
JanusFlow 速读
DeepSeek 团队又发新模型,28日凌晨推出了创新型多模态框架 Janus-Pro,这是一个能同时处理多模态理解和生成任务的统一模型。该模型基于 DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base 构建,支持 384 x 384 的图像输入,并使用特定的 tokenizer 进行图像生成。最大特点是将视觉编码分为独立通道,同时保持单一 transformer 架构进行处理。
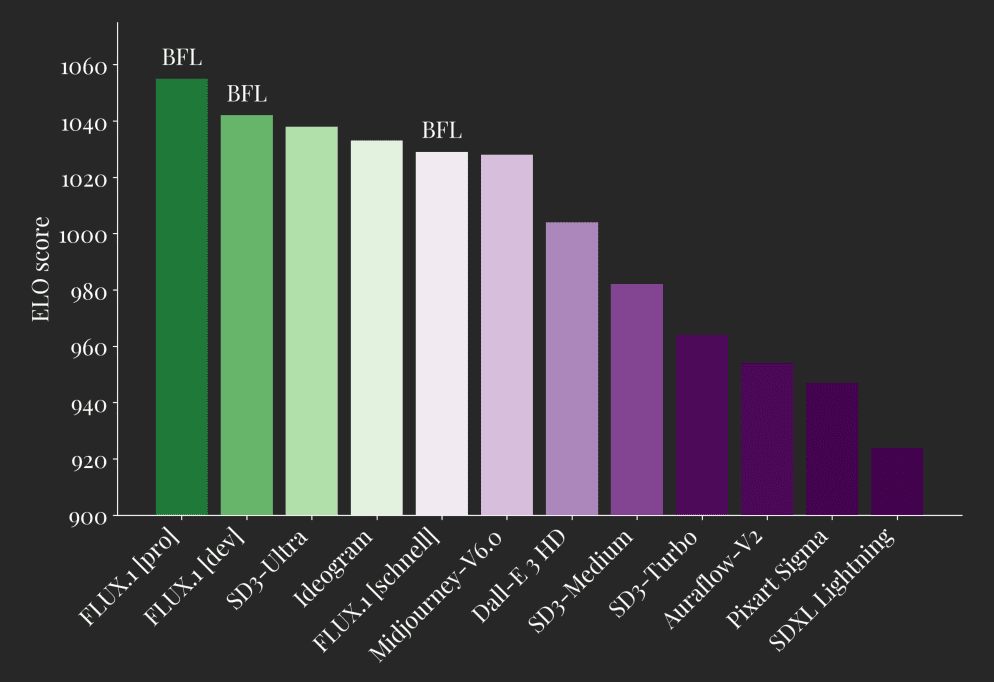
这种创新设计不仅解决了传统模型在视觉编码器角色上的冲突问题,还让整个系统变得更加灵活。在实际应用中,Janus-Pro 的表现超越了之前的统一模型,在某些任务上甚至可以媲美专门的任务型模型。在GenEval 和 DPG-Bench 基准测试中击败了 OpenAI 的 DALL-E 3 和 Stable Diffusion。
Janus 模型系列,起始于 JanusFlow,旨在构建一个统一的多模态理解与生成框架。其核心思想是将自回归语言模型 (LLM) 与修正流 (Rectified Flow) 生成模型相结合,力求在单个模型内同时实现卓越的视觉理解和高质量的图像生成能力。Janus-Pro 作为 Janus 的进阶版本,通过在训练策略、数据规模和模型尺寸上的全面优化,进一步提升了 Janus 模型的性能,并在多项基准测试中取得了显著的进步。本文将系统地梳理 Janus 模型从 JanusFlow 到 Janus-Pro 的演进历程,重点阐述其功能、参数特性以及关键改进。
1. JanusFlow:统一架构的奠基之作
论文地址:https://arxiv.org/pdf/2411.07975
JanusFlow 的核心创新在于其极简主义的统一架构,它巧妙地将修正流生成模型无缝集成到自回归 LLM 框架中,无需对 LLM 结构进行复杂修改。这一架构的核心功能包括:
- 修正流图像生成: JanusFlow 利用修正流模型进行图像生成,从高斯噪声出发,迭代预测速度向量以更新图像的 latent 空间表示,最终通过解码器生成高质量图像。这种方法避免了传统方法中 LLM 仅作为条件生成器,而缺乏直接生成能力的局限性。
- 解耦视觉编码器: 为了优化统一模型的性能,JanusFlow 采用了解耦编码器策略,分别使用独立的视觉编码器处理理解任务和生成任务:
- 理解编码器 (fenc): 采用预训练的 SigLIP-Large-Patch/16 模型,负责提取图像的语义特征,提升多模态理解能力。
- 生成编码器 (genc) 和解码器 (gdec): 采用从头开始训练的 ConvNeXt 模块,专门用于图像生成任务,优化生成质量。
- 表征对齐机制: 在统一训练过程中,JanusFlow 引入表征对齐机制,将生成模块和理解模块的中间表征进行对齐,从而加强生成过程中的语义连贯性和一致性。
- 三阶段训练策略: JanusFlow 设计了精细的三阶段训练方案:
- Stage 1:随机初始化组件适配 - 训练线性层、生成编码器和解码器,使其与预训练的 LLM 和 SigLIP 编码器协同工作,作为后续训练的初始化阶段。
- Stage 2:统一预训练 - 训练除视觉编码器外的整个模型,融合多模态理解、图像生成和纯文本数据,初步建立模型的统一能力。
- Stage 3:监督微调 - 使用指令微调数据进一步训练模型,提升对用户指令的响应能力,并在此阶段解冻 SigLIP 编码器的参数。
参数特性:
- 基础 LLM: 1.3B 参数的轻量级 LLM 架构。
- 视觉编码器: SigLIP-Large-Patch/16 (理解),ConvNeXt (生成编码器和解码器)。
- 图像分辨率: 384 × 384 像素。
性能表现: JanusFlow 在文本到图像生成和多模态理解任务上均取得了显著的性能,超越了许多专业模型,证明了其统一架构的有效性。
2. Janus-Pro:数据、模型与策略的全面升级
论文地址:https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
