

你是否遇到过这些困扰?「手动复制粘贴数据太耗时,效率低下」;「想要批量收集网页数据,但不会写代码」;「尝试过其他爬虫工具,但都太复杂,学习成本高」;「担心爬虫会被网站封禁,不知如何处理」。
别担心!今天我将教你使用 Automa 这个神器,让数据爬取变得简单又高效!
1. Automa:你的无代码数据采集助手
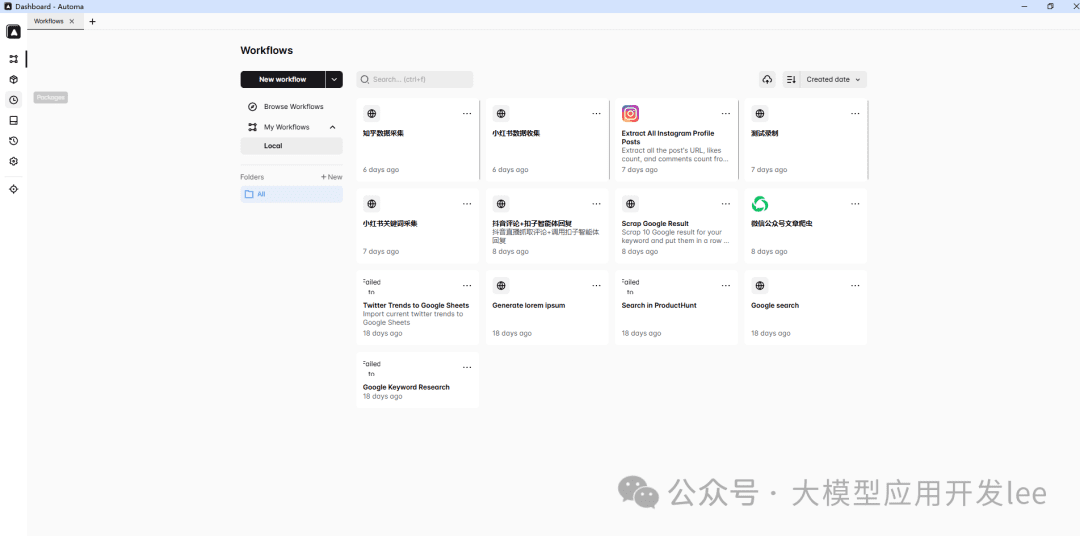
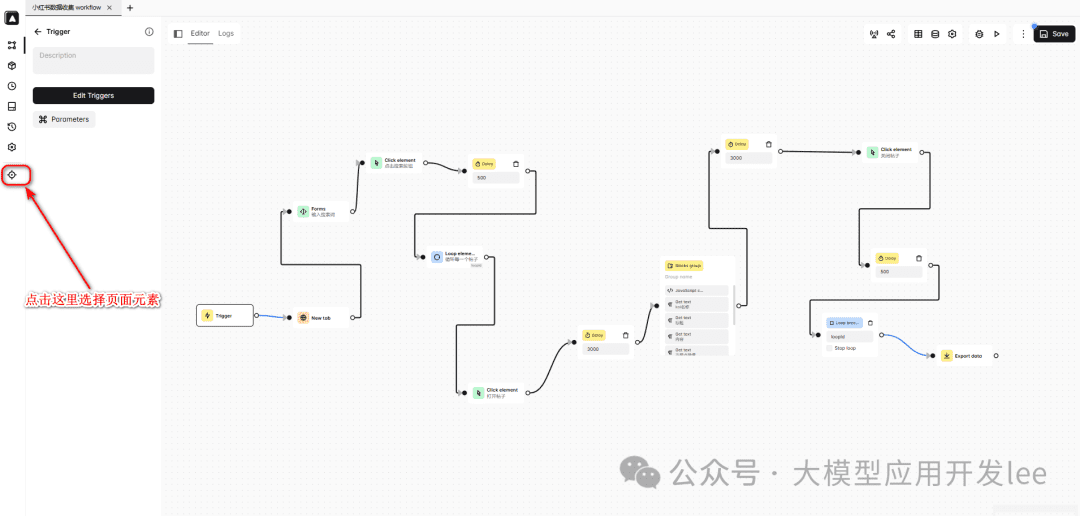
Automa插件界面总览
Automa 是一个强大的 Chrome 浏览器自动化插件。它能帮你「自动化浏览网页操作,批量采集数据,导出数据为各种格式,设置定时任务」。
最重要的是:「完全不需要写代码,通过可视化界面就能搞定!」
2. 从入门到精通:三步搞定数据爬取
第一步:安装和基础设置
在 Chrome 商店搜索"Automa"并安装,点击浏览器右上角的 Automa 图标,然后创建新的工作流。
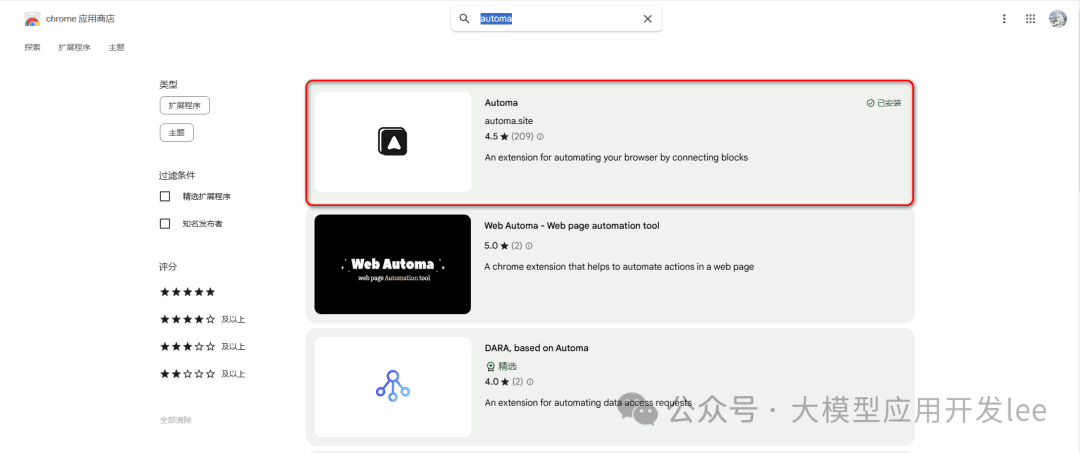
Chrome商店安装界面
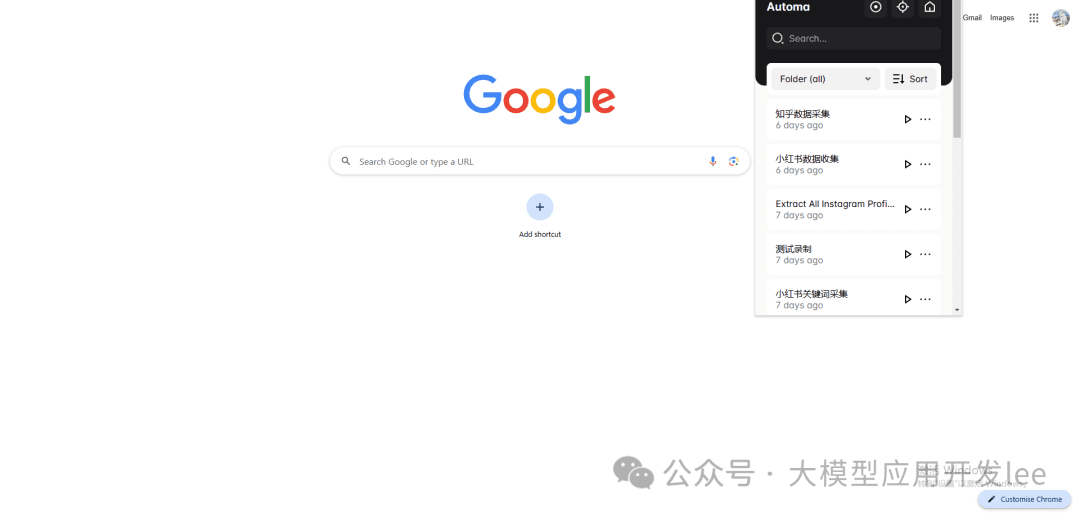
