

临近年终,国内大模型领域再传喜讯。百川智能近期密集发布多款大模型产品,继全场景深度推理模型Baichuan-M1-preview和医疗增强开源模型Baichuan-M1-14B之后,又重磅推出了全模态模型Baichuan-Omni-1.5。
这款模型被誉为“大模型通才”,标志着国产大模型在多模态融合技术上取得了显著进展。Baichuan-Omni-1.5具备卓越的全模态理解与生成能力,不仅能够同时处理文本、图像、音频、视频等多模态信息,更支持文本和音频双模态内容生成。
与此同时,百川智能还开源了OpenMM-Medical和OpenAudioBench两个高质量评测数据集,旨在推动国内全模态模型技术生态的繁荣发展。根据已公开的综合评测结果,Baichuan-Omni-1.5在多项多模态能力上整体表现超越了GPT-4o Mini,尤其在百川智能持续深耕的医疗领域,其医疗图像评测成绩更是取得了显著的领先优势。 这充分展现了百川智能作为国内大模型领域的领军企业,在技术创新和行业应用落地方面的强劲实力与坚定决心。
模型权重地址:
Baichuan-Omini-1.5:https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5 https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5
Baichuan-Omini-1.5-Base:https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Base https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5-Base
GitHub地址:https://github.com/baichuan-inc/Baichuan-Omni-1.5
技术报告:https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf
01 . 多模态能力全面突破:文图音视频处理测评表现突出
Baichuan-Omni-1.5的性能亮点可以概括为“能力全面且性能卓越”。 该模型最显著的特点在于其全面的多模态理解和生成能力,具体而言,它不仅能够理解文本、图像、视频、音频等多模态内容,还支持文本和音频的双模态生成。
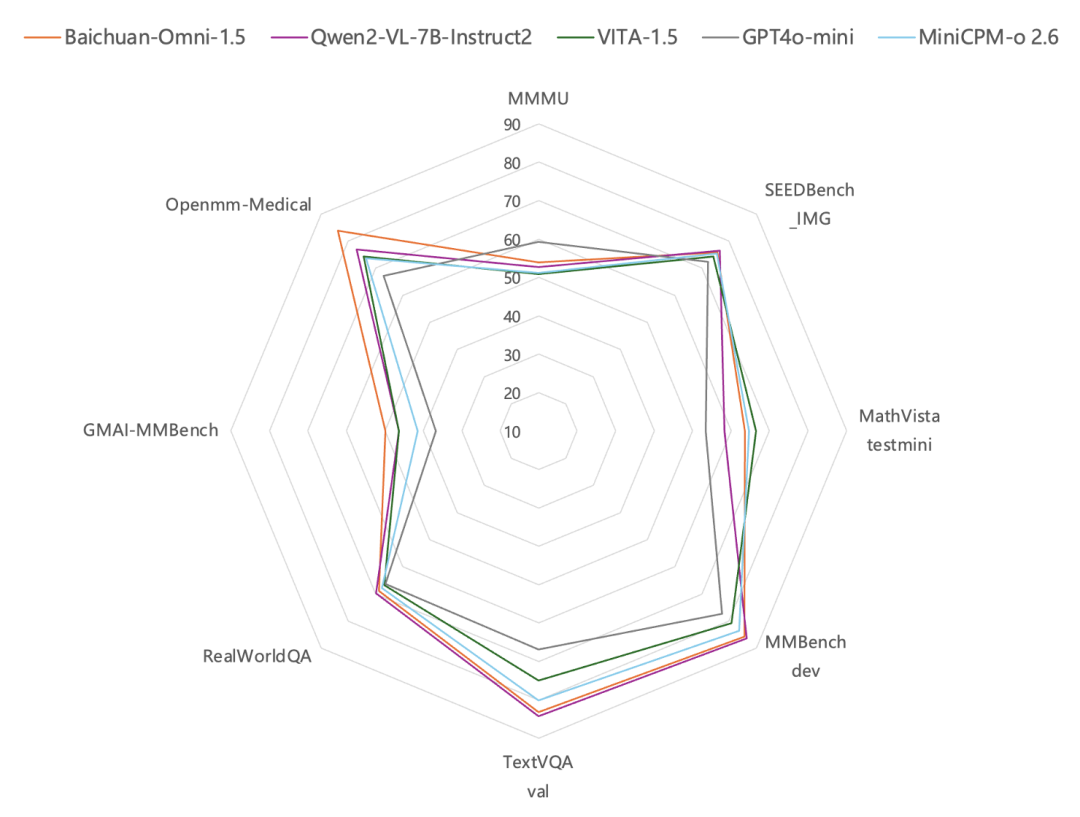
在图像理解方面,根据在 MMBench-dev、TextVQA val 等通用图像评测基准上的测试结果显示,Baichuan-Omni-1.5 的性能优于 GPT-4o Mini。尤其值得关注的是,在通用能力之外,百川智能的全模态模型在医疗垂直领域的表现尤为突出。在医疗图像评测数据集 GMAI-MMBench 和 Openmm-Medical 上的评测结果表明,Baichuan-Omni-1.5 在医疗图像理解方面的能力已经显著超越 GPT-4o Mini。
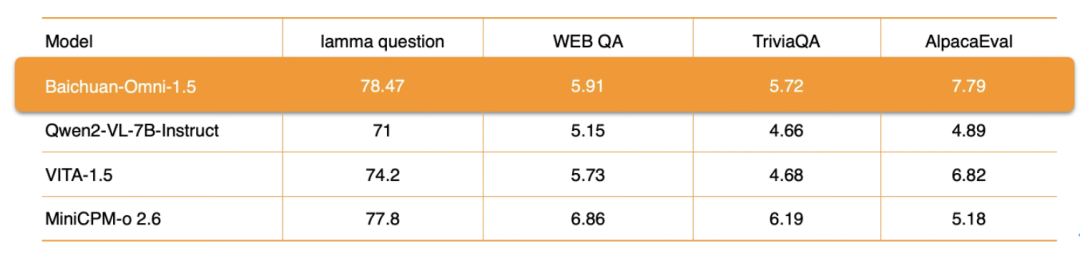
在音频处理方面,Baichuan-Omni-1.5 不仅支持多语言对话,还依托其端到端的音频合成能力,集成了 ASR(自动语音识别) 和 TTS(文本转语音) 功能。更进一步,模型还支持在此基础上实现音视频实时交互。在具体的性能指标上,Baichuan-Omni-1.5 在 lamma question 和 AlpacaEval 等数据集上的整体表现显著优于 Qwen2-VL-2B-Instruct、VITA-1.5 和 MiniCPM-o 2.6 等同类模型。
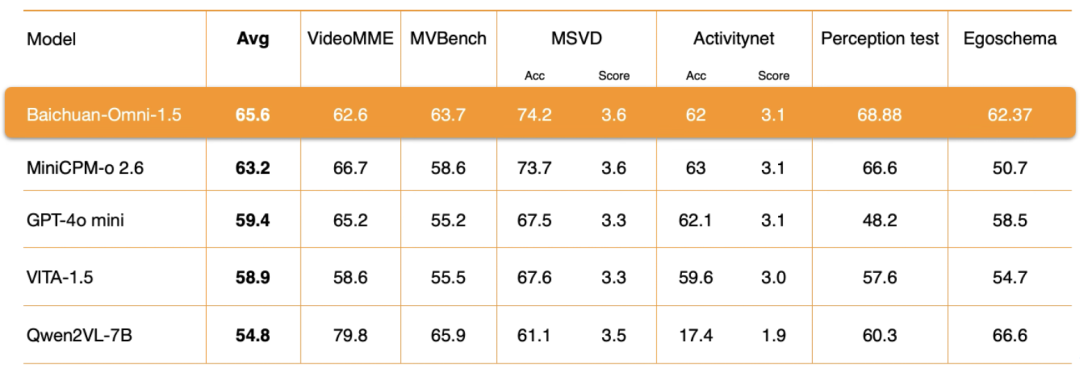
视频理解层面,百川智能针对 Baichuan-Omni-1.5 在编码器架构、训练数据质量和训练方法策略等多个关键环节进行了深入优化。评测结果显示,其视频理解的整体性能同样显著领先于 GPT-4o-mini。
综上所述,Baichuan-Omni-1.5 不仅在通用能力上整体超越了 GPT4o-mini,更重要的是实现了全模态理解和生成的统一,为构建更加通用的人工智能系统奠定了基础。