Janus-Pro 作为 Janus 的改进版本,在 JanusFlow 的基础上,主要在以下三个方面进行了升级:
- 优化的训练策略: Janus-Pro 对 JanusFlow 的三阶段训练策略进行了精细调整,旨在解决训练效率和性能瓶颈:
- Stage 1:延长 ImageNet 数据集训练 - 增加在 ImageNet 数据集上的训练步数,使模型更充分地学习像素依赖性,提升图像生成的基础能力。
- Stage 2:聚焦文本到图像数据训练 - 在 Stage 2 训练中,移除 ImageNet 数据,直接使用常规的文本到图像数据集,使模型更高效地学习基于密集文本描述生成高质量图像。
- Stage 3:调整数据比例 - 在监督微调阶段,微调了多模态理解数据、纯文本数据和文本到图像数据的比例(从 7:3:10 调整为 5:1:4),在保证视觉生成能力的同时,进一步提升多模态理解性能。
- 扩展的训练数据: Janus-Pro 大幅扩展了训练数据规模和多样性,以提升模型的泛化能力和生成质量:
- 多模态理解数据: 在 Stage 2 预训练阶段,新增约 9000 万样本,涵盖更广泛的图像字幕数据(如 YFCC)以及表格、图表、文档理解数据(如 Docmatix)。在 Stage 3 微调阶段,进一步引入 DeepSeek-VL2 数据集以及 MEME 理解、中文对话数据等,显著提升了模型的对话能力和多任务处理能力。
- 视觉生成数据: 为了提升生成图像的美学质量和稳定性,Janus-Pro 引入了约 7200 万高质量的合成美学数据,并调整了真实数据与合成数据的比例至 1:1,实验表明,合成数据的加入加速了模型收敛,并显著提升了生成图像的美学质量和稳定性。
- 扩展的模型尺寸: Janus-Pro 不仅保留了 JanusFlow 的 1.5B 参数模型,还进一步扩展到了 7B 参数,并提供了 Janus-Pro 系列的 1.5B 和 7B 两种模型尺寸。实验结果表明,更大规模的 LLM 能够显著提升模型的性能,并加快收敛速度,验证了 Janus 模型架构的可扩展性。
参数特性:
- 模型尺寸: 提供 1.5B 和 7B 两种模型尺寸选择。
- 架构: 沿用 JanusFlow 的解耦视觉编码器架构。
- 训练数据: 大幅扩展和优化的多模态理解和视觉生成训练数据。
- 图像分辨率: 实验中使用的图像分辨率仍为 384 × 384 像素。
性能表现: Janus-Pro 在各项基准测试中均取得了显著的性能提升,尤其是在多模态理解基准 MMBench 和文本到图像生成基准 GenEval、DPG-Bench 上,均超越了 JanusFlow 以及其他先进的统一模型和专业模型,证明了数据、模型和策略升级的有效性。
3.Janus 真实使用场景
视觉理解功能:
- 图像描述 (Image Description/Captioning):
- 详细场景描述: 能够根据图像内容生成详尽的文字描述,包括场景元素、物体、环境氛围等。(示例:描述西湖三潭印月、海边景观等)
- 图表描述: 能够理解并描述图表信息,例如条形图的数据表示和趋势分析。(示例:解读 "Kid's Favourite Fruits" 条形图)
- 物体识别与分类 (Object Recognition/Classification):
- 识别图像中的物体种类: 能够识别并列举图像中出现的物体类别。(示例:识别图中水果的种类)
- 物体计数 (Object Counting):
- 精确计数图像中的物体数量: 能够准确地统计图像中特定物体的数量。(示例:数出图中企鹅的数量)
- 地标识别 (Landmark Recognition):
- 识别图像中的著名地标: 能够识别图像中出现的地标性建筑或地点。(示例:识别出西湖三潭印月)
- 文本识别 (Text Recognition/OCR):
- 识别图像中的文字内容: 能够识别图像中出现的文字,并提取文本信息。(示例:识别黑板上的 "Serving Soul since Twenty Twelve")
- 视觉问答 (Visual Question Answering):
- 回答基于图像内容的提问: 能够理解图像内容,并根据用户的提问给出合理的答案。(示例:针对图像提问 "图中有什么水果?")
