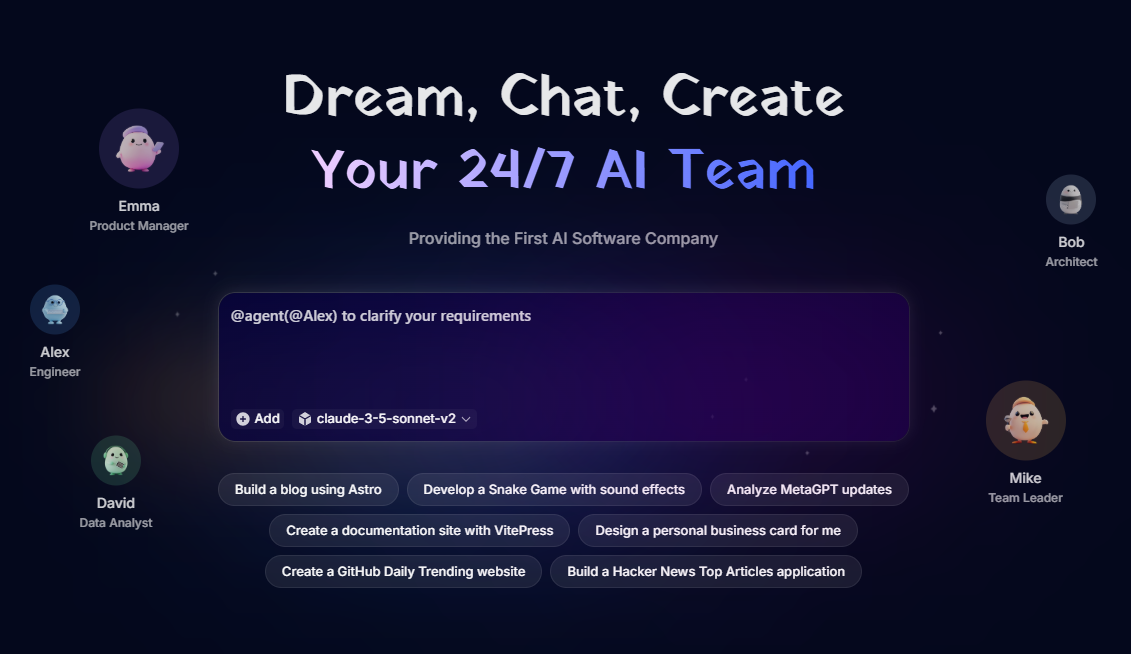

综合介绍
UniAPI 是一个兼容 OpenAI 协议的 API 转发器,核心功能是通过统一的 OpenAI 格式管理多个大模型服务商的 API,比如 OpenAI、Azure OpenAI、Claude 等。开发者可以用一个接口调用不同厂商的模型,无需频繁调整代码。UniAPI 支持模型择优、断路器机制和流式输出优化,确保请求高效稳定。它提供 Vercel 一键部署,适合快速搭建个人或团队的 API 服务站。项目由 GitHub 用户 zhangtyzzz 开发,仍在持续更新中。

功能列表
- 支持 OpenAI 及兼容 OpenAI 协议的服务,包括 Azure OpenAI、Claude 等。
- 将不同厂商的 API 统一转换为 OpenAI 格式,简化调用流程。
- 支持模型映射,用统一模型名调用不同厂商的实际模型。
- 提供模型择优机制,根据 72 小时成功率和首 token 响应时间选择最佳服务。
- 内置断路器机制,服务连续失败后自动暂停请求,保护系统稳定性。
- 优化流式输出,把大块响应拆成小块,提升视觉效果。
- 支持自定义 API 密钥、Base URL 和模型列表,灵活配置。
- 通过 Vercel 部署,提供管理面板和安全认证。
使用帮助
UniAPI 的使用分为部署和配置两部分。下面详细介绍如何安装、配置和操作,确保你能快速上手。
安装流程
UniAPI 支持两种部署方式:本地运行和 Vercel 一键部署。这里以 Vercel 部署为主,适合大多数用户。
Vercel 一键部署
- 访问部署链接
点击官方提供的 Vercel 部署地址 - 配置环境变量
在 Vercel 部署页面填写以下变量:ADMIN_API_KEY:管理员密钥,用于登录管理面板,必须设置,例如mysecretkey。TEMP_API_KEY:允许访问 API 的密钥,可设置最多 2 个,例如key1和key2。REDIS_URL:Redis 连接地址,用于持久化存储配置(可选)。ENVIRONMENT:设为production以禁用开发模式默认密钥。
配置完成后,点击“Deploy”。
- 获取部署地址
部署成功后,Vercel 会生成一个 URL,比如https://your-vercel-url.vercel.app。用ADMIN_API_KEY登录管理面板。
本地运行(可选)
- 准备环境
确保设备安装 Python 3.8 或以上。检查版本:
python --version
- 下载文件
访问 https://github.com/zhangtyzzz/uni-api/releases,下载最新二进制文件,例如uni-api-linux-x86_64-0.0.99.pex。 - 运行程序
在终端执行:
chmod +x uni-api-linux-x86_64-0.0.99.pex
./uni-api-linux-x86_64-0.0.99.pex
默认监听 http://localhost:8000。
配置 API
- 登录管理面板(Vercel 部署)
打开部署后的 URL,输入ADMIN_API_KEY登录。界面显示“添加配置”和“配置列表”。 - 添加 API 配置
