

《DeepSeek-R1 在第三方平台的稳定性评测报告》
人工智能领域的快速发展,催生了诸多卓越的推理模型。DeepSeek-R1 以其杰出的性能和处理复杂任务的能力,迅速成为业界瞩目的焦点。然而,随着用户数量的激增以及外部网络攻击的增加,DeepSeek-R1 的稳定性问题也逐渐暴露出来。为了应对这一挑战,多家第三方平台纷纷推出针对 DeepSeek-R1 模型的优化服务,力求为用户提供更加稳定和高效的使用体验。
为了帮助用户全面了解不同平台的服务质量,并根据自身需求做出明智的选择,本机构对多家支持 DeepSeek-R1 的第三方平台进行了稳定性测评。本次测评选取了 12 个具有代表性的第三方平台,并设计了 20 道原创小学奥数推理题,以考察 DeepSeek-R1 模型在各平台上的实际表现。测评维度涵盖了回复率、推理耗时以及准确率等关键指标。本报告旨在呈现网页端平台的首次测评结果,反映各平台在发布时点的稳定性水平。未来,本机构还将持续跟进,对包括网页端、API、APP 乃至本地部署版本在内的各类平台进行更全面的测评。
DeepSeek-R1 稳定性测评体验摘要
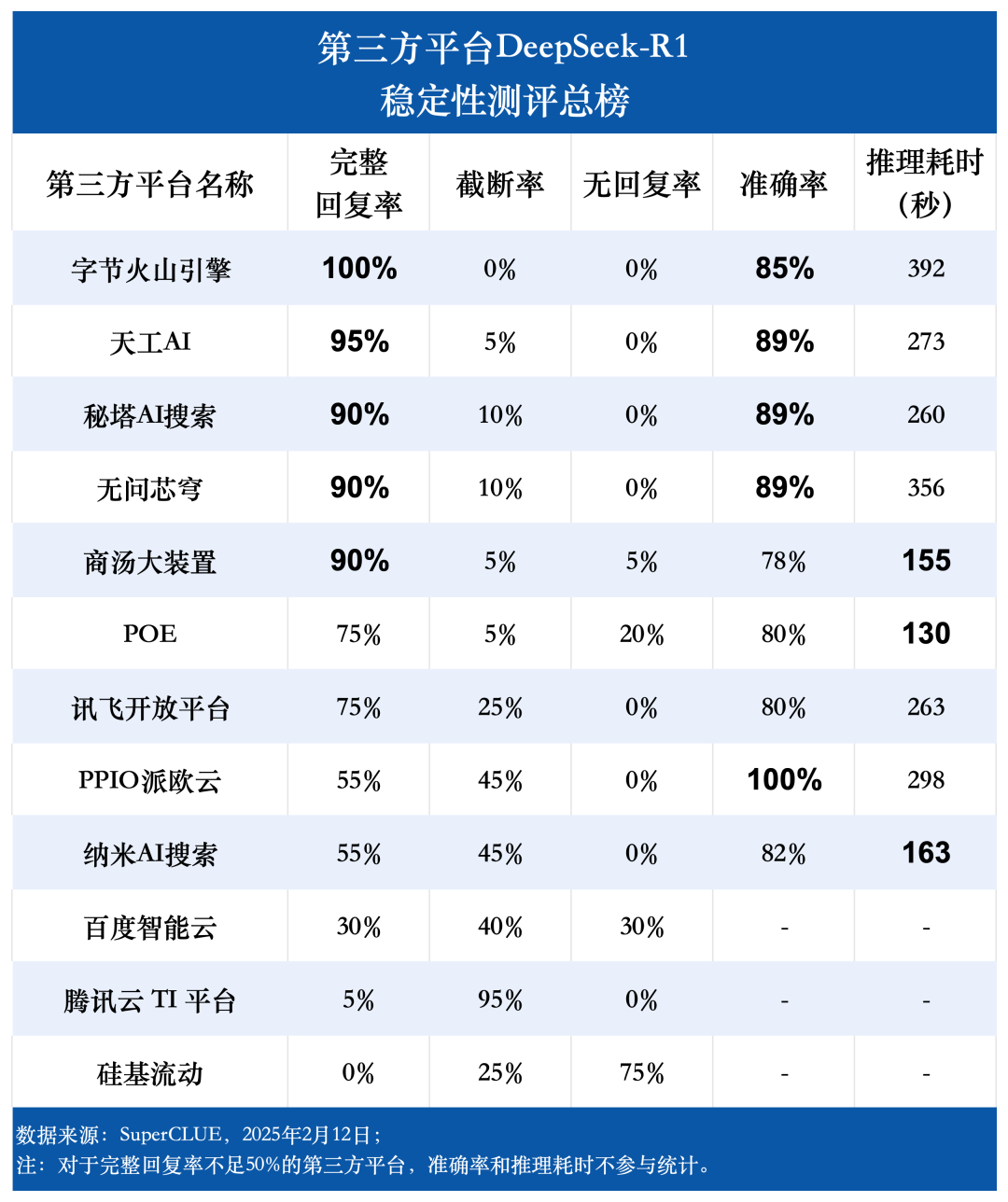
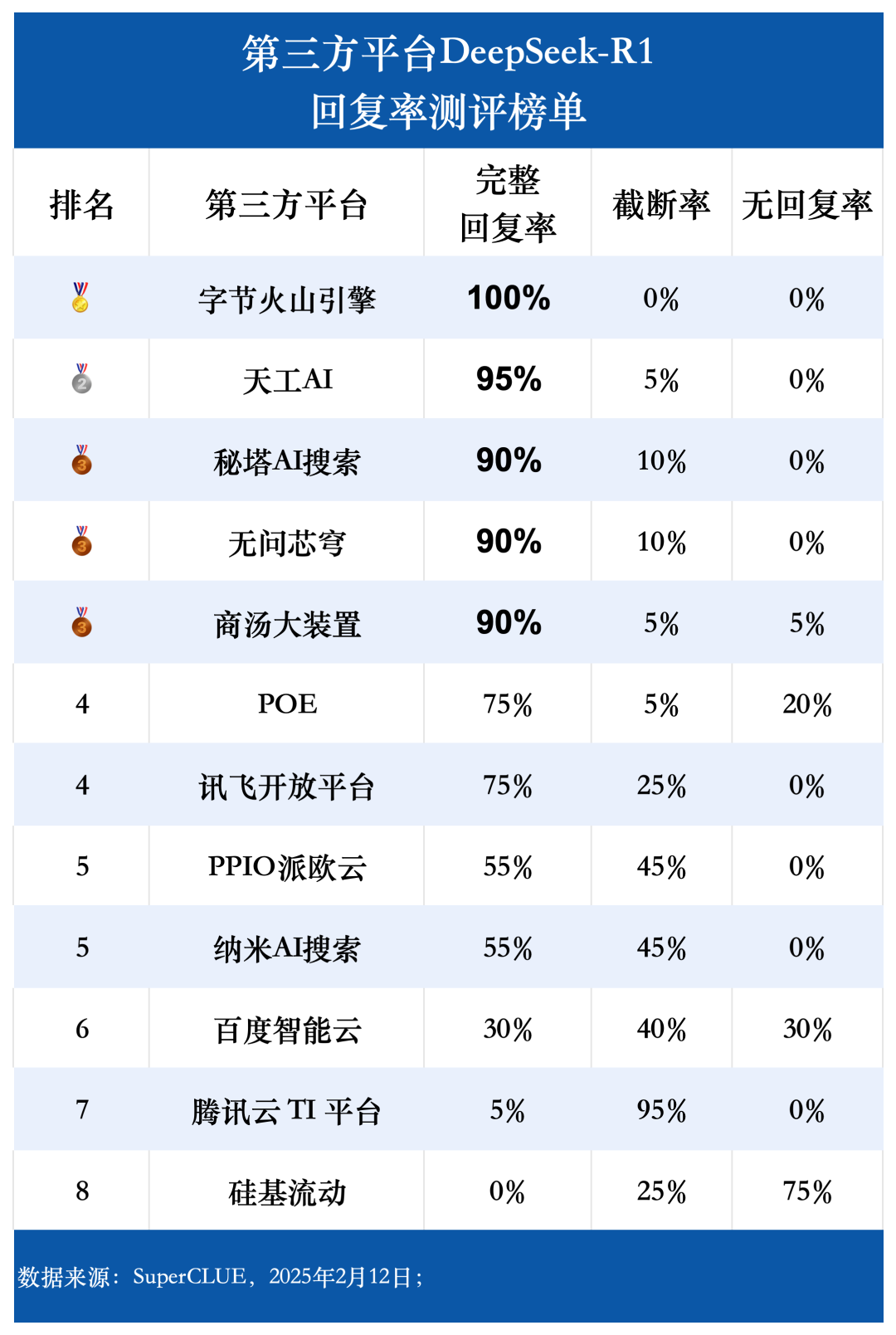
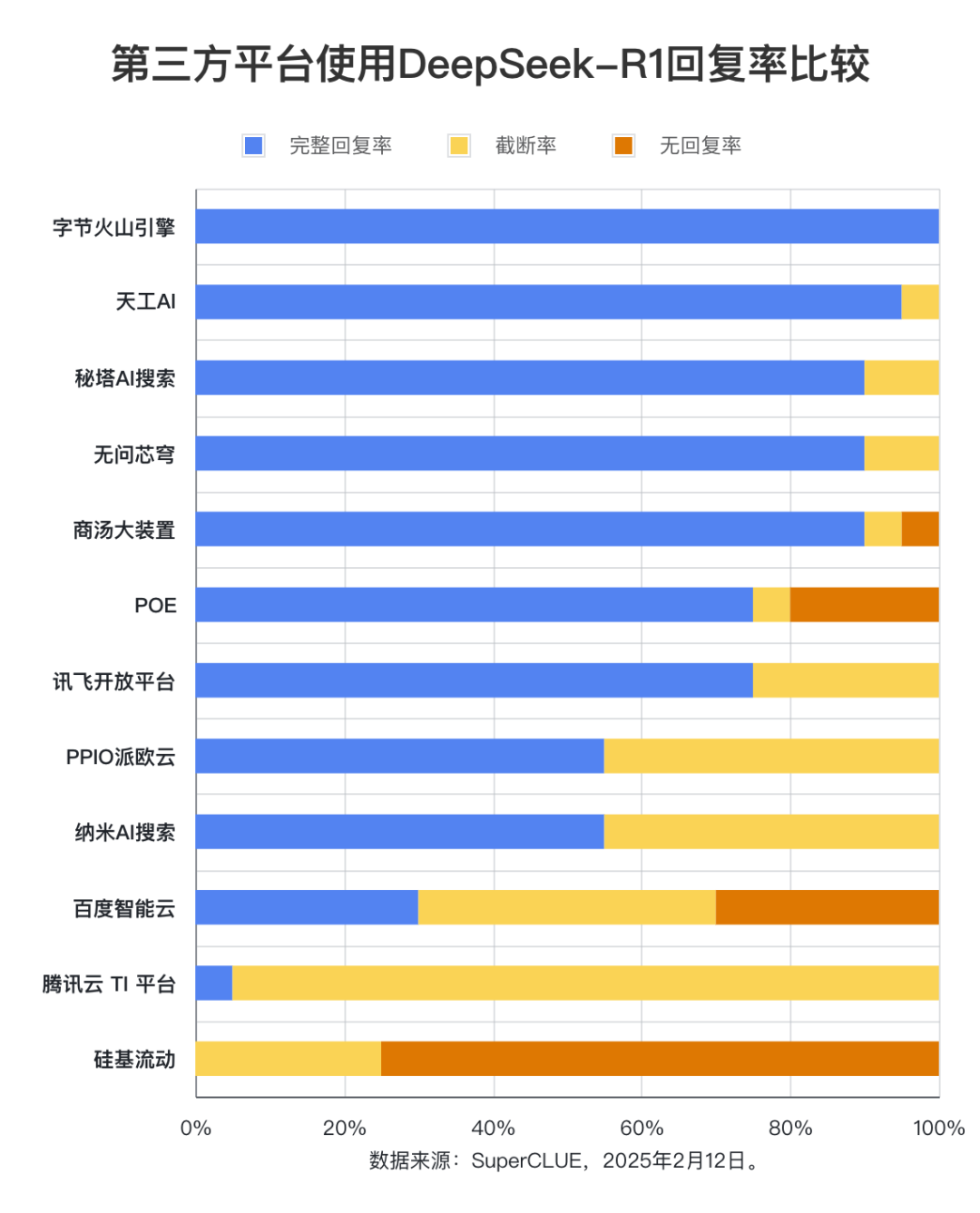
测评要点 1:第三方平台 DeepSeek-R1 完整回复率差异显著。
测评结果显示,字节火山引擎(100%)、天工 AI(95%)、秘塔 AI 搜索、无问芯穹以及商汤大装置(均为 90%)在完整回复率方面表现突出,展现了卓越的稳定性。相比之下,百度智能云、腾讯云 TI 平台以及硅基流动的完整回复率均低于 50%,表明其稳定性有待提升。这一发现强调了平台稳定性在用户选择过程中的重要性。