- 视觉推理与知识整合 (Visual Reasoning/Knowledge Integration):
- 理解图像背后的含义和关联: 能够进行更深层次的视觉推理,并结合知识背景进行理解。(示例:解释蒙娜丽莎狗狗图的幽默之处、理解蛋糕的卡通主题背景)
- 代码生成 (Code Generation - Python for Plotting):
- 根据用户指令生成代码: 能够理解用户对图表绘制的需求,并生成相应的 Python 代码。(示例:生成绘制条形图的 Python 代码)
文本到图像生成功能:
- 文本引导的图像生成 (Text-Guided Image Generation):
- 根据文本描述生成图像: 能够根据用户输入的文本提示词,生成与之语义相关的图像。
- 创意图像生成: 能够理解抽象和富有想象力的文本提示,生成具有创意和艺术性的图像。(示例:飞天鲸鱼、宇宙星云柯基犬等)
- 风格化图像生成: 能够根据文本提示词中的风格描述,生成具有特定艺术风格的图像。(示例:文艺复兴风格教堂、中国水墨画风格山村等)
- 生成包含文字的图像 (Simple Text Generation on Images): 能够生成包含简单文字元素的图像。(示例:在黑板上写字 "Hello")
实际应用场景示例:
- 智能助手: 作为多模态智能助手,理解用户上传的图片并进行问答、描述、分析等。
- 内容创作: 辅助内容创作者快速生成高质量的图像素材,例如社交媒体配图、文章插图等。
- 教育应用: 用于图像识别教学、图表解读教学等,帮助学生理解视觉信息。
- 信息检索: 通过图像搜索,并结合文字理解和生成能力,提供更丰富的检索结果。
- 艺术创作: 作为创意工具,辅助艺术家进行图像创作,探索新的视觉表达形式。
需要注意的参数特性与局限性:
- 图像分辨率限制: 当前模型训练和测试主要基于 384x384 分辨率图像,对于需要更高分辨率的场景可能存在局限性。
- 细节精细度: 虽然图像语义内容丰富,但受限于分辨率和 vision tokenizer 的重建损失,在细节精细度上可能仍有提升空间,例如小尺寸人脸区域可能不够细腻。
4. 总结与展望
Janus 模型系列,从 JanusFlow 到 Janus-Pro,展现了在统一多模态理解与生成领域持续突破的潜力。JanusFlow 奠定了统一架构的基础,而 Janus-Pro 则通过训练策略优化、数据规模扩展和模型尺寸升级,实现了性能的飞跃。Janus-Pro 的成功验证了数据驱动和模型扩展是提升统一模型性能的关键,同时也为未来更大规模、更高性能的统一多模态模型的发展指明了方向。Janus 模型系列的演进,不仅推动了多模态模型的进步,也为构建更通用、更智能的 AI 系统奠定了坚实的基础。
完整论文《Janus-Pro:统一的多模态理解和生成模型,通过数据和模型扩展实现》
作者: Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan
项目页面: https://github.com/deepseek-ai/Janus
摘要
在这项工作中,我们介绍了 Janus-Pro,这是之前 Janus 模型的增强版本。具体来说,Janus-Pro 集成了 (1) 优化的训练策略,(2) 扩展的训练数据,以及 (3) 扩展到更大的模型规模。通过这些改进,Janus-Pro 在多模态理解和文本生成图像的指令遵循能力方面取得了重大进步,同时增强了文本生成图像的稳定性。我们希望这项工作能够激发该领域的进一步探索。代码和模型已公开发布。
1. 引言

(a) 四个多模态理解基准的平均性能。(b) 文本生成图像指令遵循基准的性能。
图 1 | Janus-Pro 的多模态理解和视觉生成结果。对于多模态理解,我们对 POPE、MME-Perception、GQA 和 MMMU 的准确性进行了平均。MME-Perception 的分数除以 20 以缩放到 [0, 100] 范围。对于视觉生成,我们评估了 GenEval 和 DPG-Bench 两个指令遵循基准的性能。总体而言,Janus-Pro 优于之前的最先进统一多模态模型以及一些特定任务的模型。在屏幕上观看效果最佳。

1.一张橙色的橘子简约照片 2.一块干净的黑板,上面用白色粉笔精确清晰地写着一个绿色的表面和“Hello”这个词 3.象征着繁荣的向日葵特写,绿色的茎和叶,花瓣盛开,一只蜜蜂停在上面,翅膀在阳光下闪闪发光。
图 2 | Janus-Pro 与其前身 Janus 的文本生成图像对比。Janus-Pro 为简短提示提供了更稳定的输出,具有更高的视觉质量、更丰富的细节以及生成简单文本的能力。图像分辨率为 384x384。在屏幕上观看效果最佳。
最近在统一多模态理解和生成模型方面取得了显著进展 [30, 40, 45, 46, 48, 50, 54, 55]。这些方法已被证明可以增强视觉生成任务中的指令遵循能力,同时减少模型冗余。大多数这些方法使用相同的视觉编码器来处理多模态理解和生成任务的输入。由于这两项任务所需的表示不同,这通常会导致多模态理解性能不佳。为了解决这个问题,Janus [46] 提出了解耦视觉编码,这缓解了多模态理解和生成任务之间的冲突,在这两项任务中都取得了优异的性能。
