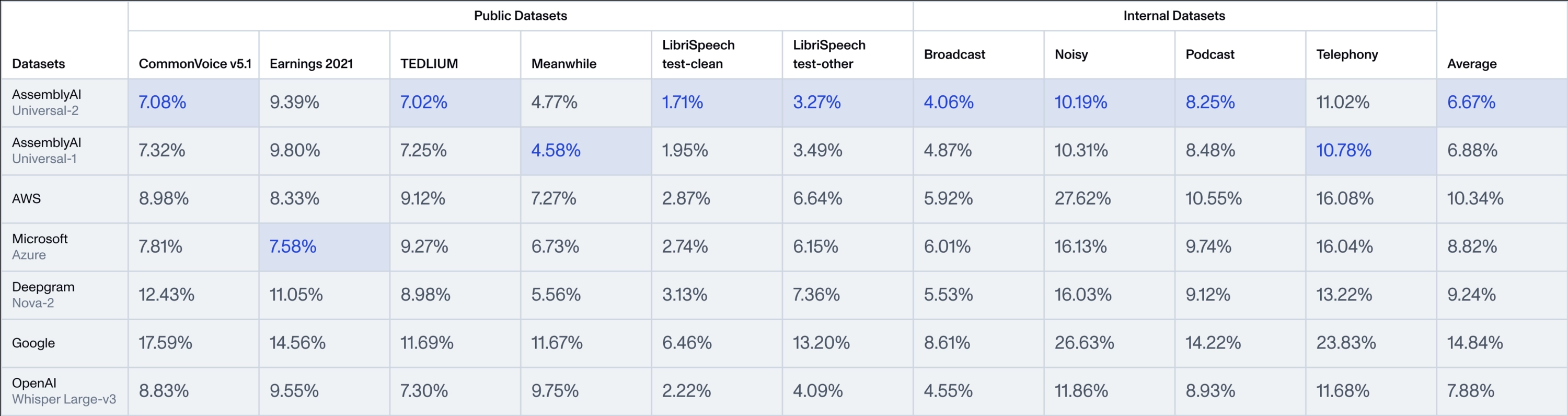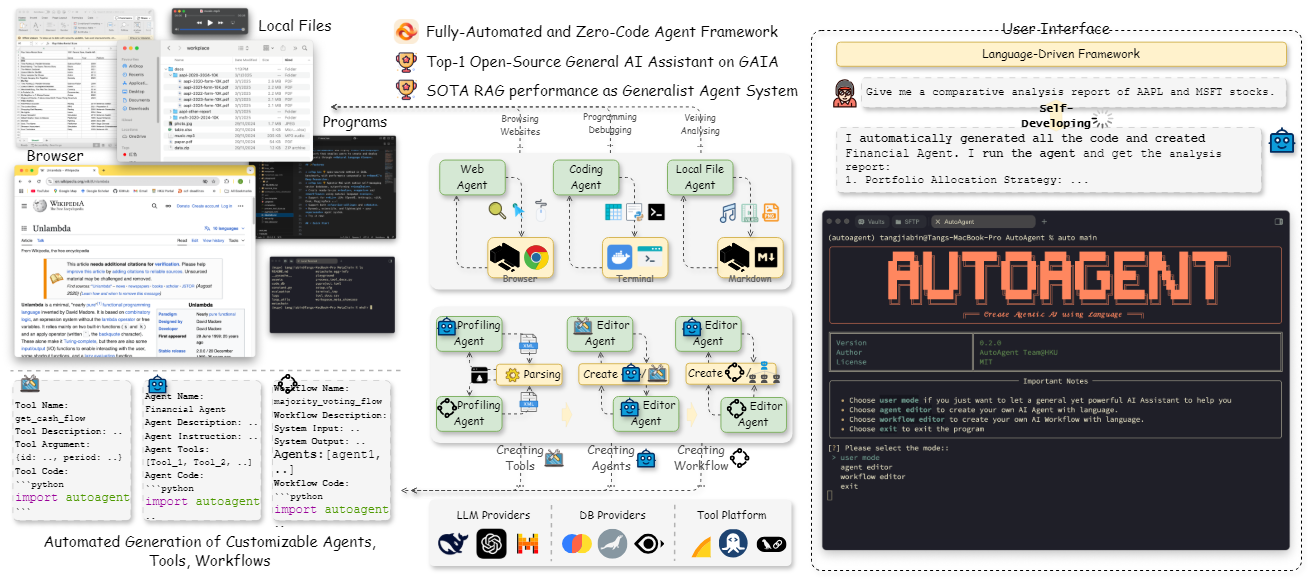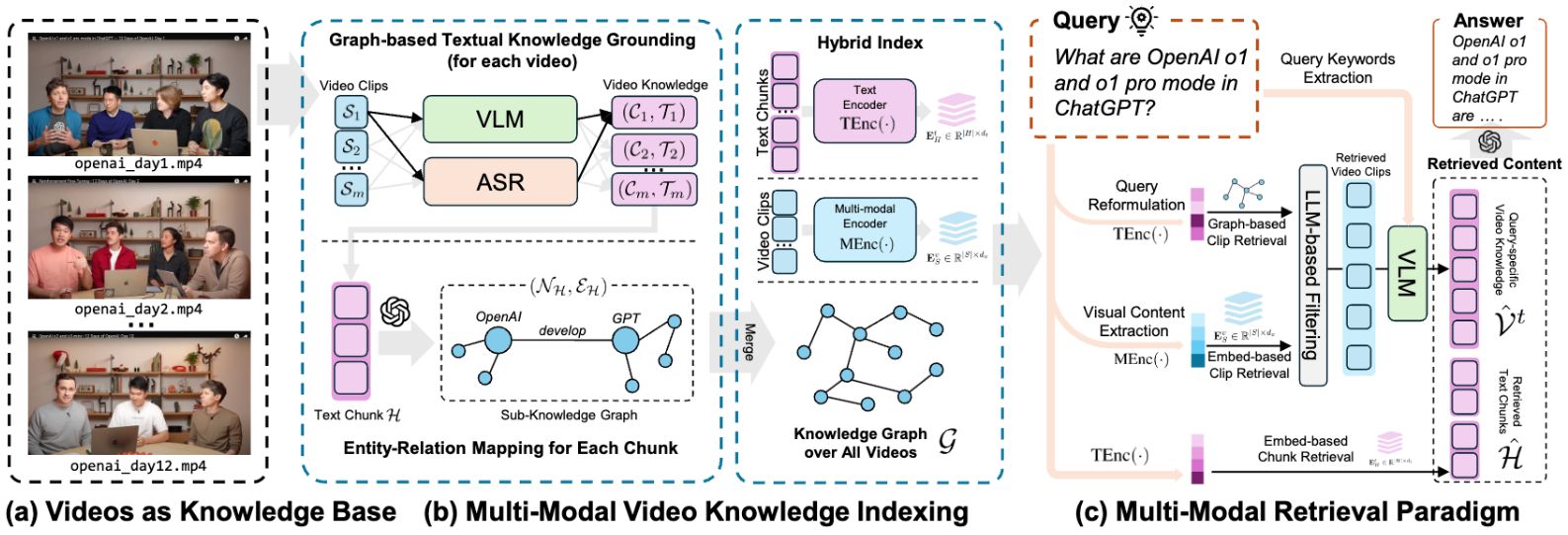