
FireRed-Image-Edit - 小红书团队开源的通用图像编辑模型
FireRed-Image-Edit 是小红书 Super Intelligence 团队开源的通用图像编辑模型,基于扩散 Transformer 架构,在 GEdit、ImgEdit 等多个权威评测...
OpenAkita - 开源的自进化AI助手框架,多平台无缝协作
OpenAkita是开源的自进化AI助手框架,提供智能、灵活且易于使用的AI辅助工具。每日自动执行内存整合、错误自检与修复、任务复盘,遇到卡壳时自动生成新技能并安装依赖,越用越聪明。支持Windows...
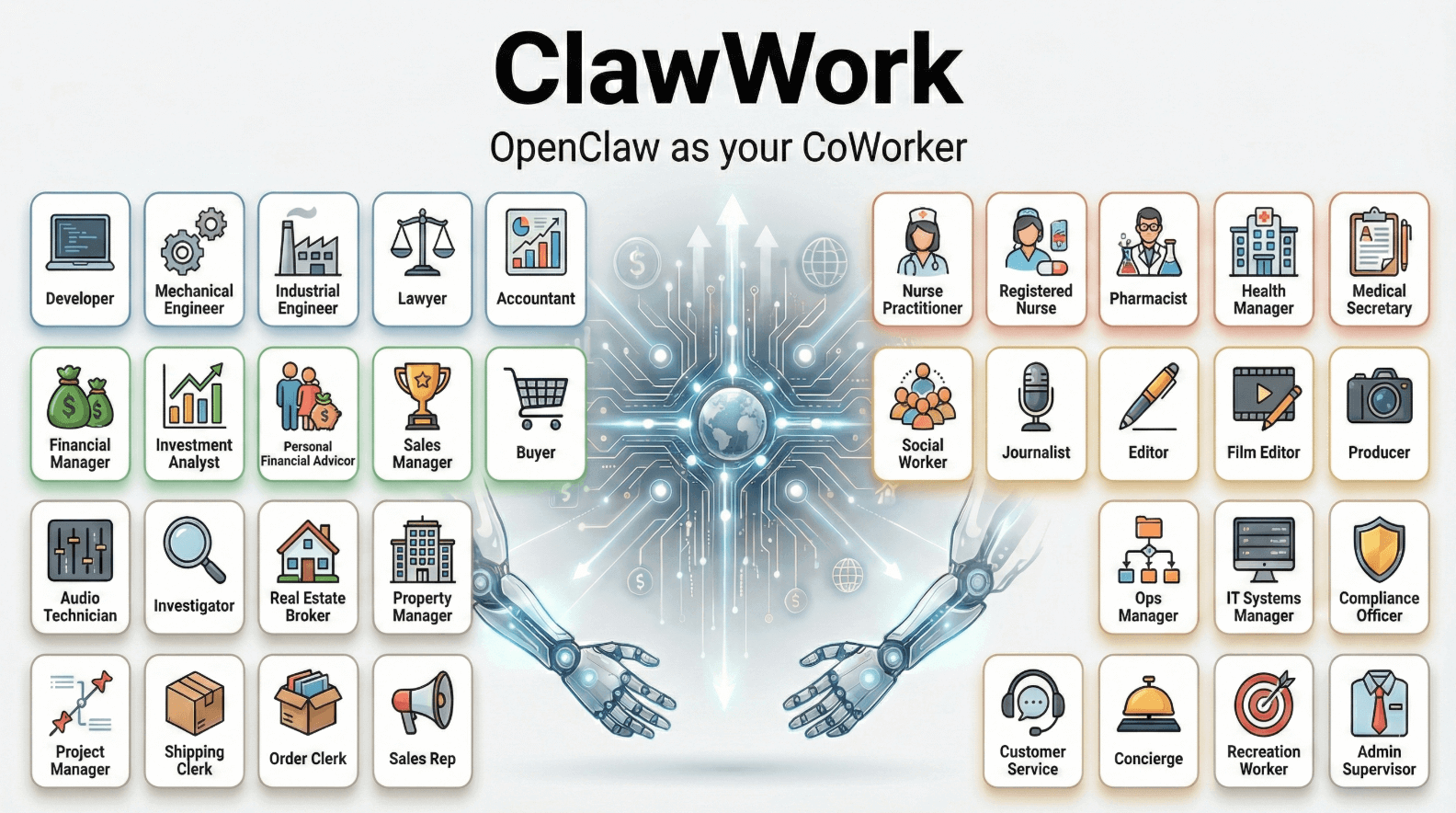
ClawWork - 香港大学数据科学实验室开源的AI经济压力测试框架
ClawWork是香港大学数据科学实验室开发的AI经济压力测试框架,允许AI在模拟经济环境中完成真实工作任务并获得报酬。核心逻辑是让初始资金仅10美元的AI通过完成220个专业任务(覆盖制造、金融、医...

