

综合介绍
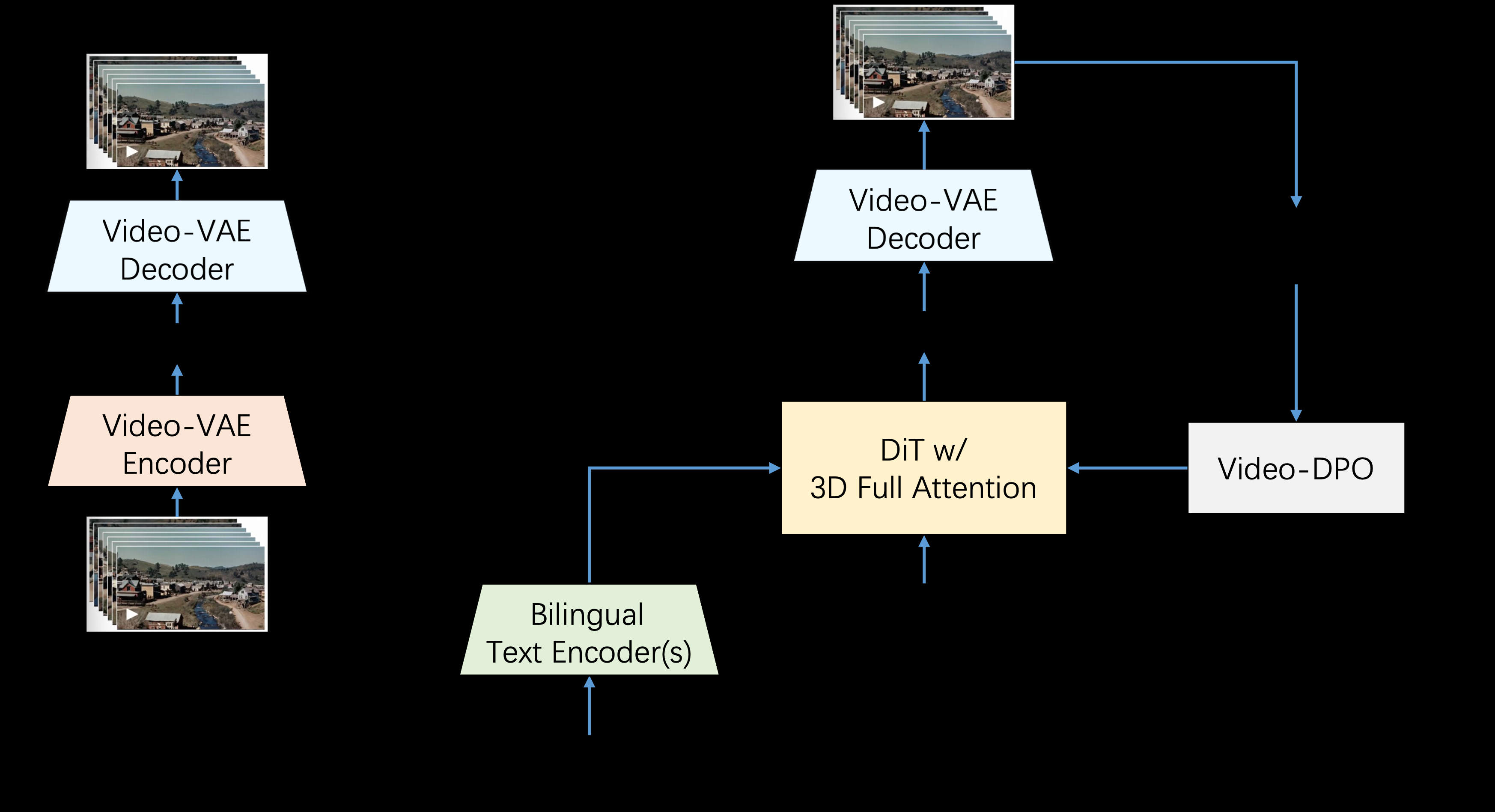
Step-Video-T2V是由StepFun AI(阶跃星辰)推出的一款先进的文本到视频转换模型。该模型拥有30亿参数,能够生成长达204帧的视频。通过深度压缩变分自编码器(VAE),模型实现了16x16的空间压缩和8x的时间压缩,从而提高了训练和推理的效率。Step-Video-T2V在视频生成领域表现出色,尤其在视频运动和效率方面。然而,对于处理复杂动作仍存在一定的挑战。该模型是开源的,使用者可以在GitHub上获取和贡献代码。
功能列表
- 生成高质量视频:利用30亿参数生成长达204帧的视频。
- 深度压缩技术:采用深度压缩变分自编码器,实现16x16空间压缩和8x时间压缩。
- 双语支持:支持英文和中文的文本提示。
- 开源和社区支持:模型和基准数据集开源,促进创新并赋能创作者。
使用帮助
安装流程
- 克隆GitHub仓库:
git clone https://github.com/stepfun-ai/Step-Video-T2V.git - 进入项目目录:
cd Step-Video-T2V - 创建并激活虚拟环境:
conda create -n stepvideo python=3.10 conda activate stepvideo - 安装依赖:
pip install -e . pip install flash-attn --no-build-isolation ## flash-attn是可选的
使用指南
生成视频
- 准备文本提示,保存在一个文件中,例如
prompt.txt:飞机在蓝天中飞翔 - 运行视频生成脚本:
python generate_video.py --input prompt.txt --output video.mp4
详细功能操作流程
- 生成高质量视频:
- 文本输入:用户输入描述视频内容的文本。
- 模型处理:Step-Video-T2V模型解析文本并生成视频。
- 视频输出:生成的视频保存为MP4格式,用户可以随时观看和分享。
- 深度压缩技术:
- 空间压缩:通过16x16的空间压缩技术,提高视频生成效率。
- 时间压缩:通过8x的时间压缩技术,进一步优化视频生成速度和质量。
- 双语支持:
- 英文支持:用户可以输入英文文本,模型自动解析并生成对应视频。
- 中文支持:用户可以输入中文文本,模型同样能生成相应视频,支持多语言用户需求。
- 开源和社区支持:
- 开源代码:用户可以在GitHub上获取模型的全部代码,自行部署和修改。
- 社区贡献:用户可以提交代码贡献,参与模型的改进和优化。
单GPU推理和量化
Step-Video-T2V项目支持单GPU推理和量化,显著减少所需的显存。请参考相关示例获取详细信息。
最佳实践推理设置
Step-Video-T2V在推理设置中表现出色,能够一致性地生成高保真和动态视频。但是,我们的实验表明,推理超参数的变化会影响生成质量。
| Models | infer_steps | cfg_scale | time_shift | num_frames |
|---|---|---|---|---|
| Step-Video-T2V | 30-50 | 9.0 | 13.0 | 204 |
| Step-Video-T2V-Turbo (Inference Step Distillation) | 10-15 | 5.0 | 17.0 | 204 |
模型下载
| 模型 | 🤗 Huggingface | 🤖 Modelscope |
|---|---|---|
| Step-Video-T2V | 下载 | 下载 |
| Step-Video-T2V-Turbo (Inference Step Distillation) | 下载 | 下载 |
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...