
DINOv3是什么
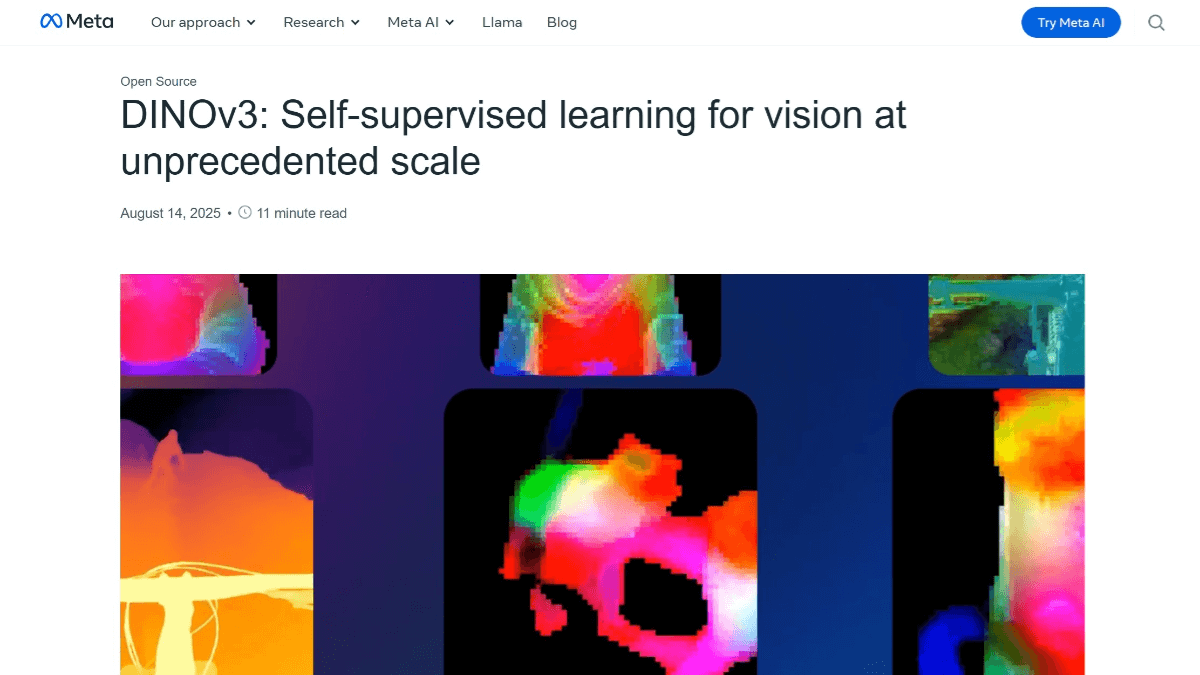
DINOv3 是 Meta AI 推出的新一代自监督视觉基础模型,采用自监督学习范式,无需标注数据即可学习图像特征。通过改进数据准备和引入 Gram anchoring 解决了特征退化问题,提升了泛化能力。DINOv3 提供 ViT 和 ConvNeXt 两种骨干网络架构,其中 ViT-7B 是目前规模最大的版本,包含 67 亿参数。模型能生成高质量的密集特征表示,精准捕捉图像的局部关系和空间信息。在图像分类、目标检测、语义分割等多种视觉任务中表现出色,无需任务特定微调即可超越许多专业模型。DINOv3 支持高分辨率特征提取,适用于医学影像分析、环境监测等需要高精度特征的场景。
DINOv3的功能特色
- 自监督学习能力:无需标注数据即可学习图像特征,通过改进数据准备和引入 Gram anchoring 解决了长期训练中的特征退化问题,提升了模型的泛化能力。
- 多种骨干网络架构:提供 ViT 和 ConvNeXt 两种骨干网络架构,满足不同计算需求,其中 ViT-7B 是目前规模最大的版本,包含 67 亿参数。
- 高质量特征表示:能生成高质量的密集特征表示,精准捕捉图像的局部关系和空间信息,适用于多种视觉任务。
- 多任务通用性:在图像分类、目标检测、语义分割等任务中表现出色,无需任务特定微调即可超越许多专业模型,显著降低了推理成本。
- 高分辨率特征提取:支持高分辨率特征提取,适用于需要高精度特征的场景,如医学影像分析和环境监测。
DINOv3的核心优势
- 强大的自监督学习能力:无需大量标注数据,通过创新的自监督机制实现高效学习,解决了特征退化问题,提升模型泛化能力。
- 灵活的架构选择:提供 ViT 和 ConvNeXt 两种骨干网络架构,满足不同计算资源和任务需求,兼顾性能与效率。
- 高质量的特征表示:生成的特征能精准捕捉图像局部关系和空间信息,适用于多种视觉任务,表现出色。
- 多任务通用性:在图像分类、目标检测、语义分割等任务中无需特定微调即可超越专业模型,降低开发成本。
- 高分辨率特征提取:支持高分辨率特征提取,适用于医学影像分析、环境监测等对精度要求高的场景。
- 开源与易用性:代码和模型开源,支持 Hugging Face Hub 和 Transformers 库,便于快速上手和应用开发。
DINOv3的官网是什么
- 项目官网:https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
- HuggingFace模型库:https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- 技术论文:https://ai.meta.com/research/publications/dinov3/
DINOv3的适用人群
- 计算机视觉研究人员:DINOv3 提供了强大的自监督学习能力和高质量的特征表示,适合从事图像分类、目标检测、语义分割等视觉任务研究的专业人员。
- 深度学习开发者:开源的代码和预训练模型使 DINOv3 成为深度学习开发者快速构建和部署视觉应用的理想选择,适合需要高效开发和优化的场景。
- 医学影像专家:高分辨率特征提取能力在医学影像分析领域具有巨大潜力,适用于需要高精度特征的医学诊断任务,如 X 光、CT 和 MRI 分析。
- 环境监测与地理信息系统(GIS)从业者:DINOv3 可用于卫星图像分析、森林砍伐监测等环境监测任务,为地理信息系统相关工作提供技术支持。
- 机器人视觉工程师:DINOv3 的高精度视觉特征和多任务通用性使其成为机器人视觉系统的理想选择,适用于火星探测机器人等复杂环境下的视觉感知任务。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...