作为开创性模型,Janus 在 1B 参数规模下得到了验证。然而,由于训练数据的限制和相对较小的模型容量,它表现出了一些缺点,例如在简短提示图像生成方面的性能不佳以及文本生成图像质量不稳定。在本文中,我们介绍了 Janus-Pro,这是 Janus 的增强版本,它在三个方面进行了改进:训练策略、数据和模型规模。Janus-Pro 系列包括两种模型规模:1B 和 7B,展示了视觉编码解码方法的可扩展性。
我们在多个基准上评估了 Janus-Pro,结果显示其多模态理解能力优越,文本生成图像指令遵循性能显著提高。具体来说,Janus-Pro-7B 在多模态理解基准 MMBench [29] 上获得了 79.2 分,超过了之前的最先进统一多模态模型,如 Janus [46] (69.4)、TokenFlow [34] (68.9) 和 MetaMorph [42] (75.2)。此外,在文本生成图像指令遵循排行榜 GenEval [14] 中,Janus-Pro-7B 得分为 0.80,超过了 Janus [46] (0.61)、DALL-E 3 (0.67) 和 Stable Diffusion 3 Medium [11] (0.74)。

图 3 | Janus-Pro 的架构。我们对多模态理解和视觉生成进行视觉编码解耦。“Und. Encoder”和“Gen. Encoder”分别是“Understanding Encoder”和“Generation Encoder”的缩写。在屏幕上观看效果最佳。
2. 方法
2.1. 架构
Janus-Pro 的架构如图 3 所示,与 Janus [46] 相同。整体架构的核心设计原则是对多模态理解和生成进行视觉编码解耦。我们应用独立的编码方法将原始输入转换为特征,然后由一个统一的自回归变换器进行处理。对于多模态理解,我们使用 SigLIP [53] 编码器从图像中提取高维语义特征。这些特征从 2-D 网格展平为 1-D 序列,并使用理解适配器将这些图像特征映射到 LLM 的输入空间。对于视觉生成任务,我们使用 [38] 中的 VQ 标记器将图像转换为离散 ID。ID 序列展平为 1-D 后,我们使用生成适配器将每个 ID 对应的代码本嵌入映射到 LLM 的输入空间。然后我们将这些特征序列连接起来,形成一个多模态特征序列,随后将其输入到 LLM 中进行处理。除了 LLM 中内置的预测头外,我们还使用一个随机初始化的预测头用于视觉生成任务中的图像预测。整个模型遵循自回归框架。
2.2. 优化的训练策略
Janus 的前一个版本采用三阶段训练过程。第一阶段侧重于训练适配器和图像头。第二阶段处理统一预训练,在此阶段,除了理解编码器和生成编码器之外的所有组件都会更新其参数。第三阶段是监督微调,它建立在第二阶段的基础上,通过在训练过程中进一步解锁理解编码器的参数。这种训练策略存在一些问题。在第二阶段,Janus 将文本生成图像能力的训练分为两部分,遵循 PixArt [4]。第一部分使用 ImageNet [9] 数据进行训练,使用图像类别名称作为文本生成图像的提示,目标是建模像素依赖性。第二部分使用普通的文本生成图像数据进行训练。在实施过程中,第二阶段的文本生成图像训练步骤中有 66.67% 分配给了第一部分。然而,通过进一步的实验,我们发现这种策略是次优的,并且导致了显著的计算效率低下。
为了解决这个问题,我们做了两项修改。
• 第一阶段更长的训练: 我们增加了第一阶段的训练步骤,允许在 ImageNet 数据集上进行充分的训练。我们的发现表明,即使 LLM 参数固定,模型也可以有效地建模像素依赖性,并根据类别名称生成合理的图像。
• 第二阶段重点训练: 在第二阶段,我们放弃了 ImageNet 数据,直接利用普通的文本生成图像数据来训练模型根据密集描述生成图像。这种重新设计的方法使第二阶段能够更有效地利用文本生成图像数据,从而提高了训练效率和整体性能。
我们还调整了第三阶段监督微调过程中不同类型数据集的数据比例,将多模态数据、纯文本数据和文本生成图像数据的比例从 7:3:10 改为 5:1:4。通过略微降低文本生成图像数据的比例,我们观察到这种调整使我们能够在保持强大的视觉生成能力的同时,实现多模态理解性能的提升。
2.3. 数据扩展
我们在多模态理解和视觉生成方面扩展了 Janus 使用的训练数据。
• 多模态理解: 对于第二阶段预训练数据,我们参考 DeepSeekVL2 [49],增加了大约 9000 万个样本。这些数据包括图像字幕数据集(例如,YFCC [31]),以及用于表格、图表和文档理解的数据(例如,Docmatix [20])。对于第三阶段监督微调数据,我们还从 DeepSeek-VL2 中加入了额外的数据集,例如 MEME 理解、中文对话数据,以及旨在增强对话体验的数据集。这些增加显著扩展了模型的能力,丰富了它处理各种任务的能力,同时提高了整体对话体验。
• 视觉生成: 我们观察到,前一个版本 Janus 中使用的真实世界数据缺乏质量,并且包含显著的噪声,这通常会导致文本生成图像不稳定,导致美学效果不佳的输出。在 Janus-Pro 中,我们加入了大约 7200 万个合成美学数据样本,使真实与合成数据的比例在统一预训练阶段达到 1:1。这些合成数据样本的提示是公开可用的,例如 [43] 中的提示。实验表明,当在合成数据上进行训练时,模型收敛速度更快,生成的文本生成图像输出不仅更稳定,而且美学质量也显著提高。
2.4. 模型扩展