测评要点 2:各平台 DeepSeek-R1 模型推理耗时存在明显差异,最长耗时平台与最短耗时平台相差近三倍。
在推理耗时方面,POE 平台表现最优,平均每题耗时仅为 130 秒。商汤大装置和纳米 AI 搜索紧随其后,平均每题耗时分别为 155 秒和 163 秒。而字节火山引擎的平均每题推理耗时最长,达到 392 秒。
测评要点 3:各平台 DeepSeek-R1 模型准确率整体较高,体现模型本身强大而可靠的性能。
测评数据显示,除完整回复率低于 50% 的平台外,其余九大平台的平均准确率高达 85.76%,最高准确率甚至达到了 100%,最低准确率也保持在 78%。这充分证明了 DeepSeek-R1 模型本身具备出色的性能和可靠性,能够为各类第三方应用提供稳定的高准确率支持。
榜单概览
完整回复率 + 截断率 + 无回复率 = 100%
- 完整回复率:模型给出完整回复,不存在截断或无响应等问题,但不考虑答案是否正确。计算方式为完整回复题目数除以总题目数。
- 截断率:模型在回复过程中出现中断,未能给出完整答案。计算方式为截断题目数除以总题目数。
- 无回复率:模型因特殊原因(如无响应/请求出错)未能给出答案。计算方式为无回复题目数除以总题目数。
- 准确率:对于模型完整回复的题目,答案与标准答案一致的比例。仅评估最终答案的正确性,不考察解题过程。
- 推理耗时(秒/题):对于模型完整回复的题目,模型推理每题答案所用的平均时间。
测评方法
1. 对每个第三方平台,均使用 20 道小学奥数题进行统一测试,以确保测评的公平性和可比性。2. 考虑到推理题的输出内容通常较长,对于支持调整最大输出 token 数(max_tokens)的平台,均将此参数设置为最大值,其余参数保持平台默认设置。