Automa插件位置
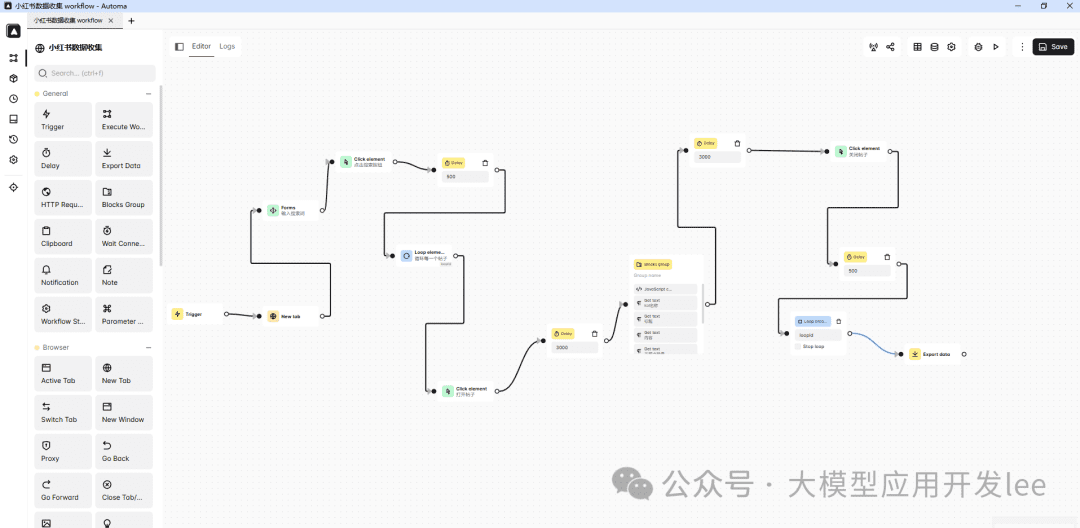
工作流创建界面
第二步:设计工作流程
以爬取电商产品数据为例,「核心步骤」包括:「设置起始页面,添加循环块处理分页,提取商品信息,最后导出数据」。
第三步:运行和优化
为了确保数据采集的稳定性和效率,「需要设置合理的延迟时间,等待页面加载完成」。同时要「添加错误处理机制,防止意外中断」。
3. 实战案例:小红薯热帖数据采集
Automa 核心概念说明
在开始实战之前,让我们先了解一下 Automa 的几个核心概念:
- 工作流(Workflow): 整体任务流程的容器
- 块(Block): 每个具体功能模块
- 选择器(Selector): 定位网页元素的工具
- 变量(Variable): 存储临时数据
- 触发器(Trigger): 启动工作流的条件
- 数据表(Table): 收集整理数据的表格
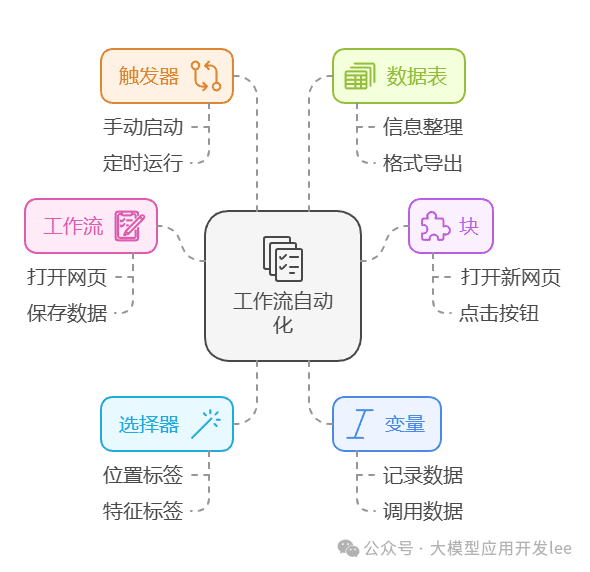
工作流自动化基础概述
案例分析
以小红薯热帖数据采集为例,我们来看看如何使用 Automa 采集热门笔记数据。核心就是模仿我们自己手动采集的过程,然后使用 Automa 来实现自动化。