Janus 的前一个版本验证了使用 1.5B LLM 进行视觉编码解耦的有效性。在 Janus-Pro 中,我们将模型扩展到 7B,1.5B 和 7B LLM 的超参数在表 1 中详细说明。我们观察到,当使用更大规模的 LLM 时,与较小的模型相比,多模态理解和视觉生成损失的收敛速度显著提高。这一发现进一步验证了这种方法强大的可扩展性。
表 1 | Janus-Pro 的架构配置。我们列出了架构的超参数。
| Janus-Pro-1B | Janus-Pro-7B | |
| 词汇量大小 | 100K | 100K |
| 嵌入大小 | 2048 | 4096 |
| 上下文窗口 | 4096 | 4096 |
| 注意力头数 | 16 | 32 |
| 层数 | 24 | 30 |
表 2 | Janus-Pro 训练的详细超参数。数据比例指的是多模态理解数据、纯文本数据和视觉生成数据的比例。

3. 实验
3.1. 实现细节
在我们的实验中,我们使用 DeepSeek-LLM (1.5B 和 7B) [3] 作为基础语言模型,最大支持序列长度为 4096。对于理解任务中使用的视觉编码器,我们选择了 SigLIP-Large-Patch16-384 [53]。生成编码器有一个大小为 16,384 的代码本,并将图像下采样 16 倍。理解适配器和生成适配器都是两层 MLP。每个阶段的详细超参数在表 2 中提供。所有图像都调整为 384x384 像素。对于多模态理解数据,我们将图像的长边调整为 384,短边用背景色(RGB: 127, 127, 127)填充以达到 384。对于视觉生成数据,短边调整为 384,长边裁剪为 384。我们在训练过程中使用序列打包来提高训练效率。我们根据指定的比例混合所有数据类型,在单个训练步骤中进行。我们的 Janus 使用 HAI-LLM [15] 进行训练和评估,HAI-LLM 是一个基于 PyTorch 构建的轻量级高效分布式训练框架。整个训练过程在配备 8 个 Nvidia A100 (40GB) GPU 的 16/32 节点集群上大约花费了 7/14 天,用于 1.5B/7B 模型。
3.2. 评估设置
多模态理解 (Multimodal Understanding): 为了评估多模态理解能力,我们在广泛认可的基于图像的视觉-语言基准测试上对我们的模型进行了评估,这些基准测试包括 GQA [17], POPE [23], MME [12], SEED [21], MMB [29], MM-Vet [51], 以及 MMMU [52]。
表 3 | 与最先进技术在多模态理解基准测试中的比较。“Und.” 和 “Gen.” 分别表示 “理解” 和 “生成”。 使用外部预训练扩散模型的模型用 † 标记。

视觉生成 (Visual Generation): 为了评估视觉生成能力,我们使用了 GenEval [14] 和 DPG-Bench [16]。GenEval 是一个具有挑战性的图像到文本生成基准测试,旨在通过对其组合能力的详细实例级分析来反映视觉生成模型的全面生成能力。DPG-Bench (密集提示图基准测试) 是一个包含 1065 个冗长、密集提示的综合数据集,旨在评估文本到图像模型的复杂语义对齐能力。
3.3. 与最先进的比较
多模态理解性能 (Multimodal Understanding Performance): 我们在表 3 中将所提出的方法与最先进的统一模型和仅支持理解的模型进行了比较。Janus-Pro 取得了总体最佳结果。这可以归因于对多模态理解和生成的视觉编码进行了解耦,从而减轻了这两项任务之间的冲突。当与规模大得多的模型相比时,Janus-Pro 仍然具有很强的竞争力。例如,Janus-Pro-7B 在除 GQA 之外的所有基准测试中均优于 TokenFlow-XL (13B)。
表 4 | 在 GenEval 基准测试中对文本到图像生成能力的评估。“Und.” 和 “Gen.” 分别表示“理解”和“生成”。使用外部预训练扩散模型的模型用 † 标记。

表 5 | 在 DPG-Bench 上的性能。除了 Janus 和 Janus-Pro 之外,此表中的所有方法都是特定于生成任务的模型。

视觉生成性能 (Visual Generation Performance): 我们报告了在 GenEval 和 DPG-Bench 上的视觉生成性能。如表 4 所示,我们的 Janus-Pro-7B 在 GenEval 上获得了 80% 的总体准确率,优于所有其他统一或仅支持生成的方法,例如,Transfusion [55] (63%),SD3-Medium (74%) 和 DALL-E 3 (67%)。这表明我们的方法具有更好的指令跟随能力。如表 5 所示,Janus-Pro 在 DPG-Bench 上取得了 84.19 分,超过了所有其他方法。这表明 Janus-Pro 擅长遵循密集的指令进行文本到图像的生成。
3.4. 定性结果
我们在图 4 中展示了多模态理解的结果。Janus-Pro 在处理来自不同情境的输入时表现出令人印象深刻的理解能力,展现了其强大的能力。我们还在图 4 的下半部分展示了一些文本生成图像生成结果。Janus-Pro-7B 生成的图像非常逼真,尽管分辨率仅为 $384\times384$,但仍然包含大量细节。对于富有想象力和创造性的场景,Janus-Pro-7B 准确地捕捉了提示中的语义信息,生成合理且连贯的图像。

图 4 | 多模态理解和视觉生成能力的定性结果。该模型是 Janus-Pro-7B,视觉生成的图像输出分辨率为 $384\times384$。在屏幕上观看效果最佳。
