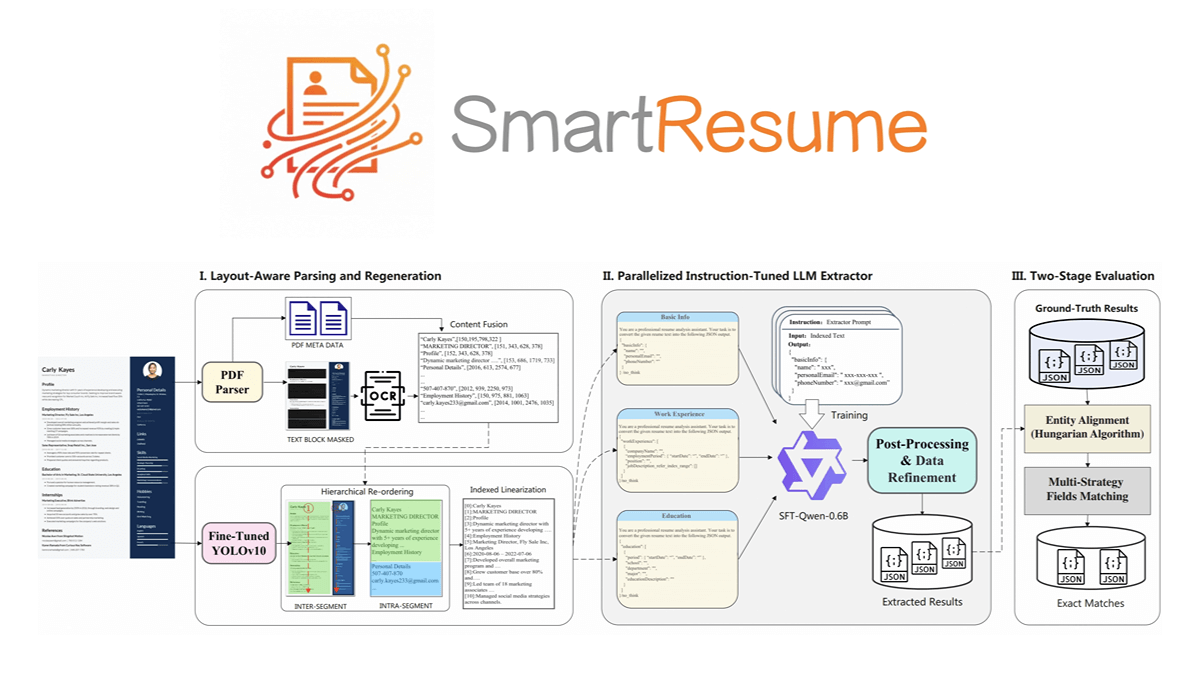
로보브레인-X0은 위즈덤 소스 연구소가 오픈소스로 공개한 세계 최초의 제로 샘플 교차 온톨로지 일반화를 지원하는 오픈소스 구현 모델로, 업계에서 큰 의미를 지니고 있습니다. 다양한 구성의 여러 실제 로봇을 구동하여 미세 조정없이 기본 작동 작업을 완료 할 수 있으며, 소량의 샘플 미세 조정 후 복제 기능을 보여줍니다.
훈위안OCR은 텐센트 하이브리드 팀이 오픈소스화한 고성능 광학 문자 인식 모델로, 10억 개의 레퍼런스만 보유하고 있습니다. 하이브리드 멀티모달 아키텍처를 기반으로 개발된 이 모델은 엔드투엔드 설계를 채택하여 텍스트 감지, 인식 및 문서 구문 분석 작업을 효율적으로 처리할 수 있습니다. 이 모델은 복잡한 문서 테스트에서 94.1점을 획득하여 ...
비타벤치는 메이투안의 롱캣 팀이 발표한 복잡한 생활 시나리오를 위한 최초의 대화형 에이전트 평가 벤치마크로, 실제 생활 시나리오에서 대규모 모델 지능의 종합적인 기능을 평가합니다. 테이크아웃 주문, 레스토랑 식사, 여행의 세 가지 빈도가 높은 생활 시나리오는 패키지를 구축하기 위한 캐리어로 사용됩니다....
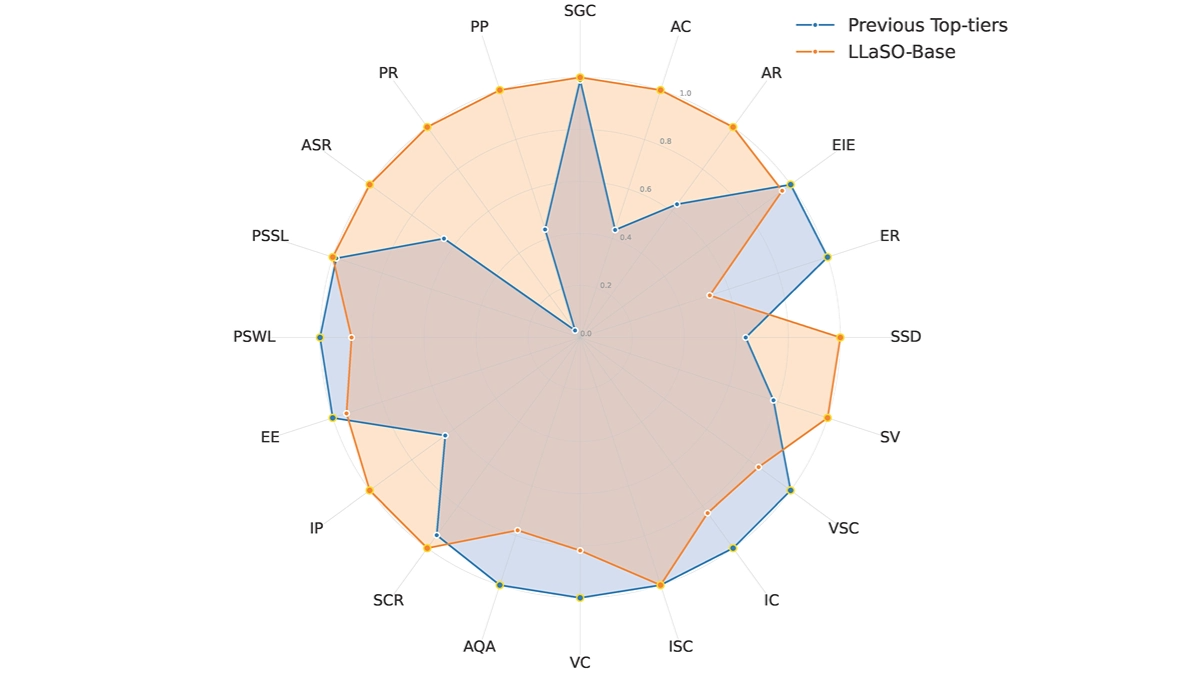
LLaSO는 베이징 뎁스 로직 인텔리전스 테크놀로지가 출시한 오픈 소스 음성 모델로, 음성 및 텍스트 데이터를 통합하고 정렬 데이터 세트, 명령 미세 조정 데이터 세트 및 평가 벤치마크를 제공하여 대규모 음성 언어 모델링 분야의 데이터 분산과 작업 범위 부족 문제를 해결합니다.