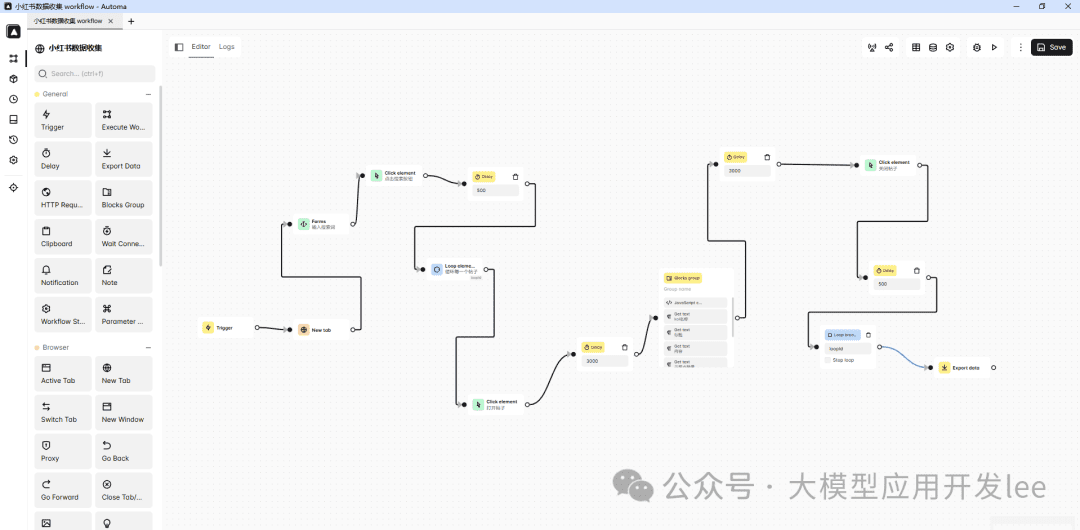
小红书数据采集流程
首先我们来看看如何使用 Automa 采集小红书数据。整个流程分为以下几个步骤:
创建工作流并配置触发器
创建一个名为"小红书数据收集"的工作流。在触发器(Trigger)中添加一个名为"key_word"的参数,用于输入要搜索的关键词。这个参数的默认值设为"独立开发者"。
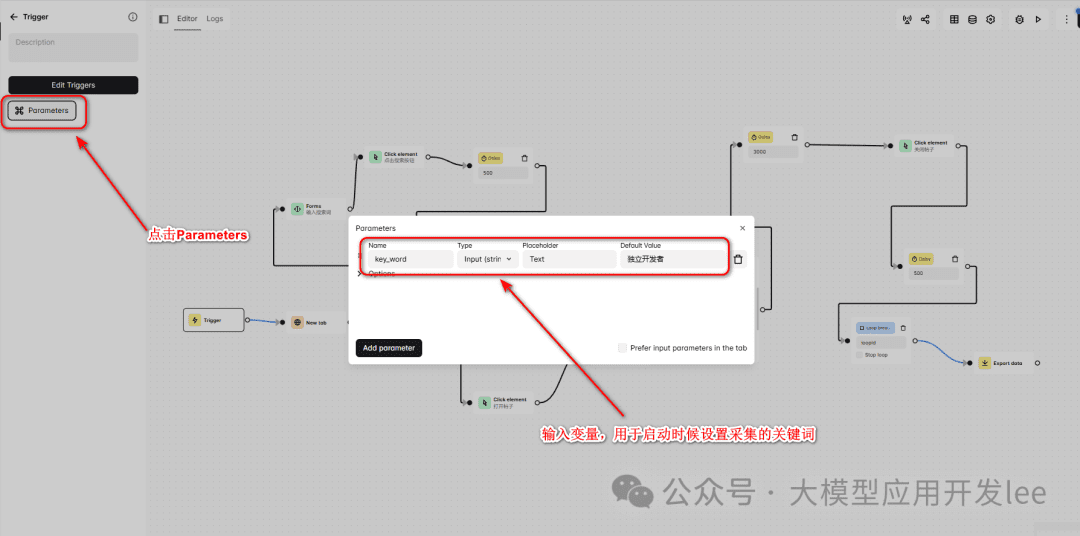
触发器配置
打开目标页面并搜索
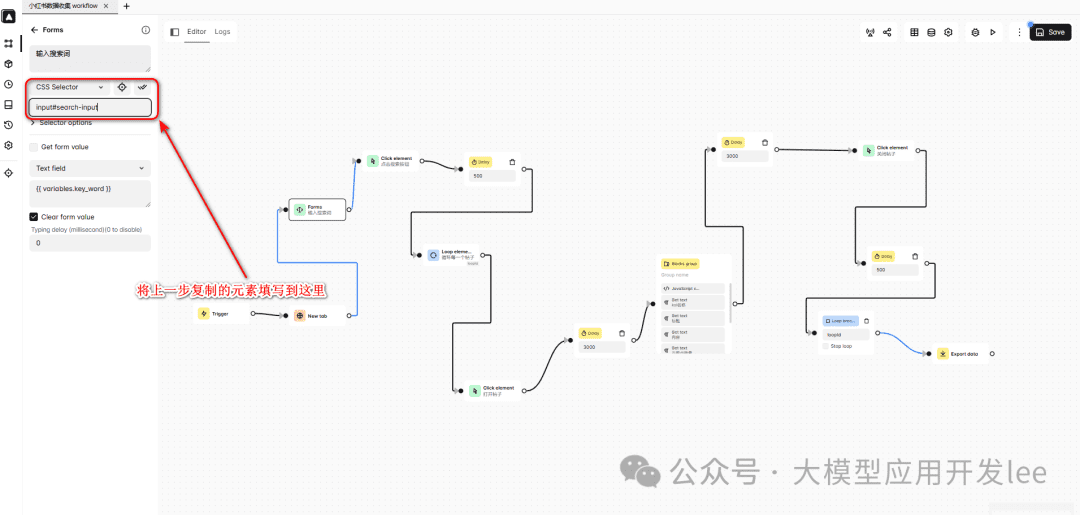
使用"新建标签页"(New Tab)块打开小红书首页(https://www.xiaohongshu.com/explore)。然后使用表单(Forms)块来定位搜索框。
如何选择到元素
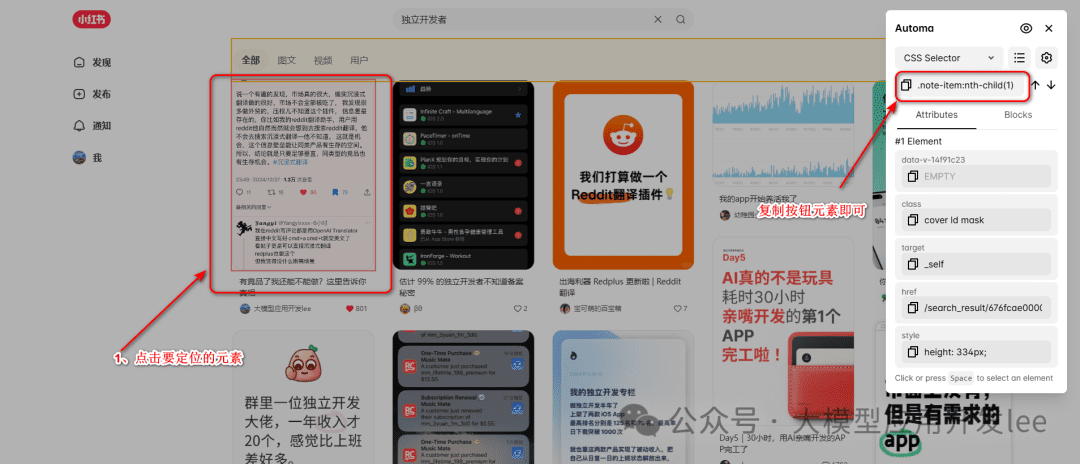
- 在 dashboard 侧边栏中找到如下图标,即可进入页面选择元素

获取选择器
- 在采集页面上选择元素,然后点击右上角的复制按钮
复制选择器
- 将上一步选择的元素粘贴到 Automa 的 Css Selcetor 中
粘贴选择器