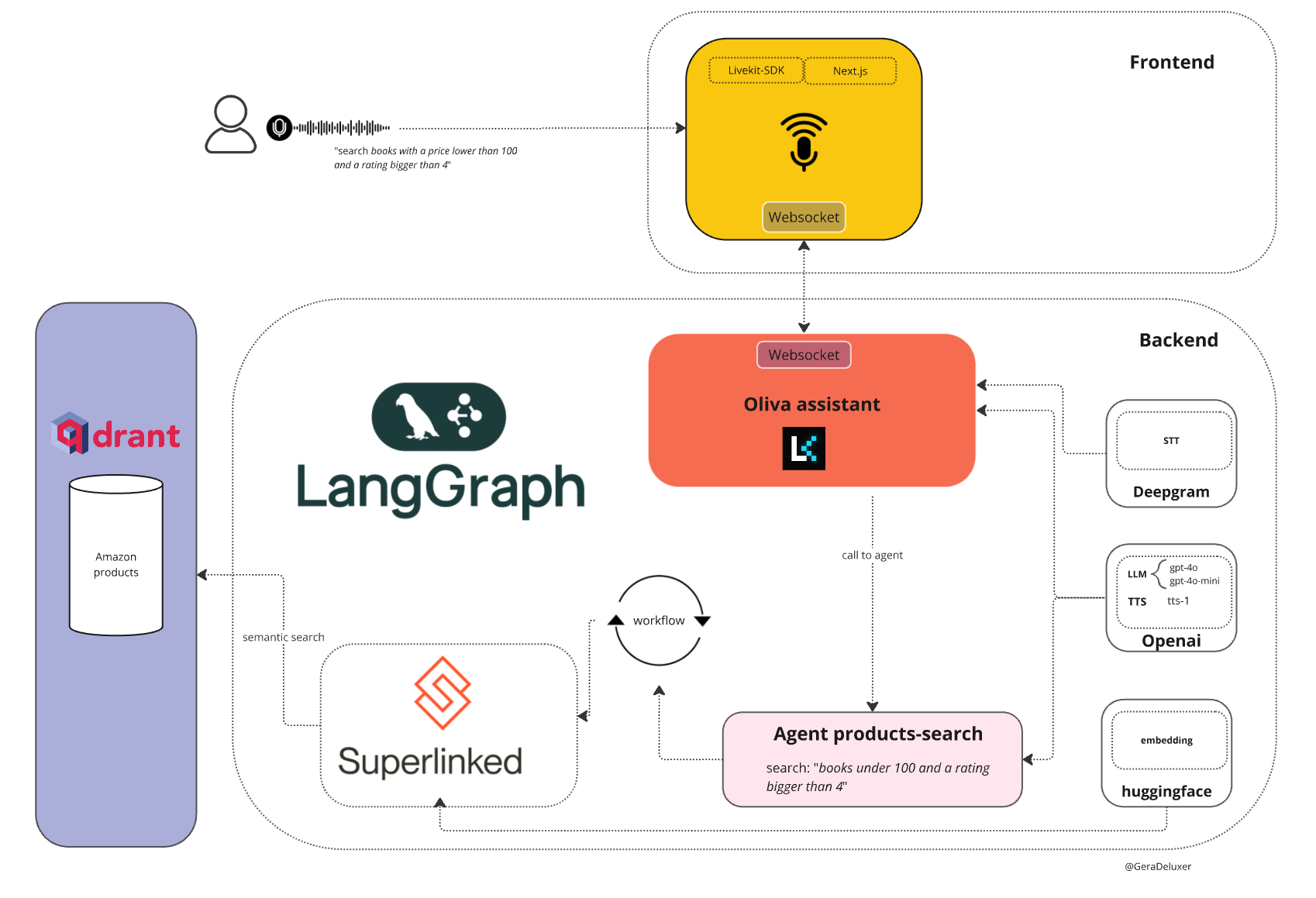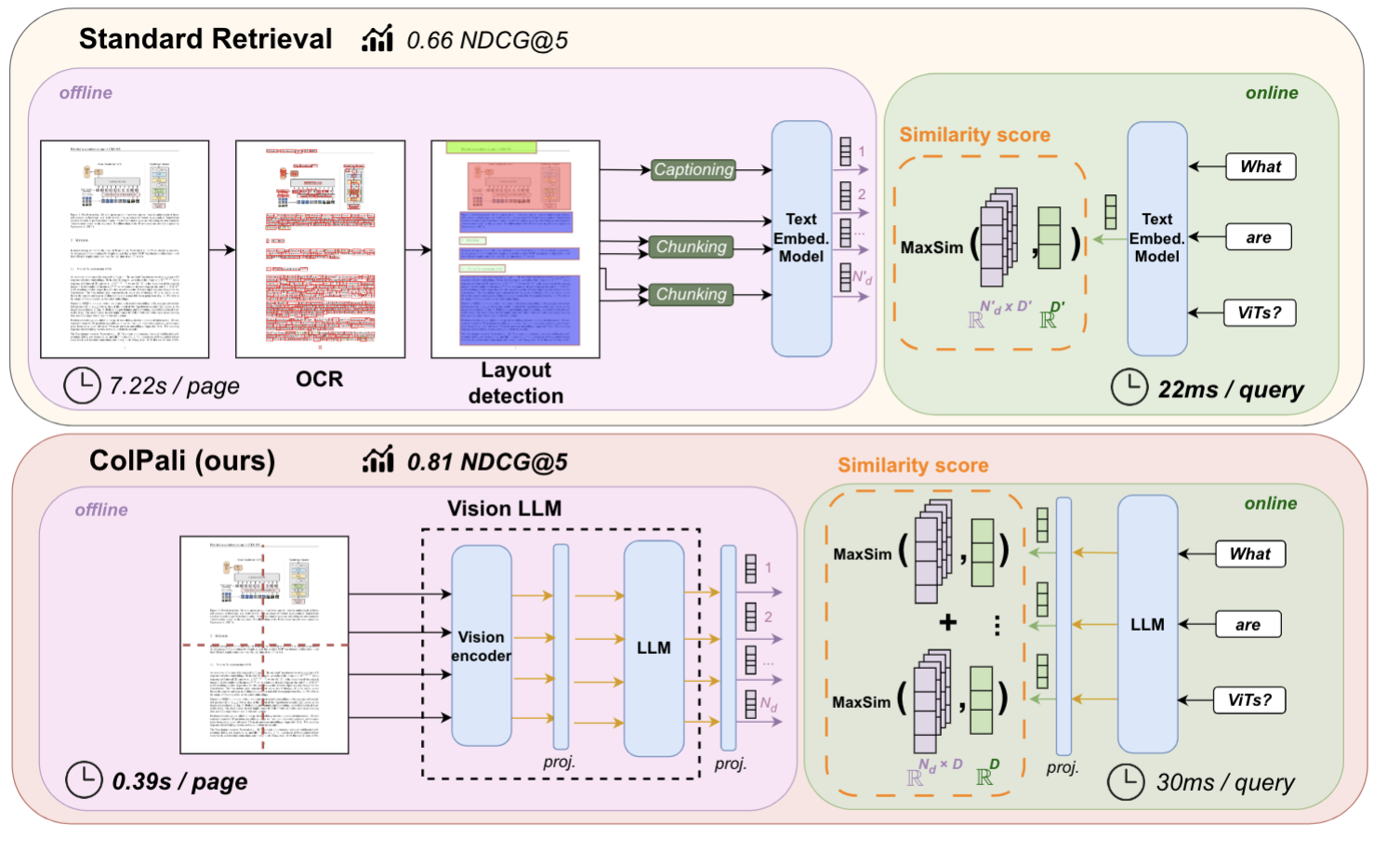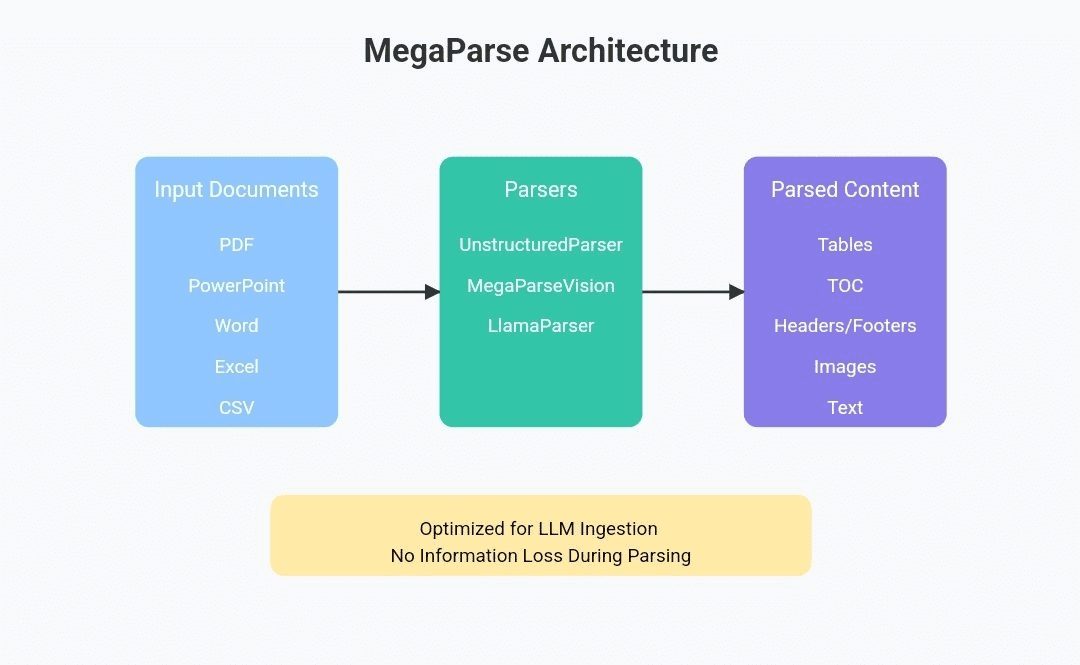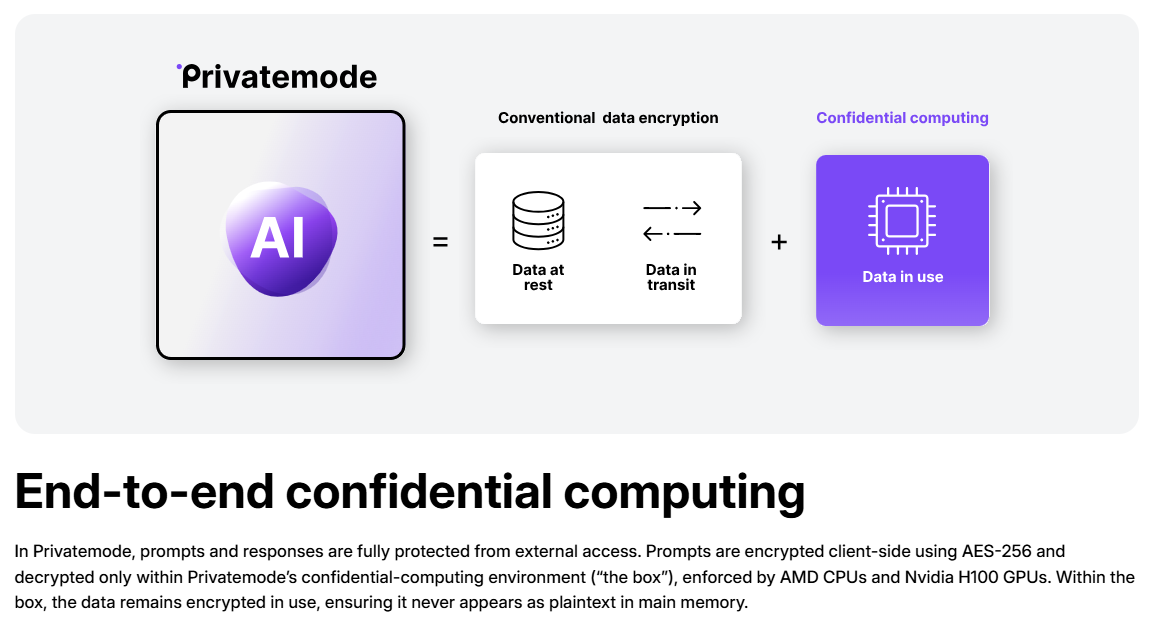