4. 结论
本文从训练策略、数据和模型规模三个方面对 Janus 进行了改进。这些增强措施使得多模态理解和文本生成图像指令遵循能力得到了显著提升。然而,Janus-Pro 仍然存在一些局限性。在多模态理解方面,输入分辨率限制为 $384\times384$,这影响了其在 OCR 等细粒度任务中的性能。对于文本生成图像,低分辨率加上视觉标记器引入的重构损失,导致图像虽然语义内容丰富,但仍然缺乏细节。例如,占据有限图像空间的小面部区域可能看起来不够详细。提高图像分辨率可以缓解这些问题。
参考文献
[1] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, 和 J. Zhou. Qwen-vl: 一个具有多功能的前沿大型视觉语言模型。arXiv 预印本 arXiv:2308.12966, 2023.[2] J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y. Guo, 等. 通过更好的字幕改进图像生成。计算机科学。https://cdn.openai.com/papers/dall-e-3.pdf, 2(3):8, 2023.
[3] X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, 等. DeepSeek LLM: 使用长期主义扩展开源语言模型。arXiv 预印本 arXiv:2401.02954, 2024.
[4] J. Chen, J. Yu, C. Ge, L. Yao, E. Xie, Y. Wu, Z. Wang, J. Kwok, P. Luo, H. Lu, 等. PixArtℎ: 快速训练扩散变换器用于照片级逼真的文本生成图像合成。arXiv 预印本 arXiv:2310.00426, 2023.
[5] J. Chen, C. Ge, E. Xie, Y. Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, 和 Z. Li. PixArt-Sigma: 弱到强的扩散变换器训练用于 4K 文本生成图像生成。arXiv 预印本 arXiv:2403.04692, 2024.
[6] X. Chu, L. Qiao, X. Lin, S. Xu, Y. Yang, Y. Hu, F. Wei, X. Zhang, B. Zhang, X. Wei, 等. Mobilevlm: 一个快速、可复现且强大的移动设备视觉语言助手。arXiv 预印本 arXiv:2312.16886, 2023.
[7] X. Chu, L. Qiao, X. Zhang, S. Xu, F. Wei, Y. Yang, X. Sun, Y. Hu, X. Lin, B. Zhang, 等. Mobilevlm v2: 更快速、更强大的视觉语言模型基础。arXiv 预印本 arXiv:2402.03766, 2024.
[8] W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, 和 S. Hoi. Instructblip: 朝着具有指令微调的通用视觉语言模型发展, 2023.
[9] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, 和 L. Fei-Fei. Imagenet: 一个大规模分层图像数据库。在 2009 年 IEEE 计算机视觉与模式识别会议论文集, 页码 248–255. 电气电子工程师学会, 2009.
[10] R. Dong, C. Han, Y. Peng, Z. Qi, Z. Ge, J. Yang, L. Zhao, J. Sun, H. Zhou, H. Wei, 等. Dreamllm: 多模态协同理解与创造。arXiv 预印本 arXiv:2309.11499, 2023.
[11] P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Mller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, K. Lacey, A. Goodwin, Y. Marek, 和 R. Rombach. 缩放修正流变换器用于高分辨率图像合成, 2024. URL https://arxiv.org/abs/2403.03206.
[12] C. Fu, P. Chen, Y. Shen, Y. Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun, 等. MME: 一个用于多模态大型语言模型的综合评估基准。arXiv 预印本 arXiv:2306.13394, 2023.
[13] Y. Ge, S. Zhao, J. Zhu, Y. Ge, K. Yi, L. Song, C. Li, X. Ding, 和 Y. Shan. SEED-X: 具有统一多粒度理解和生成的多模态模型。arXiv 预印本 arXiv:2404.14396, 2024.
[14] D. Ghosh, H. Hajishirzi, 和 L. Schmidt. GenEval: 一个面向对象的框架,用于评估文本生成图像对齐。神经信息处理系统的进展, 36, 2024.