Paper2Video는 싱가포르 국립대학교 쇼 랩에서 학술 논문을 위한 자동 프레젠테이션 비디오 생성을 위한 오픈 소스 프로젝트입니다. PaperTalker 다중 지능 프레임워크를 사용하여 논문을 슬라이드, 자막, 음성 해설 및 발표자 아바타가 포함된 완전한 프레젠테이션 비디오로 변환합니다....
KoalaQA는 Chaitin 팀이 개발한 오픈소스 지능형 애프터서비스 시스템입니다. AI 모델을 기반으로 AI 고객 서비스, AI 검색 및 지식 기반 관리 기능을 제공하여 기업이 지능형 Q&A 플랫폼을 신속하게 구축할 수 있도록 지원합니다. 이 시스템은 연중 무휴 실시간 응답을 지원합니다 ...
Pyscn은 파이썬 개발자가 코드의 잠재적 문제를 감지하여 유지보수성을 개선할 수 있도록 설계된 지능형 코드 품질 분석 도구입니다. 제어 흐름도를 통해 데드 코드를 분석하고, APTED+LSH 알고리즘을 사용하여 중복 코드를 식별하고, 모듈 결합 및 원 복잡도와 같은 메트릭을 계산합니다....
MobileLLM-R1은 수학적, 프로그래밍 및 과학적 추론을 위해 설계된 Meta의 효율적인 추론 모델 오픈 소스 시리즈입니다. 여기에는 각각 1억 4천만 개, 3억 6천만 개, 9억 5천만 개의 매개변수 버전이 포함된 기본 모델과 최종 모델이 포함되어 있습니다. 이 모델은 일반적인 채팅 모델이 아니며 미세 조정(SFT...
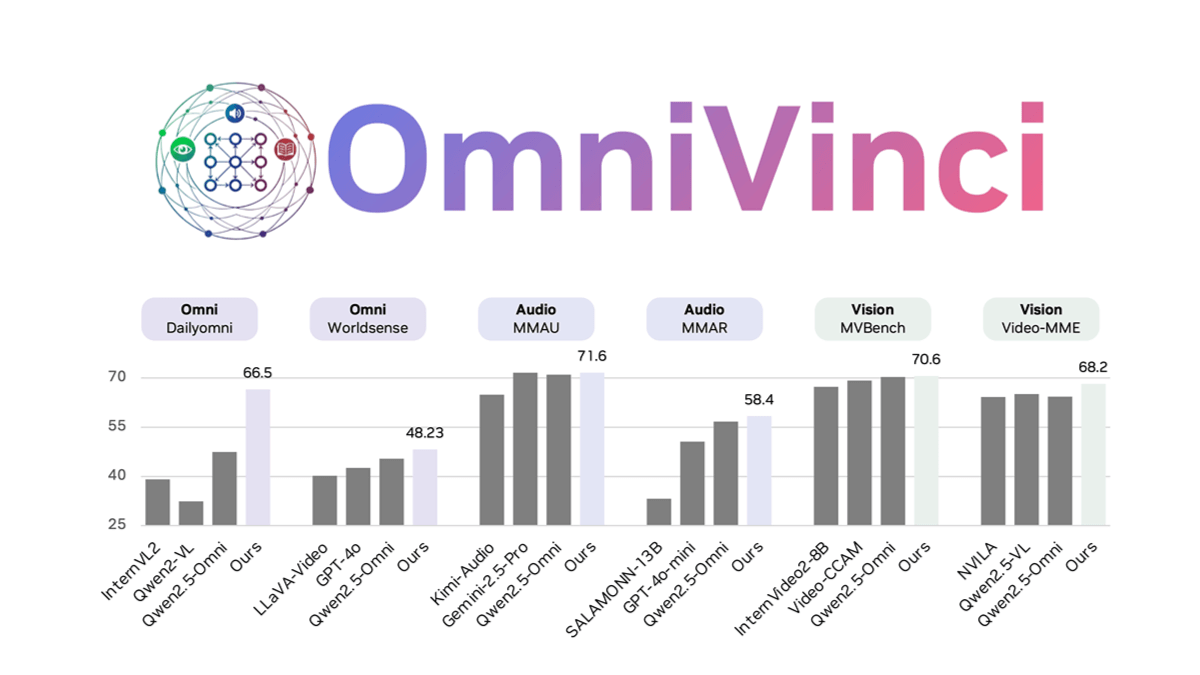
옴니빈치는 아키텍처 혁신과 데이터 최적화를 통해 멀티모달 모델의 모달 파편화 문제를 해결하는 NVIDIA에서 개발한 오픈 소스, 완전 모달, 대규모 언어 모델입니다. 시각 및 오디오 임베딩의 정렬은 일시적으로 임베딩된 그룹 캡처를 활용하는 OmniAlignNet을 통해 향상됩니다.
