

Wall-OSS-0.5是什么
Wall-OSS-0.5 是自变量机器人(X Square Robot)推出的开源视觉-语言-动作(VLA)大模型,拥有 40 亿参数,基于 30 亿参数的 VLM 骨干网络构建。采用"梯度桥接协同训练"技术,在 20 多种机器人形态、每轮超 100 万条真实轨迹以及 9000 万条多模态语料上完成预训练。模型最大的突破是"预训练即可部署",无需针对特定任务微调,预训练检查点就能直接在真实机器人硬件上执行零样本操作,在 17 项真实机器人任务中有 4 项达到 80% 以上任务进度;经过微调后,在 15 项任务上平均进度达 60.5%,领先 π0.5 达 17.5 个百分点。模型权重与训练代码已完全开源。
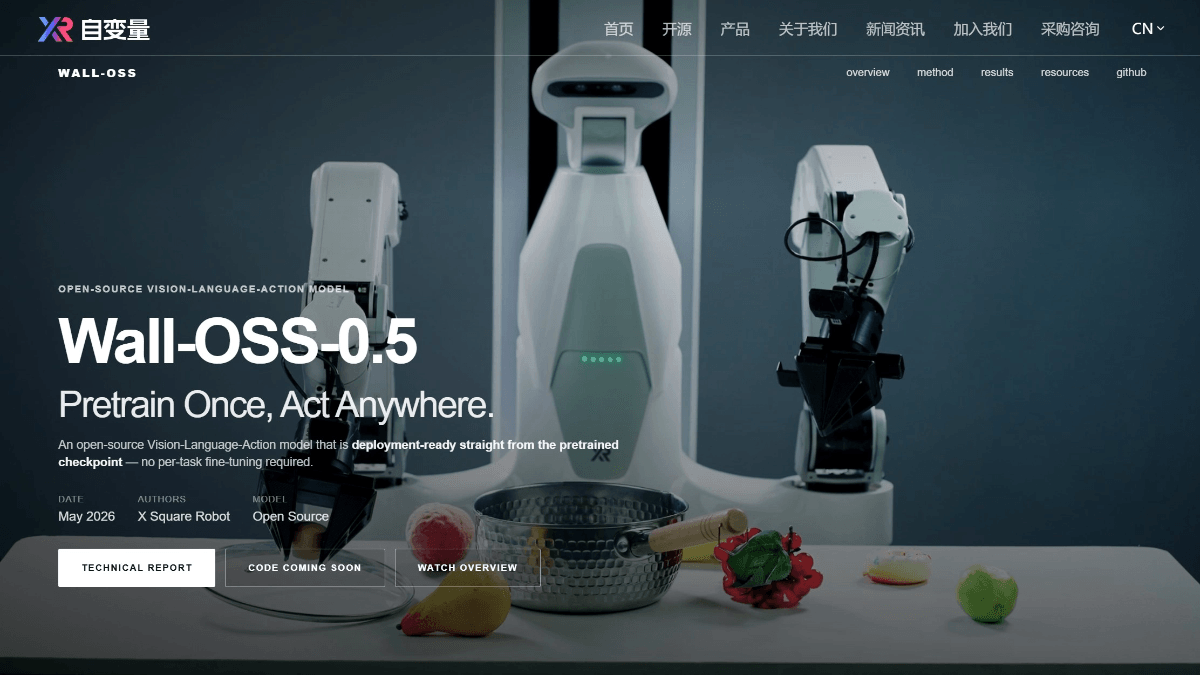
Wall-OSS-0.5的功能特色
- 零样本真实机器人操作:预训练检查点直接部署到物理硬件,无需任务特定微调即可执行抓取、排序等操作。
- 多形态统一适配:支持桌面双臂、移动操作等多种机器人形态,单个预训练检查点跨形态通用。
- 三目标协同训练:离散动作预测、多模态预测与连续流匹配三者互补优化,形成"梯度桥接"。
- 混合专家架构(MoT):视觉-语言令牌通过 VL Expert 路由,连续动作计算通过 Action Expert 处理,联合注意力实现端到端梯度流动。
- 完全开源可复现:模型权重、训练代码及推理工具链均已发布,支持社区二次开发与微调。
Wall-OSS-0.5的核心优势
- 部署即用:区别于传统 VLA 模型必须微调后才能使用,预训练检查点直接产生可执行的机器人策略。
- 高效适应:在 15 项真实机器人任务上微调后平均进度 60.5%,比 π0.5 的 43.0% 高出 17.5 个百分点。
- 强泛化能力:在 3 项未见过的任务(如变形物体操作)上依然保持高进度,绳索收紧任务达 82%。
- 视觉语言能力保持:动作训练不会侵蚀基础 VLM 能力,实体 grounding 能力提升 21.8 个百分点,通用 VL 能力完整保留。
- 数据规模领先:覆盖 20+ 种机器人形态,每轮 100 万+ 轨迹,9000 万多模态样本(含 1200 万实体桥接样本)。
Wall-OSS-0.5官网是什么
- 项目地址:https://x2robot.com/oss#resources
- Github仓库:https://github.com/X-Square-Robot/wall-x
- 论文地址:https://x2robot.com/api/files/file/wall_oss_05.pdf
Wall-OSS-0.5的操作步骤