点击“添加配置”,填写以下内容:
- 服务商:选择 OpenAI、Claude 等。
- Base URL:输入服务商的 API 地址,例如
https://api.openai.com/v1。 - API 密钥:输入从服务商获取的密钥,例如
sk-xxxx。 - 模型名称:输入实际模型名或映射名,例如
gpt-3.5-turbo。
保存后,配置会显示在列表中。
- 模型映射
在配置中添加映射,例如:
- 统一名称
gpt-4映射到 OpenAI 的gpt-4和 Claude 的claude-2。
请求时用gpt-4,系统自动选择可用服务。
使用主要功能
- 发送请求
用 curl 测试 API:
curl -X POST https://your-vercel-url.vercel.app/v1/chat/completions
-H "Authorization: Bearer your_api_key"
-H "Content-Type: application/json"
-d '{"model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": "你好"}], "stream": true}'
返回流式输出,表示配置成功。
- 模型择优
系统会根据过去 72 小时的成功率和首 token 响应时间,自动选择最佳服务商。你无需手动干预。 - 断路器机制
当某服务连续失败时,触发断路器:
- 3 次失败:暂停 5 分钟。
- 4 次失败:暂停 10 分钟。
- 9 次失败:暂停 48 小时。
暂停期间,系统切换到其他服务商。
- 流式优化
对于 Gemini 等大块响应的模型,UniAPI 自动拆分成小块输出。
常见问题解决
- 请求失败 401:检查
Authorization头是否包含正确的Bearer your_api_key。 - 模型不可用:确保配置的模型名与服务商提供的一致,或检查映射设置。
- 部署后无法访问:确认
ENVIRONMENT设为production,并检查 Vercel 日志。
通过以上步骤,你可以轻松部署并使用 UniAPI。它的配置简单,功能强大,非常适合需要管理多厂商 API 的场景。
应用场景
- 开发者测试多厂商模型
你想比较 OpenAI 和 Claude 的输出效果。UniAPI 让你用一个接口调用两者,节省时间。 - 团队搭建稳定 API 服务
团队需要一个可靠的 API 站支持业务。UniAPI 的断路器和择优机制确保服务不中断。 - 教育和研究
学生可以用 UniAPI 研究不同模型的响应速度和稳定性,适合学术实验。
QA
- UniAPI 支持哪些服务商?
支持 OpenAI、Azure OpenAI、Claude 等兼容 OpenAI 协议的服务,具体见 GitHub 更新。 - 断路器触发后怎么办?
系统自动切换其他服务商,冷却期后重试。无需手动操作。 - 流式输出有什么优势?
它把大块响应拆成小块,用户体验更流畅,尤其适合实时聊天场景。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...