InternVLA-M1은 상하이 인공 지능 연구소의 오픈 소스로 구현된 운영 '두뇌'로, 명령에 따라 작동하는 두 가지 시스템 운영의 대형 모델입니다. 이 모델은 '사고-행동-학습'을 포괄하는 완전한 폐쇄 루프를 구축하며 높은 수준의 공간 추론과 작업 계획을 담당합니다. 이 모델은 2단계 교육 정책을 채택합니다 ...
Youtu-Embedding은 엔터프라이즈급 애플리케이션을 위해 설계된 Tencent의 Youtu Labs에서 개발한 오픈 소스 범용 텍스트 표현 모델입니다. 텍스트는 심층 신경망에 의해 고차원 벡터 공간에 매핑되어 의미적으로 유사한 문장이 해당 공간에서 서로 가깝게 배치되어 정확한 의미 검색을 달성합니다.
Fun-Audio-Chat-8B는 알리 통이 팀의 오픈 소스 80억 매개 변수 엔드 투 엔드 음성 빅 모델, 음성 출력에서 직접 음성, ASR + LLM + TTS 접합 필요 없음, 중국어와 영어에 유창하며 지연 시간이 짧고 자연스러운 음색을 가진 이중 언어입니다. 25Hz의 이중 해상도 공유 LLM 사용...
월드미러 1.1(월드미러)은 텐센트 월드미러 팀이 출시한 대형 모델의 오픈 소스 3D 재구성으로, 월드미러 시리즈의 업그레이드 버전입니다. 카메라 위치, 내부 참조, 깊이 맵 등과 같은 멀티뷰 이미지, 비디오 및 멀티 모달 선험적 입력을 지원하며, 기존의 3D 재구성에만 의존하는 방식을 탈피하여...
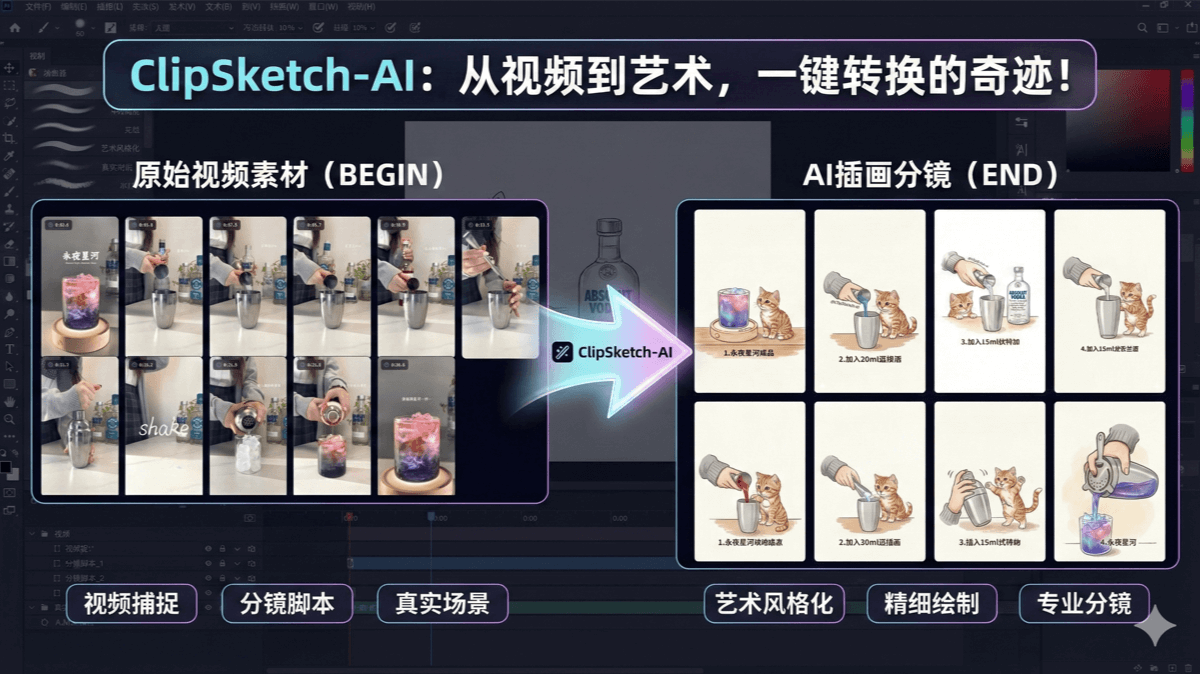
ClipSketch AI는 짧은 동영상 제작자를 위해 설계된 오픈 소스 동영상에서 손으로 그린 분할 화면 도구입니다. B 스테이션, 샤오홍슈 및 기타 플랫폼의 동영상을 한 번의 클릭으로 손으로 그린 스타일의 스토리보드로 변환하고, 키 프레임 표시, 서브 장면 자동 생성 및 소셜 카피를 지원하며, 사용자 정의 역할을 통합할 수 있습니다.
ERNIE-4.5-21B-A3B-Thinking은 추론 작업에 초점을 맞춘 바이두의 오픈 소스 대규모 언어 모델입니다. 혼합 전문가(MoE) 아키텍처를 사용하여 총 참조 수는 210억 개에 달하며, 각 토큰은 30억 개의 매개 변수를 활성화하여 128K의 긴 컨텍스트 창을 지원합니다 ...
OpenAutoGLM은 다중 모드 인식을 통해 휴대폰 화면의 내용을 이해하고 사용자가 지정한 작업을 완료하기 위해 작업 흐름을 자동으로 생성 할 수있는 "휴대폰 사용"기능을 갖춘 오픈 소스 지능형 신체 모델입니다. 사용자는 "근처 훠궈를 검색하려면 메이투안을 열어..."와 같이 자연어를 사용하여 요구 사항을 설명하기만 하면 됩니다.