循环采集数据
使用循环元素(Loop Elements)块遍历笔记列表。我们需要获取笔记列表的选择器:
- 在笔记列表页面,右键点击任意一个笔记封面
- 用 Automa 选择器获取工具获取选择器".note-item .cover"
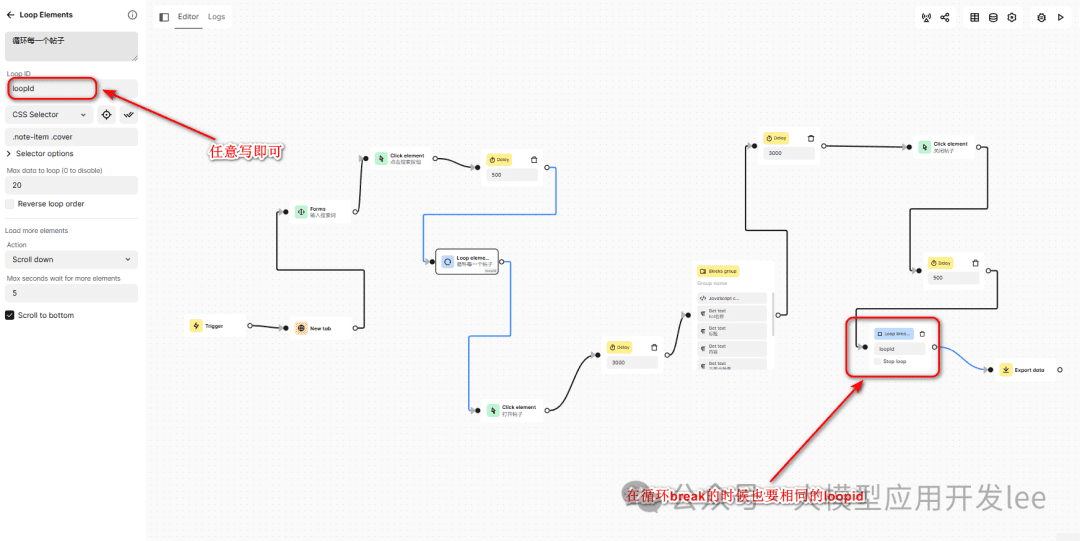
循环配置
打开帖子并获取详情
在循环中,我们需要点击每个笔记进入详情页面。这里需要注意以下几点:
- 「等待页面加载」使用"等待元素"(Wait Element)块,确保页面完全加载:
- 「点击笔记封面」使用"点击元素"(Click Element)块,点击每个笔记封面:
- 「等待详情页面加载」使用"等待元素"(Wait Element)块,确保详情页面完全加载:
打开元素示意图
在每次循环中采集的数据选择器获取方法:
- KOL 名称: 右键点击作者名称 > 检查 > 复制选择器 "a.name"
- 笔记标题: 选择器 "div#detail-title"
- 笔记内容: 选择器 "#detail-desc > .note-text > span"
- 互动数据:
- 点赞数: ".left > .like-wrapper > .count"