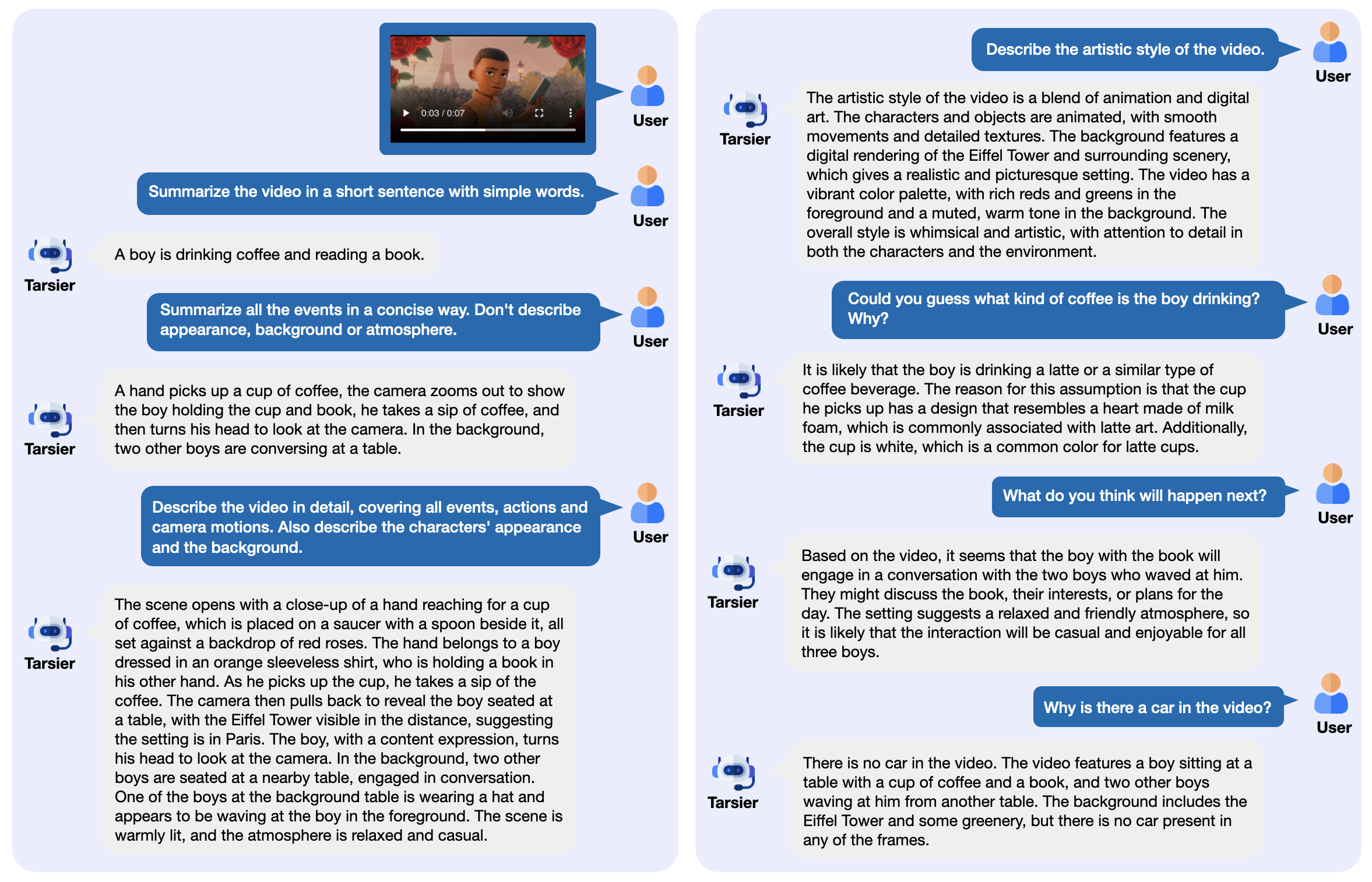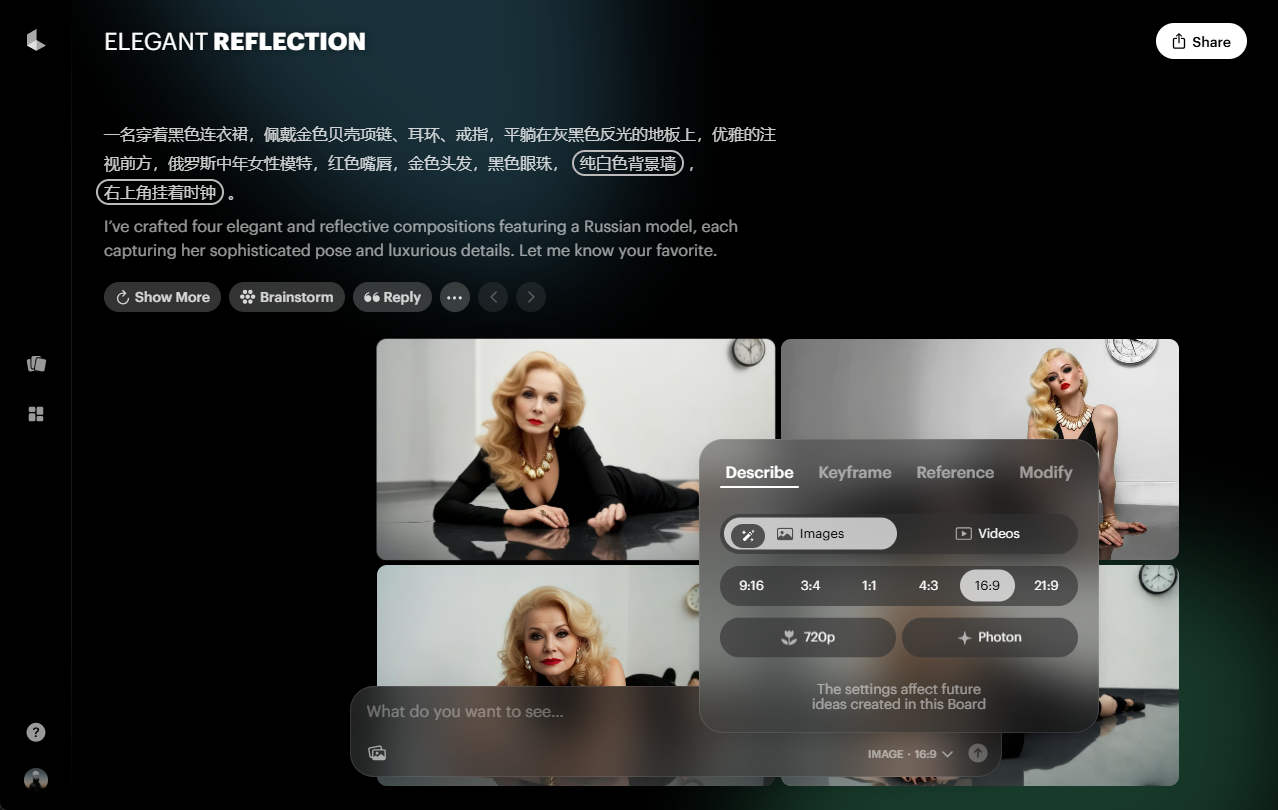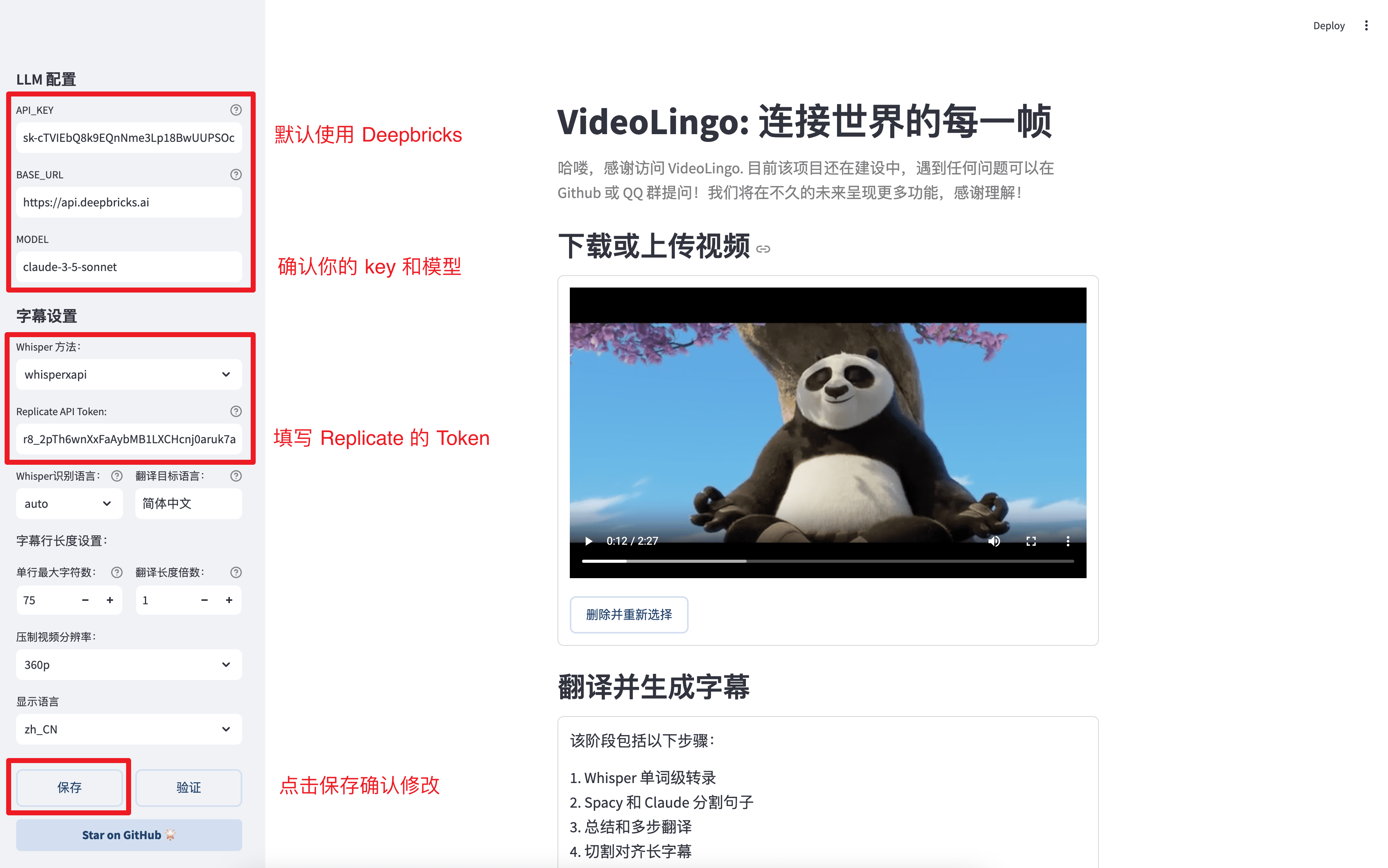