


数学能力,包含公式推导、逻辑链构建和抽象思维,长期以来被视为检验人工智能(AI),特别是大型语言模型(LLM)能力的关键领域。因为它不仅测试计算能力,更深入地考察了模型的推理、理解和解决复杂问题的能力。
然而,近期来自苏黎世联邦理工学院(ETH)团队的研究结果显示,即使是顶尖的大型语言模型,在面对高难度的数学竞赛题目时,例如美国数学奥林匹克竞赛级别的挑战,其得分率也普遍偏低,这引发了对当前 LLM 在严谨数学推理方面真实能力的讨论。
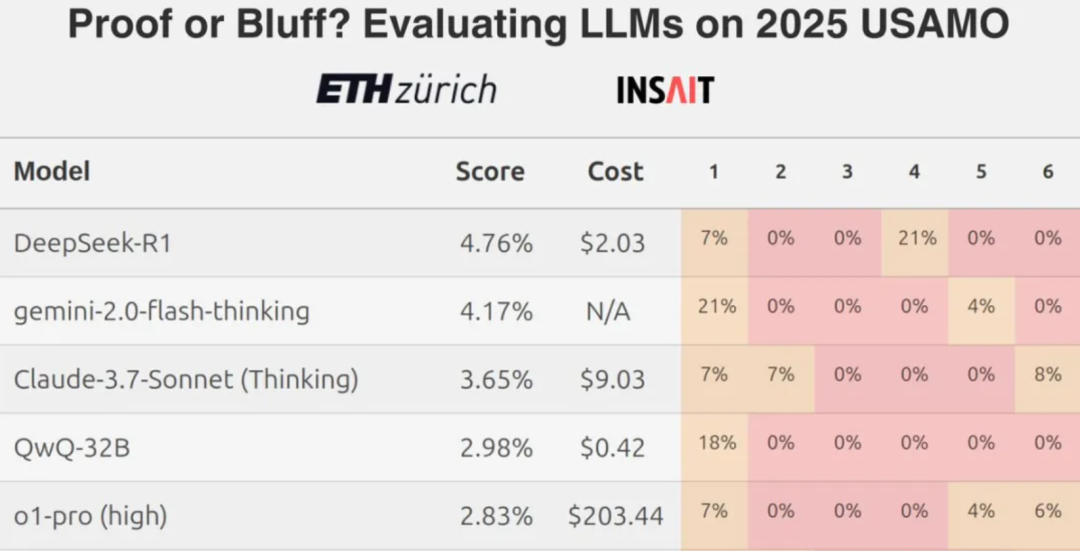
在此背景下,一个自然的问题是:这些模型在处理以中文表述的数学问题时表现如何?本评测选取了国内外共 7 款主流或新兴的大型语言模型,使用来自阿里巴巴全球数学竞赛和中国数学奥林匹克竞赛的真题,进行了一次数学能力的横向比较。
参与测试的模型包括:
- 国产模型:
DeepSeek R1、Hunyuan T1、Tongyi Qwen-32B(原文通义QwQ-32B)、YiXin-Distill-Qwen-72B - 国际模型:
Grok 3 beta、Gemini 2.0 Flash Thinking、o3-mini
总体性能评估
评测选取了 10 道具有较高难度的竞赛真题,共包含 13 个计分小问。评分标准为:完全正确得 1 分,部分正确得 0.5 分,错误不得分。
各模型在此次测试中的整体正确率如下:

详细得分分布显示了模型间的性能差异:
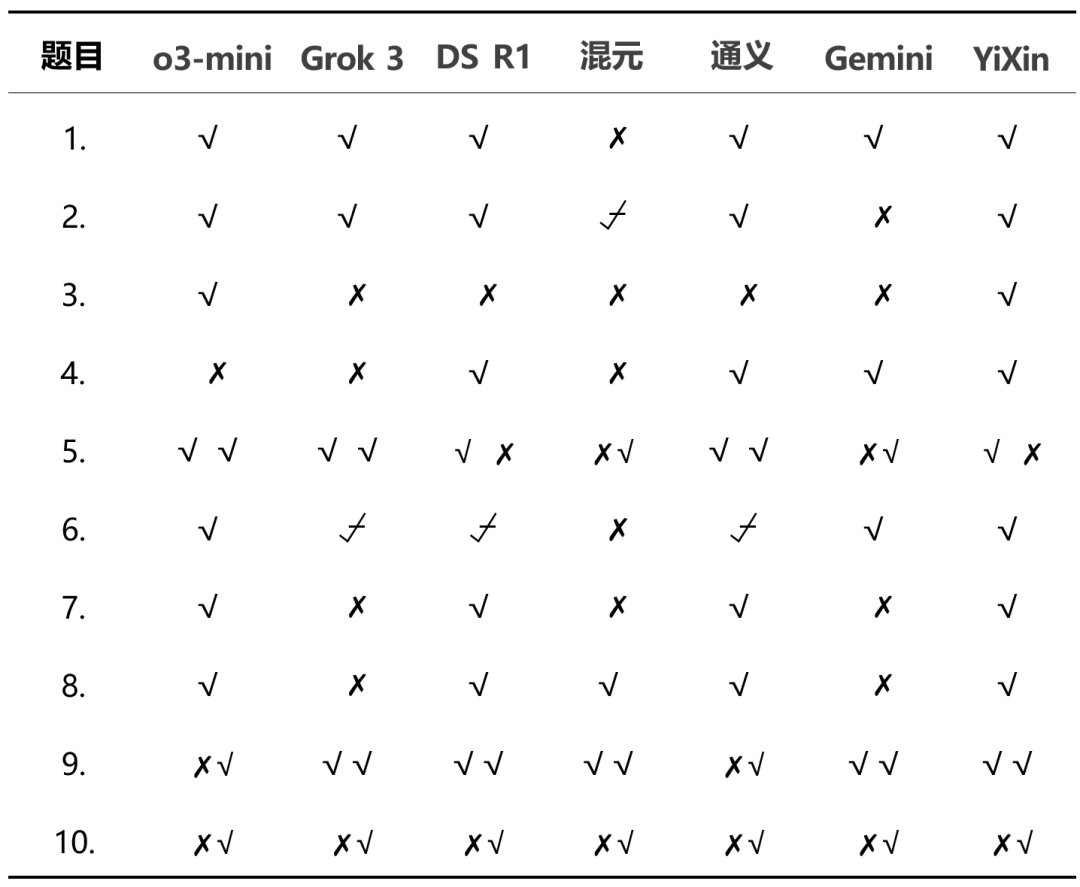
从总体结果看,o3-mini 和 YiXin-Distill-Qwen-72B 在本次测试中表现突出,展现了较强的数学问题解决能力。其他模型的表现则各有差异。
接下来将展示部分测试题目的具体解答情况。
实测详情
Round 1:找零问题
问题: 爷爷有 60 元钱,去超市买了 20 元蔬菜,收银员可能怎么给爷爷找零?
分析: 这是一道基础的算术应用题,考察模型对生活场景的理解和基本的货币计算能力。
结果:o3-mini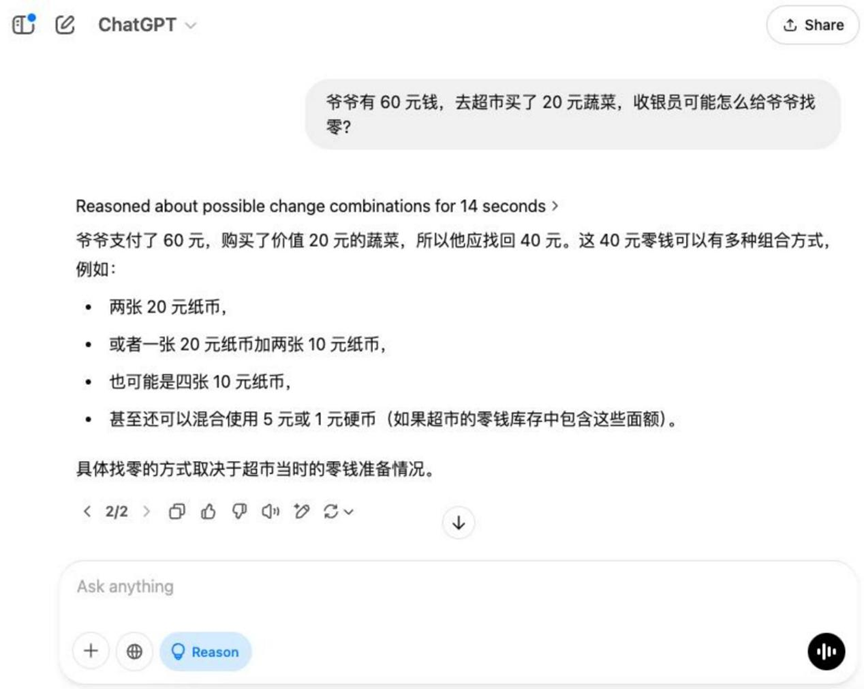
Grok 3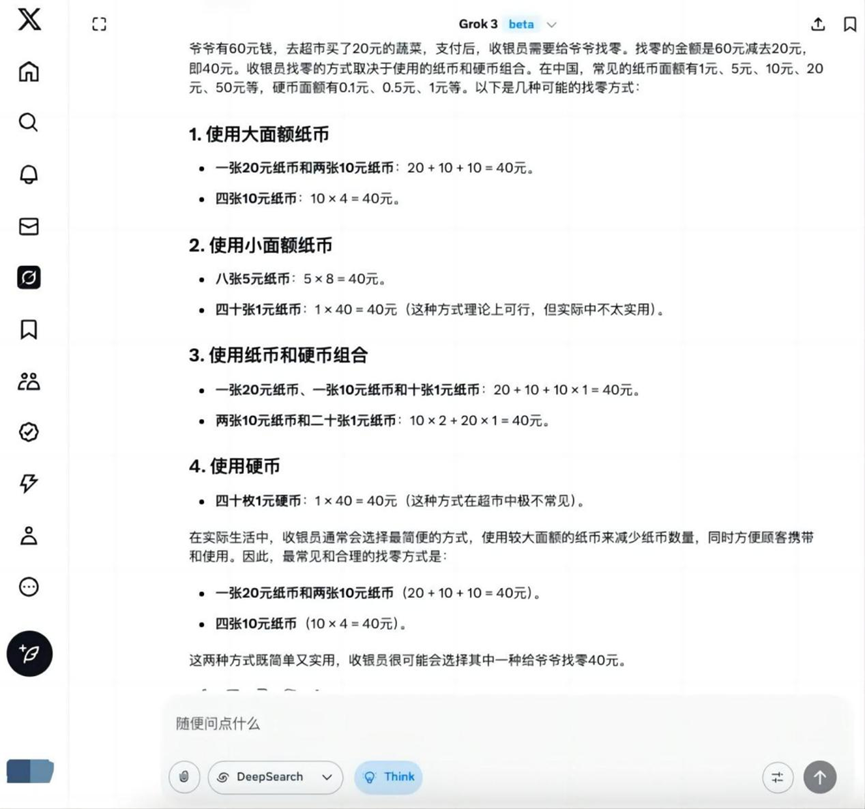
Hunyuan T1
Gemini 2.0 Flash Thinking
YiXin-Distill-Qwen-72B
在此基础题目上,除 Hunyuan T1 外,其余模型均能给出正确的找零方案。
Round 2:步行距离计算与方法判断
问题: 小明和小华每天走路去上学。小明每分钟走 48 米,小华每分钟走 55 米。小明家离学校 384 米。小华从家到学校所用的时间比小明多 4 分钟。小华家离学校有多远?下面哪种方法是错误的,说说你的理由。
方法 1: 55 × 4 = 220 (米), 384 + 220 = 604 (米)