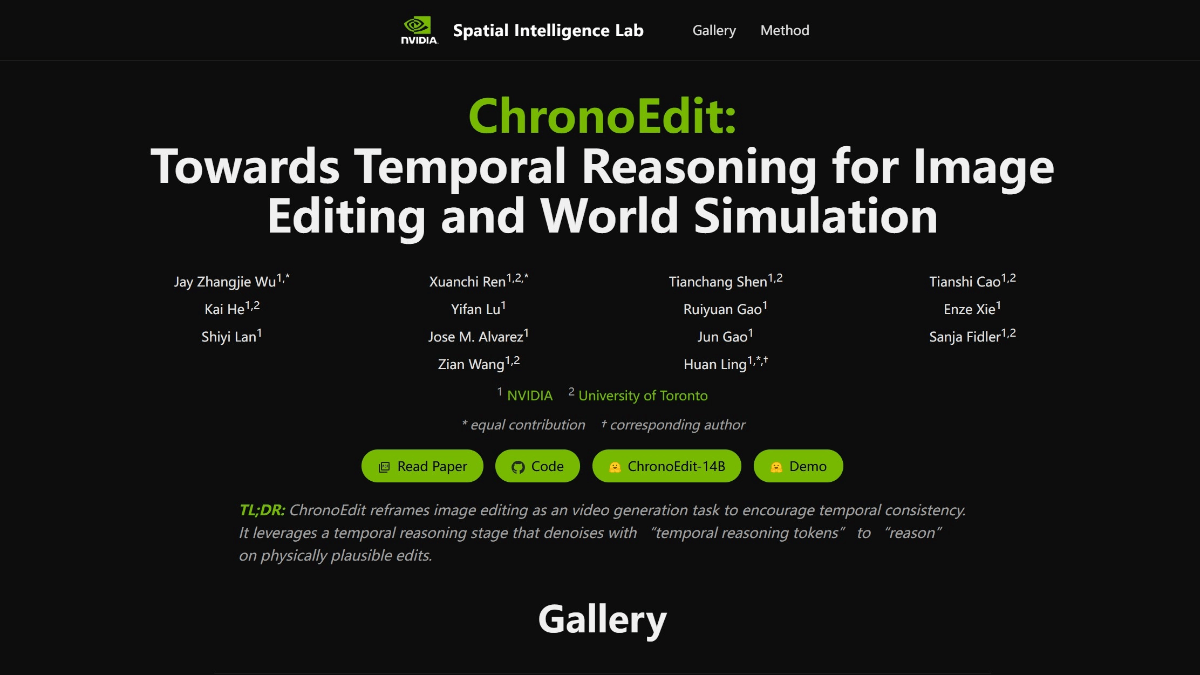
NVIDIA와 토론토 대학교가 공동 개발한 오픈 소스 AI 이미지 편집 프레임워크인 ChronoEdit는 이미지 편집 작업을 비디오 생성 작업으로 재정의하여 편집 결과가 시간적, 물리적으로 일관성을 유지하도록 합니다. 14억 개의 파라미터로 사전 훈련된 비디오 생성 모델을 추출하여 ...
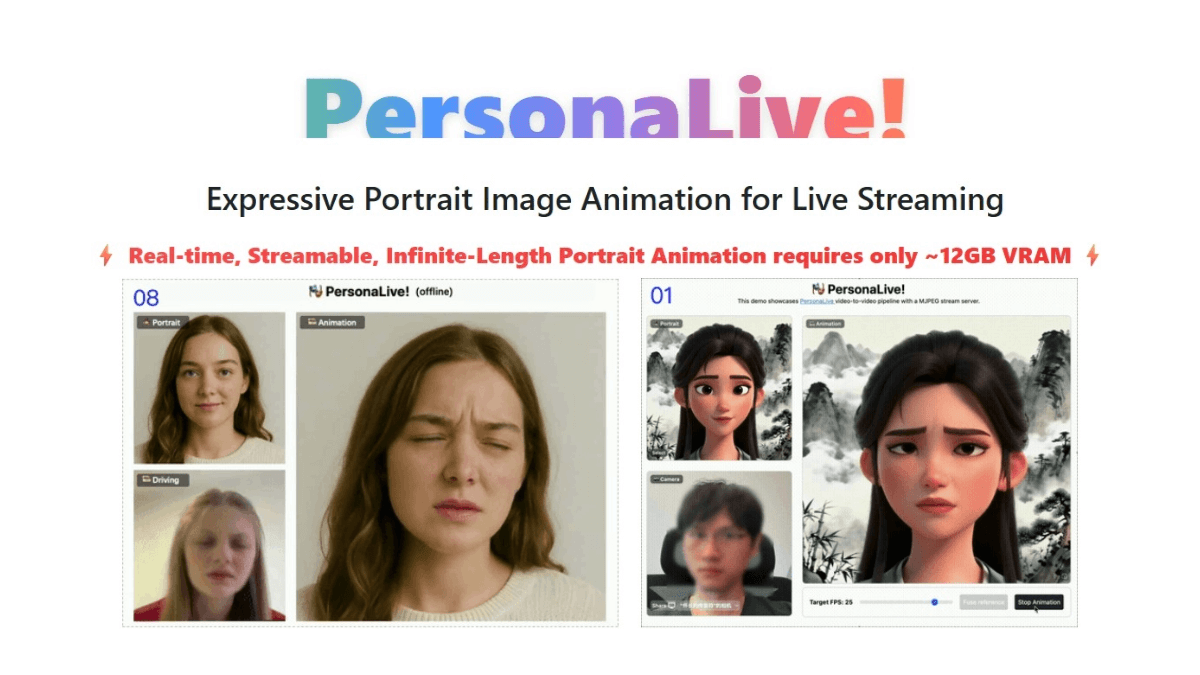
페르소나라이브는 마카오 대학교, dzine.ai, 그레이터 베이 지역 대학교의 GVC 랩이 공동 개발한 오픈 소스 실시간 AI 얼굴 교체 라이브 스트리밍 프레임워크입니다. 일반 소비자용 그래픽 카드(12GB 비디오 메모리)에서 지연 시간이 짧고 프레임 속도가 빠른 디지털 퍼스널 드라이브를 구현할 수 있으며 카메라를 통한 실시간 스트리밍을 지원합니다....
