
综合介绍
VideoChat 是一个基于开源技术的实时语音交互数字人项目,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。该项目允许用户自定义数字人的形象与音色,并支持音色克隆及唇形同步,支持视频流输出,首包延迟低至3秒。用户可以通过在线demo体验其功能,或通过详细的技术文档进行本地部署和使用。
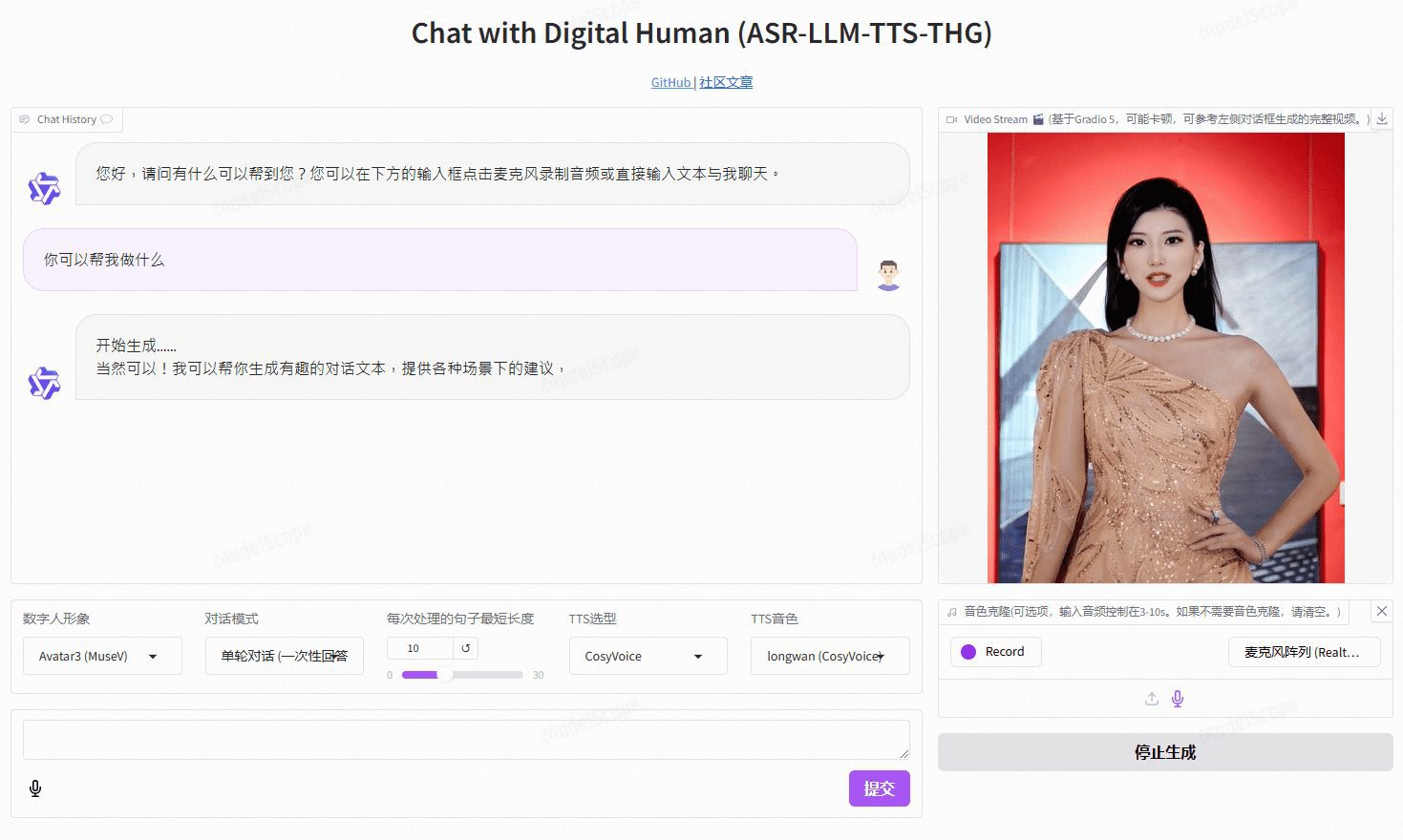
演示地址:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
功能列表
- 实时语音交互:支持端到端语音方案和级联方案
- 自定义形象与音色:用户可以根据需求自定义数字人的外观和声音
- 语音克隆:支持克隆用户的声音,提供个性化的语音体验
- 低延迟:首包延迟低至3秒,确保流畅的交互体验
- 开源项目:基于开源技术,用户可以自由修改和扩展功能
使用帮助
安装流程
- 环境配置
- 操作系统:Ubuntu 22.04
- Python 版本:3.10
- CUDA 版本:12.2
- Torch 版本:2.1.2
- 克隆项目
git lfs install git clone https://github.com/Henry-23/VideoChat.git cd video_chat - 创建虚拟环境并安装依赖
conda create -n metahuman python=3.10 conda activate metahuman pip install -r requirements.txt pip install --upgrade gradio - 下载权重文件
- 推荐使用创空间下载,已设置 git lfs 追踪权重文件
git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git - 启动服务
python app.py
使用流程
- 配置API-KEY:
- 如果本地机器性能有限,可以使用阿里云大模型服务平台百炼提供的Qwen API和CosyVoice API,在
app.py中配置API-KEY。
- 如果本地机器性能有限,可以使用阿里云大模型服务平台百炼提供的Qwen API和CosyVoice API,在
- 本地推理:
- 如果不使用API-KEY,可以在
src/llm.py和src/tts.py中配置本地推理方式,删除不需要的API调用代码。
- 如果不使用API-KEY,可以在
- 启动服务:
- 运行
python app.py启动服务。
- 运行
- 自定义数字人形象:
- 在
/data/video/目录中添加录制好的数字人形象视频。 - 修改
/src/thg.py中的Muse_Talk类的avatar_list,加入形象名和bbox_shift。 - 在
app.py中Gradio的avatar_name中加入数字人形象名后重新启动服务,等待完成初始化。
- 在
详细操作流程
- 自定义形象与音色:在
/data/video/目录中添加录制好的数字人形象视频,并在src/thg.py中修改Muse_Talk类的avatar_list,加入形象名和bbox_shift参数。 - 语音克隆:在
app.py中配置CosyVoice API或使用Edge_TTS进行本地推理。 - 端到端语音方案:使用
GLM-4-Voice模型,提供高效的语音生成和识别功能。
- 访问本地部署的服务地址,进入Gradio界面。
- 选择或上传自定义的数字人形象视频。
- 配置语音克隆功能,上传用户的语音样本。
- 开始实时语音交互,体验低延迟的对话功能。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...