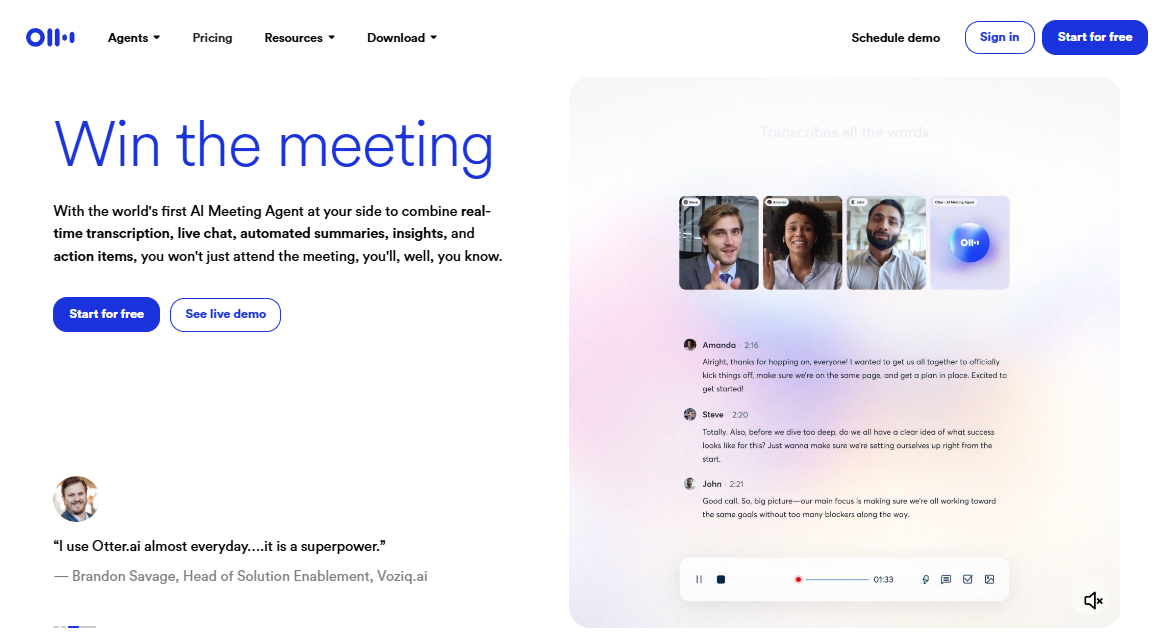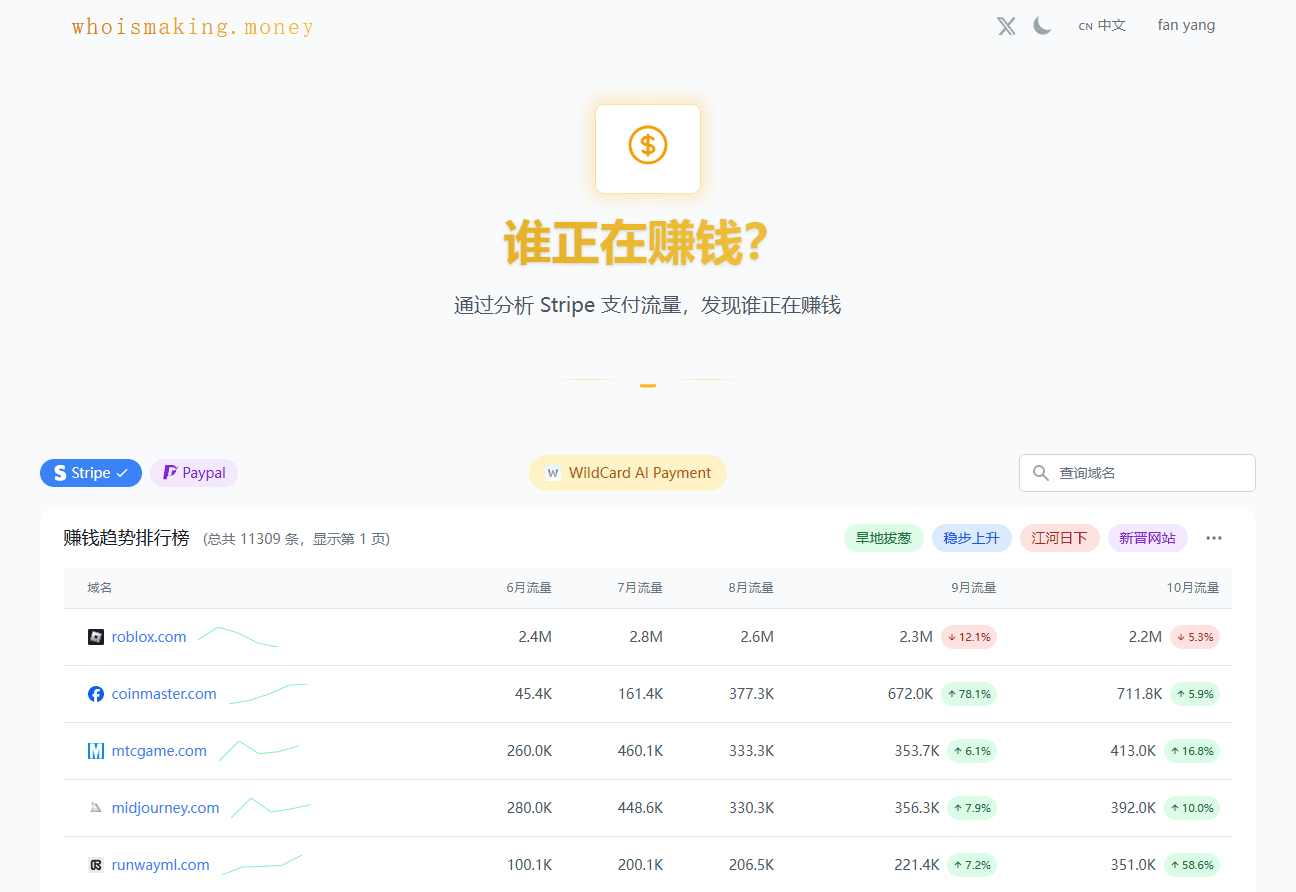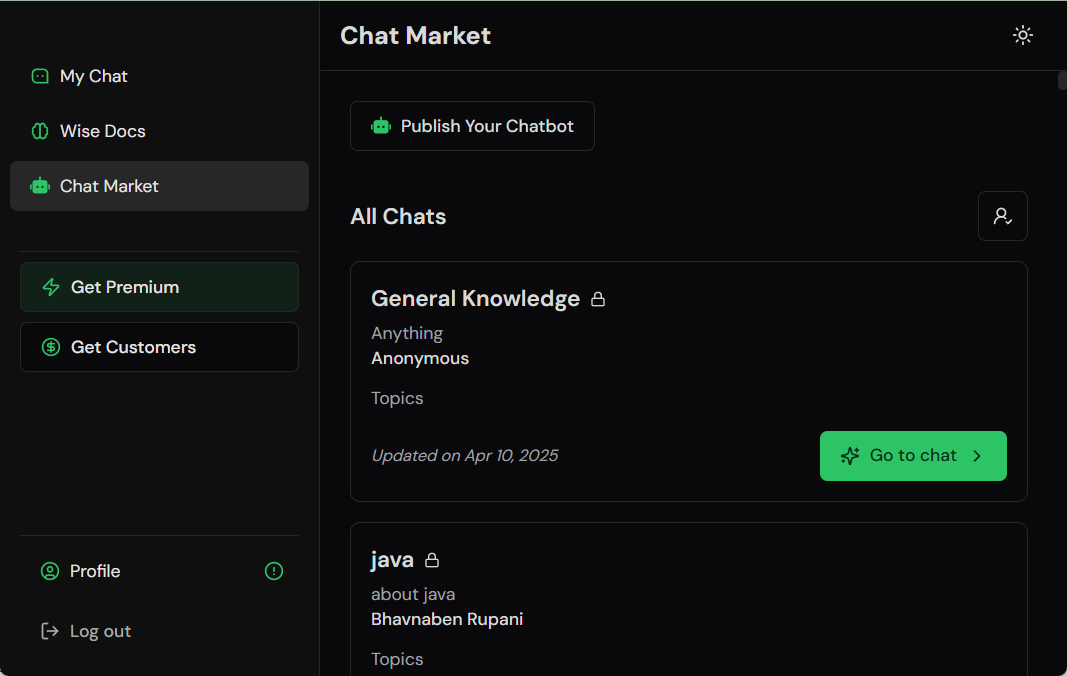
Chatwise: the AI chatbot