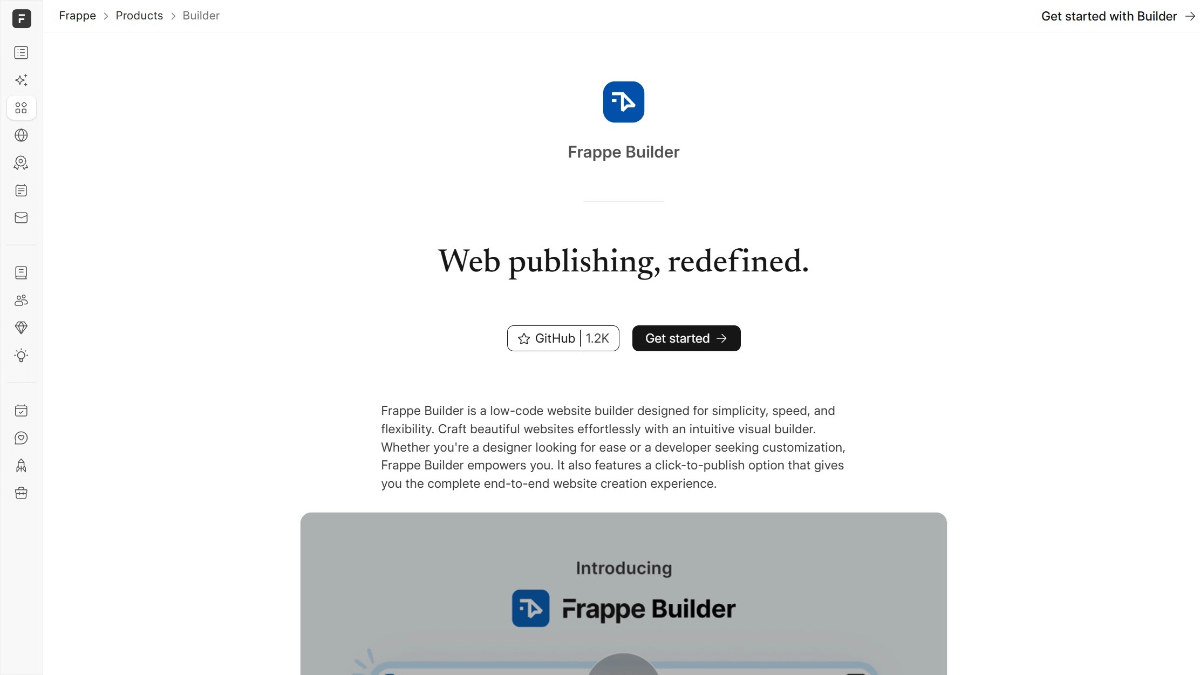
Frappe 빌더는 Frappe에서 개발한 오픈 소스 로우코드 웹사이트 빌더로, 핵심 기능은 드래그 앤 드롭 구성 요소를 지원하는 Figma와 유사한 시각적 편집기를 제공하여 웹사이트를 빠르게 구축할 수 있도록 하는 것입니다. Frappe 생태계의 일부(Frappeverse)...
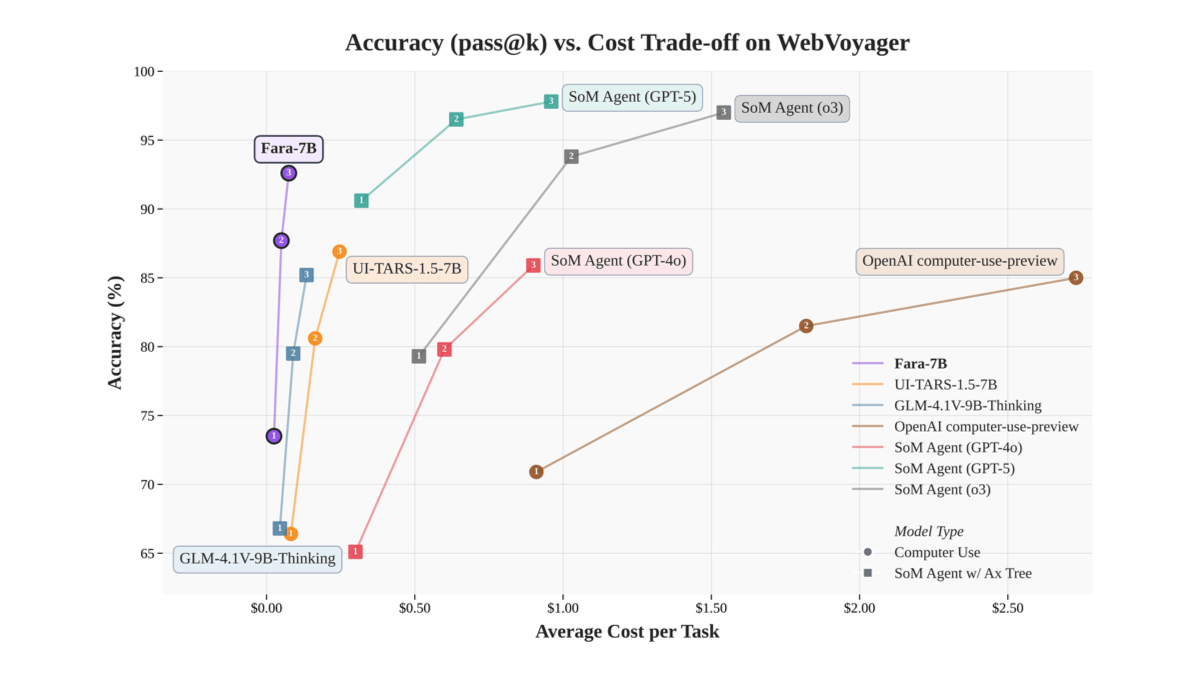
Fara-7B는 Qwen 2.5-VL-7B 아키텍처를 기반으로 하는 70억 개 매개변수 규모의 컴퓨터 운영 에이전트(CUA) 모델의 Microsoft 오픈 소스 릴리스입니다. 웹 페이지의 스크린샷을 시각적으로 구문 분석하고 화면에서 클릭, 입력 등을 수행함으로써 추가적인 접근성 트리나 여러 개의 대형 모델에 의존할 필요가 없습니다....
