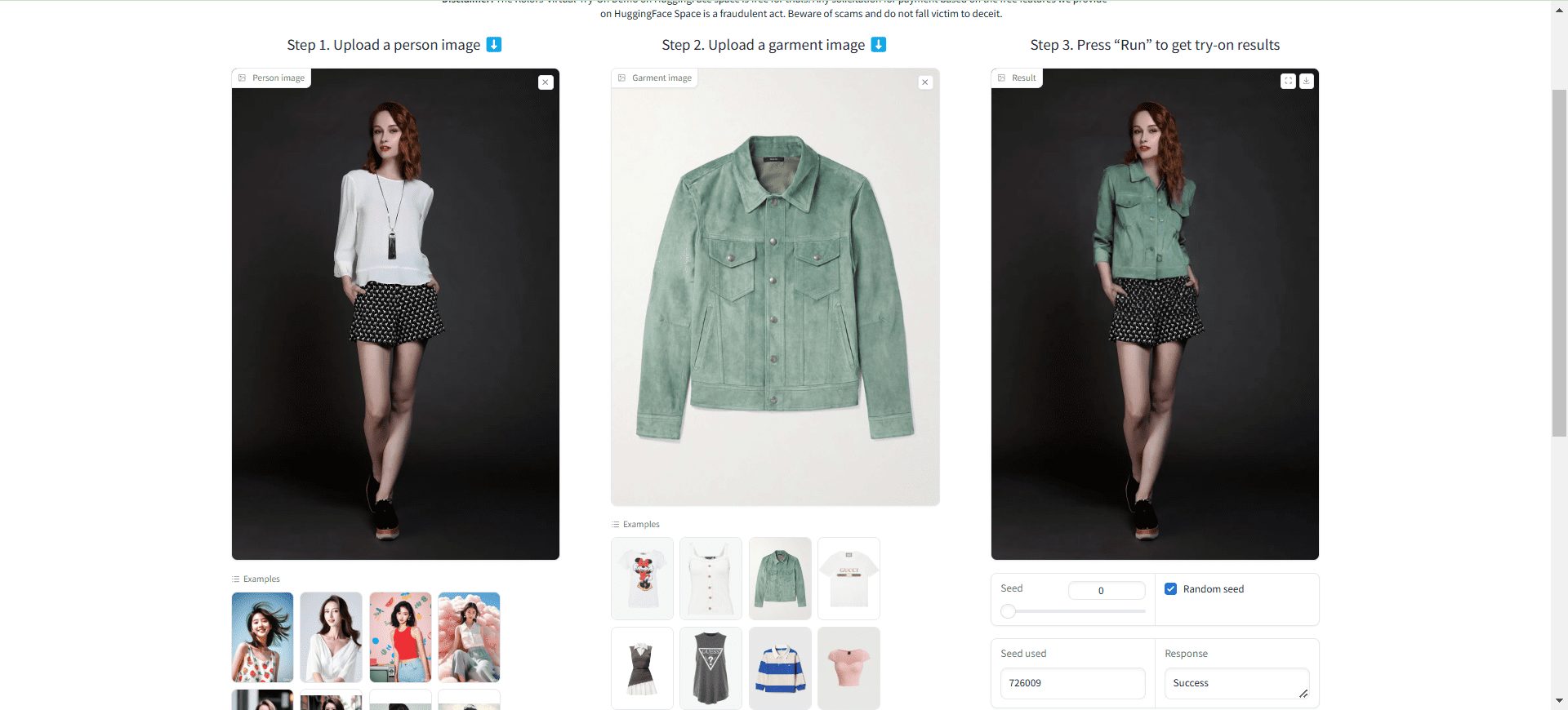

综合介绍
Spark-TTS 是由 SparkAudio 团队开发的一款开源文本转语音(Text-to-Speech, TTS)工具,托管在 GitHub 上,旨在帮助用户将文本高效转换为自然流畅的语音。它基于先进的深度学习技术,支持多种语言和声音风格,适合开发者、研究人员或内容创作者使用。项目强调易用性和高质量语音输出,提供了预训练模型和自定义训练选项,用户可以根据需求调整语音特性。虽然目前没有详细的官方文档,但通过 GitHub 仓库的代码和社区支持,用户可以快速上手并探索其功能。Spark-TTS 的开源性质使其成为语音合成领域的实用资源,尤其适合需要个性化语音解决方案的场景。