为了进一步推动多模态模型研究的进步,百川智能开源了两个专业评测数据集:OpenMM-Medical 和 OpenAudioBench。 其中 OpenMM-Medical 数据集旨在评估模型在医疗多模态任务中的性能,它整合了来自 42 个公开医学图像数据集,例如 ACRIMA(眼底图像)、BioMediTech(显微镜图像)和 CoronaHack(X 射线)等,总计包含 88996 张图像。
下载地址:
https://huggingface.co/datasets/baichuan-inc/OpenMM_Medical
OpenAudioBench 则是一个用于高效评估模型音频理解能力的综合评测平台,它包含了 5 个音频端到端理解的子评测集,其中 4 个子集来源于公开评测数据集(Llama Question、WEB QA、TriviaQA、AlpacaEval),另外 1 个子集是百川智能自建的语音逻辑推理评测集,该自建评测集包含 2701 条数据。
下载地址:
https://huggingface.co/datasets/baichuan-inc/OpenAudioBench
百川智能一直以来积极参与并推动国内开源生态的建设和繁荣。 此次开源的评测数据集为研究人员和开发者提供了统一、标准化的评估工具,有助于对不同多模态模型的性能进行客观、公正的比较分析,从而促进新一代语言理解算法和模型架构的创新发展。
02 . 全方位技术优化:数据、架构与流程协同发力,突破多模态模型瓶颈
从早期的单模态模型发展到多模态融合,再到如今的全模态模型,这一技术演进历程为人工智能技术在各行各业的落地应用拓展了更广阔的空间。然而,随着人工智能技术的深入发展,如何有效实现理解与生成在多模态模型中的统一,已经成为当前多模态领域研究的关键热点和技术难点。
一方面,理解和生成的统一是模拟人类自然交互方式,实现更自然、高效人机沟通的关键,也是通向通用人工智能(AGI)的重要环节;另一方面,不同模态数据在特征表示、数据结构和语义内涵等方面存在显著差异,如何有效提取多模态特征,并实现跨模态信息的有效交互与融合,是公认的全模态模型训练面临的最大挑战之一。
