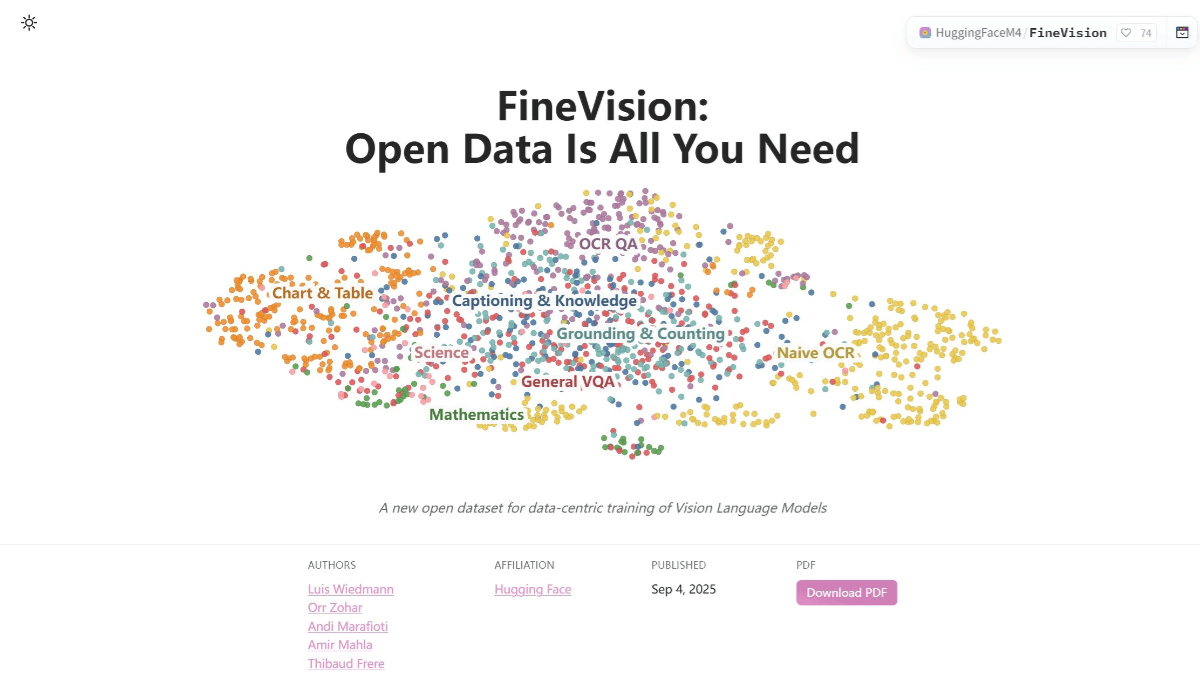

综合介绍
TangoFlux 是一个由 DeCLaRe Lab 开发的高效文本到音频(TTA)生成模型。该模型能够在短短 3.7 秒内生成长达 30 秒的 44.1kHz 立体声音频。TangoFlux 采用流匹配和 Clap-Ranked Preference Optimization(CRPO)技术,通过生成和优化偏好数据来增强 TTA 对齐。该模型在客观和主观基准测试中均表现出色,并且所有代码和模型均已开源,支持进一步的 TTA 生成研究。

体验地址:https://huggingface.co/spaces/declare-lab/TangoFlux
新加坡科技设计大学(SUTD)和NVIDIA联合发布了一种高效的文本到音频生成模型 (TTA)——TangoFlux 。该模型拥有约5.15亿个参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频。TangoFlux不仅具有超快的生成速度,同时在音频质量上也好于Stable Audio等开源音频模型。
将TANGoFLux与其他最先进的开源文本到音频生成模型进行比较:TANGoFLux不仅生成速度比最快的模型快大约2倍,而且实现了更好的音频质量(通过CLAP和FD分数衡量),所有这些还具有更少的可训练参数。

TangoFlux 论文名为“通过流匹配和 Clap-Ranked 偏好优化实现超快速、忠实的文本到音频生成”,其由 FluxTransformer 块组成,这些块是扩散变换器 (DiT) 和多模态扩散变换器 (MMDiT),它们以文本提示和持续时间嵌入为条件,以生成最长 30 秒的 44.1kHz 音频。TangoFlux 学习由变分自动编码器 (VAE) 编码的音频潜在表示的整流流轨迹。TangoFlux 训练管道包括三个阶段:预训练、微调和使用 CRPO 进行偏好优化。具体来说,CRPO 会迭代生成新的合成数据,并使用 DPO 损失构建偏好对以进行偏好优化,从而实现流匹配。

功能列表
- 快速音频生成:在 3.7 秒内生成长达 30 秒的高质量音频。
- 流匹配技术:使用 FluxTransformer 和 Multimodal Diffusion Transformers 进行音频生成。
- CRPO 优化:通过生成和优化偏好数据来提高音频生成质量。
- 多阶段训练:包括预训练、微调和偏好优化三个阶段。
- 开源代码:所有代码和模型均已开源,支持进一步研究。
使用帮助
安装流程
- 环境配置:确保已安装 Python 3.7 及以上版本,并安装必要的依赖库。
- 克隆仓库:在终端中运行
git clone https://github.com/declare-lab/TangoFlux.git克隆仓库。 - 安装依赖:进入项目目录,运行
pip install -r requirements.txt安装所有依赖。
使用流程
- 模型训练:
- 配置加速器:运行
accelerate config并根据提示配置运行环境。 - 配置训练文件路径:在
configs/tangoflux_config.yaml中指定训练文件路径和模型超参数。 - 运行训练脚本:使用以下命令启动训练:
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' src/train.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml'- DPO 训练:修改训练文件以包含 "chosen", "reject", "caption" 和 "duration" 字段,并运行以下命令:
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' src/train_dpo.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml' - 配置加速器:运行
- 模型推理:
- 下载模型:确保已下载 TangoFlux 模型。
- 生成音频:使用以下代码从文本提示生成音频:
import torchaudio from tangoflux import TangoFluxInference from IPython.display import Audio model = TangoFluxInference(name='declare-lab/TangoFlux') audio = model.generate("生成音频的文本提示", duration=10) Audio(audio, rate=44100)
详细功能操作
- 文本到音频生成:输入文本提示,设置生成音频的持续时间(1 到 30 秒),模型将生成相应的高质量音频。
- 偏好优化:通过 CRPO 技术,模型能够生成更符合用户偏好的音频。
- 多阶段训练:包括预训练、微调和偏好优化三个阶段,确保模型生成的音频质量和一致性。
注意事项
- 硬件要求:建议使用具有较高计算能力的 GPU(如 A40)以获得最佳性能。
- 数据准备:确保训练数据的多样性和质量,以提高模型的生成效果。
通过以上步骤,用户可以快速上手使用 TangoFlux 进行高质量的文本到音频转换。详细的安装和使用说明确保用户能够顺利完成模型的训练和推理过程。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...