

UltraEval-Audio是什么
UltraEval-Audio是清华大学NLP实验室、OpenBMB和面壁智能联合开源的音频模型评测框架,最新版本为v1.1.0。专注于解决音频模型复现难、依赖冲突等问题,提供一键复现热门模型(如VoxCPM、MiniCPMO2.6等)的功能,支持TTS、ASR、Codec等专有模型的评测。框架通过隔离推理运行机制避免环境冲突,覆盖语音识别、音乐分类、音频生成等任务,显著提升了研究者的工作效率。
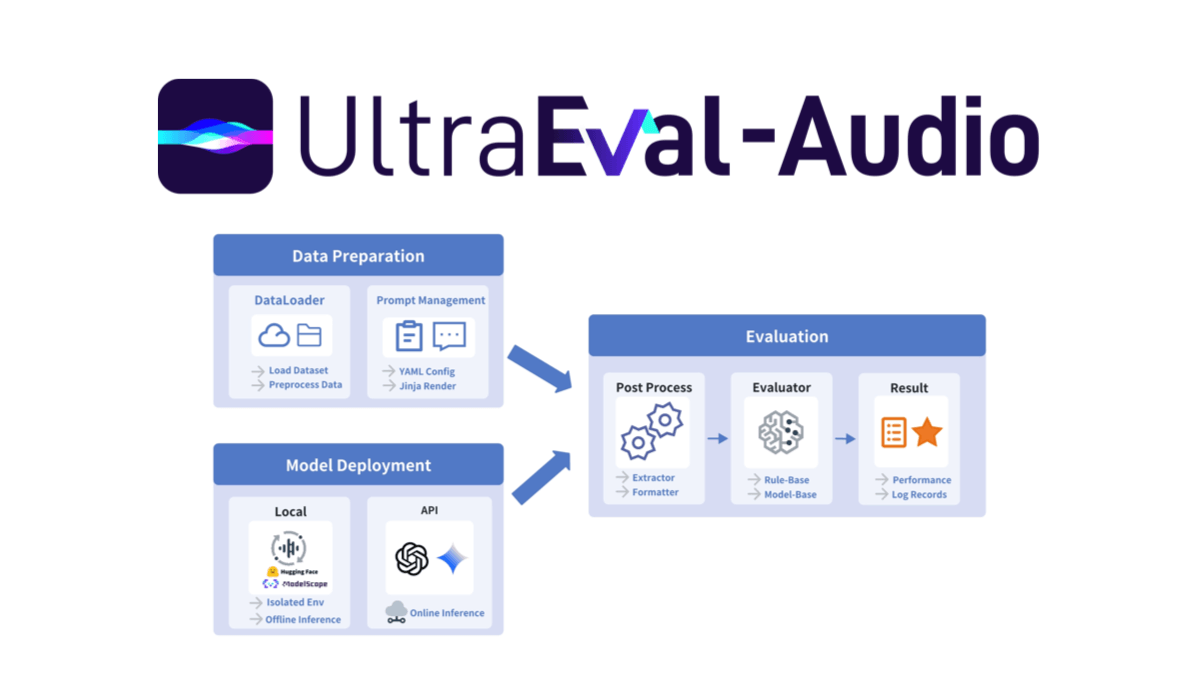
UltraEval-Audio的功能特色
- 一键复现功能:新增热门音频模型的一键复现能力,支持包括 MiniCPM-o2.6、VoxCPM 在内的十余种前沿模型快速部署,大大降低了模型复现的门槛。
- 扩展专业模型支持:扩展了对语音合成(TTS)、自动语音识别(ASR)和编解码器(Codec)等专业模型的支持,覆盖语音生成、识别、压缩等全场景。
- 隔离推理运行机制:引入隔离推理运行机制,通过容器化技术将模型运行环境与评测流程解耦,显著降低硬件适配门槛,提升评测流程的可控性和可移植性。
- 丰富的评估方法:支持预览测试、随机样本、错误重试、断点重跑等功能,确保评估过程灵活可控,提升效率与准确性。
- 自定义数据集支持:支持自定义数据集,用户可以根据自己的研究需求,灵活地将自定义数据集集成到评估框架中。
- 标准化评测流程:提供标准化的评测流程,使不同研究团队的评估结果具有可比性,有效避免因评估标准差异导致的争议。
UltraEval-Audio的核心优势
- 全面支持专业模型:涵盖语音合成(TTS)、自动语音识别(ASR)和编解码器(Codec)等专业模型,满足多样化需求。
- 隔离推理运行机制:通过容器化技术,实现模型运行环境与评测流程的解耦,提升评测的可控性和可移植性。
- 丰富的评估方法:提供预览测试、随机样本、错误重试、断点重跑等功能,确保评估过程灵活且高效。
- 自定义数据集支持:允许用户灵活集成自定义数据集,满足个性化研究需求。
- 标准化评测流程:确保不同研究团队的评估结果具有可比性,避免因评估标准差异导致的争议。
- 多语言多领域覆盖:支持多种语言和多个领域的评估任务,适用范围广泛。
- 一键式基准管理:自动化完成基准测试数据的下载和处理,简化评估流程。
UltraEval-Audio官网是什么
- Github仓库:https://github.com/OpenBMB/UltraEval-Audio/
UltraEval-Audio的适用人群
- 语音大模型开发者:用于评估和优化语音模型的性能,提升模型在语音识别、合成和理解等任务上的表现。
- 音频技术研究人员:进行音频相关领域的研究,如语音合成、语音识别、音频编解码等。
- 语音应用工程师:开发语音交互系统、智能语音助手等应用,需要对语音模型进行评估和集成。
- 学术研究人员:在语音和音频领域开展学术研究,需要标准化的评估工具来验证研究成果。
- 行业从业者:在音频技术相关行业工作,需要对不同语音模型进行比较和选择。
- 高校师生:在语音和音频技术相关的课程教学和科研项目中使用,帮助学生理解和实践语音模型评估。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...