- 环境准备:创建 Python 3.10 的 conda 环境,安装基础依赖及 Flash Attention 2.7.4+。
- 安装 LeRobot:克隆 Hugging Face 的 LeRobot 库,checkout 指定版本后执行 pip 安装。
- 安装 Wall-X:克隆 wall-x 仓库,运行
git submodule update --init --recursive后安装。 - 下载模型:从 Hugging Face(x-square-robot/wall-oss-0.5)下载预训练权重。
- 配置参数:根据目标机器人类型设置 DOF 配置、模型路径、数据路径及训练超参数。
- 运行微调:执行
bash ./workspace/lerobot_example/run.sh在 LeRobot 数据集上微调。 - 部署推理:加载预训练或微调后的检查点,在真实机器人硬件上执行零样本或微调后推理。
Wall-OSS-0.5的适用人群
- 具身智能研究人员:从事 VLA、机器人学习等方向的高校及实验室研究者。
- 机器人硬件工程师:需要将智能操作能力集成到 UR、Franka、ARX-5 等硬件平台的开发人员。
- AI 应用开发者:希望基于开源 VLA 模型构建自定义机器人应用的工程师。
- 自动化领域从业者:探索工业或服务机器人智能化升级的技术团队。
Wall-OSS-0.5的常见问题
Q:Wall-OSS-0.5 与 WALL-OSS-Flow 有什么区别?
A:Wall-OSS-0.5 是最新版本,采用梯度桥接协同训练,实现了预训练检查点直接零样本部署;WALL-OSS-Flow 是早期版本,需要更多后处理才能使用。
Q:是否必须微调才能使用?
A:不需要。Wall-OSS-0.5 的核心设计就是预训练检查点可直接在真实机器人上部署,微调仅用于进一步提升特定任务表现。
Q:支持哪些机器人类型?
A:已验证支持桌面双臂、移动操作等 20 多种形态,兼容 LeRobot 数据格式的机器人均可适配。
Q:与 π0.5 相比性能如何?
A:在 15 项真实机器人任务微调测试中,Wall-OSS-0.5 平均进度 60.5%,显著领先 π0.5 的 43.0%。
Q:动作训练会损害语言理解能力吗?
A:不会。多模态评估证实模型在增强实体 grounding 的同时,完整保留了广泛的视觉-语言理解与推理能力。
Q:商业使用是否免费?
A:模型已开源发布,具体商用权利请查看 GitHub 仓库中的 LICENSE 文件。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...