3. 推理耗时统计方法:对于平台自带推理计时功能的,采用平台提供的统计结果;对于不具备此功能的平台,则采用人工计时方式。
测评结果
(1)完整回复率
测评数据显示,字节火山引擎、天工 AI、秘塔 AI 搜索、无问芯穹和商汤大装置的完整回复率均达到 90% 以上。其中,字节火山引擎表现最为出色,完整回复率高达 100%。相比之下,百度智能云、腾讯云 TI 平台和硅基流动的完整回复率则明显偏低,均不足 50%。在截断率方面,腾讯云 TI 平台高达 95%。硅基流动在测试中出现无响应或请求出错的情况最为频繁,无回复率达到 75%。
(2)准确率
准确率的统计范围限定在模型给出完整回复的题目中,反映了模型回答正确的题目比例。测评结果显示,九个第三方平台使用 DeepSeek-R1 模型的平均准确率达到了 85.76%,这进一步印证了 DeepSeek-R1 模型本身的高质量和可靠性,能够为各类应用场景提供稳定且准确的支持。
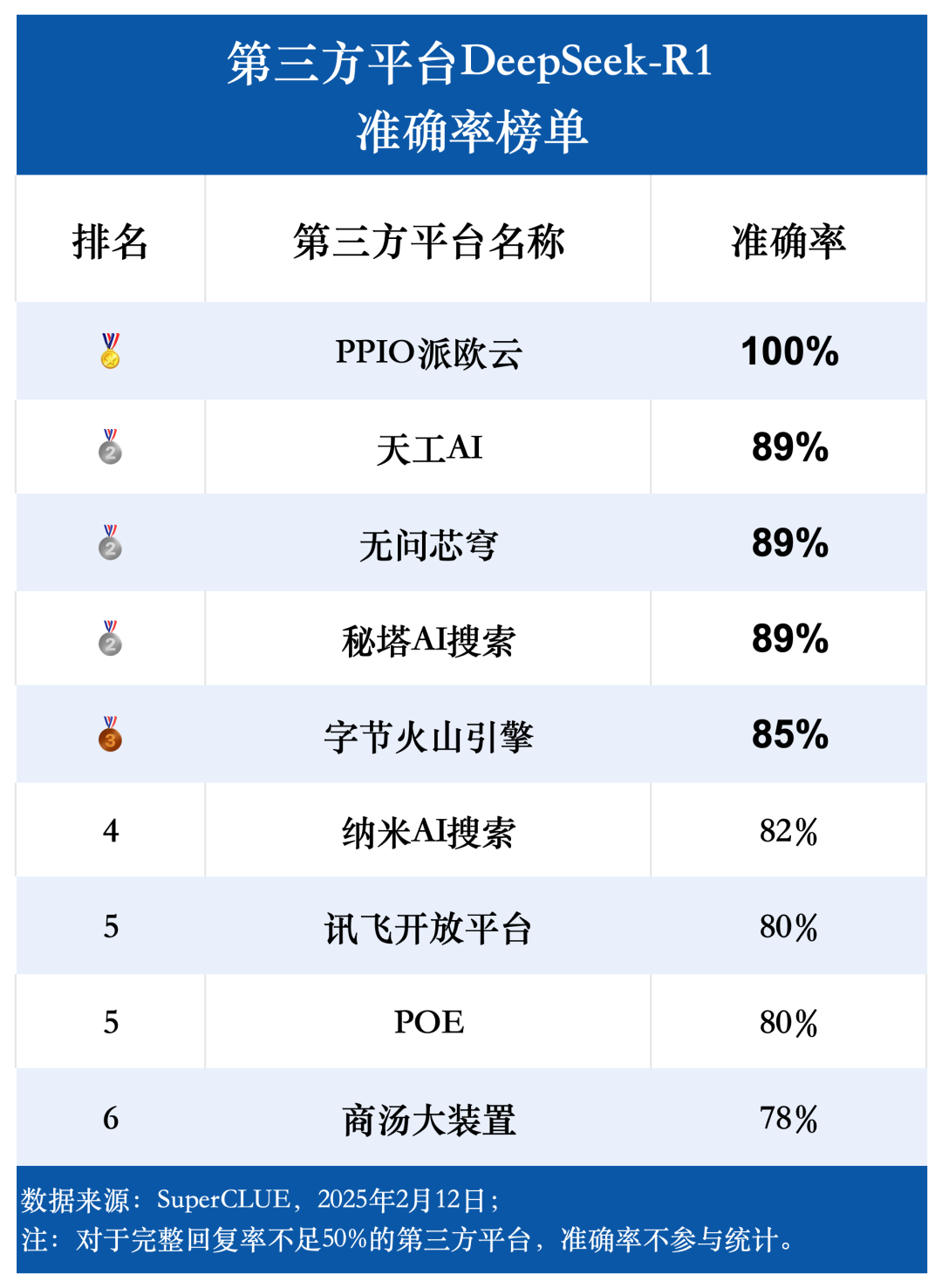
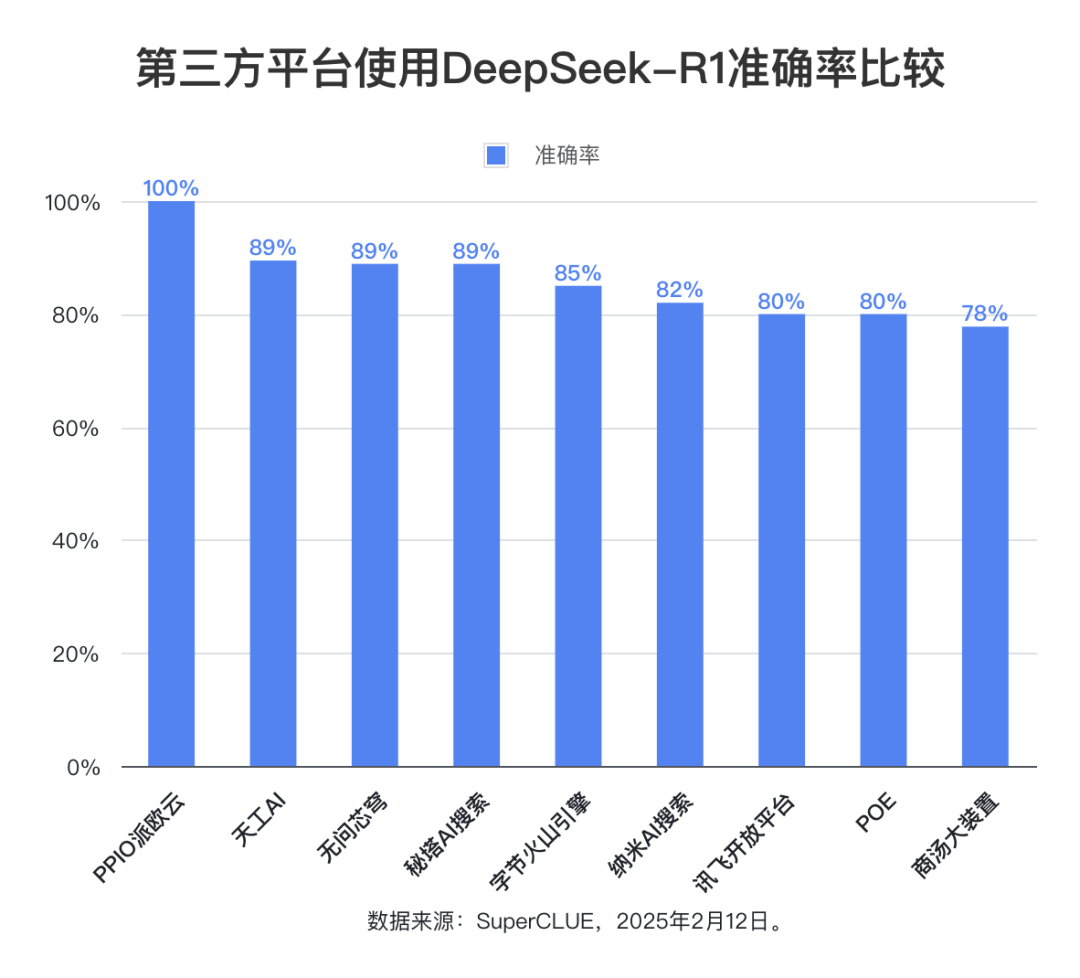
(3)推理耗时
在平均每题推理耗时方面,POE 平台表现最佳,仅为 130 秒。商汤大装置和纳米 AI 搜索的推理耗时也相对较短,均在 200 秒以内。无问芯穹和字节火山引擎的推理耗时则相对较长,均超过 350 秒。其他平台的推理耗时则介于 250-300 秒之间。

示例展示
题目: 一只青蛙早上 6 点从深为 10 米的井底向上爬,它每向上爬 2 米,因为井壁打滑,就会下滑 0.5 米。下滑 0.5 米的时间是向上爬 2 米所用时间的二分之一。6 点 12 分时,青蛙爬至离井口 2.5 米处,那么青蛙从井底爬到井口时所花的时间总共多少分钟?