- 收藏数: "#note-page-collect-board-guide > .count"
- 评论数: ".chat-wrapper > .count"
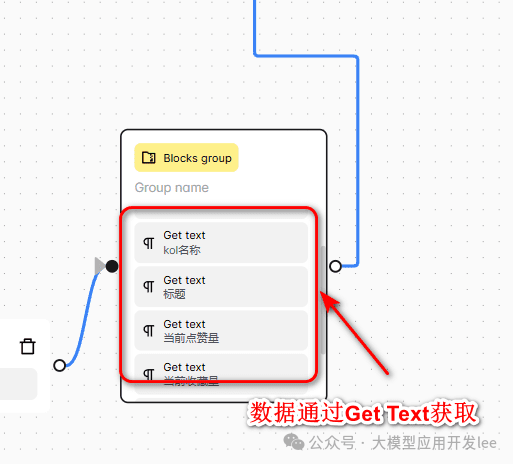
选择器示例
导出数据
最后使用导出数据(Export Data)块,将采集到的数据以 CSV 格式导出。
小技巧
- 如果选择器不准确,可以尝试使用 XPath
- 添加适当的延时等待页面加载
- 定期检查选择器是否失效
- 建议每次采集不超过 20 条数据
- 控制采集频率,不要频繁采集
整个工作流通过合理的延时控制和选择器定位,可以稳定地完成数据采集任务。同时通过参数化配置,方便根据不同需求调整采集关键词。
4. 常见问题与解决方案
动态选择器详解
在采集多个相似元素时,我们经常需要使用动态选择器。让我们通过一个实际的例子来学习。
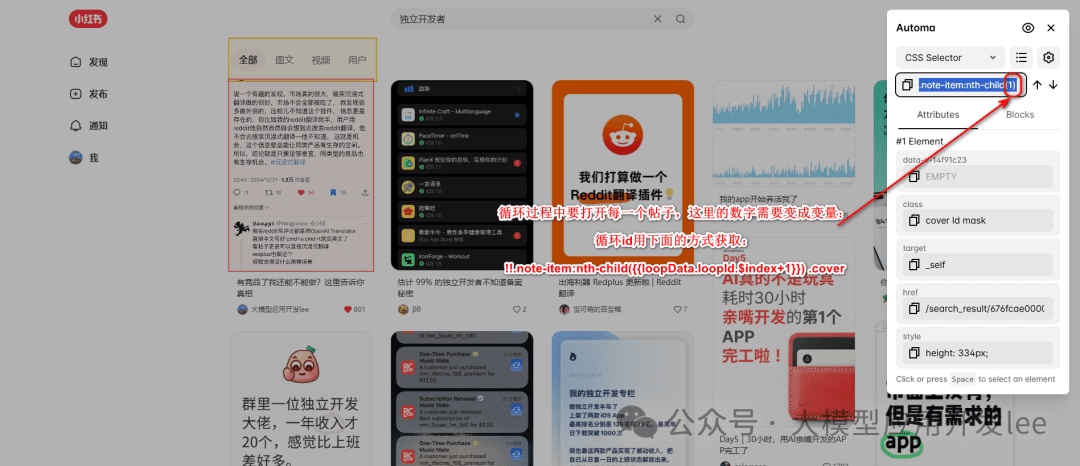
以这个选择器为例:
!!.note-item:nth-child({{loopData.loopId.$index+1}}) .cover
这个选择器看起来很复杂,让我们一步步拆解:
!! 前缀是 Automa 的特殊语法,表示使用 JavaScript 选择器而不是 CSS 选择器,让我们能够使用更灵活的选择方式。
.note-item选择 class 为"note-item"的元素,这通常是列表中的每个帖子容器。
:nth-child()是 CSS 的子元素选择器,用于选择特定位置的子元素,括号内可以是数字或表达式。
{{loopData.loopId.$index+1}}中的{{}}是 Automa 的变量语法,loopData.loopId.$index是循环中的当前索引(从 0 开始),+1是因为:nth-child从 1 开始计数。
.cover选择最终目标元素,在这个例子中是帖子的封面图。
在循环块中这样配置:
{
selector: "!!.note-item:nth-child({{loopData.loopId.$index+1}}) .cover",
timeout: 5000
}
为什么要这样写?因为它能实现动态定位:
- 第 1 次循环:
.note-item:nth-child(1) .cover - 第 2 次循环:
.note-item:nth-child(2) .cover - 第 3 次循环:
.note-item:nth-child(3) .cover - 以此类推...
这样可以避免固定选择器的问题:
/* 错误写法 */
.note-item .cover // 会选中所有cover元素
/* 正确写法 */
!!.note-item:nth-child({{loopData.loopId.$index+1}}) .cover // 精确选择当前循环的元素
如果你不确定选择器是否正确,可以在浏览器控制台测试:
// 假设当前是第3次循环
document.querySelector('.note-item:nth-child(3) .cover')
也可以使用 Automa 的日志功能:
{
type: "log",
message: "当前选择器: .note-item:nth-child({{loopData.loopId.$index+1}}) .cover"
}
通过这种动态选择器的方式,我们可以准确定位每次循环中的目标元素,避免选择到错误的元素,提高工作流的稳定性和准确性。选择器的编写是数据采集中最关键的部分之一,合理使用动态选择器可以让你的工作流更加健壮和可靠。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...