Step-Audio-EditX는 스텝스타 팀이 개발한 오픈 소스 오디오 편집 매크로 모델로, 인공 지능 기술을 통한 오디오 콘텐츠의 세밀한 조작에 중점을 두고 있습니다. 이 모델은 오디오 분위기, 말하기 스타일(예: 투정, 노인 억양 등) 및 반언어적 요소(예: 웃음, 한숨...)를 동적으로 조정할 수 있습니다.
오픈에이전트는 AI 에이전트 네트워크를 생성하고 에이전트 간의 개방형 협업을 촉진하는 오픈 소스 프로젝트입니다. AI 에이전트가 원활하게 연결하고 협업할 수 있도록 기본 네트워크 인프라가 제공됩니다. 사용자는 자체 에이전트 네트워크를 빠르게 시작하고, 모듈식 아키텍처를 통해 기능을 확장하고, 지원...
Astron Agent는 KDDI의 오픈 소스 엔터프라이즈급 지능형 워크플로 개발 플랫폼으로, 기업이 착륙 가능한 AI 에이전트 애플리케이션을 신속하게 구축할 수 있도록 지원하는 데 중점을 두고 있습니다. Java + Spring Boot 기술 스택 사용, 경량 프라이빗 배포 지원(최소 2코어 4G 구성), 내장 ...
SAM 3D는 Meta의 SAM 시리즈를 기반으로 하는 3D 재구성 모델로, SAM 3D 오브젝트와 SAM 3D 바디의 두 가지로 구성되어 있습니다. SAM 3D 오브젝트는 단일 사진에서 인터랙티브 3D 오브젝트 모델을 생성할 수 있으며, 다음과 같은 기능을 지원합니다.
SurfSense는 오픈 소스 AI 리서치 및 지식 관리 도구입니다. 고도로 사용자 정의가 가능하며 검색 엔진, Slack, Jira, Notion, YouTube, GitHub 및 기타 여러 외부 데이터 소스에 연결하여 사용자가 정보를 쉽게 통합할 수 있습니다. 사용자는 다양한 자료를 업로드할 수 있습니다.
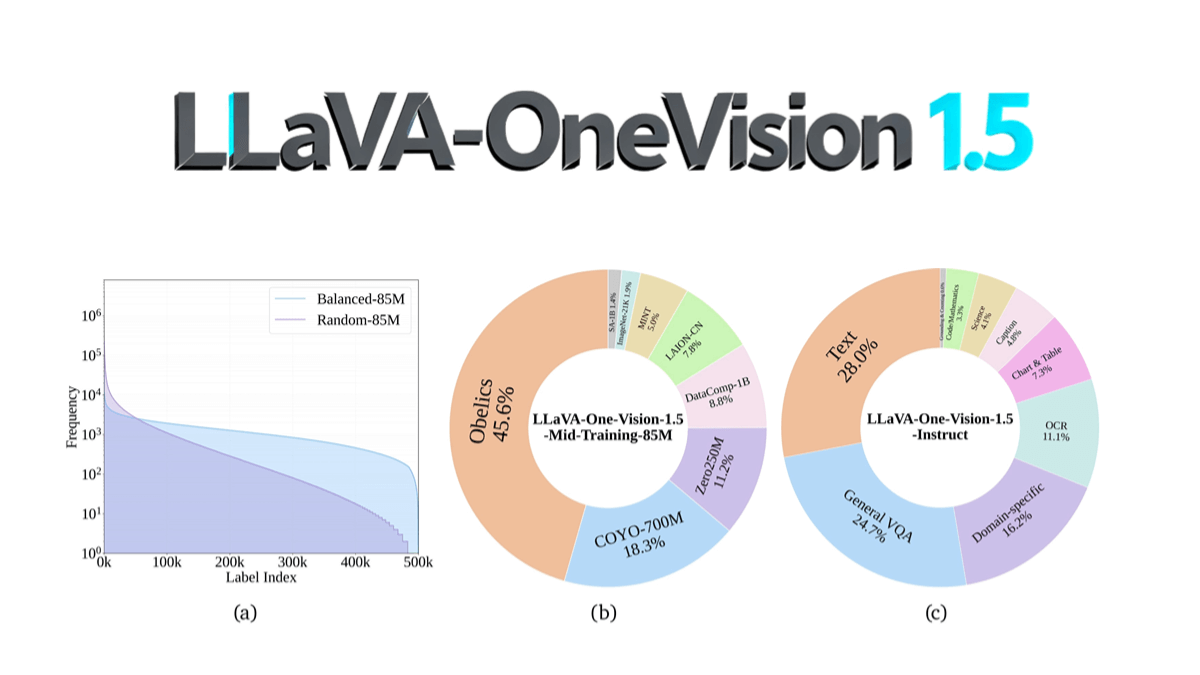
LLaVA-OneVision-1.5는 128개의 A800...에서 8B 파라미터 스케일을 사용하는 EvolvingLMMS-Lab 팀의 오픈 소스 멀티모달 모델로, 컴팩트한 3단계 훈련 프로세스(언어-이미지 정렬, 개념 평형화 및 지식 주입, 명령어 미세 조정)를 통해 학습합니다.