Ming-Omni-tts - 蚂蚁联合Inclusion AI开源的多模态音频生成模型
Ming-Omni-tts 是蚂蚁集团与Inclusion AI联合开源的多模态音频生成模型,包含0.5B和16.8B-A3B两个版本。模型首次实现了语音、环境音和音乐的统一自回归生成,支持语速、音量...

Qwen3.5 - 阿里通义千问团队开源的最新一代大语言模型
Qwen3.5是阿里巴巴通义千问团队开源的最新一代大语言模型,属于千问(Qwen)系列的升级版本。Qwen3.5突破了传统文本模型的限制,实现了真正的原生多模态理解,可直接处理文本、图像、视频等多种模...

Ring-2.5-1T - 蚂蚁百灵开源的万亿参数混合线性架构思考模型
Ring-2.5-1T 是蚂蚁集团百灵大模型团队开源的全球首个万亿参数混合线性架构思考模型,采用1:7 MLA与Lightning Linear Attention混合设计,激活参数量达63B。模型在...
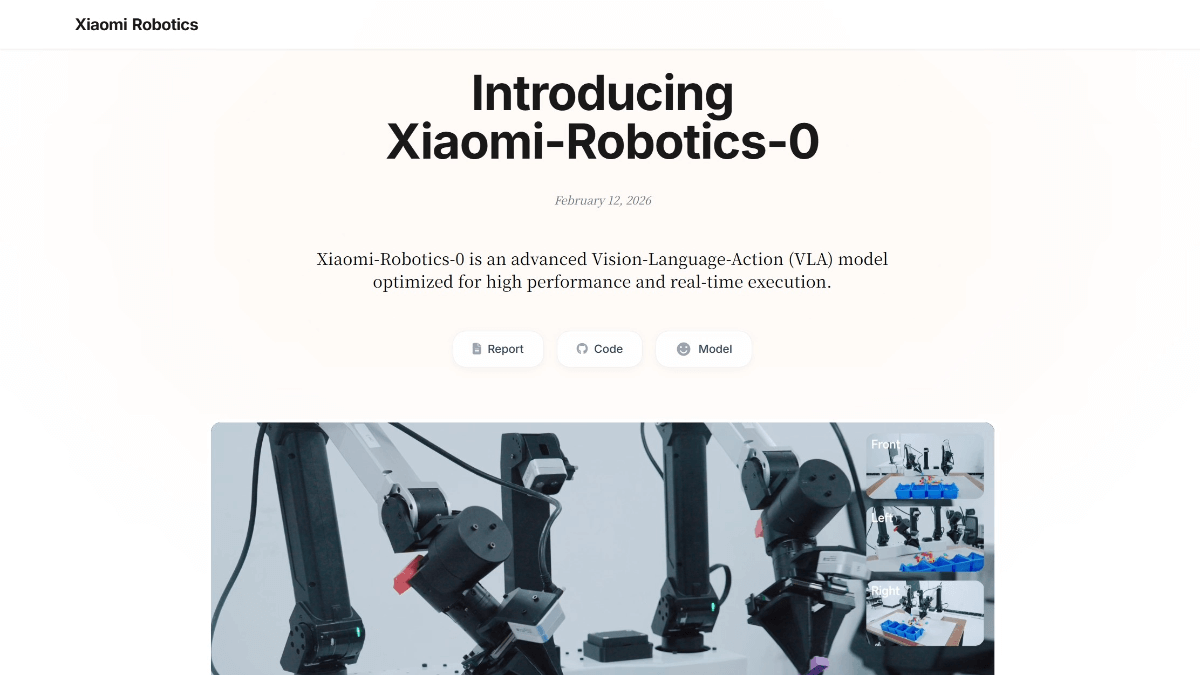
Xiaomi-Robotics-0 - 小米开源的首代具身智能大模型
Xiaomi-Robotics-0 是小米开源的首代具身智能大模型,拥有47亿参数,采用"大脑+小脑"混合架构设计。视觉语言大脑基于多模态大模型,负责理解人类模糊指令与空间推理;动作执行小脑则通过Di...

