
GLM-5.2是什么
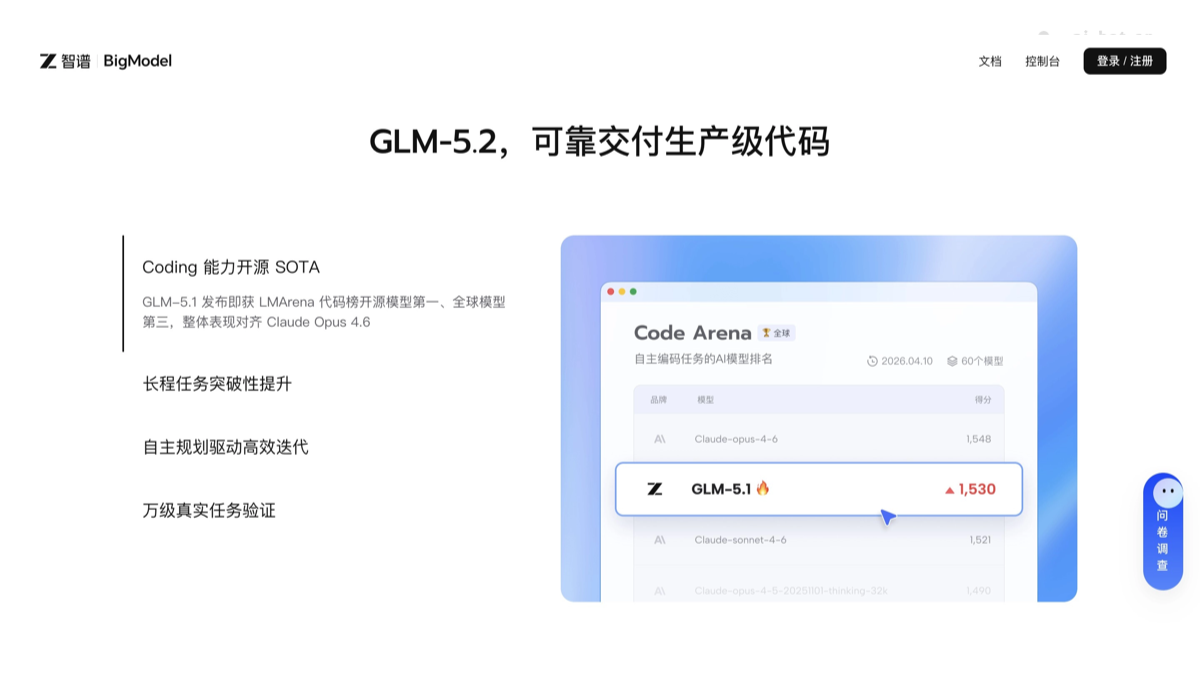
GLM-5.2 是智谱最新推出的旗舰级开源大模型,超长上下文理解和智能编程为核心卖点。模型具备百万级 token 的上下文处理能力,能一次性分析整个代码仓库或长篇技术文档。模型训练全程基于国产华为昇腾芯片与 MindSpore 框架,摆脱对 NVIDIA 硬件的依赖。在软件工程任务表现上,GLM-5.2 已达到国际顶尖闭源模型 Claude Opus 4.8 的水平。
GLM-5.2的功能特色
- 百万级上下文理解:单次可处理相当于数百万字符的文本输入,适用大型项目代码分析、长篇小说理解、复杂多轮对话等场景。
- 自主编程智能体:具备端到端的软件工程能力,能够自主规划、调用工具、执行多步骤任务,可持续工作数小时完成复杂开发流程。
- 双模式推理切换:提供深度思考与快速响应两种工作模式,用户可根据任务难度自由切换,兼顾质量与效率。
- 全链路代码辅助:覆盖从需求分析、代码生成、缺陷修复、重构优化到代码审查的完整开发周期。
- 跨文件工程分析:理解项目级代码结构,识别模块间依赖关系,支持全局性的架构调整和优化建议。
- 外部工具生态对接:通过函数调用机制连接数据库、搜索引擎、版本控制系统等外部服务,扩展模型能力边界。
- 灵活部署方案:支持在主流推理框架上进行本地私有化部署,满足企业数据安全和定制化需求。
GLM-5.2的核心优势
- 真正可用的长上下文:1M tokens 窗口非纸面参数,而是在长程依赖任务中保持稳定的实际性能。
- 开源自由度极高:MIT 协议意味着零门槛的商业使用、修改和分发,无需担心授权限制。
- 国产技术栈闭环:从芯片到框架的全链路国产化,保障技术自主可控,规避地缘政治风险。
- 长时自主工作流:独特的 Agentic Coding 能力使其能够持续执行长达 8 小时的复杂编程任务,减少人工干预。
- 推理成本可控:双模式设计让用户在低难度任务上使用轻量推理,避免为简单问题支付过高的算力成本。
- 国际竞争力:在 SWE-Bench 等权威编程评测中表现优异,具备与全球最强闭源模型竞争的实力。
GLM-5.2官网是什么
GLM-5.2的操作步骤
- API 集成:本周正式开放 API 接口,开发者可获取密钥后将其接入 IDE 插件、自动化脚本或自有产品。
- 模式选择:面对算法设计等复杂问题启用思考模式,日常问答和简单代码补全使用标准模式。
- 长文本处理:直接上传整个项目目录、技术白皮书或系统日志,利用超长上下文进行全局分析。
- 本地部署:开源权重发布后,企业可基于 SGLang、vLLM 等框架在私有服务器上部署,确保数据不出域。
- 领域定制:借助 MIT 协议的自由度,使用行业特定代码库进行微调,构建专属编程助手。
GLM-5.2的适用人群
- 软件工程师:用双模式推理处理日常编码与复杂算法设计,提升开发效率。
- 企业技术团队:通过私有化部署满足数据安全合规需求,实现国产化算力替代。
- 开源社区开发者:基于 MIT 协议自由微调、商用集成,构建垂直领域编程助手。
- 大型项目架构师:借助 1M 上下文一次性分析整个代码仓库,完成全局架构重构。
- 遗留系统维护者:理解老旧代码库逻辑,自动生成技术栈迁移方案与现代化改造代码。
GLM-5.2的常见问题
Q:GLM-5.2 什么时候开源?
A:本周正式开源模型权重,遵循 MIT 协议,可自由下载、商用和二次微调。
Q:API 什么时候上线?
A:API 将于下周正式上线,届时开发者可通过智谱开放平台获取 Key 进行接入。
Q:现在如何直接使用?
A:已面向 GLM Coding Plan 全量用户开放,登录智谱开放平台或 Z.ai 即可在 Lite / Pro / Max / 团队版中选用。
Q:上下文窗口到底多大?
A:支持 1M tokens(100 万 token)超长上下文,可一次性处理整个代码库或长篇文档。
Q:需要 NVIDIA 显卡吗?
A:不需要。模型基于华为昇腾芯片与 MindSpore 框架训练,部署和推理均无 NVIDIA 依赖。
Q:支持哪些推理模式?
A:支持思考模式(Thinking)与标准模式(Standard)双模式切换,复杂任务深度推理,简单任务快速响应。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...