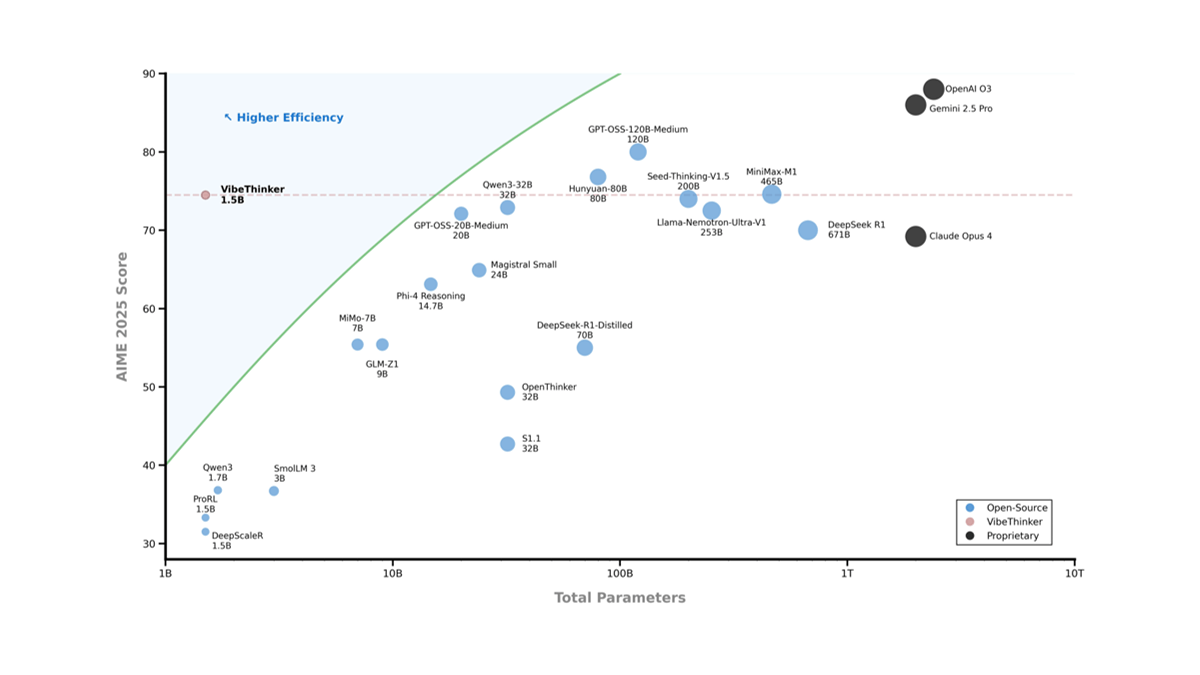
바이브씽커-1.5B는 웨이보 AI에서 오픈소스로 제공하는 15억 개의 파라미터를 가진 대규모 언어 모델입니다. 알리바바의 Qwen2.5-Math-1.5B를 기반으로 미세 조정된 이 모델은 수학 및 코딩 작업에 최적화되어 있으며 업계 최고의 추론 성능으로 뛰어난 성능을 발휘합니다.
노코베이스는 AI 기반 오픈 소스 노코드 개발 플랫폼을 기반으로 비즈니스 시스템의 신속한 구축을 지원하며, 애플리케이션 개발 구성을 통해 프로그래밍을 완료 할 수 없습니다. 이 프로젝트는 Apache-2.0 프로토콜을 사용하고 기업 관리, 협업 플랫폼 및 기타 분야에 적합한 개인 배포 및 유연한 확장 성을 제공합니다 ...
KAT-Dev-72B-Exp는 레이서 팀에서 출시한 오픈소스 프로그래밍 전용 대규모 언어 모델로, 강화 학습 기법을 기반으로 최적화되어 SWE-Bench Verified 벤치마크 테스트에서 현재 오픈소스 모델 중 최고 성능인 74.6%의 정확도를 달성했습니다. 이 모델은 혁신적인...
토크코디는 무료 오픈 소스 AI 프로그래밍 어시스턴트 데스크톱 애플리케이션으로, Rust + 타우리 2를 기반으로 구축되어 Windows, macOS, Linux 세 가지 플랫폼을 지원하며 기본 성능, 빠른 시작, 낮은 리소스 사용량 등의 이점을 제공합니다. 50 개 이상의 주류 A 지원 ...
멤머신은 멤버지가 개발한 오픈 소스 AI 메모리 시스템으로, 인간의 뇌처럼 상호 작용 데이터를 저장하고 불러올 수 있어 AI의 '상태 없는 메모리 손실' 문제를 해결하는 AI 모델과 지능을 위해 설계되었습니다. 계층화된 아키텍처(단기 메모리, 장기 메모리, 사용자 이미지, ...
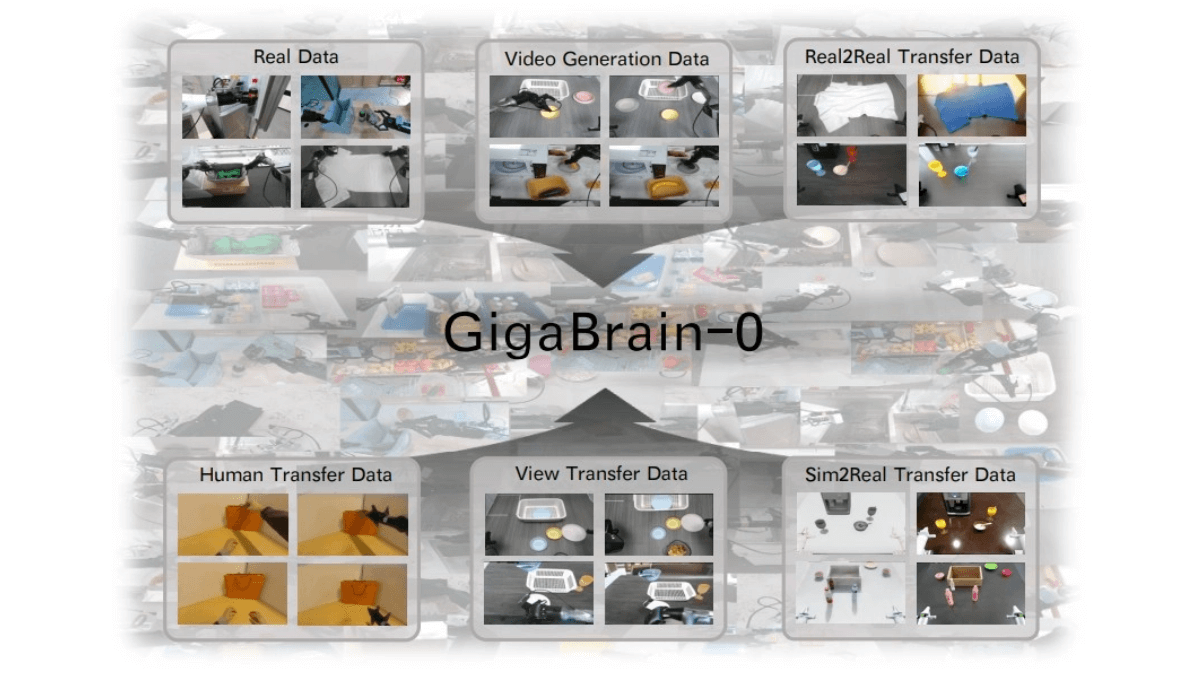
기가브레인-0은 세계 모델 생성 데이터를 사용하여 실제 머신 일반화를 달성하는 중국 최초의 엔드투엔드 비전-언어-액션(VLA) 구현 기본 모델로, 기가비전과 후베이 휴머노이드 로봇 혁신 센터가 오픈 소스로 공동 출시했습니다. 하이브리드 트랜스포머 아키텍처를 채택하여 ...