[15] High-flyer. HAI-LLM: 高效轻量级的大型模型训练工具, 2023. URL https://www.high-flyer.cn/en/blog/hai-llm.
[16] X. Hu, R. Wang, Y. Fang, B. Fu, P. Cheng, 和 G. Yu. ELLA: 为增强语义对齐配备扩散模型。arXiv 预印本 arXiv:2403.05135, 2024.
[17] D. A. Hudson 和 C. D. Manning. GQA: 一个用于真实世界视觉推理和组合问答的新数据集。在 IEEE/CVF 计算机视觉与模式识别会议论文集, 页码 6700–6709, 2019.
[18] Y. Jin, K. Xu, L. Chen, C. Liao, J. Tan, B. Chen, C. Lei, A. Liu, C. Song, X. Lei, 等. 动态离散视觉标记化的统一语言视觉预训练。arXiv 预印本 arXiv:2309.04669, 2023.
[19] H. Laurenon, D. van Strien, S. Bekman, L. Tronchon, L. Saulnier, T. Wang, S. Karamcheti, A. Singh, G. Pistilli, Y. Jernite, 和 等. 介绍 IDEFICS: 一个再现最先进视觉语言模型的开放模型, 2023. URL https://huggingface.co/blog/id efics.
[20] H. Laurenon, A. Marafioti, V. Sanh, 和 L. Tronchon. 构建并更好地理解视觉语言模型:洞察与未来方向, 2024.
[21] B. Li, R. Wang, G. Wang, Y. Ge, Y. Ge, 和 Y. Shan. SEED-Bench: 使用生成性理解对多模态 LLMs 进行基准测试。arXiv 预印本 arXiv:2307.16125, 2023.
[22] D. Li, A. Kamko, E. Akhgari, A. Sabet, L. Xu, 和 S. Doshi. Playground v2.5: 三点洞察用于增强文本生成图像生成的美学质量。arXiv 预印本 arXiv:2402.17245, 2024.
[23] Y. Li, Y. Du, K. Zhou, J. Wang, W. X. Zhao, 和 J.-R. Wen. 在大型视觉语言模型中评估对象幻觉。arXiv 预印本 arXiv:2305.10355, 2023.
[24] Z. Li, H. Li, Y. Shi, A. B. Farimani, Y. Kluger, L. Yang, 和 P. Wang. 双扩散用于统一图像生成和理解。arXiv 预印本 arXiv:2501.00289, 2024.
[25] Z. Li, J. Zhang, Q. Lin, J. Xiong, Y. Long, X. Deng, Y. Zhang, X. Liu, M. Huang, Z. Xiao, 等. Hunyuan-DiT: 一个强大的多分辨率扩散变换器,具有精细的中文理解。arXiv 预印本 arXiv:2405.08748, 2024.
[26] H. Liu, C. Li, Y. Li, 和 Y. J. Lee. 改进的视觉指令微调基线。在 IEEE/CVF 计算机视觉与模式识别会议论文集, 页码 26296–26306, 2024.
[27] H. Liu, C. Li, Q. Wu, 和 Y. J. Lee. 视觉指令微调。神经信息处理系统的进展, 36, 2024.
[28] H. Liu, W. Yan, M. Zaharia, 和 P. Abbeel. 世界模型在百万长度视频和语言上的应用,使用环注意力。arXiv 预印本 arXiv:2402.08268, 2024.
[29] Y. Liu, H. Duan, Y. Zhang, B. Li, S. Zhang, W. Zhao, Y. Yuan, J. Wang, C. He, Z. Liu, 等. MMBench: 你的多模态模型是一个全能选手吗?arXiv 预印本 arXiv:2307.06281, 2023.
[30] Y. Ma, X. Liu, X. Chen, W. Liu, C. Wu, Z. Wu, Z. Pan, Z. Xie, H. Zhang, X. yu, L. Zhao, Y. Wang, J. Liu, 和 C. Ruan. Janusflow: 调和自回归和修正流以实现统一的多模态理解和生成, 2024.
[31] mehdidc. YFCC-Huggingface. https://huggingface.co/datasets/mehdidc/yfcc15 m, 2024.
[32] D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Mller, J. Penna, 和 R. Rombach. SDXL: 改进潜在扩散模型用于高分辨率图像合成。arXiv 预印本 arXiv:2307.01952, 2023.
[33] D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Mller, J. Penna, 和 R. Rombach. SDXL: 改进潜在扩散模型用于高分辨率图像合成。2024.
[34] L. Qu, H. Zhang, Y. Liu, X. Wang, Y. Jiang, Y. Gao, H. Ye, D. K. Du, Z. Yuan, 和 X. Wu. Tokenflow: 统一图像标记器用于多模态理解和生成。arXiv 预印本 arXiv:2412.03069, 2024.
[35] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, 和 M. Chen. 使用 CLIP 潜在值进行分层文本条件图像生成。arXiv 预印本 arXiv:2204.06125, 1(2):3, 2022.
[36] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, 和 B. Ommer. 使用潜在扩散模型进行高分辨率图像合成。2022.