AionUi - 免费开源的多AI Agent桌面应用
AionUi是一个免费开源的多AI Agent桌面应用,支持将Gemini CLI、Claude Code等命令行AI工具整合到图形界面,提供本地文件操作、多会话管理、跨平台运行等功能。支持macOS...
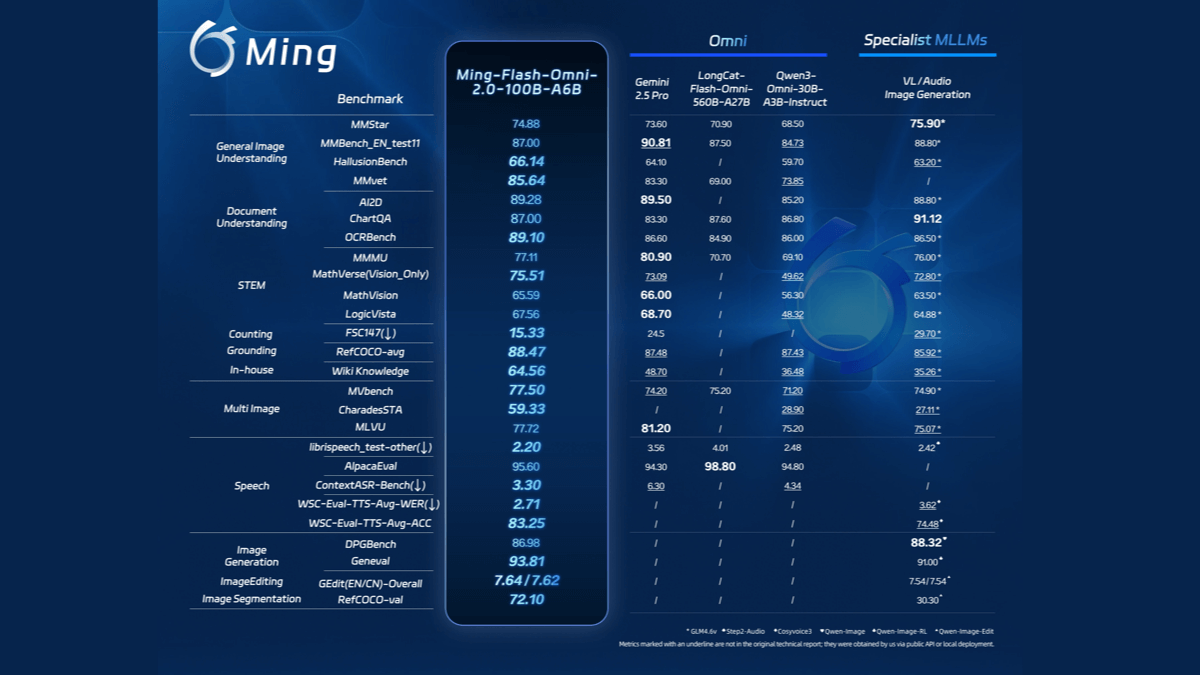
Ming-flash-omni 2.0 - 蚂蚁集团开源的全模态大模型
Ming-flash-omni 2.0是蚂蚁集团开源的全模态大模型,集成了视觉、语音和生成能力的AI模型,在多项基准测试中性能领先。支持同时生成语音、环境音效和音乐,能通过自然语言指令精细控制音色、语...

Protenix-v1 - 字节Seed团队推出的首个开源蛋白质结构预测模型
Protenix-v1是字节跳动ByteDance Seed团队推出的首个开源蛋白质结构预测模型,性能在严格对齐训练数据和模型规模后超越AlphaFold 3。模型具备显著的推理时扩展特性:通过增加采...