标准答案:15.2 分钟(即 15 分钟 12 秒)
参考答案(来自模型:Gemini-2.0-Flash-Exp):

原因分析
1. 模型最大输出长度限制是导致回复中断的重要因素之一。统计数据显示,部分平台未能提供对 max_tokens 参数的灵活调整(如百度智能云、腾讯云 TI 平台等)。这使得模型在生成较长回复时更容易出现截断现象。数据显示,不可设置 max_tokens 参数的平台平均截断率为 39%,而可设置该参数的平台截断率则为 16.43%。特别是在本次测评中,小学奥数题的复杂性以及解题步骤的繁琐性,导致模型需要生成的内容长度显著增加,token 限制问题也因此被进一步放大,加剧了输出截断的发生。

2. 平台用户负载也是影响模型服务稳定性的潜在因素。
考虑到不同平台的用户量级存在差异,用户数量较多的平台可能因服务器负载过重而面临更高的不稳定性风险。平台服务稳定性的不足,可能会间接影响模型生成回复的完整性和推理速度。
结论与建议
1. 不同第三方平台在部署和运行 DeepSeek-R1 模型时,稳定性表现存在显著差异。建议用户在选择平台时,综合评估 各平台的技术架构、资源调度能力以及用户负载情况,并结合自身需求(如回复率、推理耗时等指标)进行权衡。对于追求更高稳定性的用户,可以优先考虑用户量相对较少,但资源分配更为均衡的平台,以降低因高并发导致的性能波动风险。
2. 测评数据表明,字节火山引擎、天工 AI、秘塔 AI 搜索、无问芯穹以及商汤大装置等平台的完整回复率均达到 90% 及以上,表明这些平台在保障模型输出完整性和可靠性方面表现出色。对于需要确保高回复率的应用场景,建议优先选择上述平台作为技术支持。
3. 在推理耗时方面,POE 平台和商汤大装置 展现出明显的优势,其低延迟特性使其更适合对实时性要求较高的应用场景。建议用户在选择平台时,根据具体的业务需求,对推理耗时的敏感程度进行优先级排序,以便在性能与成本之间取得最佳平衡。