方法 2: 384 / 48 = 8 (分), 55 × (8 + 4) = 660 (米)
分析: 此题结合了行程问题计算和逻辑判断,要求模型不仅能算出正确答案,还要能分析给定解题方法的正误,考察多步推理和逻辑辨析能力。
结果:DeepSeek R1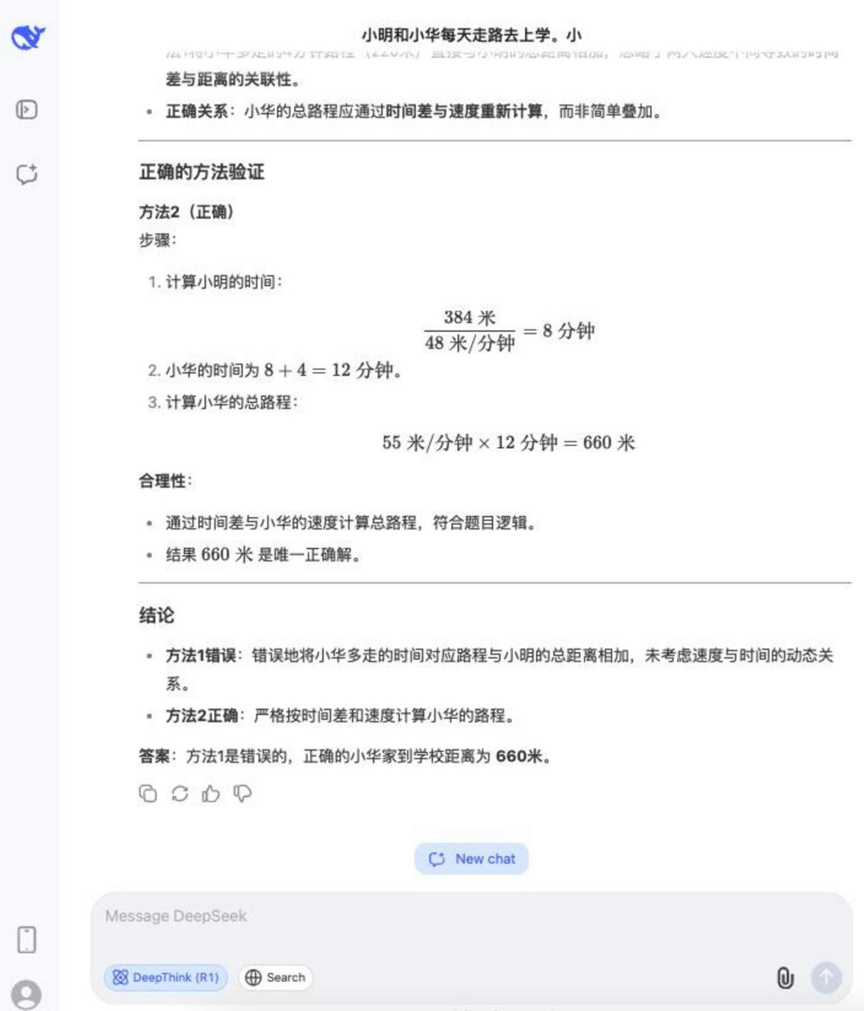
Tongyi Qwen-32B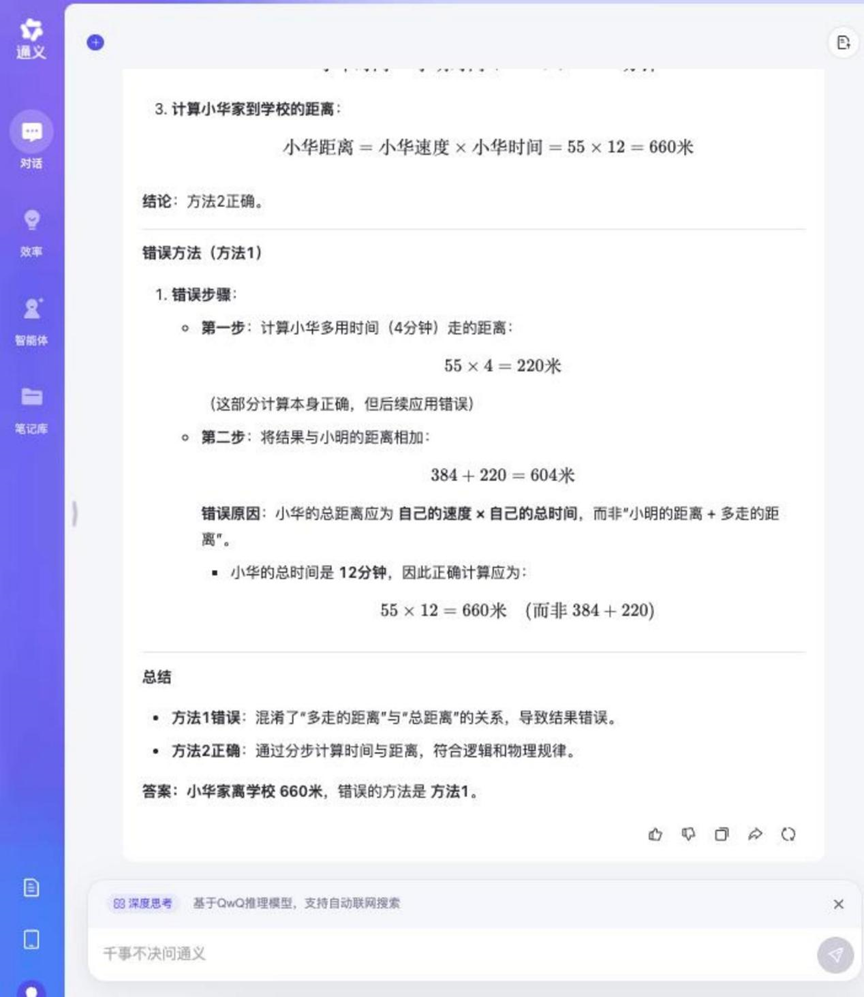
YiXin-Distill-Qwen-72B
这道题目的推理过程相对较长,但大多数参与测试的模型都能正确解答并判断出错误的方法。
Round 3:几何遮挡问题(看不见的塔)
问题: 在某市有6座塔,分别位于点A、B、C、D、E、F。几位同学组成一个旅游小组去该市自由行动。经过一段时间后,每位同学都发现,自己只能看到位于A、B、C、D处的4座塔,而看不到位于E和F处的塔。已知:同学们的位置和塔的位置均视为同一平面上的点,且这些点彼此不重合。A、B、C、D、E、F中任意3点不共线。看不到塔的唯一可能就是视线被其他塔所阻挡。例如,如果某位同学所在的位置P和A、B共线,且A在线段PB上,那么该同学就看不到位于B处的塔。请问:这个旅游小组最多可能有多少名同学? A. 3 B. 4 C. 6 D. 12
分析: 这是一道复杂的几何与逻辑推理题,涉及到可视性、遮挡和点集构型问题,对模型的空间想象和逻辑推理能力提出了较高要求。