that shares knowledge into revenue
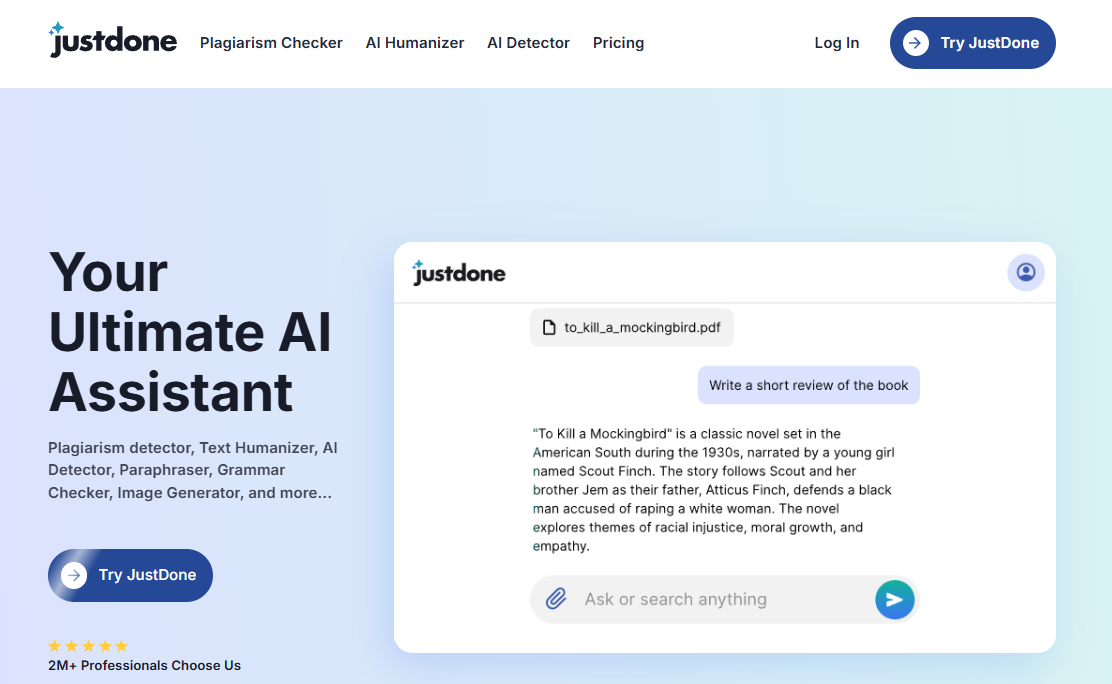
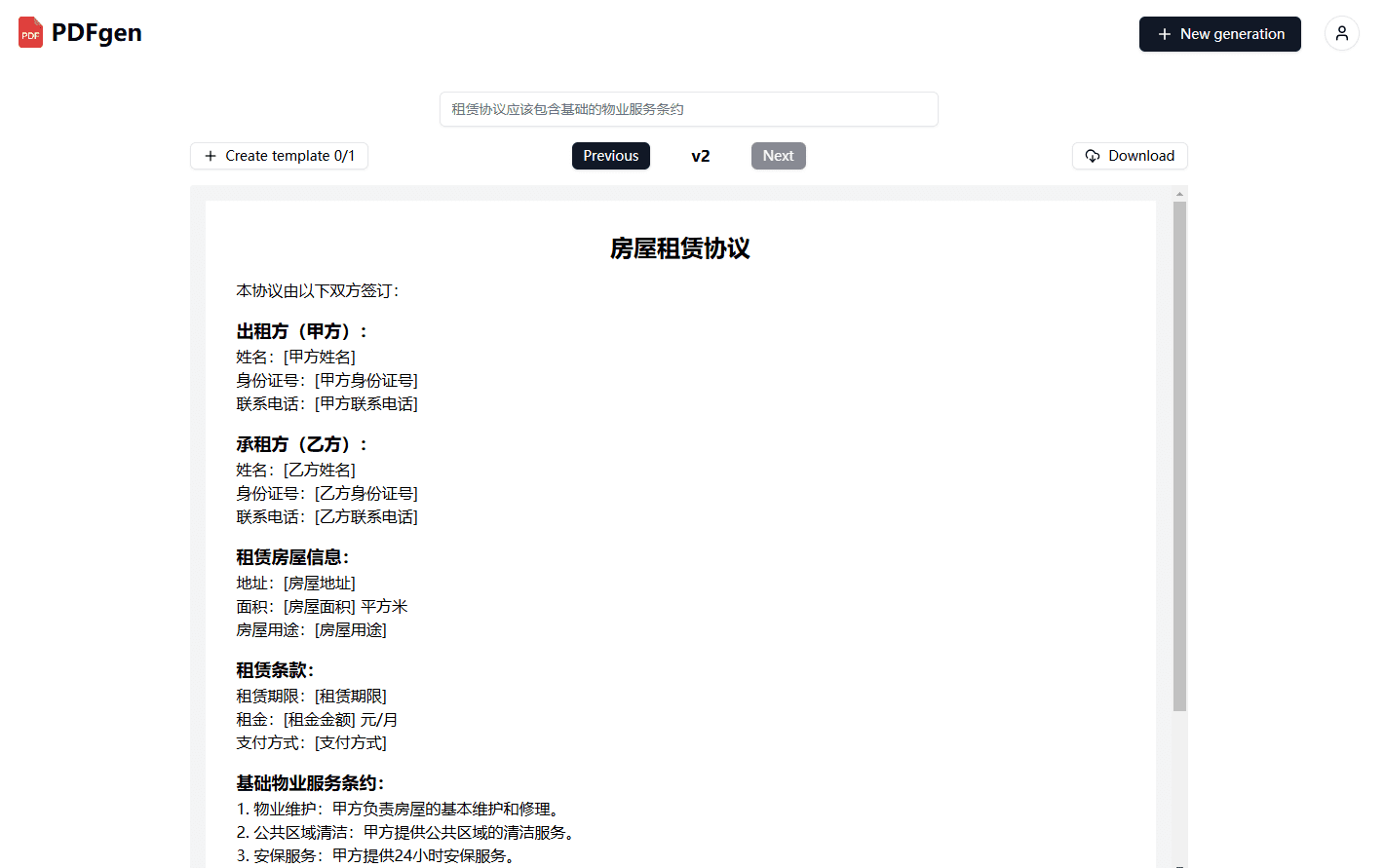