Baichuan-Omni-1.5 的发布,表明百川智能在解决上述技术难题上取得了重要进展,探索出了一条有效的技术路径。为了克服全模态模型训练中常见的“降智”问题,百川智能的研究团队从模型结构设计、训练策略优化以及训练数据构建等多个维度进行了全流程的深度优化,最终实现了理解与生成的有效统一。
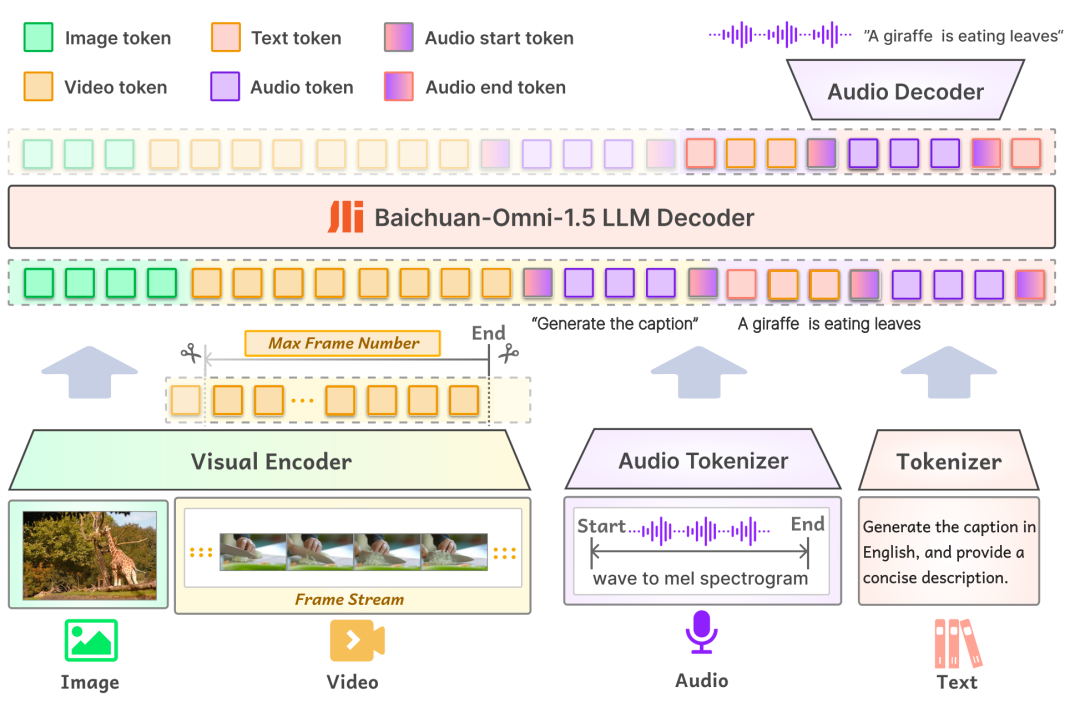
首先在模型结构方面,Baichuan-Omni-1.5 的输入层支持多种模态数据,各类模态数据通过各自对应的 Encoder/Tokenizer 被输入到大型语言模型中进行处理;在输出层,模型采用了文本-音频交错输出的设计,通过 Text Tokenizer 和 Audio Decoder 可以同时生成文本和音频两种模态的内容。 其中,Audio Tokenizer 基于 OpenAI 开源的语音识别翻译模型 Whisper 进行增量训练,从而具备了高级语义抽取和高保真音频重建能力。为了使模型能够处理不同分辨率的图像,Baichuan-Omni-1.5 引入了 NaViT 模型,支持最高 4K 分辨率的图像输入和多图推理, 从而确保模型能够全面捕捉图像信息,准确理解图像内容。
其次,在数据层面,百川智能构建了一个包含 3.4 亿条高质量图片/视频-文本数据和近 100 万小时音频数据的海量数据库,并从中精选出 1700 万条全模态数据用于模型的 SFT(监督微调)阶段。 与传统模型的数据构成不同,全模态模型的训练不仅需要数据规模的庞大,更需要数据类型的多元化和模态间的交错性。 在现实世界中,信息通常以多种模态融合呈现,不同模态的数据之间蕴含互补的信息,多模态数据的有效融合有助于模型学习到更通用的模式和规律,从而提升模型的泛化能力。 这也是构建高性能全模态模型的关键要素之一。