结果:o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B
题目难度提升明显。在此轮测试中,仅 o3-mini 和 YiXin-Distill-Qwen-72B 成功解出,其他模型未能给出正确答案。
Round 4:概率问题(虎虎生威)
问题: 春节期间,某牛奶公司推出了一项新春盲盒活动:每盒牛奶附赠一个“红包”,其中包含“虎”“生”“威”三种图案之一。集齐两个“虎”、一个“生”和一个“威”即可拼成“虎虎生威”全家福。活动一经推出,便成为网红爆款,吸引了许多人参与。已知条件如下:红包上的图案是独立随机分布的,且无法从外表区分。“虎”“生”“威”三种图案出现的概率均为1/3。问:为了集齐一整套“虎虎生威”全家福,平均需要购买多少盒牛奶?
分析: 这是典型的收集者问题(Coupon collector's problem变种),需要运用概率论和期望值计算,考察模型处理概率模型和进行数学期望计算的能力。
结果:DeepSeek R1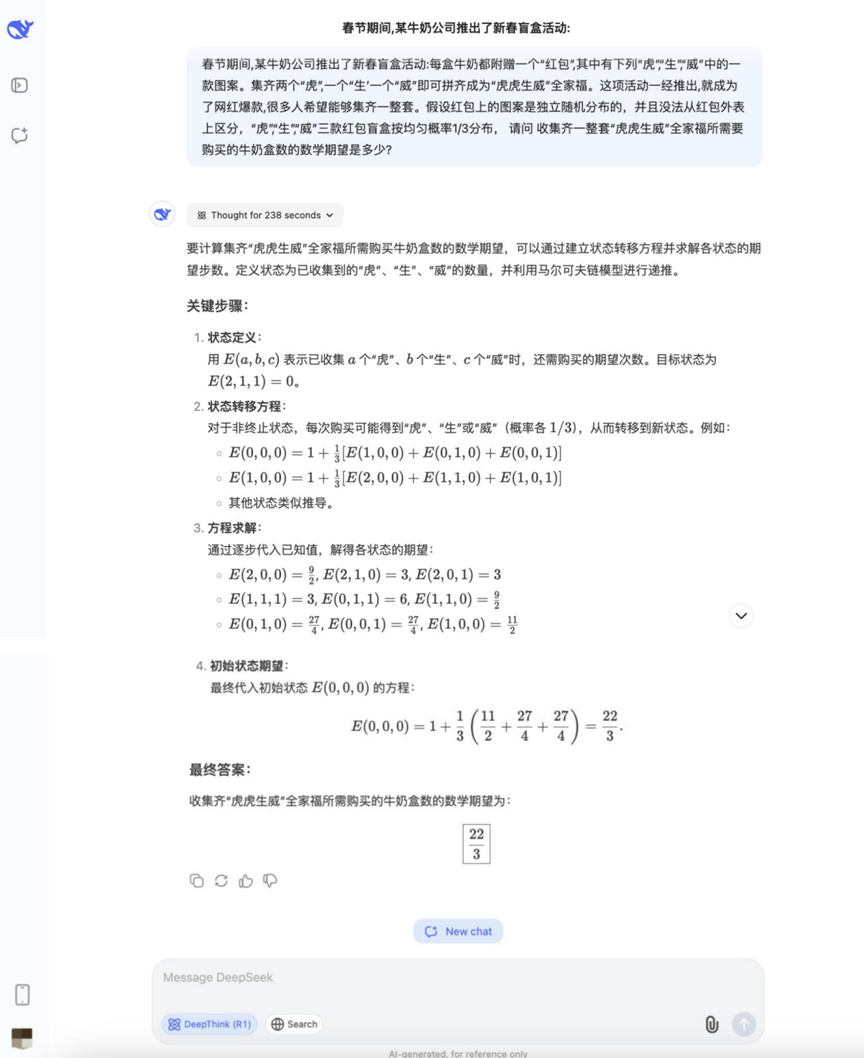
Hunyuan T1
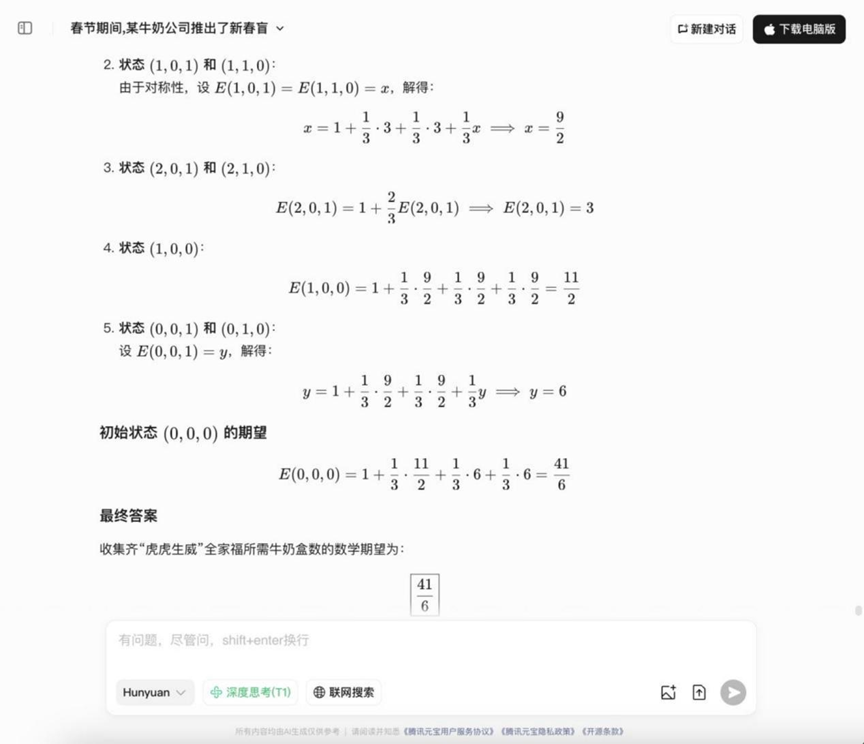
YiXin-Distill-Qwen-72B
此轮概率题目的解答情况开始分化,部分模型能够正确列出思路并计算。
Round 5:几何与路径规划(战机游戏)
问题描述图片:
