
特邀撰稿人 Lennart Heim 和 Sihao Huang,本文交叉发布于 Lennart 的个人博客。Lennart 是 ChinaTalk 的常客,最近曾参与关于测试时计算时代的地缘政治的讨论。Sihao 之前曾撰文探讨北京对全球 AI 治理的愿景。
近期关于 DeepSeek AI 模型的报道主要聚焦于其在基准测试中的卓越表现和效率提升。尽管这些成就值得认可,并具有政策影响(详见下文),但关于计算资源获取、出口管制和 AI 发展的实际情况,比许多报道所呈现的更为复杂。以下是几个值得关注的关键点:
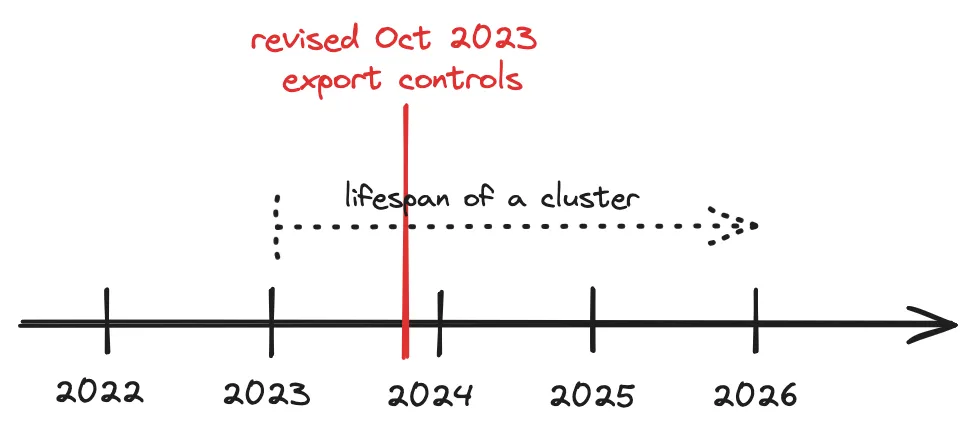
- AI 芯片的真正出口限制始于 2023 年 10 月,当前关于其无效性的说法为时过早。 DeepSeek 使用 Nvidia H800 训练,该芯片专为规避 2022 年 10 月的最初限制而设计。对于 DeepSeek 的计算任务而言,这些芯片的性能与美国可用的 H100 相当。而 Nvidia 最新推出的 H20——目前仍可出口至中国的 AI 芯片——在训练方面性能较弱,但在部署方面依然具备强大能力。
尽管 H20 在训练方面受限,但在前沿 AI 部署(尤其是长上下文推理等内存密集型任务)方面仍然未受限制且性能强劲。这一点至关重要,尤其是在测试时计算、合成数据生成和强化学习等趋势下,这些过程更依赖内存,而非计算能力。随着 2024 年 12 月对高带宽内存(HBM)出口的限制生效,H20 继续可用的情况值得关注,特别是在 AI 计算需求日益向部署端倾斜的背景下。 - 硬件出口管制存在时间滞后效应,目前尚未完全生效。
需要注意:这一切的前提是出口管制能够完美执行,而事实并非如此。半导体管制存在大量漏洞,并有可靠证据表明存在大规模芯片输送。尽管 Diffusion Framework 可能有助于弥补部分漏洞,但执行仍是关键挑战。[JS:当然,西方云计算的访问问题仍然存在……]中国仍在使用出口限制前建设的数据中心,其中包含数万颗芯片,而美国企业正在建设包含数十万颗芯片的数据中心。真正的考验将在这些数据中心需要升级或扩建时出现——对美国企业来说,这一过程更为容易,但对受制于出口管制的中国企业而言则将充满挑战。如果下一代模型的训练需要 10 万颗芯片,出口管制将极大影响中国的前沿模型开发。然而,即便没有如此大规模的训练需求,出口管制仍将通过减少部署能力、限制企业发展,以及抑制合成训练数据和自博弈能力,对中国 AI 生态系统产生深远影响。
- DeepSeek V3 在较少计算资源下完成训练并不意外,机器学习算法的成本一直在随时间下降。 但同样的效率提升,使得像 DeepSeek 这样的小型企业能获得 AI 能力(即“可及性效应”),也可能让其他企业在更大规模计算集群上构建更强大的系统(即“性能效应”)。值得庆幸的是,DeepSeek 仅使用 2,000 颗 H800 训练了 V3,而非 20 万颗 B200(Nvidia 最新一代芯片)。

- 发布时间具有战略考量,但技术实力是真实的。 R1 的发布正值特朗普总统上周就职,显然是为了在美国政策关键时期,削弱公众对美国 AI 领先地位的信心。这与华为在前商务部长雷蒙多访华期间推出新产品的策略如出一辙。毕竟,R1 预览版的基准测试结果早在 11 月就已公开。
这种精心策划的公关时间安排,不应掩盖两个事实:DeepSeek 的技术进步,以及他们目前和未来因出口管制面临的结构性挑战。 - 出口管制难以精准影响单次训练任务,但可以有效遏制整个 AI 生态系统的发展。尤其是,最先进芯片的限制可有效约束大规模 AI 部署(即让大量用户访问 AI 服务)和能力提升。 AI 企业通常将 60-80% 的计算资源用于部署——即便在计算密集型推理模型崛起之前也是如此。限制计算资源将增加中国 AI 的成本,削弱其大规模部署能力,并限制系统性能。值得注意的是,部署计算不仅关乎用户访问,它还在生成合成训练数据、通过模型交互促进能力提升、以及构建、扩展和优化模型等方面发挥关键作用。