[37] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, 和 B. Ommer. 使用潜在扩散模型进行高分辨率图像合成。在 IEEE/CVF 计算机视觉与模式识别会议论文集, 页码 10684–10695, 2022.
[38] P. Sun, Y. Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, 和 Z. Yuan. 自回归模型击败扩散:LLama 用于可扩展图像生成。arXiv 预印本 arXiv:2406.06525, 2024.
[39] Q. Sun, Q. Yu, Y. Cui, F. Zhang, X. Zhang, Y. Wang, H. Gao, J. Liu, T. Huang, 和 X. Wang. 多模态生成性预训练。arXiv 预印本 arXiv:2307.05222, 2023.
[40] C. Team. Chameleon: 混合模态早期融合基础模型。arXiv 预印本 arXiv:2405.09818, 2024.
[41] G. Team, R. Anil, S. Borgeaud, Y. Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, 等. Gemini: 一个能力强大的多模态模型家族。arXiv 预印本 arXiv:2312.11805, 2023.
[42] S. Tong, D. Fan, J. Zhu, Y. Xiong, X. Chen, K. Sinha, M. Rabbat, Y. LeCun, S. Xie, 和 Z. Liu. Metamorph: 通过指令微调实现多模态理解和生成。arXiv 预印本 arXiv:2412.14164, 2024.
[43] Vivym. Midjourney 提示数据集。https://huggingface.co/datasets/vivym/midjourney-prompts, 2023. 访问日期: [插入访问日期,例如 2023-10-15].
[44] C. Wang, G. Lu, J. Yang, R. Huang, J. Han, L. Hou, W. Zhang, 和 H. Xu. Illume: 照亮你的 LLMs 以看到、绘制和自我增强。arXiv 预印本 arXiv:2412.06673, 2024.
[45] X. Wang, X. Zhang, Z. Luo, Q. Sun, Y. Cui, J. Wang, F. Zhang, Y. Wang, Z. Li, Q. Yu, 等. Emu3: 下一个标记预测是你所需要的全部。arXiv 预印本 arXiv:2409.18869, 2024.
[46] C. Wu, X. Chen, Z. Wu, Y. Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruan, 等. Janus: 解耦视觉编码以实现统一的多模态理解和生成。arXiv 预印本 arXiv:2410.13848, 2024.
[47] S. Wu, H. Fei, L. Qu, W. Ji, 和 T.-S. Chua. Next-gpt: 任何到任何的多模态 LLM。arXiv 预印本 arXiv:2309.05519, 2023.
[48] Y. Wu, Z. Zhang, J. Chen, H. Tang, D. Li, Y. Fang, L. Zhu, E. Xie, H. Yin, L. Yi, 等. VILA-U: 一个整合视觉理解和生成的基础模型。arXiv 预印本 arXiv:2409.04429, 2024.
[49] Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y. Ma, C. Wu, B. Wang, 等. DeepSeek-VL2: 混合专家视觉语言模型用于高级多模态理解。arXiv 预印本 arXiv:2412.10302, 2024.
[50] J. Xie, W. Mao, Z. Bai, D. J. Zhang, W. Wang, K. Q. Lin, Y. Gu, Z. Chen, Z. Yang, 和 M. Z. Shou. Show-o: 一个单一的变换器统一多模态理解和生成。arXiv 预印本 arXiv:2408.12528, 2024.
[51] W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, 和 L. Wang. MM-Vet: 评估大型多模态模型的综合能力。arXiv 预印本 arXiv:2308.02490, 2023.
[52] X. Yue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun, 等. MMMU: 一个大规模多学科多模态理解和推理基准,用于专家 AGI。在 IEEE/CVF 计算机视觉与模式识别会议论文集, 页码 9556–9567, 2024.
[53] X. Zhai, B. Mustafa, A. Kolesnikov, 和 L. Beyer. 语言图像预训练的 Sigmoid 损失。在 IEEE/CVF 国际计算机视觉会议论文集, 页码 11975–11986, 2023.
[54] C. Zhao, Y. Song, W. Wang, H. Feng, E. Ding, Y. Sun, X. Xiao, 和 J. Wang. Monoformer: 一个用于扩散和自回归的单一变换器。arXiv 预印本 arXiv:2409.16280, 2024.
[55] C. Zhou, L. Yu, A. Babu, K. Tirumala, M. Yasunaga, L. Shamis, J. Kahn, X. Ma, L. Zettlemoyer, 和 O. Levy. Transfusion: 使用一个多模态模型预测下一个标记并扩散图像。arXiv 预印本 arXiv:2408.11039, 2024.
[56] Y. Zhu, M. Zhu, N. Liu, Z. Ou, X. Mou, 和 J. Tang. LLAVA-Phi: 高效的多模态助手,带有小语言模型。arXiv 预印本 arXiv:2401.02330, 2024.[57] L. Zhuo, R. Du, H. Xiao, Y. Li, D. Liu, R. Huang, W. Liu, L. Zhao, F.-Y. Wang, Z. Ma, 等. Lumina-Next: 使用 Next-DiT 使 Lumina-T2X 更强大、更快速。arXiv 预印本 arXiv:2406.18583, 2024.
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...