分析: 这是一个结合了几何图形、坐标或网格系统以及最短路径/最优策略的问题,可能需要模型理解图示信息并进行空间推理和规划。
结果:o3-mini:成功解决
YiXin-Distill-Qwen-72B:部分正确

这轮测试对模型的综合能力要求更高,大约一半的测试模型能完全正确处理。
Round 6:数论证明题(寻找最小非因子)
问题描述图片:
分析: 进入证明题领域,这类题目要求模型具备严谨的逻辑演绎能力和对数论概念的深刻理解,是对模型抽象推理能力的直接考验。
结果:o3-mini
YiXin-Distill-Qwen-72B

在国产模型中,YiXin-Distill-Qwen-72B 在此轮证明题中表现较好。证明题对模型的挑战显著增大。
Round 7:函数与映射问题(单位圆上的映射)
问题描述图片:
分析: 此题涉及高等数学中的函数、映射以及单位圆等概念,考察模型对抽象数学定义的理解和应用能力。
结果:o3-mini
YiXin-Distill-Qwen-72B
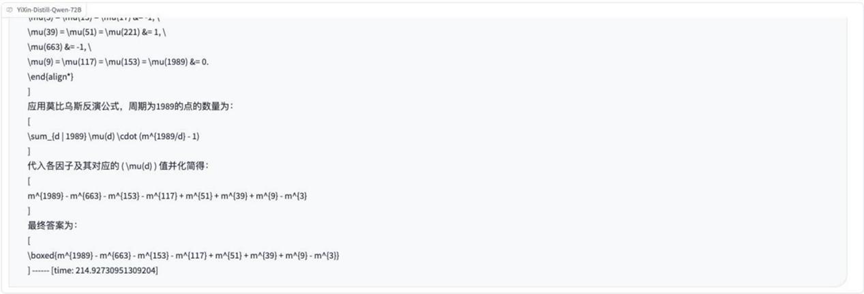
大约一半的模型能够正确处理这道涉及抽象映射的问题。
Round 8:组合优化问题(最大三角形)
问题: 空间中有 1989 个点,任意三点不共线。将这些点分成 30 组,每组点数各不相同。从任意三个不同的组中各取一点作为顶点,可以构成一个三角形。问:如何分配每组的点数,使得构成的三角形个数最大?