덱스보틱은 체화지능 분야의 파편화와 낮은 연구 효율성 문제를 해결하는 덱스말의 오픈소스 시각-언어-행동(VLA) 모델의 체화지능 원스톱 연구 서비스 플랫폼입니다. 덱스보틱은 파이토치를 기반으로 구현 지능 분야의 파편화와 낮은 효율성 문제를 해결하기 위한 원스톱 연구 서비스 플랫폼입니다...
코이나는 프로테오믹스 데이터 분석을 간소화하는 데 중점을 둔 오픈 소스 분산형 머신 러닝 플랫폼입니다. 독일 뮌헨 공과대학교와 미국 미시간 대학교의 연구팀이 개발했습니다. 이 플랫폼은 표준화된 인터페이스를 통해 30개 이상의 주류 모델(예: ProSIT, MS²PIP)을 통합하고 펩타이드 질량...
NewBie-image-Exp0.1은 NewBieAI-Lab 팀이 오픈소스화한 최초의 실험적인 애니메이션 텍스트 기반 그래픽 모델로, 보조 스타일에 최적화된 35억 개의 파라미터가 포함된 Next-DiT 아키텍처를 사용합니다. 이 모델은 듀얼 텍스트 인코더(GEMMA3-4B)를 통해 2차 스타일에 최적화되어 있습니다.
슈퍼토닉은 로컬 장치에서 빠른 음성 생성에 초점을 맞춘 오픈 소스 고성능 텍스트 음성 변환(TTS) 시스템입니다. ONNX 런타임 기술을 사용하여 휴대폰, 컴퓨터, 심지어 라즈베리 파이와 같은 장치에서 실행할 수 있고 23개 언어와 음성 클론을 지원하며 네트워크가 필요하지 않습니다....
InfinityStar는 고해상도 이미지 및 동영상 생성을 위해 설계된 ByteDance에서 오픈소스화한 통합 시공간 자동 회귀 프레임워크입니다. 개별 자동 회귀 접근 방식을 사용하여 단일 모델에서 텍스트 대 이미지, 텍스트 대 비디오 및 이미지 대 비디오 작업을 동시에 처리할 수 있습니다. 이 프레임워크는 VBench에서 벤치마킹되었습니다 ...
유니월드 V2는 래빗잔 인텔리전스와 북경대학교의 유니월드 팀이 공동으로 출시한 차세대 이미지 편집 모델입니다. 이미지 편집 분야, 특히 복잡한 명령의 중국어 이해와 실행에 있어 상당한 이점을 가지고 있습니다. 이 모델은 예술적인 중국어 글꼴을 정확하게 렌더링하고 미세한 글꼴을 지원할 수 있습니다.
GLM-4.6V는 스마트 스펙트럼 AI에서 오픈소스화한 멀티모달 대규모 언어 모델 시리즈로, 클라우드 및 고성능 클러스터 시나리오를 위한 기본 버전인 GLM-4.6V(106B-A12B)와 혼합 전문가(MoE) 아키텍처, 총 약 106억 개의 레퍼런스, 활성화... 등 두 가지 버전이 있습니다.
Vidi2는 비디오 콘텐츠 이해, 분석 및 생성에 중점을 둔 2세대 멀티모달 비디오 이해 및 생성 빅모델로, ByteDance에서 오픈소스화했습니다. 텍스트, 비디오 및 오디오 모달리티의 공동 입력을 지원하며, 사진 콘텐츠, 사운드 정보 및 자연어 명령을 동시에 이해하여 모달 간 상호 작용 및 푸시 기능을 구현할 수 있습니다.
PartCrafter는 북경대학교, 바이트댄스, 카네기멜론대학교가 공동으로 제안한 고급 3D 생성 모델입니다. 단일 RGB 이미지에서 의미적으로 명확하고 기하학적으로 다양한 3D 메시 파트를 한 번에 여러 개 생성할 수 있습니다. 이 모델은 조합 잠재 공간을 통해 모델링되며 ...
Bee는 데이터 품질을 개선하여 오픈 소스 모델과 폐쇄 소스 모델 간의 성능 격차를 좁히기 위해 텐센트 혼합 요소 팀과 칭화대학교가 공동으로 출시한 풀스택 오픈 소스 멀티모달 빅 모델 솔루션입니다. 이 프로젝트에는 세 가지 핵심 성과가 포함되어 있습니다. 1,500만 개 규모의 고품질 2계층 CoT 데이터 세트 Honey-Data...