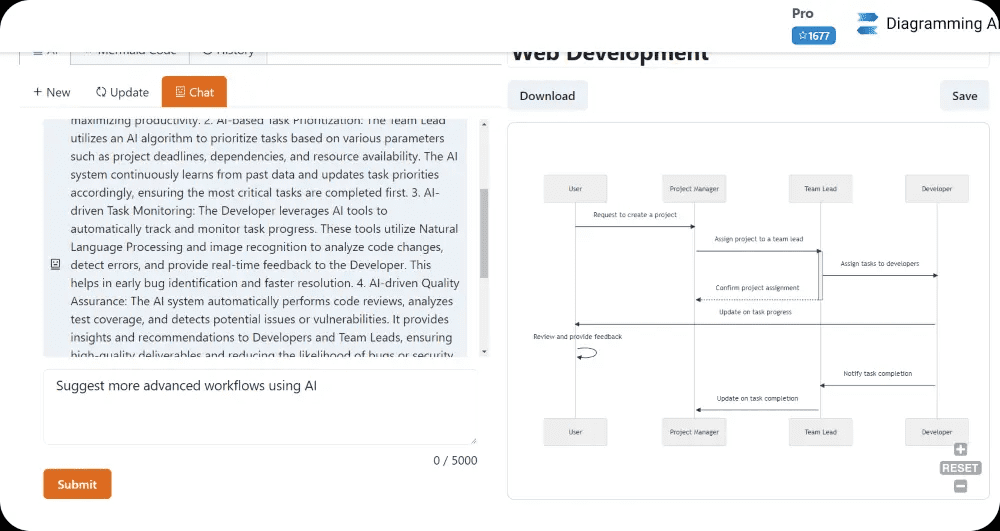
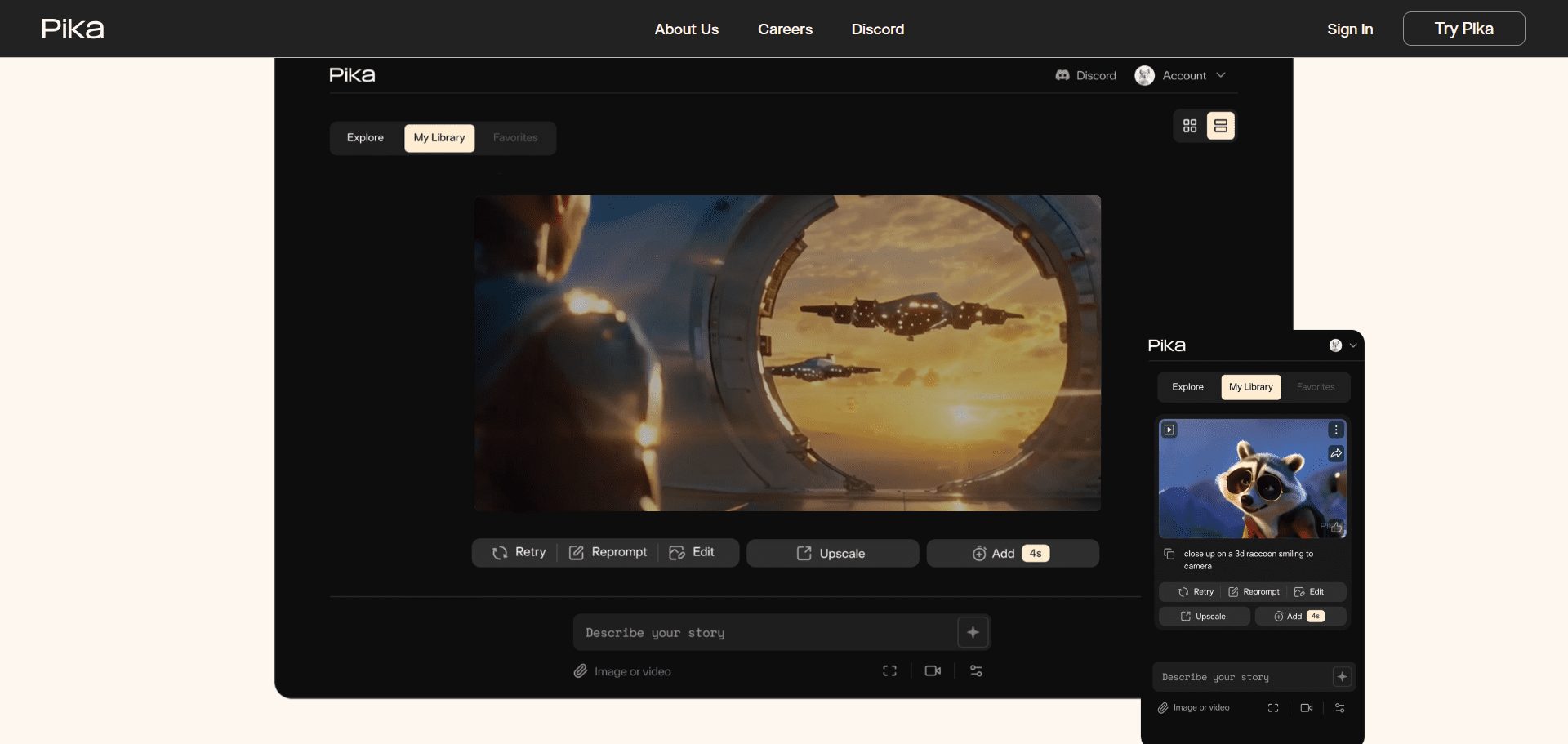
General Introduction Chatwise is a simple and useful platform that specializes in helping users turn their knowledge into AI chatbots that make money. All you need to do is upload a file, article, or link, and the site will quickly generate an intelligent bot that others can learn from your content with a paid subscription, and you can...