分析: 这是一个组合数学中的优化问题,需要模型理解组合计数原理,并找到最优的分配策略,涉及较复杂的数学建模和优化思想。
结果:o3-mini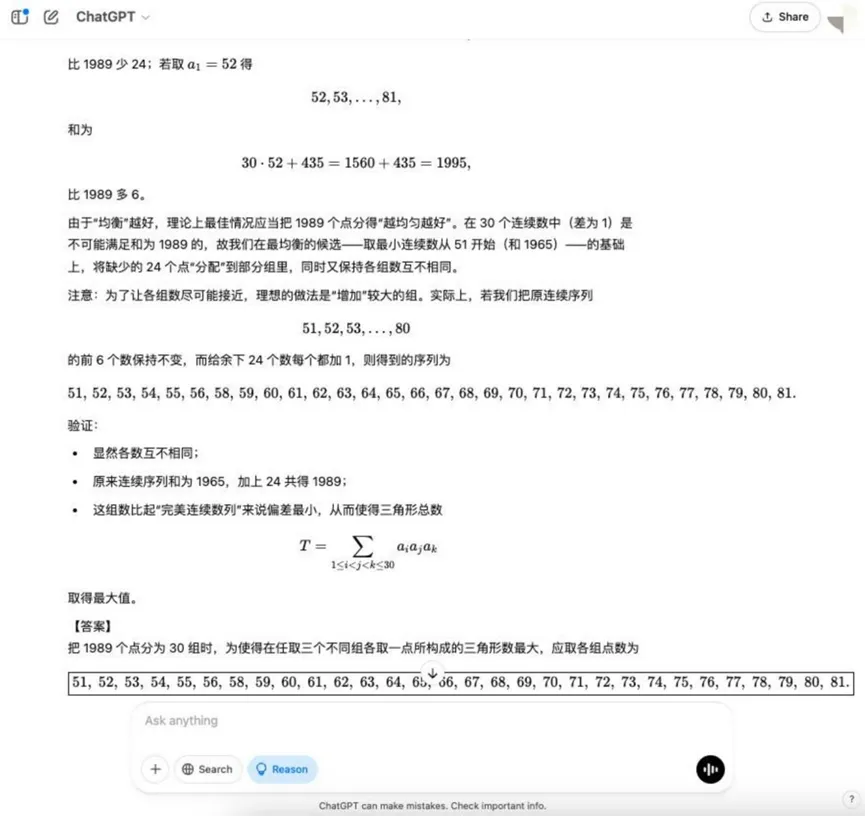
YiXin-Distill-Qwen-72B

组合优化问题进一步加大了难度,对模型的数学策略和计算能力提出更高要求。
Round 9:数论问题(因子链)
问题描述图片:
分析: 再次涉及数论概念,考察模型对因子、整除性等关系的理解和应用,可能需要构造性证明或计数。
结果:o3-mini:部分正确
YiXin-Distill-Qwen-72B:完全正确

YiXin-Distill-Qwen-72B 在此数论题上表现稳健。
Round 10:几何问题(等面积点)
问题描述图片:
分析: 最后一题是几何问题,涉及面积计算、点的轨迹或存在性证明,考验模型的几何直观、代数运算和逻辑推理能力。
结果:o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B

最终的几何题也显示出模型间处理复杂几何问题的能力差异。
观察与分析
基于本次对多款大型语言模型进行的中文数学能力测试,可以得到以下几点观察:
- 模型基础数学能力提升显著: 相较于早期模型,当前一代 LLM 在处理涉及多步骤推理的数学问题,如几何、概率以及一些开放式应用题时,表现出明显进步。这可能得益于模型规模的增大、训练数据的丰富以及类似“思维链”等推理增强技术的应用。
