

Transformer LLMs工作原理是什么
Transformer LLMs工作原理是DeepLearning.AI与《Hands-On Large Language Models》的作者Jay Alammar和Maarten Grootendorst合作推出的课程。课程深入剖析支持大型语言模型(LLMs)的Transformer架构。课程从语言的数值表示演变讲起,涵盖分词、Transformer块的注意力机制与前馈层,及如何通过缓存计算提升性能等内容。学完后,用户将深入了解LLMs处理语言的方式,能读懂相关论文,提升构建LLM应用的能力。
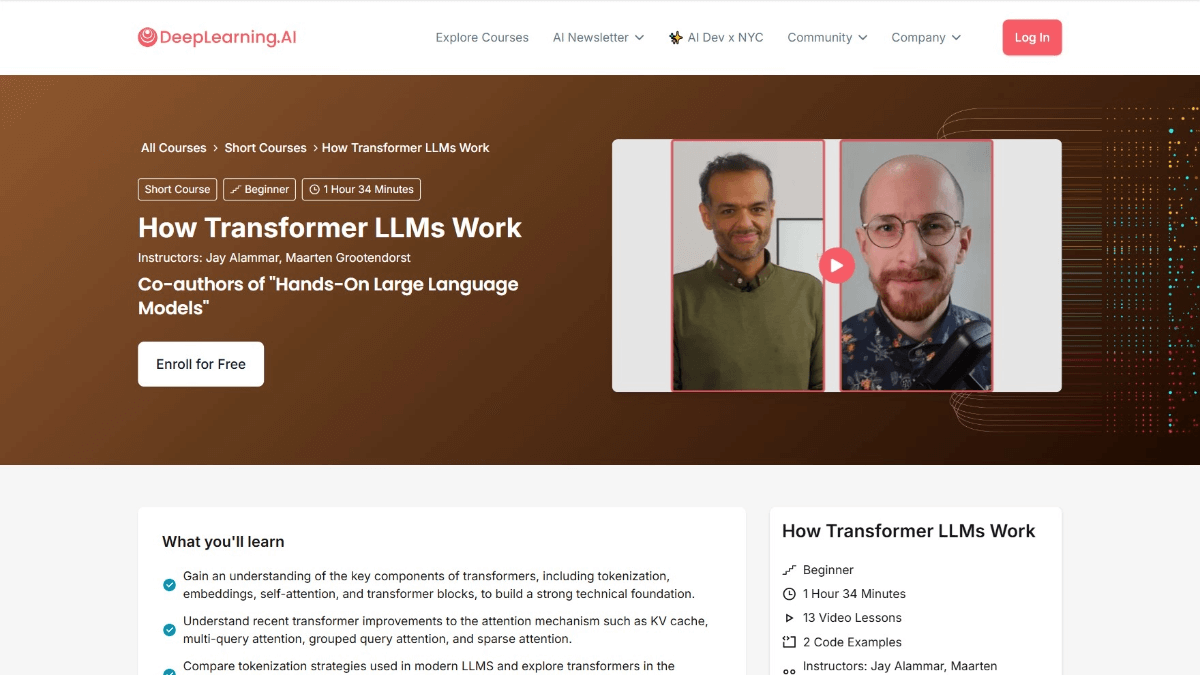
Transformer LLMs工作原理的课程目标
- 理解语言的数值表示演变:从简单的Bag-of-Words模型到复杂的Transformer架构,了解语言如何被数字化表示。
- 掌握分词处理:学习如何将输入文本分解为“token”,并理解token如何被送入语言模型。
- 深入Transformer架构:详细探讨Transformer架构的三个主要阶段:分词和嵌入、Transformer块堆叠、及语言模型头部。
- 理解Transformer块的细节:包括注意力机制和前馈层,及如何协同工作处理和生成文本。
- 学习性能优化:了解如何通过缓存计算等技术提升Transformer的性能。
- 实际应用探索:通过Hugging Face Transformer库,探索最近模型的实现,增强实际应用能力。
Transformer LLMs工作原理的课程大纲
- Transformer LLMs概述:介绍课程目标、结构及Transformer架构在现代大语言模型(LLMs)中的重要性。
- 语言表示的演变:从词袋模型(Bag-of-Words)到Word2Vec,再到Transformer架构,了解语言模型的发展历程。
- 分词与嵌入:学习输入文本如何被分解成token,及如何将token转换为嵌入向量,包括位置编码的应用。
- Transformer块:了解Transformer块的结构,包括自注意力机制和前馈网络的作用。
- 多头注意力:探索多头注意力机制如何通过多个“头”捕捉输入的不同方面,提升模型性能。
- Transformer块堆叠:学习如何通过堆叠多个Transformer块构建深度模型,及残差连接和层归一化的作用。
- 语言模型头:了解Transformer如何通过语言模型头生成下一个token的概率分布,实现文本生成。
- 缓存机制:学习如何通过缓存机制提高Transformer模型的推理速度,及缓存的实际应用。
- 最新架构创新:介绍混合专家模型(Mixture-of-Experts, MoE)及其他Transformer架构的最新创新。
- 使用Hugging Face实现Transformer:学习如何用Hugging Face Transformers库加载和微调预训练的Transformer模型。
- Transformer的实践编码:通过实际的编码练习,学习如何实现Transformer的关键组件,并构建简单的Transformer模型。
- 阅读和理解研究论文:学习如何阅读和理解Transformer相关的研究论文,分析近期论文及其对领域的贡献。
- 构建LLM应用:探讨如何开发基于LLM的应用程序,讨论Transformer架构的未来发展方向和潜在应用。
Transformer LLMs工作原理的课程地址
- 课程地址:DeepLearning.AI
Transformer LLMs工作原理的适用人群
- 自然语言处理研究人员:深入研究Transformer架构,探索在语言理解、生成和翻译等领域的前沿应用,推动自然语言处理技术的发展。
- 机器学习工程师:掌握Transformer的工作原理,能优化模型性能,提升模型的准确性和效率,开发更强大的语言模型应用。
- 数据科学家:用Transformer架构处理和分析大规模文本数据,挖掘数据中的模式和信息,为决策提供支持。
- 软件开发者:将Transformer LLMs集成到各种软件应用中,如聊天机器人、内容推荐系统等,提升产品的智能化水平。
- 人工智能爱好者:对Transformer架构感兴趣,希望通过学习其工作原理,深入了解人工智能技术,拓展技术视野。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...