Spark-TTS 语音生成界面

Spark-TTS 语音克隆界面
功能列表
- 文本转语音转换:将输入的文本快速转换为自然语音,支持多种语言。
- 预训练模型支持:提供现成的模型,用户无需从零开始训练即可生成语音。
- 自定义语音训练:允许用户使用自己的数据集训练模型,调整语音风格或语调。
- 多种声音风格:支持不同性别、语速和音调的语音输出。
- 开源代码访问:用户可自由下载、修改和优化代码,满足个性化需求。
- 跨平台兼容性:基于通用编程环境,支持在多种操作系统上运行。
使用帮助
Spark-TTS 作为一个 GitHub 上的开源项目,没有独立的安装包或图形界面,主要面向具备一定编程基础的用户。以下是详细的使用指南,帮助你从零开始上手并充分利用其功能。
安装流程
由于 Spark-TTS 是基于 GitHub 的代码仓库,需要通过克隆仓库并配置环境来使用。以下是具体步骤:
- 环境准备
- 确保你的电脑已安装 Python(建议版本 3.8 或更高)。
- 安装 Git,用于从 GitHub 下载代码。可以从 Git 官网 下载并安装。
- (可选)安装虚拟环境工具,如
virtualenv,以隔离项目依赖。
- 克隆仓库
- 打开终端(Windows 使用 CMD 或 PowerShell,Mac/Linux 使用 Terminal)。
- 输入以下命令,将 Spark-TTS 仓库克隆到本地:
git clone https://github.com/SparkAudio/Spark-TTS.git - 克隆完成后,进入项目目录:
cd Spark-TTS
- 安装依赖
- Spark-TTS 通常需要依赖深度学习框架(如 PyTorch 或 TensorFlow)和音频处理库。查看仓库中的
requirements.txt文件(如果有),运行以下命令安装依赖:pip install -r requirements.txt - 如果没有
requirements.txt,常见依赖可能包括:pip install torch torchaudio numpy - 根据你的硬件(CPU 或 GPU),确保安装对应版本的 PyTorch,可参考 PyTorch 官网。
- Spark-TTS 通常需要依赖深度学习框架(如 PyTorch 或 TensorFlow)和音频处理库。查看仓库中的
- 验证安装
- 进入项目目录后,运行一个简单的测试脚本(如果仓库提供)。例如:
python test.py - 如果没有报错,说明环境配置成功。
- 进入项目目录后,运行一个简单的测试脚本(如果仓库提供)。例如:
主要功能操作
Spark-TTS 的核心功能是将文本转为语音,以下是具体操作流程:
1. 使用预训练模型生成语音
- 准备文本:创建一个简单的文本文件(如
input.txt),写入需要转换的文本,例如:“你好,这是一个测试语音。” - 运行脚本:假设仓库提供了一个
generate.py脚本(具体文件名以实际仓库为准),在终端输入:python generate.py --input input.txt --output output.wav
- 参数说明:
--input:指定输入文本文件路径。--output:指定生成的语音文件保存路径(如output.wav)。- 如果脚本支持,可添加
--model参数选择预训练模型,或--voice参数调整声音风格。
- 结果:运行后,你会在指定路径找到生成的
output.wav文件,用音频播放器打开即可听到效果。
2. 训练自定义模型
- 准备数据集:你需要提供文本和对应的音频数据。数据格式通常是
.txt文件(文本)和.wav文件(音频),建议参考仓库中的README.md或示例文件夹。 - 配置参数:编辑配置文件(可能是
config.json或类似文件),设置训练参数,如学习率、批次大小等。如果没有配置文件,直接在脚本中修改参数。 - 启动训练:运行训练脚本,例如:
python train.py --data_path ./dataset --output_model my_model - 训练过程:根据数据量和硬件性能,训练可能需要数小时甚至几天。完成后,你会得到一个新的模型文件(如
my_model.pth)。 - 使用新模型:将训练好的模型路径传入生成脚本:
python generate.py --input input.txt --model my_model.pth --output custom_output.wav
3. 调整语音风格
- 如果 Spark-TTS 支持多风格输出(需查看代码或文档确认),可以通过参数调整语速、音调等。例如:
python generate.py --input input.txt --speed 1.2 --pitch 0.8 --output styled_output.wav - 参数说明:
--speed:语速,1.0 为正常速度,大于 1.0 加快,小于 1.0 减慢。--pitch:音调,值越高音调越高,反之越低。
- 效果验证:生成后试听,逐步调整参数直到满意。
操作流程实例
假设你想将一段中文文本转为女性语音:
- 创建
test.txt,写入:“今天天气很好,我们去公园散步吧。” - 运行命令:
python generate.py --input test.txt --voice female --output park.wav - 检查
park.wav,确认语音是否自然流畅。 - 如果不满意,尝试调整参数或训练新模型。
注意事项
- 文档参考:优先查看仓库中的
README.md,里面可能有更具体的安装和使用说明。 - 硬件要求:生成和训练可能需要 GPU 加速,若无 GPU,可在 CPU 上运行,但速度较慢。
- 社区支持:如果遇到问题,可在 GitHub Issues 页面提问,或搜索类似 TTS 项目(如 Coqui TTS)的解决方案。
通过以上步骤,你可以轻松上手 Spark-TTS,无论是生成语音还是定制专属模型,都能满足需求。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...