- 解题风格存在差异: 不同模型在解题过程的详略程度上表现不同。
o3-mini,Grok 3 beta,Tongyi Qwen-32B的输出相对简洁,推理步骤直接。DeepSeek R1,Hunyuan T1,YiXin-Distill-Qwen-72B则倾向于展示更详细的思考过程,有时包含反思和修正步骤,显得更为“啰嗦”,但这可能有助于追踪其推理逻辑。Gemini 2.0 Flash Thinking的解题过程不仅冗长,且主要使用英文输出,这表明其在中文数学语料上的训练可能相对不足。
- 对输入错误的鲁棒性: 测试中观察到,即使问题描述中存在轻微的符号错误或表述不规范,部分模型仍能正确理解题意并进行解答,显示出一定的鲁棒性。但这并不意味着模型总能忽略错误,关键信息的错误仍会导致解答失败。
- 未来提升方向:专业化与工具整合: 尽管进步明显,但当前 LLM 在处理复杂数学问题时的准确率仍有提升空间,尤其是在高难度竞赛题和需要严格证明的场景下。未来的提升路径可能包括:
- 集成外部计算引擎: 通过调用如 Wolfram Alpha 等符号计算工具,弥补 LLM 在精确计算和符号运算方面的短板。
- 领域专属微调: 针对数理逻辑、特定数学分支(如代数、几何、概率论)构建高质量的微调数据集,强化模型的专业推理能力和知识深度。
- 交互式学习与修正: 发展允许用户在解题过程中进行引导、指出错误步骤并让模型动态调整解题策略的机制。
- 对使用者的建议:
- 学生: 可以利用 LLM 辅助学习,快速验证基础题目的解法和答案。但对于复杂或需要创造性思维的问题,需警惕模型可能出现的“一本正经的胡说八道”(即自信地给出错误答案)。
- 教育工作者: 在利用 AI 辅助教学时,需要设计更能考察学生深层理解和独立思考能力的题目,避免学生仅依赖模型得出表面答案。
- 开发者: 在应用 LLM 解决数学问题时,应通过优化提示词(Prompt Engineering)来明确问题边界和解题要求,减少模型因模糊理解而进行的无效推理或“脑补”。
总而言之,大型语言模型在数学领域的应用正从探索阶段逐步走向实用化。未来模型的发展方向将是在模拟人类思维的灵活性与保证数学逻辑的严谨性之间寻求更优的平衡点。
附注:
本次评测中表现较好的 YiXin-Distill-Qwen-72B 模型信息如下:
- 标准版: https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B
- AWQ 量化版: https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B-AWQ
- 本地部署资源需求:72B 标准版约需 8 张 NVIDIA 4090 级别显卡;AWQ 量化版可在 2 张同级别显卡上运行。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...