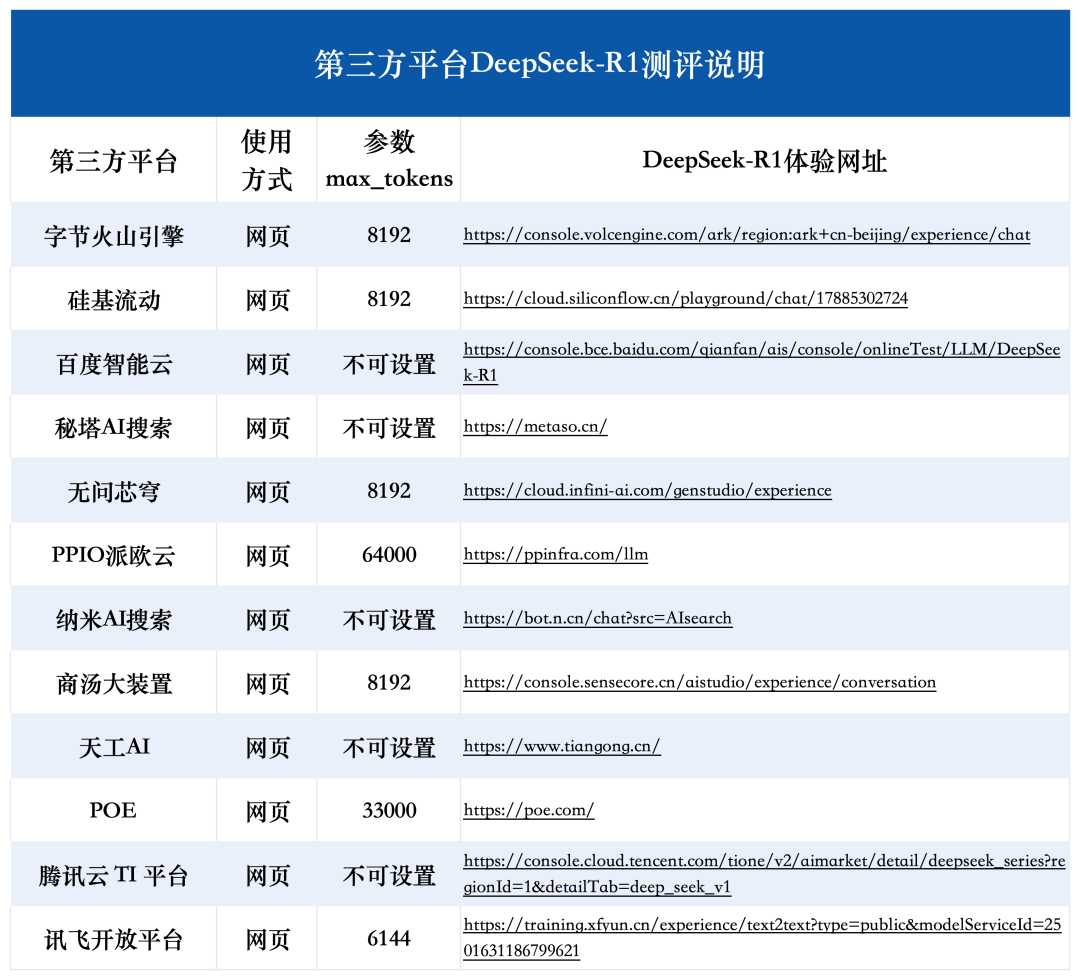
附各平台 DeepSeek-R1 体验网址:
字节火山引擎:https://console.volcengine.com/ark/region:ark+cn-beijing/experience/chat
硅基流动: https://cloud.siliconflow.cn/playground/chat/17885302724
百度智能云: https://console.bce.baidu.com/qianfan/ais/console/onlineTest/LLM/DeepSeek-R1
秘塔AI搜索: https://metaso.cn/
无问芯穹: https://cloud.infini-ai.com/genstudio/experience
PPIO派欧云:https://ppinfra.com/llm
纳米AI搜索: https://bot.n.cn/chat?src=AIsearch
商汤大装置: https://console.sensecore.cn/aistudio/experience/conversation
天工AI: https://www.tiangong.cn/
POE:https://poe.com/
腾讯云 TI 平台: https://console.cloud.tencent.com/tione/v2/aimarket/detail/deepseek_series?regionId=1&detailTab=deep_seek_v1
讯飞开放平台:https://training.xfyun.cn/experience/text2text?type=public&modelServiceId=2501631186799621
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...