例如,Gwern 最近的评论指出,部署计算在 AI 发展中扮演着远超用户访问的关键角色。像 OpenAI 的 o1 这样的模型可用于生成高质量训练数据,从而形成反馈循环,使部署能力直接推动开发能力和整体性能提升。 - DeepSeek 的效率提升可能源于其此前获得的大规模算力支持。 乍看之下,减少芯片使用(即“提高效率”)的路径可能需要从拥有大量算力开始。DeepSeek 运营着亚洲首个 10,000 片 A100 集群,并据称维持着一个 50,000 片 H800 集群,同时还可以无限制地访问中国和外国的云服务提供商(不受出口管制)。这种广泛的算力访问对于其通过反复试验开发高效技术以及向客户提供模型服务至关重要。
近期,其他 AI 公司的使用量激增,即使在更大算力支持下仍导致服务中断。DeepSeek 能否应对类似的激增仍未经过考验,且在算力有限的情况下,他们将面临挑战。(Sam Altman 甚至声称 ChatGPT Pro 订阅计划目前正在亏损。)
虽然他们的 R1 模型展现出了卓越的效率,但其开发过程依赖于大量算力来进行合成数据生成、蒸馏和实验。 - 出口管制进一步加剧了中美算力差距,而这仍然是 DeepSeek 面临的主要限制。DeepSeek 领导层公开承认即使效率有所提升,他们仍然面临 4 倍的算力劣势。 DeepSeek 创始人梁文锋表示:“这意味着我们需要两倍的计算能力才能实现相同的结果。此外,数据效率方面也存在约 2 倍的差距,这意味着我们需要 2 倍的训练数据和计算能力才能达到可比的效果。综合来看,这需要 4 倍的计算能力。” 他补充道:“我们短期内没有融资计划。我们的问题从来不是资金,而是对高端芯片的禁运。”
- 美国领先的 AI 公司会将最强的能力保密,这意味着公开基准测试无法准确反映 AI 发展的全貌。 中国公司倾向于公开分享进展,而 Anthropic 和 OpenAI 等公司则保留了大量私有能力。因此,基于公开信息的直接比较是不完整的。DeepSeek 受到关注的部分原因是其开放的态度——他们详细分享了模型权重和方法,这与西方公司日益封闭的趋势形成对比。然而,开放性是否必然带来战略优势仍有待观察。
那么,这意味着什么?
DeepSeek 的成就是真实且重要的。将其进展简单斥为宣传是不准确的。他们报告的训练成本并非史无前例,算法效率的历史趋势也支持这一点。然而,比较需要谨慎考虑背景——DeepSeek 仅报告了最终的预训练运行成本,而忽略了诸如人员成本、前期实验、数据获取和基础设施建设等关键开支。关于不同成本核算方法可能导致的误导性比较,详见 这篇文章。
算力效率的不断提升意味着 AI 能力终将扩散。 仅靠管制是不够的,还需要配套措施来增强社会的适应力和防御能力,建立能够识别、评估和应对 AI 风险的机构,并构建坚固的防御体系,以应对来自对手的潜在 AI 威胁。然而,我们也应认识到,出口管制已经对中国的 AI 发展产生了影响,并且未来可能带来更强的效应。
模型本身可能并不是许多人认为的“战略护城河”,但算力对国家安全的影响因应用场景而异。对于需要大规模部署的应用(例如大规模监控),算力限制可能形成重大障碍。而对于单用户应用,管制的影响较小。算力可获得性与国家安全能力之间的关系依然复杂,尽管模型能力本身变得越来越容易复制。
尽管 AI 能力可能会在管制之下依然扩散,而且完全阻止扩散始终是困难的,但这些管制仍然对维持技术优势至关重要。管制能争取到宝贵时间,但仍需配套政策,以确保民主国家保持领先,并能抵御潜在对手的挑战。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...