为了增强模型的跨模态理解能力,百川智能构建了高质量的视觉-音频-文本交错数据,并使用 1600 万图文数据、30 万纯文本数据、40 万音频数据以及上述跨模态数据对模型进行了对齐训练。 此外,为了使模型能够同时执行 ASR、TTS、音色切换和音频端到端问答等多样化的音频任务,研究团队还在对齐数据中专门构建了与这些任务相关的数据样本。
第三个关键技术点在于训练流程的优化设计,这是确保高质量数据能够有效提升模型性能的核心环节。百川智能在预训练和 SFT 阶段均采用了多阶段训练方案,以全面提升模型的效果。 其训练过程主要分为四个阶段:第一阶段以图文数据训练为主;第二阶段加入音频数据进行预训练;第三阶段引入视频数据进行训练;最后一个阶段为多模态对齐阶段,最终使模型具备对全模态内容的综合理解能力。
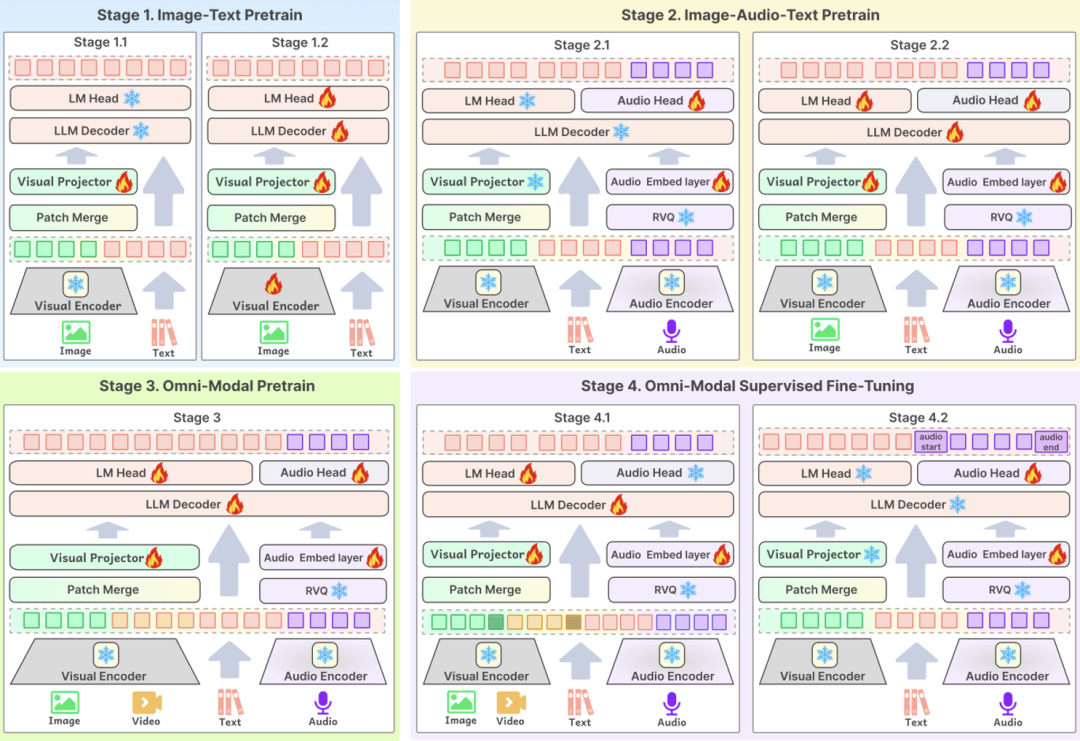
基于上述全方位的技术优化,Baichuan-Omni-1.5 的整体能力相较于传统的单一模态大语言模型或多模态模型实现了显著提升。Baichuan-Omni-1.5 的发布不仅是百川智能在技术研发上的又一重要里程碑,也预示着人工智能的发展重心正在从侧重模型基础能力提升向实际应用落地加速转移。
此前,大模型的能力提升主要集中在语言理解、图像识别等基础能力方面,而 Baichuan-Omni-1.5 强大的多模态融合能力,将有助于技术与实际应用场景实现更紧密的结合。 通过提升模型在语言、视觉、音频等多模态信息处理上的综合能力,Baichuan-Omni-1.5 能够有效应对更加复杂和多样化的实际应用任务。例如,在医疗行业,全模态模型的强大理解和生成能力可以用于辅助医生进行疾病诊断,提高诊断的准确性和效率,这对于推动人工智能技术在医疗领域的深入应用具有重要的探索价值。 展望未来,Baichuan-Omni-1.5 的发布或将成为 AGI 时代人工智能技术在医疗健康领域应用的开端, 让我们有理由期待在不久的将来,人工智能将在医疗等领域发挥更大的作用, 深刻改变我们的生活。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...